这真的不是一个简单的过程,绕了不少弯路。
一、官方方法(知道就好,具体操作用不上这个)
1、Llama2 项目获取
方法1:有git可以直接克隆到本地
创建一个空文件夹然后鼠标右键,然后输入git clone https://github.com/facebookresearch/llama.git
方法2:直接下载
打开网站LLaMa git 官方,直接下载zip文件就行
2、LLama2 项目部署
这里在conda中创建一个虚拟环境conda create -n 环境名字 python=x.x
创建成功之后使用cd命令或者直接在LLaMa文件夹右键打开终端,输入
# 常规安装命令
pip install -e .
# 国内环境可以使用清华源加速
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
这一步目的是安装LLama2运行所需要的依赖
3、申请Llama2许可
要想使用Llama2,首先需要向meta公司申请使用许可,否则你将无法下载到Llama2的模型权重。填入对应信息(主要是邮箱)后,勾选页面最底部的 “I accept the terms and conditions”,点击 “Accept and Continue”,跳转到下图界面即可。
申请网站需要科学上网:Request access to the next version of Llama
然后对应的邮箱得到验证的链接,这个https://download.llamameta.net/*? 开头的一大串链接即为下面下载模型时需要验证的内容。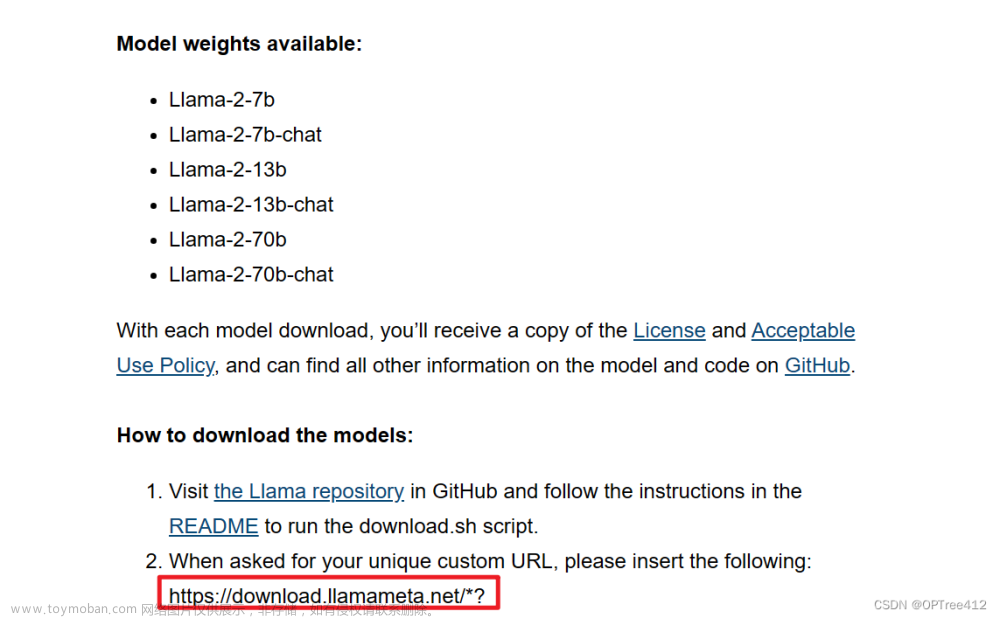
4、下载模型权重
在LLaMa文件夹中打开终端,运行download.sh文件。./download.sh
第一个输入邮件中给你的超长链接,第二个输入你需要的模型。
我是选择7B和7B-chat
5、运行
下载完成之后,就可以使用啦
# 句子补全
torchrun --nproc_per_node 1 example_text_completion.py \ --ckpt_dir llama-2-7b/ \ --tokenizer_path tokenizer.model \ --max_seq_len 128 --max_batch_size 4
# 对话生成
torchrun --nproc_per_node 1 example_chat_completion.py \ --ckpt_dir llama-2-7b-chat/ \ --tokenizer_path tokenizer.model \ --max_seq_len 512 --max_batch_size 4
命令的含义是
-
torchrun是一个PyTorch提供的用于分布式训练的命令行工具 -
--nproc_per_node 1这个选项指定在每个节点上使用1个GPU。意味着每个训练节点(可能是单个GPU或多个GPU)只使用一个GPU -
--ckpt_dir llama-2-7b/和--tokenizer_path tokenizer.model主要指定使用的模型和tokenizer的路径。这个可以在对应.py文件中写死入参避免重复指定。
二、Huggingface版LLaMa2(具体操作看这里!!)
