1 前言
ElasticSearch 是一个实时的分布式搜索与分析引擎,常用于大量非结构化数据的存储和快速检索场景,具有很强的扩展性。纵使其有诸多优点,在搜索领域远超关系型数据库,但依然存在与关系型数据库同样的深度分页问题,本文就此问题做一个实践性分析探讨
2 from + size 分页方式
from + size 分页方式是 ES 最基本的分页方式,类似于关系型数据库中的 limit 方式。from 参数表示:分页起始位置;size 参数表示:每页获取数据条数。例如:
GET /order/_search
{
"query": {
"match_all": {}
},
"from": 10,
"size": 20
}该条 DSL 语句表示从搜索结果中第 10 条数据位置开始,取之后的 20 条数据作为结果返回。这种分页方式在 ES 集群内部是如何执行的呢?
在 ES 中,搜索一般包括 2 个阶段,Query 阶段和 Fetch 阶段,Query 阶段主要确定要获取哪些 doc,也就是返回所要获取 doc 的 id 集合,Fetch 阶段主要通过 id 获取具体的 doc。
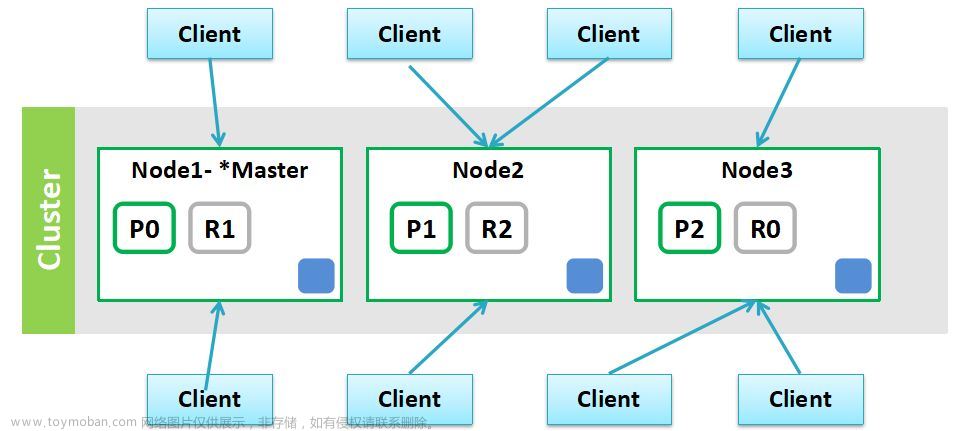
2.1 Query 阶段

如上图所示,Query 阶段大致分为 3 步:
-
第一步:Client 发送查询请求到 Server 端,Node1 接收到请求然后创建一个大小为 from + size 的优先级队列用来存放结果,此时 Node1 被称为 coordinating node(协调节点);
-
第二步:Node1 将请求广播到涉及的 shard 上,每个 shard 内部执行搜索请求,然后将执行结果存到自己内部的大小同样为 from+size 的优先级队列里;
-
第三步:每个 shard 将暂存的自身优先级队列里的结果返给 Node1,Node1 拿到所有 shard 返回的结果后,对结果进行一次合并,产生一个全局的优先级队列,存在 Node1 的优先级队列中。(如上图中,Node1 会拿到 (from + size) * 6 条数据,这些数据只包含 doc 的唯一标识_id 和用于排序的_score,然后 Node1 会对这些数据合并排序,选择前 from + size 条数据存到优先级队列);
-
2.2 Fetch 阶段

如上图所示,当 Query 阶段结束后立马进入 Fetch 阶段,Fetch 阶段也分为 3 步:
-
第一步:Node1 根据刚才合并后保存在优先级队列中的 from+size 条数据的 id 集合,发送请求到对应的 shard 上查询 doc 数据详情;
-
第二步:各 shard 接收到查询请求后,查询到对应的数据详情并返回为 Node1;(Node1 中的优先级队列中保存了 from + size 条数据的_id,但是在 Fetch 阶段并不需要取回所有数据,只需要取回从 from 到 from + size 之间的 size 条数据详情即可,这 size 条数据可能在同一个 shard 也可能在不同的 shard,因此 Node1 使用 multi-get 来提高性能)
-
第三步:Node1 获取到对应的分页数据后,返回给 Client;
2.3 ES 示例
依据上述我们对 from + size 分页方式两阶段的分析会发现,假如起始位置 from 或者页条数 size 特别大时,对于数据查询和 coordinating node 结果合并都是巨大的性能损耗。
例如:索引 wms_order_sku 有 1 亿数据,分 10 个 shard 存储,当一个请求的 from = 1000000, size = 10。在 Query 阶段,每个 shard 就需要返回 1000010 条数据的_id 和_score 信息,而 coordinating node 就需要接收 10 * 1000010 条数据,拿到这些数据后需要进行全局排序取到前 1000010 条数据的_id 集合保存到 coordinating node 的优先级队列中,后续在 Fetch 阶段再去获取那 10 条数据的详情返回给客户端。
