之前我们已经讲过使用htmlunit及基础,没有看过的可以参考Java:爬虫htmlunit-CSDN博客
我们今天就来实际操作一下,爬取指定网站的数据
1、首先我们要爬取一个网站数据的时候我们需要对其数据获取方式我们要进行分析,我们今天就拿双色球历史开奖查询-双色球历史开奖结果-彩经网作为我们示例目标,使用google浏览器,示例仅供学习使用

历史数据比较多,所以存在分页的情况,请打开f12调出开发者模式
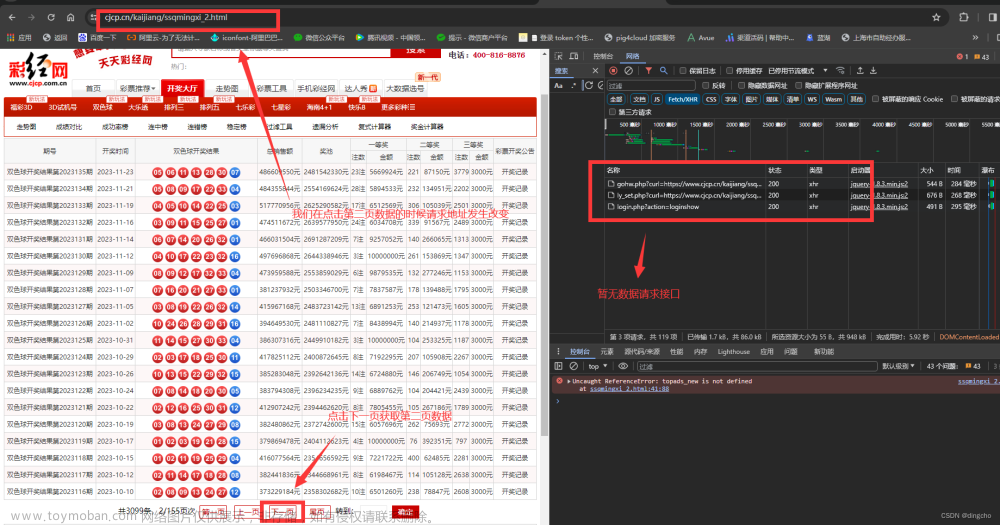
在使用网站过程中我们点击下一页的时候发现,请求接口已经做了路由跳转,在右侧请求地址中未发现数据接口,在上方发现地址变化了,为什么会这样呢?这个其实涉及到了搜索引擎收录的问题这个在后续我们会具体讲解;我们现在可以继续尝试点击下一页,地址都会变化所以我们直接根据地址来进行爬数据操作就可以了,地址确定之后我们就需要对页面数据进行分析

实际我们只要获取列表数据即可,第一行数据是头所不需要获取,即获取第二个 //tbody[@id='kjnum']//tr ,代码如下 >>>
@Slf4j
public class BaseTest {
public static void main(String[] args) throws Exception {
HtmlPage page = SpiderUtils.crawlPageWithoutAnalyseJs("https://www.cjcp.cn/kaijiang/ssqmingxi_154.html");
//System.err.println(page);
List<HtmlTableRow> htmlTableRowList = page.getByXPath("//tbody[@id='kjnum']//tr");
htmlTableRowList.forEach(f -> {
log.info("********************");
List<HtmlTableCell> htmlTableCellList = f.getCells();
log.info("开奖期数 >> " + htmlTableCellList.get(0).getTextContent());
log.info("开奖时间 >> " + htmlTableCellList.get(1).getTextContent());
log.info("双色球开奖结果 >> " + htmlTableCellList.get(2).getTextContent());
log.info("总销售额 >> " + htmlTableCellList.get(3).getTextContent());
log.info("奖池 >> " + htmlTableCellList.get(4).getTextContent());
log.info("一等奖 >> 注数 >> " + htmlTableCellList.get(5).getTextContent());
log.info("一等奖 >> 金额 >> " + htmlTableCellList.get(6).getTextContent());
log.info("二等奖 >> 注数 >> " + htmlTableCellList.get(7).getTextContent());
log.info("二等奖 >> 金额 >> " + htmlTableCellList.get(8).getTextContent());
log.info("三等奖 >> 注数 >> " + htmlTableCellList.get(9).getTextContent());
log.info("三等奖 >> 金额 >> " + htmlTableCellList.get(10).getTextContent());
log.info("********************");
});
}
}执行后,发现我们未获取到号码 >>>


通过对页面的分析,发现号码是图片形式所以我们要添加下获取方式 >>>
List<HtmlImage> htmlImageList = htmlTableCellList.get(2).getByXPath("div//img");
htmlImageList.forEach(htmlImage -> {
log.info(htmlImage.getAttribute("src"));
});这个时候我们再跑一下数据 >>> 这时候我们就可以看到已经正常获取数据
 注意:在此我们需要getByXPath中获取当前节点的根不能以"//"开始,"//为当前页面根目录搜索" 文章来源:https://www.toymoban.com/news/detail-794944.html
注意:在此我们需要getByXPath中获取当前节点的根不能以"//"开始,"//为当前页面根目录搜索" 文章来源:https://www.toymoban.com/news/detail-794944.html
当然大家对爬虫比较感兴趣,htmlunit还提供了其它获取页面元素的方法,具体我们可以参考HtmlTableRow 类 (System.Web.UI.HtmlControls) | Microsoft Learn文章来源地址https://www.toymoban.com/news/detail-794944.html
到了这里,关于Java:爬虫htmlunit实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








