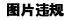一、目的
在用Flume把Kafka的数据采集写入Hive的ODS层表的HDFS文件路径后,发现HDFS文件中没问题,但是ODS层表中字段的数据却有问题,字段中的JSON数据不全
二、Hive处理JSON数据方式
(一)将Flume采集Kafka的JSON数据以字符串的方式整个写入Hive表中,然后再用get_json_object或json_tuple进行解析
1、ODS层建静态分区外部表,Flume直接写入ODS层表的HDFS路径下
create external table if not exists ods_evaluation( evaluation_json string ) comment '评价数据外部表——静态分区' partitioned by (day string) stored as SequenceFile ;

2、用get_json_object进行解析
select
get_json_object(evaluation_json,'$.deviceNo') device_no,
get_json_object(evaluation_json,'$.createTime') create_time,
get_json_object(evaluation_json,'$.cycle') cycle,
get_json_object(evaluation_json,'$.laneNum') lane_num,
get_json_object(evaluation_json,'$.evaluationList') evaluation_list
from hurys_dc_ods.ods_evaluation
;

(二)在导入Hive表之前将JSON数据已拆分好,需要使用JsonSerDe
create external table if not exists ods_track(
device_no string comment '设备编号',
create_time timestamp comment '创建时间',
track_data string comment '轨迹数据集合(包含多个目标点)'
)
comment '轨迹数据表——静态分区'
partitioned by (day date)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties (
"separatorChar" = ",",
"quoteChar" = "\"",
"escapeChar" = "\\"
)
tblproperties("skip.header.line.count"="1") ;
注意:使用JsonSerDe时,每行必须是一个完整的JSON,一个JSON不能跨越多行,否则不能使用JsonSerDe
三、ODS层原有建表SQL
create external table if not exists ods_evaluation(
evaluation_json string
)
comment '评价数据外部表——静态分区'
partitioned by (day string)
row format delimited fields terminated by '\x001'
lines terminated by '\n'
stored as SequenceFile
;
四、HDFS文件中的数据
HDFS文件中JSON数据完整,数据没问题

五、报错详情

查看表数据时发现evaluation_json字段的数据不完整

六、解决方法
(一)重新建表,建表语句中删除其中两行
--row format delimited fields terminated by '\x001'
--lines terminated by '\n'
(二)新建表SQL
create external table if not exists ods_evaluation( evaluation_json string ) comment '评价数据外部表——静态分区' partitioned by (day string) stored as SequenceFile ;
七、查询新表中evaluation_json字段的数据
数据解析成功!
 文章来源:https://www.toymoban.com/news/detail-776275.html
文章来源:https://www.toymoban.com/news/detail-776275.html
又解决了一个问题,宾果!文章来源地址https://www.toymoban.com/news/detail-776275.html
到了这里,关于二百一十、Hive——Flume采集的JSON数据文件写入Hive的ODS层表后字段的数据残缺的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!