分析:这个例子的执行过程中,在 Query 阶段会在每个 shard 上均有巨大的查询量,返回给 coordinating node 时需要执行大量数据的排序操作,并且保存到优先级队列的数据量也很大,占用大量节点机器内存资源。
2.4 小结
其实 ES 对结果窗口的返回数据有默认 10000 条的限制(参数:index.max_result_window = 10000),当 from + size 的条数大于 10000 条时 ES 提示可以通过 scroll 方式进行分页,非常不建议调大结果窗口参数值。
3 Scroll 分页方式
scroll 分页方式类似关系型数据库中的 cursor(游标),首次查询时会生成并缓存快照,返回给客户端快照读取的位置参数(scroll_id),后续每次请求都会通过 scroll_id 访问快照实现快速查询需要的数据,有效降低查询和存储的性能损耗。
3.1 执行过程
scroll 分页方式在 Query 阶段同样也是 coordinating node 广播查询请求,获取、合并、排序其他 shard 返回的数据_id 集合,不同的是 scroll 分页方式会将返回数据_id 的集合生成快照保存到 coordinating node 上。Fetch 阶段以游标的方式从生成的快照中获取 size 条数据的_id,并去其他 shard 获取数据详情返回给客户端,同时将下一次游标开始的位置标识_scroll_id 也返回。这样下次客户端发送获取下一页请求时带上 scroll_id 标识,coordinating node 会从 scroll_id 标记的位置获取接下来 size 条数据,同时再次返回新的游标位置标识 scroll_id,这样依次类推直到取完所有数据。
3.2 ES 示例
第一次查询时不需要传入_scroll_id,只要带上 scroll 的过期时间参数(scroll=1m)、每页大小(size)以及需要查询数据的自定义条件即可,查询后不仅会返回结果数据,还会返回_scroll_id。
GET /order/_search?scroll=1m
{
"query": {
"bool": {
"must": [
{
"range": {
"shipmentOrderCreateTime": {
"gte": "2021-10-04 00:00:00",
"lt": "2021-10-15 00:00:00"
}
}
}
]
}
},
"size": 20
}第二次查询时不需要指定索引,在 JSON 请求体中带上前一个查询返回的 scroll_id,同时传入 scroll 参数,指定刷新搜索结果的缓存时间(上一次查询缓存 1 分钟,本次查询会再次重置缓存时间为 1 分钟)
GET /_search/scroll
{
"scroll":"1m",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoIAAAAAJFQdUKFllGc2E4Y2tEUjR5VkpKbkNtdDFMNFEAAAACJj74YxZmSWhNM2tVbFRiaU9VcVpDUWpKSGlnAAAAAiY--F4WZkloTTNrVWxUYmlPVXFaQ1FqSkhpZwAAAAJMQKhIFmw2c1hwVFk1UXppbDhZcW1za2ZzdlEAAAACRUHVCxZZRnNhOGNrRFI0eVZKSm5DbXQxTDRRAAAAAkxAqEcWbDZzWHBUWTVRemlsOFlxbXNrZnN2UQAAAAImPvhdFmZJaE0za1VsVGJpT1VxWkNRakpIaWcAAAACJ-MhBhZOMmYzWVVMbFIzNkdnN1FwVXVHaEd3AAAAAifjIQgWTjJmM1lVTGxSMzZHZzdRcFV1R2hHdwAAAAIn4yEHFk4yZjNZVUxsUjM2R2c3UXBVdUdoR3cAAAACJ5db8xZxeW5NRXpHOFR0eVNBOHlOcXBGbWdRAAAAAifjIQkWTjJmM1lVTGxSMzZHZzdRcFV1R2hHdwAAAAJFQdUMFllGc2E4Y2tEUjR5VkpKbkNtdDFMNFEAAAACJj74YhZmSWhNM2tVbFRiaU9VcVpDUWpKSGlnAAAAAieXW_YWcXluTUV6RzhUdHlTQTh5TnFwRm1nUQAAAAInl1v0FnF5bk1Fekc4VHR5U0E4eU5xcEZtZ1EAAAACJ5db9RZxeW5NRXpHOFR0eVNBOHlOcXBGbWdRAAAAAkVB1Q0WWUZzYThja0RSNHlWSkpuQ210MUw0UQAAAAImPvhfFmZJaE0za1VsVGJpT1VxWkNRakpIaWcAAAACJ-MhChZOMmYzWVVMbFIzNkdnN1FwVXVHaEd3AAAAAkVB1REWWUZzYThja0RSNHlWSkpuQ210MUw0UQAAAAImPvhgFmZJaE0za1VsVGJpT1VxWkNRakpIaWcAAAACTECoShZsNnNYcFRZNVF6aWw4WXFtc2tmc3ZRAAAAAiY--GEWZkloTTNrVWxUYmlPVXFaQ1FqSkhpZwAAAAJFQdUOFllGc2E4Y2tEUjR5VkpKbkNtdDFMNFEAAAACRUHVEBZZRnNhOGNrRFI0eVZKSm5DbXQxTDRRAAAAAiY--GQWZkloTTNrVWxUYmlPVXFaQ1FqSkhpZwAAAAJFQdUPFllGc2E4Y2tEUjR5VkpKbkNtdDFMNFEAAAACJj74ZRZmSWhNM2tVbFRiaU9VcVpDUWpKSGlnAAAAAkxAqEkWbDZzWHBUWTVRemlsOFlxbXNrZnN2UQAAAAInl1v3FnF5bk1Fekc4VHR5U0E4eU5xcEZtZ1EAAAACTECoRhZsNnNYcFRZNVF6aWw4WXFtc2tmc3ZR"
}3.3 小结
scroll 分页方式的优点就是减少了查询和排序的次数,避免性能损耗。缺点就是只能实现上一页、下一页的翻页功能,不兼容通过页码查询数据的跳页,同时由于其在搜索初始化阶段会生成快照,后续数据的变化无法及时体现在查询结果,因此更加适合一次性批量查询或非实时数据的分页查询。
启用游标查询时,需要注意设定期望的过期时间(scroll = 1m),以降低维持游标查询窗口所需消耗的资源。注意这个过期时间每次查询都会重置刷新为 1 分钟,表示游标的闲置失效时间(第二次以后的查询必须带 scroll = 1m 参数才能实现)
4 Search After 分页方式
Search After 分页方式是 ES 5 新增的一种分页查询方式,其实现的思路同 Scroll 分页方式基本一致,通过记录上一次分页的位置标识,来进行下一次分页数据的查询。相比于 Scroll 分页方式,它的优点是可以实时体现数据的变化,解决了查询快照导致的查询结果延迟问题。
4.1 执行过程
Search After 方式也不支持跳页功能,每次查询一页数据。第一次每个 shard 返回一页数据(size 条),coordinating node 一共获取到 shard 数 * size 条数据 , 接下来 coordinating node 在内存中进行排序,取出前 size 条数据作为第一页搜索结果返回。当拉取第二页时,不同于 Scroll 分页方式,Search After 方式会找到第一页数据被拉取的最大值,作为第二页数据拉取的查询条件。
这样每个 shard 还是返回一页数据(size 条),coordinating node 获取到 shard 数 * size 条数据进行内存排序,取得前 size 条数据作为全局的第二页搜索结果。
后续分页查询以此类推…
4.2 ES 示例
第一次查询只传入排序字段和每页大小 size