1、提交申请方法(稍微麻烦)
使用Meta官方的huggingface版本的Llama2模型也需要向Meta公司申请验证链接(详见3、申请Llama2许可),此外还需使用申请账号登入huggingface官网,进入Meta Llama 2页面,同意用户协议后并递交申请,等待Meta公司的审核通过,大概2~3个小时或者一两天。
只有提交后,才能下载官方的huggingface版本的权重文件。
2、生成验证token(你有全局VPN的话可以用代码下载llama2模型权重,我没有)
为了在客户端上访问带有权限的huggingface模型,huggingface登陆后,我们需要在token生成界面生成一个token用于验证。
登录(没用过,一笔带过)
在客户端登录有两种方式,。一种是在命令行输入huggingface-cli login ,随后输入生成的token就好(这里和linux密码一样,不论输入还是粘贴都不显现的)。不过我实测下来这种方式总是不成功,可能和国内的网络环境有关系。
另一种方式则是在代码中登录,即使用huggingface_hub.login() 函数。
3、下载模型权重(是否含有-hf)
会注意到,官方的模型权重中有两种模型:一种有-hf和没有-hf的。
-hf后缀表示该模型来自Hugging Face。也就是说如果你在官方网址里面下载不含h-hf的模型权重,使用Hugging Face代码是运行不起来的。
如果你已经下载了官方的模型,也有办法变成-hf版本。
方法1:重新下载呗(但是还需要等待很久)
方法2:脚本处理(很快,但是要按照流程走)
此处以llama2-7B举例,需要严格按照如下流程进行操作。
- 使用这个脚本convert_llama_weights_to_hf.py,把这里的代码复制到自己电脑上
- 你的文件夹中应该有把params.json、consolidated.00.pth
和checklist.chk,把tokenizer_config.json、tokenizer.model和LICENSE.txt也放进去 - 把文件名改成7B(重要)
- 在对应的文件夹中打开终端运行这行命令
python 代码路径/convert_llama_weights_to_hf.py --input_dir llama模型所在路径/7B --model_size 7B --output_dir 输出的地址 - 等个几秒钟就会在输出路径中得到-hf版的权重了。
4、不用官方验证获取LLaMa权重(我没用过)
Tom Jobbins
这位老哥贡献出了好多模型的权重,我们就可以不用验证了。
在这里直接搜索llama2-7B就能找到模型了

细心的人可以看到模型后缀有GPTQ、GGUF、AWQ,这里大概介绍一下,详细的请看这里。
| 名称 | 解释 |
|---|---|
| GPTQ (Post-Training Quantization for GPT Models) | GPTQ是一种4位量化的训练后量化(PTQ)方法,主要关注GPU推理和性能。GPTQ是最常用的压缩方法,因为它针对GPU使用进行了优化。 |
| GGUF(Generated Unified Format) | 如果你的GPU无法处理如此大的模型,那么从GPTQ开始切换到以cpu为中心的方法(如GGUF)是绝对值得的。如果你想同时利用CPU和GPU, GGUF是一个非常好的格式。 |
| AWQ (Activation-aware Weight Quantization) | 它是一种类似于GPTQ的量化方法。在量化过程中会跳过一小部分权重,这有助于减轻量化损失。 |
5、测试是否安装成功
测试代码
import torch
import transformers
from transformers import LlamaForCausalLM, LlamaTokenizer
model_dir = r"./llama-2-7b-chat-hf" # 要么权重路径 要么meta-llama/Llama-2-7b-chat-hf(需要全局VPN下载)
model = LlamaForCausalLM.from_pretrained (model_dir) # 初始化模型
tokenizer = LlamaTokenizer.from_pretrained (model_dir) # 初始化tokenizer
# 使用模型
pipeline = transformers.pipeline (
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
# 获取结果
sequences = pipeline (
'I have tomatoes, basil and cheese at home. What can I cook for dinner?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=400,
)
# 输出结果
for seq in sequences:
print (f"{seq ['generated_text']}")
模型权重路径应该包括这些文件
输出的结果如下
三、搭建text-generation-webui
text-generation-webui是github上的一个开源项目,也是目前运行开源模型最广泛使用的软件之一。
1、创建虚拟空间
conda create -n textgen python=3.10.9 或者 3.11
conda activate textgen
2、安装依赖包
2.1 安装pytorch
这里注意python版本、CUDA版本和系统环境来下载pytorch,可以在这里下载离线文件安装。
2.2 下载项目
text-generation-webui
2.3 安装依赖包(重要!!)
可以先按照自己的环境,运行对应的脚本。比如我就运行start_linux.sh(先进入到textgen虚拟环境)。打开终端,然后输入./start_linux.sh。
这个过程会有两个问题,按照自己的情况进行回答即可。
但是运行这个脚本依旧有可能无法打开项目,那就需要查看requirements.txt了。
在text-generation-webui项目的文件夹中,打开终端,进入textgen虚拟环境中输入pip install -r requirements.txt
这一步没有全局VPN是十分痛苦的,有些依赖包无法下载。只能打开pip list把requirements.txt 没安装上的部分用局部VPN一点一点安装上。如果没有安装好的话,绝对没发成功运行项目,所以一定要仔细。
3、运行!!!
上面的步骤完成后,把自己下载的hugging face模型权重和token的文件放到项目中的models中,models中,models中。
然后执行下面的步骤:文章来源:https://www.toymoban.com/news/detail-798816.html
- 打开textgen虚拟环境
- 输入
python server.py --listen-host 0.0.0.0 --listen-port 7866 --listen #让本机可以访问,具体参数请见github 
完结撒❀!!!!!文章来源地址https://www.toymoban.com/news/detail-798816.html
到了这里,关于【部署LLaMa到自己的Linux服务器】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












