最近,AIGCer在使用一些视频生成工具,对其中的技术点有了强烈兴趣,正好搜索到了这篇视频扩散模型综述,方法果然浩如烟海,读下来感觉受益良多,分享给大家。
最近,人工智能生成内容(AIGC)浪潮在计算机视觉领域取得了巨大成功,扩散模型在这一成就中发挥着关键作用。由于其出色的生成能力,扩散模型逐渐取代了基于GAN和自回归Transformer的方法,在图像生成和编辑以及视频相关研究领域表现出色。然而,现有的调查主要集中在图像生成的背景下的扩散模型,对它们在视频领域应用的最新评论相对较少。为了弥补这一差距,本文介绍了AIGC时代视频扩散模型的全面回顾。具体而言,首先简要介绍扩散模型的基础知识和演变历程。随后,概述了视频领域扩散模型研究的概况,将这方面的工作分为三个关键领域:视频生成、视频编辑和其他视频理解任务。对这三个关键领域的文献进行了彻底的回顾,包括在该领域中的进一步分类和实际贡献。最后,讨论了该领域研究面临的挑战,并勾勒了潜在的未来发展趋势。本综述中研究的视频扩散模型的全面列表可在地址中查看:「https://github.com/ChenHsing/Awesome-Video-Diffusion-Models」
介绍
人工智能生成内容(AIGC)目前是计算机视觉和人工智能领域最重要的研究方向之一。它不仅引起了广泛关注和学术研究,还在各行业和其他应用中产生了深远的影响,如计算机图形学、艺术与设计、医学成像等。在这些努力中,以扩散模型为代表的一系列方法已经取得了显著的成功,迅速取代了基于生成对抗网络(GANs)和自回归Transformer的方法,成为图像生成的主导方法。由于它们强大的可控性、逼真的生成和出色的多样性,基于扩散的方法还在广泛的计算机视觉任务中蓬勃发展,包括图像编辑、密集预测和诸如视频合成和3D生成等各种领域。
作为最重要的媒体之一,视频在互联网上崭露头角。与纯文本和静态图像相比,视频呈现了丰富的动态信息,为用户提供了更全面、沉浸式的视觉体验。基于扩散模型的视频任务研究正逐渐引起关注。如下图1所示,自2022年以来,视频扩散模型研究论文的数量显著增加,可以分为三个主要类别:视频生成、视频编辑和视频理解。
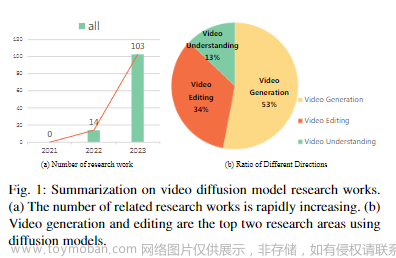
随着视频扩散模型的快速发展和其取得令人印象深刻的成果,追踪和比较这一主题的最新研究变得非常重要。多篇综述文章已经涵盖了AIGC时代基础模型的研究,包括扩散模型本身和多模态学习。也有一些专门关注文本到图像研究和文本到3D应用的综述。然而,这些综述要么只提供对视频扩散模型的粗略覆盖,要么更加强调图像模型。因此,在这项工作中,作者旨在通过对扩散模型的方法论、实验设置、基准数据集以及其他视频应用进行全面回顾,填补这一空白。
「贡献」:在这篇综述中,系统地跟踪和总结了有关视频扩散模型的最新文献,涵盖视频生成、编辑以及视频理解的其他方面。通过提取共享的技术细节,这次综述涵盖了该领域最具代表性的工作。还介绍了关于视频扩散模型的背景和相关知识基础。此外,对视频生成的基准和设置进行了全面的分析和比较。更重要的是,由于视频扩散的快速演进,可能没有在这次综述中涵盖所有最新的进展。
「流程」:将介绍背景知识,包括问题定义、数据集、评估指标和相关研究领域。随后,介绍主要概述视频生成领域的方法。深入研究与视频编辑任务相关的主要研究。后续阐明了利用扩散模型进行视频理解的各种方向。再强调了现有的研究挑战和潜在的未来发展方向,并总结结论。
预备知识
首先介绍扩散模型的基础内容,随后回顾相关研究领域。最后,介绍常用的数据集和评估指标。
扩散模型
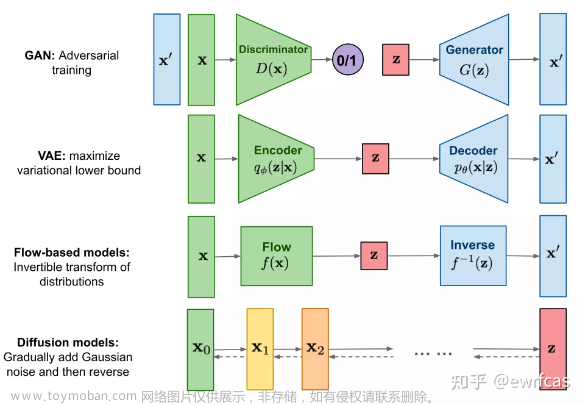
扩散模型是一类概率生成模型,其任务是学习逆转一个逐渐降低训练数据结构的过程。这一类模型在深度生成模型领域取代了生成对抗网络在一些挑战性任务中的主导地位。目前的研究主要关注于三种主要的扩散模型表述:去噪扩散概率模型(DDPMs)、基于分数的生成模型(SGMs)和随机微分方程(Score SDEs)。
去噪扩散概率模型(DDPMs)
去噪扩散概率模型(DDPM)包括两个马尔可夫链:一个前向链将数据扰动到噪声,而一个反向链将噪声转换回数据。前者旨在将任何数据转化为一个简单的先验分布,而后者学习转换核以逆转前者的过程。通过首先从先验分布中抽样一个随机向量,然后通过反向马尔可夫链进行原始抽样,可以生成新的数据点。这个抽样过程的关键是训练反向马尔可夫链以匹配前向马尔可夫链的实际时间逆转。
正式而言,假设存在一个数据分布 ₀₀,前向马尔可夫过程生成了一系列随机变量 x₁, x₂, ..., ,其转移核为 q(xₜ | xₜ₋₁)。在给定 x₀ 的条件下,x₁, x₂, ..., 的联合分布,表示为 q(x₁, ..., | x₀),可以分解为:
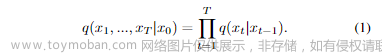
通常,转移核被设计为:
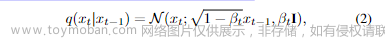
其中,βₜ ∈ (0, 1) 是在模型训练之前选择的超参数。
反向马尔可夫链由一个先验分布 p() = N(; 0, I) 和一个可学习的转移核 θ(xₜ₋₁|xₜ) 参数化,其形式为

在这里,θ 表示模型参数,均值 μθ(xₜ, t) 和方差 θ(xₜ, t) 由深度神经网络参数化。利用反向马尔可夫链,作者可以通过首先从噪声向量 ∼ p() 中抽样,然后从可学习的转移核 xₜ₋₁ ∼ θ(xₜ₋₁|xₜ) 迭代抽样直到 t = 1,生成新的数据 x₀。
基于分数的生成模型(SGMs)
基于分数的生成模型(SGMs)的关键思想是使用不同水平的噪声扰动数据,并同时通过训练一个单一的条件分数网络来估计与所有噪声水平相对应的分数。通过在逐渐减小的噪声水平上链接分数函数并使用基于分数的抽样方法,生成样本。在SGMs的公式中,训练和抽样是完全解耦的。
假设 q(x₀) 是数据分布,且 0 < σ₁ < σ₂ < ... < σₜ 是一系列噪声水平。SGMs的一个典型示例涉及使用高斯噪声分布 q(xₜ|x₀) = N(xₜ; x₀, σₜ₂I) 将数据点 x₀ 扰动为 xₜ,从而产生一系列噪声数据密度 q(x₁), q(x₂), ..., q(),其中 q(xₜ) := ∫ q(xₜ|x₀)q(x₀)dx₀。噪声条件分数网络(NCSN)是一个深度神经网络 θ(x,t),其训练目标是估计分数函数 ∇xₜ log q(xₜ)。作者可以直接使用分数匹配、去噪分数匹配和切片分数匹配等技术,从扰动的数据点中训练作者的NCSN。
对于样本生成,SGMs利用迭代方法,通过使用诸如淬火 Langevin 动力学(ALD)等技术,依次生成来自 θ(x,T), θ(x,T−1), ..., θ(x,0) 的样本。
随机微分方程(Score SDEs)
使用多个噪声尺度扰动数据是上述方法成功的关键。Score SDEs 进一步将这个思想推广到无限多个噪声尺度。扩散过程可以被建模为以下随机微分方程(SDE)的解:
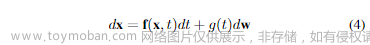
其中,f(x, t) 和 g(t) 分别是 SDE 的扩散和漂移函数, w是标准维纳过程。从样本 x(T)~开始并反转过程,作者可以通过这个逆时间 SDE 获得样本 x(0)~p₀:
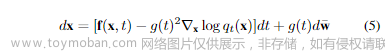
其中, 是标准维纳过程,当时间倒流时使用。一旦对于所有t已知每个边际分布的分数 ∇log(x),作者可以从方程5推导出逆扩散过程并模拟它以从中抽样。
相关工作
视频扩散模型的应用涵盖了广泛的视频分析任务,包括视频生成、视频编辑以及各种其他形式的视频理解。这些任务的方法学存在相似性,通常将问题制定为扩散生成任务,或利用扩散模型在下游任务中强大的受控生成能力。在这份调查中,主要关注任务包括文本到视频生成、无条件视频生成以及文本引导的视频编辑等。