GET /order/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"shipmentOrderCreateTime": {
"gte": "2021-10-12 00:00:00",
"lt": "2021-10-15 00:00:00"
}
}
}
]
}
},
"size": 20,
"sort": [
{
"_id": {
"order": "desc"
}
},{
"shipmentOrderCreateTime":{
"order": "desc"
}
}
]
}接下来每次查询时都带上本次查询的最后一条数据的 _id 和 shipmentOrderCreateTime 字段,循环往复就能够实现不断下一页的功能
GET /order/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"shipmentOrderCreateTime": {
"gte": "2021-10-12 00:00:00",
"lt": "2021-10-15 00:00:00"
}
}
}
]
}
},
"size": 20,
"sort": [
{
"_id": {
"order": "desc"
}
},{
"shipmentOrderCreateTime":{
"order": "desc"
}
}
],
"search_after": ["SO-460_152-1447931043809128448-100017918838",1634077436000]
}4.3 小结
Search After 分页方式采用记录作为游标,因此 Search After 要求 doc 中至少有一条全局唯一变量(示例中使用_id 和时间戳,实际上_id 已经是全局唯一)。Search After 方式是无状态的分页查询,因此数据的变更能够及时的反映在查询结果中,避免了 Scroll 分页方式无法获取最新数据变更的缺点。同时 Search After 不用维护 scroll_id 和快照,因此也节约大量资源。
5 总结思考
5.1 ES 三种分页方式对比总结

- 如果数据量小(from+size 在 10000 条内),或者只关注结果集的 TopN 数据,可以使用 from/size 分页,简单粗暴
- 数据量大,深度翻页,后台批处理任务(数据迁移)之类的任务,使用 scroll 方式
- 数据量大,深度翻页,用户实时、高并发查询需求,使用 search after 方式
5.2 个人思考
-
在一般业务查询页面中,大多情况都是 10-20 条数据为一页,10000 条数据也就是 500-1000 页。正常情况下,对于用户来说,有极少需求翻到比较靠后的页码来查看数据,更多的是通过查询条件框定一部分数据查看其详情。因此在业务需求敲定初期,可以同业务人员商定 1w 条数据的限定,超过 1w 条的情况可以借助导出数据到 Excel 表,在 Excel 表中做具体的操作。
-
如果给导出中心返回大量数据的场景可以使用 Scroll 或 Search After 分页方式,相比之下最好使用 Search After 方式,既可以保证数据的实时性,也具有很高的搜索性能。
-
总之,在使用 ES 时一定要避免深度分页问题,要在跳页功能实现和 ES 性能、资源之间做一个取舍。必要时也可以调大 max_result_window 参数,原则上不建议这么做,因为 1w 条以内 ES 基本能保持很不错的性能,超过这个范围深度分页相当耗时、耗资源,因此谨慎选择此方式。文章来源:https://www.toymoban.com/news/detail-817457.html
以上为全部内容。文章来源地址https://www.toymoban.com/news/detail-817457.html
到了这里,关于ElasticSearch(ES)深度分页详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!