前言
了解分片的基本原理,对Elasticsearch性能调优有帮助。
关系梳理
ES底层使用的是Lucene库,ES的分片(shard )是Lucene的索引,ES的索引是分片的集合,Lucene的索引是由多个段(segment)组成。

段(segment)
Per-segment search,也即按段搜索,是Lucene中的概念。每个段本身就是一个倒排索引,Lucene中的索引除了表示段的集合外,还增加了提交点的概念,一个提交点就是一个列出了所有已知段的文件。

Per-segment search的工作流程如下:
- 新的文档首先被写入内存区的索引缓存(buffer)。
- 不时,这些buffer被提交。
- 新段被打开,它包含的文档可以被检索。
- 内存的缓存被清除,等待接收新的文档。


提交
一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。ES在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
不可变性
写入磁盘的倒排索引是不可变的,也即段是不可改变的,所以既不能把文档从旧的段中移除,也不能修改旧的段来更新文档。取而代之的是,每个提交点会包含一个 .del 文件,它记录了段中被删除的文档。
当一个文档被 “删除” 时,它实际上只是在 .del 文件中被标记为删除。一个被标记为删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前从结果集中移除。
文档更新也是类似的操作方式:当一个文档被更新时,旧版本文档被标记为删除,文档的新版本被索引到一个新的段中。 可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前会被移除。
近实时搜索
提交一个新的段到磁盘需要调操作系统的fsync方法,确保段被物理地写入磁盘,即使断电也不会丢失数据。但是fsync是昂贵的,它不能在每个文档被索引时就触发。所以需要一种更轻量级的方式使新的文档可以被搜索。
位于ES和磁盘间的是文件系统缓存。在内存索引缓存中的文档被写入新的段,新的段首先写入文件系统缓存,这代价很低,之后会被同步到磁盘,这代价很大。一旦一个文件被缓存,它也可以被打开和读取,就像其他文件一样。


Refresh
在ES中,refresh是指这样一个过程:将In-memory buffer中的文档写入到文件系统缓存中新的段,新的段被打开(可被搜索)。默认情况下每个分片会每秒自动刷新一次。文档在In-memory buffer中是不能被搜索的,写入到段里面才能被搜索。这就是为什么我们说Elasticsearch是近实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
Flush
在ES中,进行一次提交并删除事务日志的操作叫做flush。一些老资料说ES每30分钟flush一次,或者事务日志过大也会flush。官网最新的说法是ES根据需要自动触发刷新,主要取决于事务日志的大小和权衡执行flush的成本。也可以调用flush API主动flush。
Translog
Translog全称transaction log(事务日志)。事务日志主要是为了防止在两次提交之间的数据丢失。事务日志也被用来提供实时 CRUD ,当你通过文档ID查询、更新、删除一个文档,在从相应的段检索之前, ES会首先检查事务日志最新的改动,这意味着ES总是能够通过文档ID实时地获取到文档的最新版本。
事务日志并不是实时落盘的,而是定期刷到磁盘。所以事务日志其实也是存在丢失的可能性的。那么这里就有一个问题,既然调用fsync的提交是一种昂贵的操作,为了防止数据丢失引入了事务日志,但是事务日志也需要刷到磁盘才能保证数据不丢,那事务日志的意义何在?答案是事务日志的刷盘更轻量级,因为它调用的是fdatasync这个系统函数,而不是fsync。感兴趣的朋友可以了解下fsync和fdatasync的差别。
完整流程
我们将上述知识点串起来得到完整流程。
- 当一个文档被索引,它被加入到内存缓存,同时写入事务日志。

- 分片每秒都进行refresh。refresh后,内存缓冲区的文档被写入到文件系统缓存;段被打开,使得新的文档可以被搜索;缓存被清除。

- 更多的文档加入到缓冲区,写入事务日志,这个过程会持续。
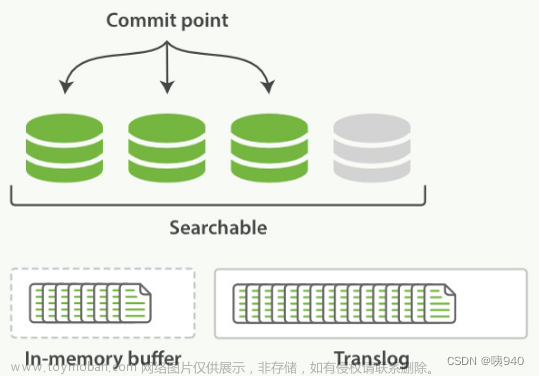
- 不时的,比如事务日志很大了,会进行一次全提交。内存缓冲区的所有文档会写入到新的段中;缓冲区被清空;一个提交点写入磁盘;文件系统缓存通过fsync操作flush到磁盘;事务日志被清除。
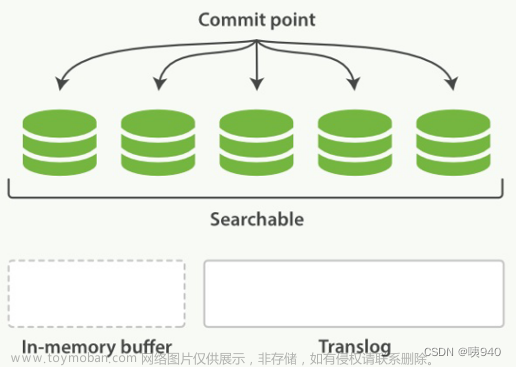
合并段
通过每秒自动刷新创建新的段,用不了多久段的数量就爆炸了。每个段都会消费文件句柄、内存、CPU资源。更重要的是,每次搜索请求都需要依次检查每个段。段越多,查询越慢。
ES通过后台合并段解决这个问题。小段被合并成大段,再合并成更大的段。合并段时会真正删除被标记为已删除的文档。旧的段不会再复制到更大的新段中。这个过程你不必做什么,当你在索引和搜索时ES会自动处理。这个过程不会中断索引和搜索。
两个提交的段和一个未提交的段合并为了一个更大的段。

这期间发生一系列操作:新的段flush到了硬盘;新的提交点写入新的段,排除旧的段;新的段打开供搜索;旧的段被删除。
 文章来源:https://www.toymoban.com/news/detail-813741.html
文章来源:https://www.toymoban.com/news/detail-813741.html
合并大的段会消耗很多IO和CPU,如果不合并又会影响到搜索性能。默认情况下,ES会限制合并过程,这样搜索就可以有足够的资源进行。optimize API可以强制合并段。文章来源地址https://www.toymoban.com/news/detail-813741.html
到了这里,关于深入理解Elasticsearch分片的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!