「文本到视频生成」:旨在根据文本描述自动生成相应的视频。通常涉及理解文本描述中的场景、对象和动作,并将它们转换为一系列连贯的视觉帧,生成既逻辑上一致又视觉上一致的视频。文本到视频生成具有广泛的应用,包括自动生成电影、动画、虚拟现实内容、教育演示视频等。
「无条件视频生成」:是一个生成建模任务,其目标是从随机噪声或固定初始状态开始生成一系列连续且视觉上连贯的视频,而无需依赖特定的输入条件。与有条件视频生成不同,无条件视频生成不需要任何外部指导或先前信息。生成模型需要自主学习如何在没有明确输入的情况下捕捉时间动态、动作和视觉一致性,以生成既真实又多样的视频内容。这对于探索生成模型从无监督数据中学习视频内容并展示多样性的能力至关重要。
「文本引导的视频编辑」:是一种利用文本描述来引导编辑视频内容的技术。在这个任务中,自然语言描述作为输入,描述了要应用于视频的期望更改或修改。系统然后分析文本输入,提取相关信息,如对象、动作或场景,并使用这些信息来引导编辑过程。文本引导的视频编辑通过允许编辑者使用自然语言传达其意图,从而提供了一种促进高效直观编辑的方式,潜在地减少了手动费时的逐帧编辑的需求。
数据集与评估指标
数据
视频理解任务的发展通常与视频数据集的发展保持一致,视频生成任务也是如此。在视频生成的早期阶段,任务受限于在低分辨率、小规模数据集以及特定领域上的训练,导致生成的视频相对单调。随着大规模视频文本配对数据集的出现,诸如通用文本到视频生成等任务开始受到关注。因此,视频生成的数据集主要可分为标题级和类别级,将分别讨论。
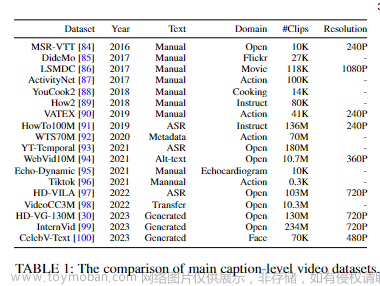
「标题级数据集」 包含与描述性文本标题配对的视频,为训练模型基于文本描述生成视频提供了关键的数据。作者在下表1中列出了几个常见的标题级数据集,这些数据集在规模和领域上各不相同。早期的标题级视频数据集主要用于视频文本检索任务,规模较小(小于120K),并且重点关注特定领域(例如电影、动作、烹饪)。随着开放领域WebVid-10M数据集的引入,文本到视频(T2V)生成这一新任务开始受到关注,研究人员开始关注开放领域的T2V生成任务。尽管它是T2V任务的主流基准数据集,但仍存在分辨率低(360P)和带水印的内容等问题。随后,为提高一般文本到视频(T2V)任务中视频的分辨率和覆盖范围,VideoFactory和InternVid引入了更大规模(130M和234M)和高清晰度(720P)的开放领域数据集。
「类别级数据集」 包含按特定类别分组的视频,每个视频都标有其类别。这些数据集通常用于无条件视频生成或类别条件视频生成任务。在下面表2中总结了常用的类别级视频数据集。
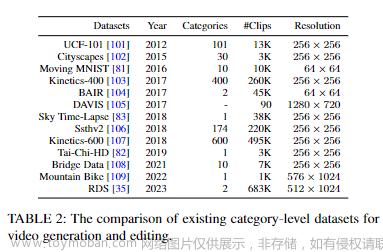
值得注意的是,其中一些数据集也应用于其他任务。例如,UCF-101、Kinetics和Something-Something是动作识别的典型基准。DAVIS最初是为视频对象分割任务提出的,后来成为视频编辑的常用基准。在这些数据集中,UCF-101是最广泛应用于视频生成的,既可以作为无条件视频生成的基准,也可以作为基于类别的条件生成和视频预测应用的基准。它包含来自YouTube的样本,涵盖101个动作类别,包括人体运动、乐器演奏和互动动作等。与UCF类似,Kinetics-400和Kinetics-600是两个涵盖更复杂动作类别和更大数据规模的数据集,同时保持了与UCF-101相同的应用范围。
另一方面,Something-Something数据集具有类别级和标题级标签,因此特别适用于文本条件的视频预测任务。值得注意的是,这些最初在动作识别领域发挥关键作用的大规模数据集呈现出较小规模(小于50K)和单一类别、单一领域属性(数字、驾驶风景、机器人)的特点,因此不足以生成高质量的视频。因此,近年来,专门用于视频生成任务的数据集被提出,通常具有独特属性,如高分辨率(1080P)或延长时长。例如,Long Video GAN提出了一个包含66个视频的骑马数据集,平均时长为6504帧,每秒30帧。Video LDM收集了RDS数据集,包括683,060个真实驾驶视频,每个视频长度为8秒,分辨率为1080P。
评估指标
总体来说,视频生成的评估指标可以分为定量和定性两类。定性评估通常通过人为主观评价进行,包括参与者对生成的视频与其他竞争模型合成的视频进行比较,并对视频的逼真度、自然连贯性和文本对齐等方面进行投票式评估。然而,人为评估成本高昂且有可能未能充分反映模型的全部能力。
因此,接下来主要探讨图像级和视频级评估的定量标准。
「图像级指标」 视频由一系列图像帧组成,因此图像级评估指标可以在一定程度上提供对生成的视频帧质量的见解。常用的图像级指标包括Frechet Inception Distance(FID),峰值信噪比(PSNR),结构相似性指数(SSIM)和CLIPSIM。FID 通过比较合成视频帧与真实视频帧来评估生成视频的质量。它涉及对图像进行归一化处理以使其具有一致的尺度,利用InceptionV3 从真实和合成视频中提取特征,然后计算均值和协方差矩阵。然后将这些统计数据组合起来计算FID 分数。
SSIM 和PSNR都是像素级别的指标。SSIM评估原始图像和生成图像的亮度、对比度和结构特征,而PSNR是表示峰值信号和均方误差(MSE)之间比率的系数。这两个指标通常用于评估重建图像帧的质量,并应用于超分辨率和修复等任务。
CLIPSIM 是用于测量图像-文本相关性的方法。基于CLIP 模型,它提取图像和文本特征,然后计算它们之间的相似性。这个度量通常用于文本条件的视频生成或编辑任务
「视频级指标」 尽管图像级评估指标代表生成的视频帧的质量,但它们主要关注单个帧,忽视了视频的时空一致性。另一方面,视频级指标将提供对视频生成更全面的评估。Fr ́echet Video Distance(FVD)是一种基于FID 的视频质量评估指标。与使用Inception网络从单帧提取特征的图像级方法不同,FVD利用在Kinetics 上预训练的Inflated-3D Convnets (I3D)从视频剪辑中提取特征。随后,通过均值和协方差矩阵的组合来计算FVD分数。与FVD 类似,Kernel Video Distance (KVD) 也基于I3D特征,但它通过使用最大均值差异(MMD),一种基于核的方法,来评估生成视频的质量。Video IS (Inception Score) 使用由3D-Convnets (C3D)提取的特征计算生成视频的Inception分数,这通常应用于UCF-101上的评估。高质量的视频具有低熵概率,表示为P(y|x),而多样性通过检查所有视频的边际分布来评估,这应该表现出高熵水平。Frame Consistency CLIP Score通常用于视频编辑任务,用于测量编辑视频的一致性。其计算涉及计算编辑视频的所有帧的CLIP图像query,并报告所有视频帧对之间的平均余弦相似性。
视频生成
将视频生成分为四个组别,并为每个组别提供详细的评估:通用文本到视频(T2V)生成、带有其他条件的视频生成、无条件视频生成和视频完成。最后,总结了设置和评估指标,并对各种模型进行了全面比较。视频生成的分类细节在下图2中展示。
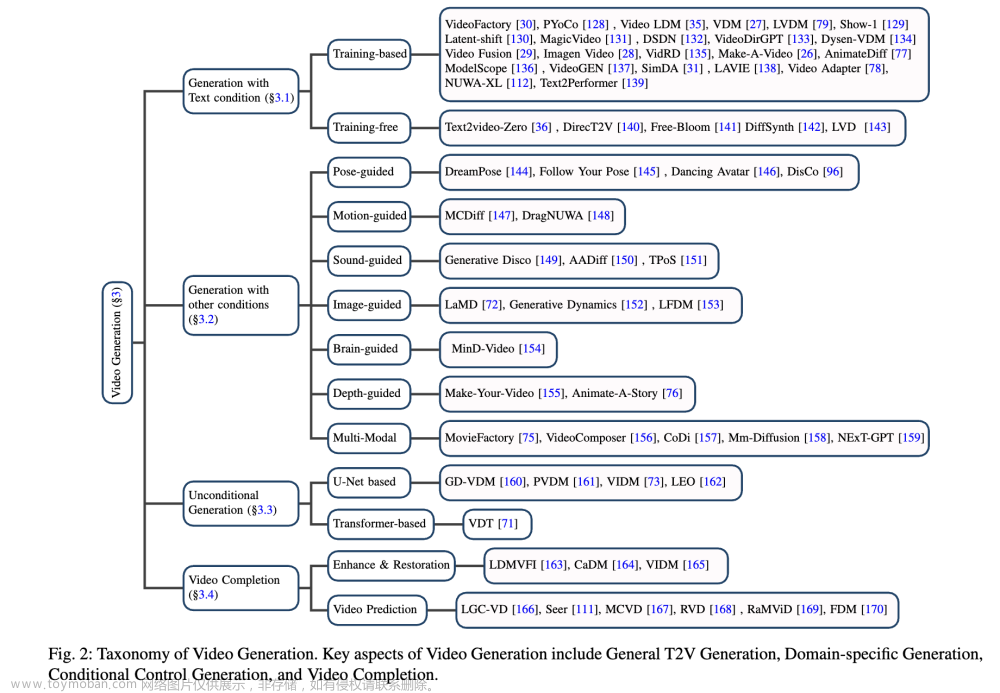
文本条件下的视频生成
最近的研究表明,生成人工智能与自然语言之间的互动至关重要。虽然在从文本生成图像方面取得了显著进展,但Text-to-Video (T2V) 方法的发展仍处于早期阶段。在这个背景下,首先简要概述了一些非扩散方法,然后深入介绍了在基于训练和基于无训练扩散技术上引入T2V模型。
非扩散型T2V方法
在扩散型模型出现之前,该领域的早期努力主要基于GANs,VQ-VAE和自回归Transformer框架。
