目录
JanusGraph介绍
JanusGraph 的主要优势
JanusGraph的应用:
JanusGraph 的行业应用:
架构概览
分布式技术应用
横向扩展能力
程序与janus的交互
Janus与图数据库相关概念
结构化存储
图结构存储
实体关系存储
知识存储技术
JanusGraph介绍
JanusGraph 是一个开源的、分布式的、基于属性图的数据库,由 Apache TinkerPop 社区开发。它支持 Apache Cassandra 和 Apache HBase 作为存储后端,并提供原生支持 Gremlin 图遍历语言。
JanusGraph 的主要优势
- 支持非常大的图。JanusGraph 图可以随着集群中机器的数量而扩展。
- 支持非常多的并发事务和操作性图处理。JanusGraph 的事务容量随着集群中机器的数量而扩展,并能够在毫秒内回答复杂的遍历查询。
- 支持全球图分析和批量图处理通过 Hadoop 框架。
- 支持地理、数值范围和全文搜索对于非常大的图中的顶点和边。
- 原生支持 Apache TinkerPop 提供的流行的属性图数据模型。
- 原生支持 Gremlin 图遍历语言。
- 众多图级别配置可用于调整性能。
- 顶点中心索引提供顶点级查询,以缓解臭名昭著的超节点问题。
- 提供优化的磁盘表示,以允许有效地使用存储和访问速度。
JanusGraph 的应用
- 社交网络
- 推荐系统
- 知识图谱
- 机器学习
- 数据挖掘
JanusGraph 的行业应用
- 腾讯使用 JanusGraph 来构建其社交网络图谱。
- 微软使用 JanusGraph 来构建其推荐系统。
- 美国国家航空航天局 (NASA) 使用 JanusGraph 来构建其知识图谱。
- 谷歌使用 JanusGraph 来进行机器学习和数据挖掘。
参考文档:JanusGraph
架构概览
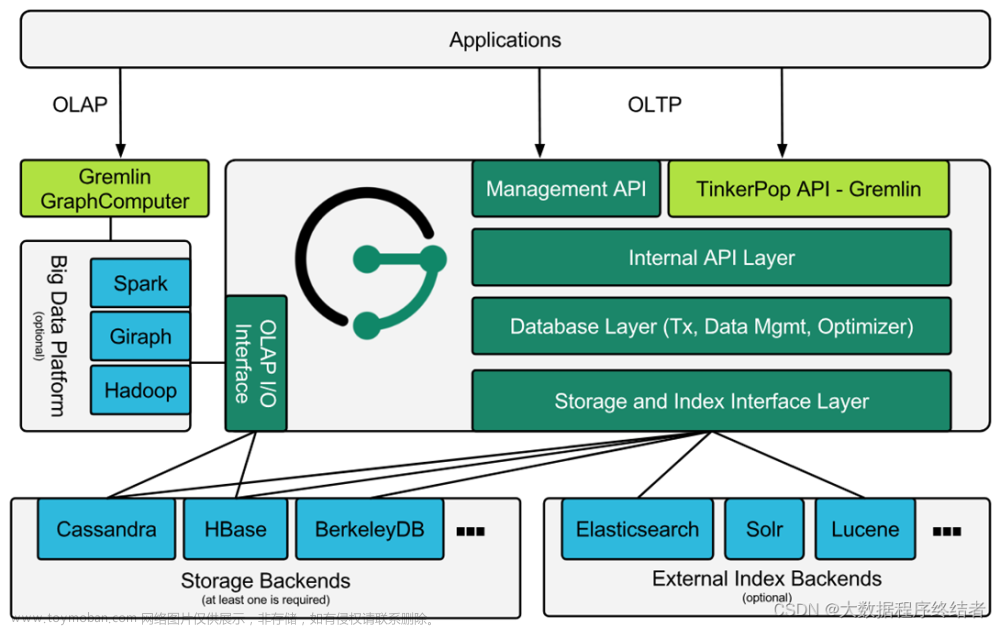
JanusGraph 架构可以利用分布式技术和横向扩展能力实现高性能的图数据库操作。它专注于紧凑的图序列化、丰富的图数据建模和高效的查询执行。JanusGraph可以利用Spark进行图分析和批处理图处理构建。JanusGraph实现了强大、模块化的接口,用于数据持久化、数据索引和客户端访问。JanusGraph的模块化架构使其能够与各种存储、索引和客户端技术进行交互;它还简化了扩展JanusGraph以支持新技术的过程。
分布式技术应用

Spark支持: JanusGraph 利用 Spark进行图分析和批处理图处理。Spark提供了分布式存储和处理大规模数据的能力,使 JanusGraph 能够有效地处理大规模图数据。
HBase作为存储后端: JanusGraph 的数据存储可以选择使用 HBase,这是一个分布式、面向列的 NoSQL 数据库。HBase 提供高度可扩展性,能够处理大量的数据和高并发请求。JanusGraph 将实体数据分布式存储在多个节点上。每个节点负责存储一部分实体数据。PropertyKey 和 Vertex 都使用哈希算法进行分块。
横向扩展能力
数据存储适配器: JanusGraph 提供了多个数据存储适配器,其中包括 Apache Cassandra、Apache HBase 等。这些存储适配器允许在需要时横向扩展存储层,以处理不断增长的数据量。
索引适配器: JanusGraph 支持多个索引适配器,如 Elasticsearch、Apache Solr 等。通过选择适当的索引适配器,可以提高查询性能,并且这些适配器也可以横向扩展以处理更大规模的索引数据。
程序与janus的交互
