英文名称: From Complex to Simple: Unraveling the Cognitive Tree for Reasoning with Small Language Models
中文名称: 从复杂到简单:揭示小型语言模型推理的认知树
链接: http://arxiv.org/abs/2311.06754v1
代码: https://github.com/alibaba/EasyNLP
作者: Junbing Yan, Chengyu Wang, Taolin Zhang, Xiaofeng He, Jun Huang, Wei Zhang
机构: 华东师范大学计算机科学与技术学院, 阿里巴巴集团, 上海人工智能教育研究院期刊: EMNLP 2023日期: 2023-11-12
1 读后感
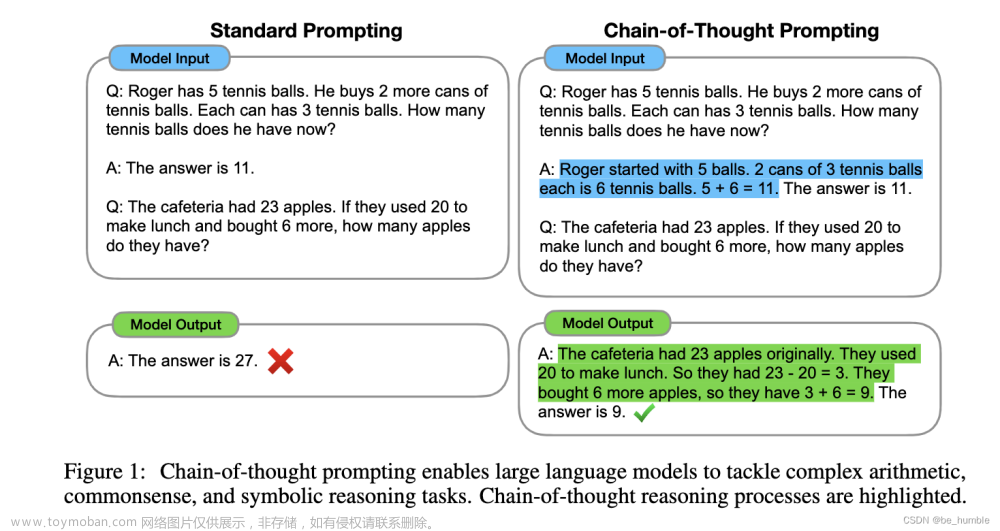
大语言模型的功能主要包括知识能力和思维能力;现在我们越来越多发现模型训练再好也不可能容纳世界知识,幻觉问题再所难免。研究也更多转向模型的思维和解决问题的能力。小模型因其可以本地部署速度快,便于精调,方便验证,成本低而更受关注。这篇论文主要研究如何提升小模型的推理能力。
文中提出了反思树 CogTree,希望通过对小模型的微调和一些附加技巧,替代大模型的推理能力。推理树的根节点表示初始查询,而叶节点则由可以直接回答的简单问题组成。通过两个系统迭代实现:直觉系统负责产生原始问题的多个分解假设,反思系统对直觉系统产生的假设进行验证,并选择更有可能的假设进行后续生成。通过上述双系统的迭代式生成,提升模型准确度。正文 9 页左右。
文中最喜欢的一句话,来自 1957 年,利昂•费斯廷格的《认知失调理论》
In cognitive theory, human decision-making behavior arises from the comparative analysis of various options (Festinger, 1957) 在认知理论中,人类的决策行为源于对各种选项的比较分析。
2 摘要
目标:提升轻量化大语言模型的认知推理能力。
方法:使用迭代方法构建认知树(CogTree),包括直觉系统回答问题和反思系统验证评价;分别利用轻量级大模型精调了两个系统。
结论:实验结果表明,使用比 GPT-3.5 小得多的 7B 语言模型,可以达到与 GPT-3.5 175B 相当的性能水平。
2.1 引言
在认知科学中,埃文斯提出双过程理论:大脑最初采用一种隐含的、无意识的、直观的过程,称为直觉系统,它检索相关信息;接下来用一个明确的、有意识的和可控的推理过程,称为反思系统进行判断;两者迭代进行思考过程。
论文面向轻量化大模型的复杂任务推理,使用较小规模的模型(7B),构建双系统生成推理树。基于人类的认知理论,通过两个系统来模仿人类产生认知的过程。直觉系统(Generation)利用上下文将复杂的问题分解为子问题,并生成对查询的响应。反思系统(Scores)评估直觉系统产生的结果,并选择最有可能的解决方案,为下一轮提供指导。
图 1:CogTree 框架示意图论文的主要贡献包含:
- 提出了问题分解范式,CogTree 框架