在这些工作中,GODIVA是一个使用VQ-VAE进行通用T2V任务的表示性工作。它在包含超过100M视频文本对的Howto100M数据集上进行了预训练。该模型在当时表现出色,展示了卓越的零样本性能。随后,自回归Transformer方法由于其明确的密度建模和与GANs相比更稳定的训练优势,成为主流T2V任务的引领者。其中,CogVideo是一个开源视频生成模型,创新地利用预训练的CogView2作为其视频生成任务的骨干。此外,它扩展到使用Swin Attention进行自回归视频生成,有效减轻了长序列的时间和空间开销。除了上述工作外,PHENAKI引入了用于可变长度视频生成的新颖C-ViViT骨干。NUWA是一个基于自回归Transformer的T2I、T2V和视频预测任务的统一模型。MMVG提出了一种有效的蒙版策略,用于多个视频生成任务,包括T2V、视频预测和视频补充。
基于训练的T2V扩散方法
「早期T2V探索」 在众多的努力中,VDM是为视频生成设计视频扩散模型方面的先驱。它将传统的图像扩散U-Net架构扩展到3D U-Net结构,并采用图像和视频的联合训练。它采用的条件采样技术能够生成质量更高、时长更长的视频。作为对T2V扩散模型的首次探索,它还适应了无条件生成和视频预测等任务。
与需要配对的视频-文本数据集的VDM不同,Make-A-Video引入了一种新的范例。在这里,网络从配对的图像-文本数据中学习视觉-文本相关性,并从无监督视频数据中捕捉视频运动。这种创新方法减少了对数据收集的依赖,从而生成了多样且逼真的视频。此外,通过使用多个超分辨率模型和插值网络,它实现了更高清晰度和帧率的生成视频。
「时间建模探索」 虽然先前的方法利用像素级的扩散,MagicVideo是最早使用潜在扩散模型(LDM)进行潜在空间中的T2V生成的工作之一。通过在较低维度的潜在空间中利用扩散模型,它显著降低了计算复杂性,从而加速了处理速度。引入的逐帧轻量级适配器调整了图像和视频的分布,以便所提出的有向注意力更好地建模时间关系,确保视频一致性。
与此同时,LVDM也将LDM作为其骨干,采用分层框架来建模潜在空间。通过采用掩码采样技术,该模型能够生成更长的视频。它结合了条件潜在扰动和无条件引导等技术,以减轻自回归生成任务后期性能下降的影响。通过这种训练方法,它可以应用于视频预测任务,甚至生成包含数千帧的长视频。
ModelScope在LDM中引入了空间-时间卷积和注意力,用于T2V任务。它采用了LAION和WebVid的混合训练方法,并作为一个开源基准方法。
先前的方法主要依赖于1D卷积或时间注意力来建立时间关系。而Latent-Shift则侧重于轻量级的时间建模。从TSM获得启示,它在卷积块中在相邻帧之间移动通道以进行时间建模。此外,该模型在生成视频的同时保持了原始的T2I能力。
「多阶段T2V方法」 magen Video扩展了成熟的T2I模型Imagen,用于视频生成任务。级联视频扩散模型由七个子模型组成,其中一个专门用于基础视频生成,三个用于空间超分辨率,三个用于时间超分辨率。这些子模型共同形成一个全面的三阶段训练流程。它验证了在T2I训练中采用的许多训练技术的有效性,例如无分类器引导、条件增强和v-参数化。此外,作者利用渐进蒸馏技术来加速视频扩散模型的采样时间。其中引入的多阶段训练技术已成为主流高清视频生成的有效策略。
Video LDM同时训练一个由三个训练阶段组成的T2V网络,包括关键帧T2V生成、视频帧插值和空间超分辨率模块。它在空间层上添加了时间注意力层和3D卷积层,使得第一阶段可以生成关键帧。随后,通过实施掩码采样方法,训练了一个帧插值模型,将短视频的关键帧扩展到更高的帧率。最后,使用视频超分辨率模型增强分辨率。
LAVIE使用了一个由三个阶段组成的级联视频扩散模型:基础T2V阶段、时间插值阶段和视频超分辨率阶段。此外,它验证了联合图像-视频微调的过程可以产生高质量且富有创意的结果。
Show-1首次引入了基于像素和基于潜在扩散模型的融合,用于T2V生成。其框架包括四个不同的阶段,最初的三个在低分辨率像素级别运行:关键帧生成、帧插值和超分辨率。值得注意的是,像素级阶段可以生成具有精确文本对齐的视频。第四阶段由一个潜在超分辨率模块组成,提供了一种经济有效的增强视频分辨率的方法。
「噪声先验探索」 虽然大多数方法通过扩散模型独立地对每一帧进行去噪,但VideoFusion通过考虑不同帧之间的内容冗余和时间相关性而脱颖而出。具体而言,它使用每一帧的共享基础噪声和沿时间轴的残余噪声来分解扩散过程。这种噪声分解是通过两个共同训练的网络实现的。这种方法旨在确保在生成帧运动时的一致性,尽管这可能导致有限的多样性。此外,论文表明,使用T2I骨干模型(例如DALLE-2)来训练T2V模型可以加速收敛,但其文本query可能面临理解长时序文本序列的挑战。
PYoCo承认直接将图像的噪声先验扩展到视频可能在T2V任务中产生次优结果。作为解决方案,它巧妙地设计了视频噪声先验,并对eDiff-I模型进行微调以用于视频生成。提出的噪声先验涉及在视频的不同帧之间采样相关噪声。作者验证了提出的混合和渐进噪声模型更适合T2V任务。
「数据集贡献」 VideoFactory针对先前广泛使用的WebVid数据集存在低分辨率和水印问题提出了改进。为此,它构建了一个大规模视频数据集HD-VG-130M,包含了来自开放领域的130百万个视频文本对。该数据集是通过BLIP-2字幕从HD-VILA中收集而来,声称具有高分辨率并且没有水印。此外,VideoFactory引入了一种交换的交叉注意力机制,以促进时空模块之间的交互,从而改善了时序关系建模。在这个高清数据集上训练的方法能够生成分辨率为(1376×768)的高清视频。
VidRD引入了“重用和扩散”框架,通过重复使用原始潜在表示并遵循先前的扩散过程来迭代生成额外的帧。此外,它在构建视频文本数据集时使用了静态图像、长视频和短视频。对于静态图像,通过随机缩放或平移操作引入了动态因素。对于短视频,使用BLIP-2标注进行分类,而长视频首先进行分割,然后基于MiniGPT-4进行注释以保留所需的视频剪辑。在视频文本数据集中构建多样的类别和分布被证明对提升视频生成的质量非常有效。
「高效训练」 ED-T2V使用LDM作为其主干,并冻结了大部分参数以降低训练成本。它引入了身份关注和时间交叉关注以确保时间上的一致性。本文提出的方法在保持可比的T2V生成性能的同时成功降低了训练成本。
SimDA设计了一种参数高效的T2V任务训练方法,通过保持T2I模型的参数固定。它引入了轻量级的空间适配器来传递T2V学习的视觉信息。此外,它还引入了一个时间适配器,以在较低的特征维度中建模时间关系。提出的潜在转移关注有助于保持视频的一致性。此外,轻量级架构使得推理速度加快,适用于视频编辑任务。
「个性化视频生成」 通常指的是根据特定主题或风格创建定制视频,涉及生成根据个人偏好或特征定制的视频。AnimateDiff注意到LoRA和Dreambooth在个性化T2I模型方面取得的成功,并旨在将它们的效果扩展到视频动画。此外,作者的目标是训练一个可以适应生成各种个性化视频的模型,而无需在视频数据集上反复训练。这包括使用T2I模型作为基础生成器,并添加一个运动模块来学习运动动态。在推理过程中,个性化T2I模型可以替换基础T2I权重,实现个性化视频生成。
「去除伪影」 为解决T2V生成的视频中出现的闪烁和伪影问题,DSDN引入了一个双流扩散模型,一个用于视频内容,另一个用于运动。通过这种方式,它可以保持内容和运动之间的强对齐性。通过将视频生成过程分解为内容和运动组件,可以生成具有更少闪烁的连续视频。
VideoGen首先利用T2I模型生成基于文本提示的图像,作为引导视频生成的参考图像。随后,引入了一个高效的级联潜在扩散模块,采用基于流的时间上采样步骤来提高时间分辨率。与先前的方法相比,引入参考图像提高了视觉保真度并减少了伪影,使模型能够更专注于学习视频动态。
「复杂动态建模」 在生成文本到视频(T2V)时,面临着对复杂动态建模的挑战,尤其是在处理动作一致性中的干扰方面。为了解决这个问题,Dysen-VDM引入了一种将文本信息转化为动态场景图的方法。利用大型语言模型(LLM),Dysen-VDM从输入文本中识别关键动作,并按照时间顺序排列它们,通过添加相关的描述性细节来丰富场景。此外,模型从LLM的上下文学习中受益,赋予了它强大的时空建模能力。这种方法在合成复杂动作方面展现了显著的优势。
VideoDirGPT也利用LLM来规划视频内容的生成。对于给定的文本输入,它通过GPT-4将其扩展为一个视频计划,其中包括场景描述、实体及其布局,以及实体在背景中的分布。随后,模型通过对布局进行明确的控制生成相应的视频。这种方法在复杂动态视频生成的布局和运动控制方面展现了显著的优势。
「领域特定的文本到视频生成」 Video-Adapter引入了一种新颖的设置,通过将预训练的通用T2V模型转移到特定领域的T2V任务中。通过将特定领域的视频分布分解为预训练的噪声和一个小的训练组件,它大幅降低了转移训练的成本。该方法在T2V生成中的Ego4D和Bridge Data场景中的有效性得到了验证。
NUWA-XL采用了一种由粗到细的生成范式,促进了并行视频生成。它最初使用全局扩散生成关键帧,然后利用局部扩散模型在两个帧之间进行插值。这种方法使得能够创建长达3376帧的视频,从而为动画生成建立了一个基准。该工作专注于卡通视频生成领域,利用其技术来制作持续数分钟的卡通视频。
Text2Performer将以人为中心的视频分解为外观和运动表示。首先,它利用VQVAE的潜在空间对自然人类视频进行无监督训练,以解开外观和姿态表示。随后,它利用连续的VQ-diffuser对连续姿态query进行采样。最后,作者在姿态query的时空域上采用了一种运动感知的掩码策略,以增强时空相关性。
无训练T2V扩散方法
前述方法都是基于训练的T2V方法,通常依赖于广泛的数据集,如WebVid或其他视频数据集。一些最近的研究旨在通过开发无训练的T2V方法来减少庞大的训练成本,接下来将介绍这些方法。
Text2Video-Zero利用预训练的T2I模型Stable Diffusion进行视频合成。为了在不同帧之间保持一致性,它在每一帧和第一帧之间执行交叉注意力机制。此外,通过修改潜在代码的采样方法,它丰富了运动动态。此外,该方法可以与条件生成和编辑技术(如ControlNet和InstructPix2Pix)结合使用,实现对视频的可控生成。
另一方面,DirecT2V和Free-Bloom引入了大型语言模型(LLM)来基于单个抽象用户提示生成逐帧描述。LLM导向器用于将用户输入分解为帧级描述。此外,为了在帧之间保持连续性,DirecT2V使用了一种新颖的值映射和双Softmax过滤方法。Free-Bloom提出了一系列反向处理增强方法,包括联合噪声采样、步骤感知注意力转移和双路径插值。实验证明这些修改增强了零样本视频生成的能力。
为了处理复杂的时空提示,LVD首先利用LLM生成动态场景布局,然后利用这些布局指导视频生成。它的方法无需训练,并通过根据布局调整注意力图来引导视频扩散模型,从而实现复杂动态视频的生成。
DiffSynth提出了一种潜在迭代去闪烁框架和视频去闪烁算法,以减轻闪烁并生成连贯的视频。此外,它可以应用于各种领域,包括视频风格化和3D渲染。
具有其他条件的视频生成
大多数先前介绍的方法涉及文本到视频生成。在本小节中,关注基于其他模态条件(例如姿态、声音和深度)的视频生成。在图3中展示了受条件控制的视频生成的例子。

姿态引导的视频生成
Follow Your Pose: 采用由姿态和文本控制驱动的频生成模型。它通过利用图像-姿态对和不带姿态的视频进行两阶段的训练。在第一阶段,通过使用(图像,姿态)对来微调T2I(文本到图像)模型,实现了姿态控制的生成。在第二阶段,模型利用未标记的视频进行学习,通过引入时间注意力和跨帧注意力机制来进行时间建模。这两阶段的训练赋予了模型姿态控制和时间建模的能力。
Dreampose: 构建了一个双通道的CLIP-VAE图像编码器和适配器模块,用于替换LDM中原始的CLIP文本编码器作为条件组件。给定单个人类图像和姿态序列,该研究可以基于提供的姿态信息生成相应的人体姿态视频。
Dancing Avatar: 专注于合成人类舞蹈视频。它利用一个T2I模型以自回归方式生成视频的每一帧。为了确保整个视频的一致性,它使用了一个帧对齐模块,结合了ChatGPT的见解,以增强相邻帧之间的一致性。此外,它利用OpenPose ControlNet的能力,基于姿态生成高质量的人体视频。
Disco:解决了一个称为参考人类舞蹈生成的新问题设置。它利用ControlNet、Grounded-SAM和OpenPose进行背景控制、前景提取和姿态骨架提取。此外,它使用了大规模图像数据集进行人类属性预训练。通过结合这些训练步骤,Disco为人类特定的视频生成任务奠定了坚实的基础。
运动引导的视频生成
MCDiff 是在考虑运动作为控制视频合成的条件方面的先驱。该方法涉及提供视频的第一帧以及一系列笔画运动。首先,使用流完成模型基于稀疏笔画运动控制来预测密集视频运动。随后,该模型采用自回归方法,利用密集运动图预测随后的帧,最终实现完整视频的合成。
DragNUWA 同时引入文本、图像和轨迹信息,以从语义、空间和时间的角度对视频内容进行精细控制。为了进一步解决先前作品中缺乏开放域轨迹控制的问题,作者提出了Trajectory Sampler(TS)以实现对任意轨迹的开放域控制,Multiscale Fusion(MF)以在不同粒度上控制轨迹,并采用自适应训练(AT)策略生成遵循轨迹的一致视频。
声音引导的视频生成
AADiff 引入了将音频和文本一起作为视频合成的条件的概念。该方法首先使用专用编码器分别对文本和音频进行编码。然后,计算文本和音频query之间的相似性,并选择具有最高相似性的文本标记。所选的文本标记以prompt2prompt的方式用于编辑帧。这种方法使得可以生成与音频同步的视频,而无需额外的训练。
Generative Disco 是一个针对音乐可视化的文本到视频生成的AI系统。该系统采用了一个包括大型语言模型和文本到图像模型的流程来实现其目标。
TPoS 将具有可变时间语义和大小的音频输入与LDM的基础结合起来,以扩展在生成模型中利用音频模态的应用。这种方法在客观评估和用户研究中表现出色,超越了广泛使用的音频到视频基准,突显了其卓越的性能。
图像引导的视频生成
成器训练来生成视频运动。通过这种以运动为指导的方法,模型实现了在给定第一帧的情况下生成高质量感知视频的能力。
LFDM 利用条件图像和文本进行以人为中心的视频生成。在初始阶段,训练一个潜在流自编码器来重构视频。此外,在中间步骤可以使用流预测器来预测流动运动。随后,在第二阶段,使用图像、流动和文本提示作为条件来训练扩散模型,生成连贯的视频。
Generative Dynamics 提出了一种在图像空间建模场景动态的方法。它从展示自然运动的实际视频序列中提取运动轨迹。对于单个图像,扩散模型通过一个频率协调的扩散采样过程,在傅立叶域中为每个像素预测了长期运动表示。这个表示可以转换成贯穿整个视频的密集运动轨迹。当与图像渲染模块结合时,它能够将静态图像转化为无缝循环的动态视频,促进用户与所描绘对象进行逼真的交互。
brain导引的视频生成
MinD-Video 是探索通过连续fMRI数据进行视频生成的开创性尝试。该方法从将MRI数据与图像和文本进行对比学习开始。接下来,一个经过训练的MRI编码器替换了CLIP文本编码器作为输入进行条件编码。通过设计一个时间注意力模块来建模序列动态,进一步增强了模型。由此产生的模型能够重构具有精确语义、运动和场景动态的视频,超越了基准性能,并在该领域设立了新的基准。