- 提升了模型的推理能力
- 证明了方法的有效性
图 2:直观系统和反思系统逐步产生数学推理问题的图示
3 认知树框架
数学和逻辑推理设置中,认知树 T 中的每个节点 n 代表逻辑集中的理论,或数学问题中子问题的解决方案。树的边 e 对应于对当前节点状态 s 的评估,可以是置信度分数或分类结果。
反思系统的辨别能力在提高模型的整体功效方面起着关键作用。文中利用交叉检查技术不仅验证中间结果的精确性,而且在完成推理过程后验证整个推理过程的准确性。为了增强模型评估能力,使用了比较强化方法。引入一个新的训练目标,最大化正确/错误/模棱两可的决策的表示之间的向量空间差异。
4 实现
4.1 直觉系统
直觉系统的生成能力是构建认知树的基础。选择仅包含 decoder-only 的模型(例如,GPT2-XL 或 LLaMA-7B)作为直觉系统。通过上下文方法来增强直觉系统的能力。
在逻辑推理问题的情况下,定义查询 Q,分解 D 将目标进一步分解为较小问题,分解集 Z 表示分解集合,最终采样 k 个可选项。
(下面两个图非常重要,一定要看一看)
图 -3 逻辑推理的查询和分解示例
图 -4 数学问题的查询和分解示例
4.2 反思系统
反思系统用于评估直觉系统的生成结果,确定其可接受性。反思系统采用两种方法来验证结果:中间过程的验证和整个推理链的验证。
当前状态分数:
总分数:
具体实现是:采用基于提示的方法并将其视为分类问题,模型输出三个类别之一:确定、不可能或可能,请参考图 2。
4.3 训练
4.3.1 直觉系统
直觉系统的目标是生成答案,使用监督微调 SFT 精调模型,直觉系统通过利用上下文示例将查询(即复杂问题)分解为子问题。在自回归期间,只对生成的文本计算损失。最大化似然函数:
4.3.2 反思系统
反思系统的目标是打分。由于人类的决策行为源于对各种选择的比较分析,因此采用对比学习方法来增强模型区分不同状态的能力,即最大化正样本和负样本在样本空间中的距离来学习正样本和负样本的表示。对比学习中负采样也非常重要,需要生成更具挑战的负样本。
对比学习的损失函数如下:
反思系统的全损耗函数:
5 算法精度评测
在 Entailment Bank 逻辑推理数据集以及 GSM8K 数学问题数据集上进行了测试。
将文中算法与其他基于大模型微调的方法进行对比:
表 3:测试集在准确性和相对改进方面的整体性能。文章来源:https://www.toymoban.com/news/detail-812277.html
结果表明,利用上下文训练的 GPT2-XL(1.5B,仅 ChatGPT 1%)优于 GPT-3.5(175B)。通过结合 CoT 和 ToT 增强方法,GPT-3.5 的准确率大幅提升,达到 92-93%。文中方法与反射系统相结合进行结果验证时,可以实现更高的性能(LLaMA-7B 为 94%),超过了 GPT-3.5 精调效果。文章来源地址https://www.toymoban.com/news/detail-812277.html
到了这里,关于论文阅读_CogTree_推理的认知树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!