深度引导的视频生成
Make-Your-Video 采用了一种新颖的方法进行文本深度条件视频生成。它通过在训练过程中使用MiDas提取深度信息,并将其整合为一个条件因素。此外,该方法引入了因果关注掩码,以促进更长视频的合成。与最先进的技术进行比较显示出该方法在可控文本到视频生成方面的优越性,展示了更好的定量和定性性能。
Animate-A-Story 引入了一种创新的方法,将视频生成分为两个步骤。第一步是Motion Structure Retrieval,涉及根据给定的文本提示从大型视频数据库中检索最相关的视频。利用离线深度估计方法获得这些检索到的视频的深度图,然后作为运动引导。在第二步中,采用Structure-Guided Text-to-Video Synthesis来训练一个视频生成模型,该模型由深度图导出的结构性运动进行引导。这种两步法使得可以基于定制文本描述创建个性化视频。
多模态引导的视频生成
VideoComposer 专注于以多模态为条件生成视频,包括文本、空间和时间条件。具体而言,它引入了一个时空条件编码器,允许各种条件的灵活组合。这最终使得可以整合多种模态,如草图、蒙版、深度和运动矢量。通过利用多模态的控制,VideoComposer实现了更高质量的视频和生成内容中细节的改进。
MM-Diffusion 是联合音视频生成的首次尝试。为了实现多模态内容的生成,它引入了一个包含两个子网络的分叉架构,分别负责视频和音频的生成。为了确保这两个子网络的输出之间的一致性,设计了基于随机位移的注意力块来建立相互连接。除了具有无条件音视频生成的能力外,《MM-Diffusion》还在视频到音频转换方面展现了显著的才华。
MovieFactory 致力于将扩散模型应用于电影风格视频的生成。它利用ChatGPT详细阐述用户提供的文本,为电影生成目的创建全面的顺序脚本。此外,设计了一个音频检索系统,为视频提供配音。通过上述技术,实现了生成多模态音频-视觉内容。
CoDi 提出了一种具有创建输出模态多样组合能力的新型生成模型,包括语言、图像、视频或音频,可以从不同的输入模态组合中生成。这是通过构建一个共享的多模态空间实现的,通过在不同模态之间对齐输入和输出空间来促进任意模态组合的生成。
NExT-GPT 呈现了一个端到端的、任意到任意的多模态LLM系统。它将LLM与多模态适配器和多样的扩散解码器集成在一起,使系统能够感知任意组合的文本、图像、视频和音频输入,并生成相应的输出。在训练过程中,它只微调了一个小的参数子集。此外,它引入了一个模态切换指令调整(MosIT)机制,并手动策划了一个高质量的MosIT数据集。该数据集促进了对复杂的跨模态语义理解和内容生成能力的获取。
无条件视频生成
在这一部分,将深入探讨了无条件视频生成。这指的是生成属于特定领域的视频,而无需额外的条件。这些研究的焦点围绕着视频表示的设计和扩散模型网络的架构。 「基于U-Net的生成」: VIDM是无条件视频扩散模型的早期作品之一,后来成为重要的基准方法之一。它利用两个流:内容生成流用于生成视频帧内容,动作流定义了视频运动。通过合并这两个流,生成一致的视频。此外,作者使用位置分组归一化(PosGN) 来增强视频的连续性,并探索隐式运动条件(IMC)和PosGN的组合,以解决长视频的生成一致性。
「类似于LDM的方法」: PVDM与LDM类似,首先训练一个自编码器将像素映射到较低维度的潜在空间,然后在潜在空间中应用扩散去噪生成模型来合成视频。这种方法既减少了训练和推断的成本,同时又能保持令人满意的生成质量。
「针对驾驶场景视频的生成」: GD-VDM主要专注于合成驾驶场景视频。它首先生成深度图视频,其中场景和布局生成被优先考虑,而细节和纹理则被抽象掉。然后,生成的深度图作为条件信号被提供,用于进一步生成视频的其余细节。这种方法保留了出色的细节生成能力,特别适用于复杂的驾驶场景视频生成任务。
「LEO方法」: LEO通过一系列流动图在生成过程中表示运动,从而在本质上将运动与外观分离。它通过基于流动图的图像动画器和潜在运动扩散模型的组合实现人类视频生成。前者学习从流动图到运动代码的重构,而后者捕捉运动先验以获取运动代码。这两种方法的协同作用使得能够有效地学习人类视频的相关性。此外,这种方法可以扩展到无限长度的人类视频合成和保持内容的视频编辑等任务。
「基于Transformer的生成」: 与大多数基于U-Net结构的方法不同,VDT是在Transformer架构基础上探索视频扩散模型的先驱者。利用Transformer的多功能可扩展性,作者研究了各种时间建模方法。此外,他们将VDT应用于多个任务,如无条件生成和视频预测。
视频补全
视频补全是视频生成领域内的一个关键任务。在接下来的章节中,将详述视频增强与恢复以及视频预测的不同方面。
视频增强与恢复
「CaDM」:CaDM引入了一种新颖的神经增强视频流传递范式,旨在显著降低流传递比特率,同时与现有方法相比,保持明显提升的恢复能力。首先,CaDM方法通过同时减小视频流中的帧分辨率和颜色位深度,提高编码器的压缩效能。此外,CaDM通过使解码器具备卓越的增强能力,赋予去噪扩散恢复过程对编码器规定的分辨率-颜色条件的认知。
「LDMVFI」: LDMVFI是首次尝试采用条件潜在扩散模型方法来解决视频帧插值(VFI)任务。为了利用潜在扩散模型进行VFI,该工作引入了一系列开创性的概念。值得注意的是,提出了一个专门用于视频帧插值的自动编码网络,它集成了高效的自注意模块,并采用基于可变形核的帧合成技术,显著提升了性能。
「VIDM」: VIDM利用预训练的LDM来解决视频修复任务。通过为第一人称视角的视频提供一个mask,该方法利用了LDM的图像补全先验来生成修复的视频。
视频预测
Seer: 专注于探索文本引导的视频预测任务。它利用潜在扩散模型(LDM)作为其基础骨架。通过在自回归框架内整合时空注意力,以及实施帧顺序文本分解模块,Seer熟练地将文本到图像(T2I)模型的知识先验转移到视频预测领域。这种迁移导致了显著的性能提升,尤其在基准测试中得到了显著证明。
FDM:引入了一种新颖的层次抽样方案,用于长视频预测任务。此外,提出了一个新的CARLA数据集。与自回归方法相比,该方法不仅更高效,而且产生了更优秀的生成结果。
MCVD:采用概率条件评分为基础的去噪扩散模型,用于无条件生成和插值任务。引入的掩模方法能够遮蔽所有过去或未来的帧,从而实现对过去或未来帧的预测。此外,它采用自回归方法以块状方式生成可变长度的视频。MCVD的有效性在各种基准测试中得到验证,包括预测和插值任务。
LGC-VD:由于自回归方法在生成长视频时产生不切实际的结果的倾向,引入了一个局部-全局上下文引导的视频扩散模型,旨在包含多样的感知条件。LGC-VD采用两阶段训练方法,并将预测错误视为一种数据增强形式。这种策略有效地解决了预测错误,并显著增强了在长视频预测任务背景下的稳定性。
RVD (Residual Video Diffusion):采用了一种扩散模型,该模型利用卷积循环神经网络(RNN)的上下文向量作为条件生成残差,然后将其添加到确定性的下一帧预测中。作者证明采用残差预测比直接预测未来帧更有效。该工作与基于生成对抗网络(GANs)和变分自动编码器(VAEs)的先前方法进行了广泛比较,为其有效性提供了实质性的证据。
RaMViD: 采用3D卷积将图像扩散模型扩展到视频任务领域。它引入了一种新颖的条件训练技术,并利用掩码条件扩展其适用范围,包括视频预测、填充和上采样等各种完成任务。
基准测试结果
本节对视频生成任务的各种方法进行了系统比较,分为零样本和微调两种不同的设置。对于每种设置,首先介绍它们常用的数据集。随后,说明了每个数据集所使用的详细评估指标。最后,对这些方法在不同设置下的性能进行了全面比较。
零样本文本到视频生成
「数据集:」 通用文本到视频(T2V)方法,如Make-A-Video和 VideoLDM,主要在MSRVTT和UCF-101数据集上以零样本方式进行评估。MSRVTT是一个视频检索数据集,其中每个视频剪辑都附有约20个自然语句的描述。通常,用于测试集中的2,990个视频剪辑的文本描述被用作提示,以生成相应的生成视频。UCF-101 是一个包含101个动作类别的动作识别数据集。在T2V模型的上下文中,视频通常是基于这些动作类别的类别名称或手动设置的提示生成的。
「评估指标:」 在零样本设置下进行评估时,通常使用MSRVTT数据集上的FVD 和FID指标来评估视频质量。CLIPSIM用于衡量文本和视频之间的对齐性。对于UCF-101数据集,典型的评估指标包括Inception Score、FVD和FID,用于评估生成的视频及其帧的质量。
「结果比较:」 在下表3中,作者展示了当前通用T2V方法在MSRVTT和UCF-101上的零样本性能。作者还提供了关于它们的参数数量、训练数据、额外依赖项和分辨率的信息。可以观察到,依赖于ChatGPT或其他输入条件的方法在性能上明显优于其他方法,并且使用额外数据通常会导致性能提升。

微调视频生成
数据集: 微调视频生成方法指的是在特定数据集上进行微调后生成视频。这通常包括无条件视频生成和类条件视频生成。主要关注三个特定的数据集:UCF-101 、Taichi-HD和 Time-lapse。这些数据集涉及不同的领域:UCF-101 集中在人类运动领域,Taichi-HD 主要包括太极拳视频,而Time-lapse 主要包含天空的延时摄影镜头。此外,还有其他几个可用的基准测试,但作者选择这三个,因为它们是最常用的。
评估指标: 在微调视频生成任务的评估中,UCF-101数据集的常用指标包括 IS Inception Score)和 FVD(Fréchet Video Distance)。对于Time-lapse和 Taichi-HD数据集,常见的评估指标包括 FVD 和 KVD。
结果比较: 在下表4中,展示了在基准数据集上进行微调的当前最先进方法的性能。同样,提供了有关方法类型、分辨率和额外依赖项的进一步细节。显然,基于扩散的方法相比传统的GAN和自回归Transformer方法具有显著优势。此外,如果有大规模的预训练或类别条件,性能往往会进一步提升。

视频编辑
随着扩散模型的发展,视频编辑领域的研究研究呈指数增长。根据许多研究的共识,视频编辑任务应满足以下标准:
-
保真度:每一帧都应在内容上与原始视频的相应帧保持一致;
-
对齐:生成的视频应与输入的控制信息对齐;
-
质量:生成的视频应在时间上保持一致且质量高。
虽然预训练的图像扩散模型可以通过逐帧处理来用于视频编辑,但跨帧的语义一致性不足使得逐帧编辑视频变得不可行,使视频编辑成为一项具有挑战性的任务。在这一部分,将视频编辑分为三个类别:文本引导视频编辑,模态引导视频编辑和领域特定视频编辑。视频编辑的分类细节总结在下图4中。

文本引导视频编辑
在文本引导视频编辑中,用户提供输入视频和描述所期望结果视频属性的文本提示。然而,与图像编辑不同,文本引导视频编辑带来了帧一致性和时间建模的新挑战。总体而言,有两种主要的基于文本的视频编辑方法:
-
在大规模文本视频配对数据集上训练T2V扩散模型;
-
将预训练的T2I扩散模型扩展到视频编辑; 由于大规模文本视频数据集难以获取且训练T2V模型计算成本高昂,后者更受关注。为了捕捉视频中的运动,向T2I模型引入了各种时间模块。然而,扩展T2I模型的方法存在两个关键问题:时间不一致,即编辑后的视频在帧间呈现视觉上的闪烁;语义差异,即视频未根据给定文本提示的语义进行更改。一些研究从不同角度解决了这些问题。
基于训练的方法
基于训练的方法是指在大规模文本-视频数据集上进行训练,使其成为一个通用的视频编辑模型。
「GEN-1」 提出了一种结构和内容感知的模型,该模型在时间、内容和结构一致性上提供了全面的控制。该模型引入了时间层到预训练的T2I模型中,并联合对图像和视频进行训练,实现了对时间一致性的实时控制。
「Dreamix」 的高保真度源于两个主要创新:使用原始视频的低分辨率版本初始化生成,并在原始视频上进行生成模型的微调。他们进一步提出了一种混合微调方法,具有完全的时间注意力和时间注意力屏蔽,显著提高了运动可编辑性。
「TCVE」 提出了一种Temporal U-Net,能有效捕捉输入视频的时间一致性。为了连接Temporal U-Net和预训练的T2I U-Net,作者引入了一个连贯的时空建模单元。
「Control-A-Video」 基于预训练的T2I扩散模型,集成了一个时空自注意模块和可训练的时间层。此外,他们提出了一种首帧调节策略(即基于第一帧生成视频序列),使Control-A-Video能够使用自回归方法生成任意长度的视频。与大多数同时在单一框架中建模外观和时间表示的方法不同,MagicEdit 创新地将内容、结构和运动的学习分离,以实现高保真度和时间一致性。
「MagicProp」视频编辑任务划分为外观编辑和运动感知外观传播,实现了时间一致性和编辑灵活性。他们首先从输入视频中选择一帧,并将其外观作为参考进行编辑。然后,他们使用图像扩散模型自回归生成目标帧,受其前一帧、目标深度和参考外观的控制。
无训练方法
无训练方法涉及利用预训练的T2I或T2V模型,并以zero-shot方式进行调整,以适应视频编辑任务。与基于训练的方法相比,无训练方法不需要昂贵的训练成本。然而,它们可能会遇到一些潜在的缺点。首先,在zero-shot方式编辑的视频可能会产生时空失真和不一致性。此外,使用T2V模型的方法可能仍然会产生高昂的训练和推理成本。作者简要检查用于解决这些问题的技术。
「TokenFlow」 展示了通过在扩散特征空间中强制实施一致性来实现编辑视频的一致性。具体而言,通过对关键帧进行采样,联合编辑它们,并基于原始视频特征提供的对应关系将特征传播到所有其他帧,从而明确地保持原始视频特征的一致性和细粒度共享表示。
「VidEdit」 结合了基于图谱的方法和预训练的T2I模型,既具有高时空一致性,又能在视频内容外观上提供对象级别的控制。该方法将视频分解为带有内容语义统一表示的分层神经图谱,然后应用预训练的、以文本驱动的图像扩散模型进行zero-shot图谱编辑。同时,通过在图谱空间中编码时空外观和空间位置来保持结构。
「Rerender-A-Video」 使用分层的跨帧约束来强制时空一致性。其关键思想是使用光流应用密集的跨帧约束,先前渲染的帧作为当前帧的低级参考,并首次渲染的帧作为锚点,以保持样式、形状、纹理和颜色的一致性。
「FateZero」 通过在反演过程的每个阶段存储全面的注意力图来解决图谱学习和每个视频调整的高昂成本问题,以保持卓越的运动和结构信息。此外,它还整合了时空块以增强视觉一致性。
「Vid2Vid-Zero」 利用一个null-text反演模块来将文本与视频对齐,一个空间正则化模块用于视频到视频的一致性,以及一个跨帧建模模块用于时态一致性。与FateZero 类似,它还包括一个时空注意模块。
「Pix2Video」 初始使用预训练的结构引导的T2I模型对锚定帧进行文本引导编辑,确保生成的图像保持对编辑提示的真实性。随后,他们使用自注意特征注入逐渐传播到未来帧的修改,保持时间一致性。
「InFusion」 由两个主要组件组成:首先,它将解码器层中的残差块和注意特征合并到编辑提示的去噪管道中,突出了其zero-shot编辑能力。其次,通过使用从交叉关注映射获得的掩码提取来合并已编辑和未编辑概念的关注,以确保一致性。
「」 直接采用ControlNet的体系结构和权重,通过完全跨帧交互扩展自注意力以实现高质量和一致性。为了管理长视频编辑任务,它实现了一个分层采样器,将长视频划分为短片段,并通过对关键帧对的条件进行全局一致性。
「EVE」 提出了两种策略来强化时态一致性:深度图引导,用于定位移动对象的空间布局和运动轨迹,以及帧对齐注意力,迫使模型同时关注先前帧和当前帧。
「MeDM」 利用明确的光流来建立跨视频帧的像素对应关系的实用编码,从而保持时态一致性。此外,他们使用从光流派生的提供的时态对应关系指导,迭代地对视频帧中的嘈杂像素进行对齐。
「Gen-L-Video」 通过将长视频视为时序重叠的短视频来探索长视频编辑。通过提出的时序协同去噪方法,它将现成的短视频编辑模型扩展到处理包含数百帧的编辑视频,同时保持一致性。
为了确保编辑后视频的所有帧之间的一致性,FLATTEN 将光流整合到扩散模型的注意机制中。提出的Flow-guided attention允许来自不同帧的补丁放置在注意模块内的相同流路径上,从而实现相互关注并增强视频编辑的一致性。
One-shot调整方法
使用特定视频实例对预训练的T2I模型进行微调,从而能够生成具有相似运动或内容的视频。虽然这需要额外的训练开销,但与无训练方法相比,这些方法提供了更大的编辑灵活性。
「SinFusion」 先驱性的one-shot调整扩散模型,可以从仅有的几帧中学习单个输入视频的运动。其骨干是一个完全卷积的DDPM网络,因此可以用于生成任何大小的图像。
「SAVE」 通过微调参数空间的谱偏移,使得学习输入视频的基本运动概念以及内容信息。此外,它提出了一个谱偏移正则化器来限制变化。
「Edit-A-Video」 包含两个阶段:第一阶段将预训练的T2I模型扩展到T2V模型,并使用单个<文本,视频>对进行微调,而第二阶段是传统的扩散和去噪过程。一个关键观察是编辑后的视频往往受到背景不一致性的影响。为了解决这个问题,他们提出了一种称为稀疏因果混合的屏蔽方法,该方法自动生成一个掩码来近似编辑区域。
「Tune-A-Video」 利用稀疏时空注意机制,该机制仅访问第一帧和前一帧视频,以及一种有效的调整策略,仅更新注意块中的投影矩阵。此外,它在推断时从输入视频中寻求结构引导,以弥补缺乏运动一致性的问题。
「Video-P2P」 不使用T2I模型,而是将其改变为文本到集合模型(T2S),通过用帧注意力替换自注意力,从而产生一个生成一组语义一致图像的模型。此外,他们使用了一种解耦引导策略,以提高对提示更改的鲁棒性。
「」 主要集中在改进扩散模型和ControlNet中的注意模块。他们将原始的空间自注意转化为关键帧注意,将所有帧与所选帧对齐。此外,他们还结合了时空注意模块以保持一致性。
「Shape-aware TLVE」 利用T2I模型,并通过在输入和编辑的关键帧之间传播变形场来处理形状变化。
「」 进行了两个关键创新:Shift-restricted Temporal Attention Module(STAM)用于限制时序注意力模块中引入的新参数,解决语义差异问题,以及Fine-coarse Frame Attention Module(FFAM)用于时序一致性,通过在空间维度上沿着时序维度采样来利用时序维度的信息。通过结合这些技术,他们创建了一个T2V扩散模型。
「StableVideo」 在现有的T2I模型和聚合网络之上设计了一个帧间传播机制,以从关键帧生成编辑后的图集,从而实现时空一致性。
其他模态引导的视频编辑
先前介绍的大多数方法都侧重于文本引导的视频编辑。在这一小节中,将重点关注由其他模态(例如,指令和声音)引导的视频编辑。
指令引导的视频编辑
指令引导的视频编辑旨在根据给定的输入视频和指令生成视频。由于缺乏视频-指令数据集,InstructVid2Vid 利用 ChatGPT、BLIP和 Tune-A-Video的联合使用以相对较低的成本获取输入视频、指令和编辑视频的三元组。在训练过程中,他们提出了帧差异损失(Frame Difference Loss),引导模型生成具有时间一致性的帧。CSD首先使用 Stein 变分梯度下降(SVGD),其中多个样本共享其从扩散模型中知识蒸馏,以实现样本间的一致性。然后,他们将协作分数蒸馏(CSD)与 Instruct-Pix2Pix 结合起来,实现具有指令的多图像的一致性编辑。
声音引导的视频编辑
声音引导的视频编辑旨在使视觉变化与目标区域的声音保持一致。为了实现这一目标,Soundini提出了局部声音引导和扩散采样的光流引导。具体而言,音频编码器使声音的潜在表示与潜在图像表示在语义上保持一致。基于扩散模型,SDVE引入了一个特征串联机制以实现时间上的一致性。他们通过在残差层中始终通过噪声信号提供频谱特征query来进一步在网络上进行语音条件化。
运动引导的视频编辑
受到视频编码过程的启发,VideoControlNet同时利用了扩散模型和ControlNet。该方法将第一帧设置为 I 帧,其余帧分为不同的图片组(GoP)。不同 GoP 的最后一帧被设置为 P 帧,而其他帧被设置为 B 帧。然后,对于给定的输入视频,模型首先基于输入的 I 帧直接使用扩散模型和ControlNet 生成 I 帧,然后通过运动引导的 P 帧生成模块(MgPG)生成 P 帧,其中利用了光流信息。最后,B 帧是基于参考 I/P 帧和运动信息插值而来,而不是使用耗时的扩散模型。
多模态视频编辑
「Make-A-Protagonist」 提出了一个多模态的条件视频编辑框架,用于更改主角。具体而言,他们利用BLIP-2进行视频字幕,使用CLIP Vision Model 和DALLE-2 Prior进行视觉和文本线索编码,以及使用ControlNet进行视频一致性。在推断过程中,他们提出了一个基于mask的去噪采样,结合专家实现无标注的视频编辑。 「CCEdit」 为可控创意视频编辑解耦了视频结构和外观。它使用基础的ControlNet保留视频结构,同时通过文本提示、个性化模型权重和定制中心帧进行外观编辑。此外,提出的时间一致性模块和插值模型可以无缝生成高帧率视频。
领域特定的视频编辑
在这一小节中,将简要概述为特定领域量身定制的几种视频编辑技术,从视频着色和视频风格转移方法开始,然后是为以人为中心的视频设计的几种视频编辑方法。
着色和重塑
「着色」 涉及为灰度帧推断合理且时间一致的颜色,这需要同时考虑时间、空间和语义的一致性以及颜色的丰富性和忠实度。基于预训练的T2I模型,ColorDiffuser提出了两种新颖的技术:Color Propagation Attention 作为光流的替代,以及Alternated Sampling Strategy 用于捕捉相邻帧之间的时空关系。 「重塑」 Style-A-Video 设计了一种综合的控制条件:用于样式指导的文本,用于内容指导的视频帧,以及用于详细指导的注意力图。值得注意的是,该工作具有zero-shot训练,即无需额外的每个视频训练或微调。
人类视频编辑
「Diffusion Video Autoencoders」 提出了一种扩散视频自动编码器,从给定的以人为中心的视频中提取单一的时间不变特征(ID)和每帧的时变特征(运动和背景),并进一步操纵单一的不变特征以获取所需的属性,从而实现了时间一致的编辑和高效计算。
「Instruct-Video2Avatar」 为了满足轻松创建高质量3D场景的不断增长的需求,Instruct-Video2Avatar采用了一种头部视频和编辑指令的方法,并输出了一个编辑过的3D神经头像。他们同时利用Instruct-Pix2Pix进行图像编辑,EbSynth进行视频样式化,以及INSTA用于照片逼真的3D神经头像。
「TGDM」 采用zero-shot训练的CLIP引导模型来实现灵活的情感控制。此外,他们提出了一个基于多条件扩散模型的pipeline,以实现复杂的纹理和身份转移。
视频理解
除了在生成任务中的应用,如视频生成和编辑,扩散模型还被应用于基本的视频理解任务,如视频时间分割,视频异常检测 ,文本-视频检索等,将在本节介绍。视频理解的分类详细信息总结下图中。

时间动作检测与分割
受到DiffusionDet的启发,DiffTAD探索了将扩散模型应用于时间动作检测任务。这涉及到对长视频的真实proposal进行扩散,随后学习去噪过程,通过在DETR架构中引入专门的时间位置query来完成。值得注意的是,该方法在ActivityNet和THUMOS等基准上取得了最先进的性能结果。
类似地,DiffAct采用了一种可比较的方法来解决时间动作分割任务,其中动作段从随机噪声中迭代生成,输入视频特征作为条件。该方法在广泛使用的基准数据集上进行了验证,包括GTEA,50Salads和Breakfast。
视频异常检测
专注于无监督视频异常检测,DiffVAD和CMR利用扩散模型的重构能力来识别异常视频,因为高重构误差通常表示异常。在两个大规模基准测试上进行的实验证明了这种范例的有效性,因此相比之前的研究显著提高了性能。 MoCoDAD专注于基于骨架的视频异常检测。该方法应用扩散模型生成基于个体过去动作的多样且合理的未来动作。通过对未来模式进行统计聚合,当生成的一组动作偏离实际未来趋势时,就会检测到异常。
文本-视频检索
DiffusionRet将检索任务构建为从噪声生成联合分布 p(candidates,query) 的逐步过程。在训练期间,生成器使用生成损失进行优化,而特征提取器则使用对比损失进行训练。通过这种方式,DiffusionRet巧妙地结合了生成和判别方法的优势,在开放领域场景中取得了出色的性能,展示了其泛化能力。
MomentDiff和DiffusionVMR解决了视频时刻检索任务,旨在识别与给定文本描述相对应的视频中的特定时间间隔。这两种方法将实际时间间隔扩展到随机噪声,并学会将随机噪声去噪回到原始时间间隔。这个过程使模型能够学习从任意随机位置到实际位置的映射,从而便于从随机初始化中精确定位视频片段。
视频字幕生成
RSFD研究了视频字幕生成中经常被忽视的长尾问题。它提出了一种新的Refined Semantic enhancement approach for Frequency Diffusion (RSFD),通过不断识别不常见token的语言表示来改善字幕生成。这使得模型能够理解低频token的语义,从而提高字幕生成的质量。
视频目标分割
Pix2Seq-D将全景分割重新定义为离散数据生成问题。它采用基于模拟位的扩散模型来建模全景掩码,利用灵活的架构和损失函数。此外,Pix2Seq-D可以通过整合先前帧的预测来建模视频,从而实现对象实例跟踪和视频对象分割的自动学习。
视频姿态估计
DiffPose通过将视频人体姿态估计问题制定为条件热力图生成任务来解决。在每个去噪步骤生成的特征的条件下,该方法引入了一个空间-时间表示学习器,该学习器聚合跨帧的视觉特征。此外,还提出了一种基于查找的多尺度特征交互机制,用于在局部关节和全局上下文之间创建多尺度的相关性。这种技术产生了关键点区域的精细表示。
音频-视频分离
DAVIS利用生成方法解决了音频-视觉声源分离任务。该模型利用扩散过程从高斯噪声中生成分离的幅度,条件是音频混合和视觉内容。由于其生成目标,DAVIS更适合实现跨不同类别的高质量声音分离。
动作识别
DDA专注于基于骨架的人体动作识别。该方法引入了基于扩散的数据增强,以获取高质量和多样的动作序列。它利用DDPMs生成合成的动作序列,生成过程由空间-时间Transformer准确引导。实验证明了这种方法在自然性和多样性指标方面的优越性。此外,它证实了将合成的高质量数据应用于现有动作识别模型的有效性。
视频声音跟踪器
LORIS专注于生成与视觉提示的节奏同步的音乐配乐。该系统利用潜在条件扩散概率模型进行波形合成。此外,它还结合了上下文感知的条件编码器,以考虑时间信息,促进长期波形生成。作者还扩展了模型的适用性,可以在各种体育场景中生成具有出色音乐质量和节奏对应性的长期音轨。
视频过程规划
PDPP专注于教学视频中的过程规划。该方法使用扩散模型描绘整个中间动作序列的分布,将规划问题转化为从该分布中进行采样的过程。此外,使用基于扩散的U-Net模型提供了基于初始和最终观察的准确条件指导,增强了对从学习的分布中采样的动作序列的学习。
挑战与未来趋势
尽管基于扩散的方法在视频生成、编辑和理解方面取得了显著进展,但仍存在一些值得探讨的开放问题。在本节中,总结了当前的挑战和潜在的未来方向。
「大规模视频文本数据集的收集」: 文本到图像合成取得的重大成就主要源于数十亿高质量(文本,图像)对的可用性。然而,用于文本到视频(T2V)任务的常用数据集相对较小,为视频内容收集同样庞大的数据集是一项相当具有挑战性的工作。例如,WebVid数据集仅包含1000万个实例,并且存在显著缺陷,即分辨率较低,仅为360P,进一步受到水印伪影的影响。尽管正在进行获取新数据集的方法的努力,但仍急需改进数据集规模、注释准确性和视频质量。
「高效的训练和推理」: T2V模型的大量训练成本是一个重大挑战,一些任务需要使用数百个GPU。尽管方法(例如SimDA)已经努力减轻训练费用,但数据集规模和时间复杂性的挑战仍然是一个关键问题。因此,研究更高效的模型训练和减少推理时间的策略是未来研究的有价值的方向。
「基准和评估方法」: 尽管存在用于开放域视频生成的基准和评估方法,但它们在范围上相对有限。由于在文本到视频(T2V)生成中缺乏生成视频的真实标准,现有的度量指标(例如Fréchet Video Distance(FVD)和Inception Score(IS))主要强调生成视频分布与真实视频分布之间的差异。这使得很难拥有一个全面评估指标,准确反映视频生成的质量。目前,相当依赖用户AB测试和主观评分,这是一项费时的工作,并可能因主观性而存在偏见。未来构建更贴合的评估基准和度量方法也是一条有意义的研究途径。
「模型容量不足」: 尽管现有方法取得了显著进展,但由于模型容量的限制,仍然存在许多局限性。例如,视频编辑方法在某些情况下往往会出现时间一致性失败,例如用动物替换人物。此外,观察到在前面讨论的大多数方法中,对象替换仅限于生成具有相似属性的输出。此外,为了追求高保真度,许多当前基于T2I的模型使用原始视频的关键帧。然而,由于现有图像生成模型的固有限制,尚未解决在保持结构和时间一致性的同时注入额外对象的问题。进一步的研究和增强是解决这些局限性的关键。
结论
本调查深入探讨了AIGC(AI生成内容)时代的最新发展,重点关注了视频扩散模型。据知,这是这类调查的首次尝试。全面概述了扩散过程的基本概念、流行的基准数据集和常用的评估方法。在此基础上,全面回顾了100多种关注视频生成、编辑和理解任务的作品,并根据它们的技术观点和研究目标进行了分类。此外,在实验部分,详细描述了实验设置,并在各种基准数据集上进行了公正的比较分析。最后,提出了视频扩散模型未来研究方向的几个建议。
参考文献:
[1]A Survey on Video Diffusion Models
链接:https://arxiv.org/pdf/2310.10647
更多精彩内容,请关注公众号:AI生成未来文章来源:https://www.toymoban.com/news/detail-786908.html
 文章来源地址https://www.toymoban.com/news/detail-786908.html
文章来源地址https://www.toymoban.com/news/detail-786908.html
到了这里,关于一文详解视频扩散模型的最新进展的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[论文精读] 使用扩散模型生成真实感视频 - 【李飞飞团队新作,文生视频 新基准】](https://imgs.yssmx.com/Uploads/2024/02/772295-1.png)