将JanusGraph嵌入应用程序内,在同一JVM中直接执行Gremlin查询。查询执行、JanusGraph的缓存和事务处理都在与应用程序相同的JVM中进行,而从存储后端检索数据可能是本地的或远程的。
通过将Gremlin查询提交到服务器,与本地或远程的JanusGraph实例进行交互。JanusGraph本地支持Apache TinkerPop堆栈的Gremlin Server组件。
Janus与图数据库相关概念
图数据库基本特点
图数据库是源于欧拉和图理论的一种非关系型数据库,其基本特征是以"图"这种数据结构存储和查询数据。JanusGraph是一种典型的图数据库,具有以下特点:
1. 数据模型: 图数据库的数据模型主要以节点和关系(边)为基础,同时可以处理键值对。JanusGraph的数据模型支持灵活的图结构定义,包括顶点、边的标签以及属性的关联。
2. 关系查询: 图数据库通过节点和边的关系来存储和查询数据,能够迅速解决复杂的关系问题。相较于传统的关系型数据库,图数据库在处理多层关系挖掘分析方面有着质的优势。其查询速度快、操作简单,并能提供更为丰富的关系展现方式。
3. 底层数据存储: 图数据库底层数据存储能够支持数据的弹性增长,适合存储海量的图数据。JanusGraph支持多种存储适配器,如Apache Cassandra、Apache HBase等,保证了数据的稳定性和完整性。
4. 关系挖掘: 图数据库采用基于边的遍历方式进行关系挖掘,相较于传统数据库的实体遍历方式,更容易找出多对多关系和进行高阶关系的扩展。JanusGraph借助图领域的路径寻找和优化算法,支持高效的关系挖掘。
5. 属性图存储模型: 图数据库采用属性图的基础数据存储模型,将数据描述为点和边及它们的属性。JanusGraph支持横向扩展,可容纳数千亿个顶点和边,满足海量图数据的存储需求。
6. 功能特性: JanusGraph包含众多功能特性,如邻接表技术高效查询结构数据、高效查询或遍历关系数据、在线schema变更和并行在线数据更新、分布式架构、高可用和热备份、地理位置、数字范围和全文检索等。JanusGraph支持图查询语言Cypher或Gremlin,提供强大的图查询能力。
结构化存储
当使用 MySQL 和 PostgreSQL、Hive 来存储Janus知识图谱的知识内容时,可以根据知识结构的明确性和数据模型的复杂性选择合适的数据库引擎。以下是 MySQL 和 PostgreSQL 在存储知识图谱方面的简要介绍:
- MySQL:
1. 数据建模: 在 MySQL 中,可以通过建立多个表来表示知识图谱中的不同概念和实体。每个表对应于一个概念或实体,表中的字段表示该概念或实体的属性。例如,可以有一个表用于存储概念定义,另一个表用于存储属性定义,以及其他表用于存储实例数据。
2. 关系建立: 利用 MySQL 的外键和关联机制,可以在不同表之间建立清晰的关系。例如,概念表中的某个字段可以与属性表中的外键相对应,建立概念和属性之间的关系。这样,数据库就能够表示知识图谱中的关联关系。
3. SQL 查询: 使用 MySQL 的 SQL 查询语言,可以轻松进行复杂的查询,包括概念之间的关联、属性的筛选等。这为知识图谱的检索和分析提供了灵活性。
PostgreSQL:
1. 数据建模: PostgreSQL 与 MySQL 类似,可以通过建立多个表来存储知识图谱的知识内容。PostgreSQL 支持更复杂的数据类型和索引,使得更为灵活的数据建模成为可能。
2. JSONB 数据类型: 对于包含复杂结构的知识内容,可以使用 PostgreSQL 的 JSONB 数据类型。这使得可以存储包含嵌套关系的数据,适用于知识图谱中一些较为灵活的知识结构。
3. 全文搜索: PostgreSQL 提供了全文搜索功能,这对于知识图谱中的文本信息查询非常有用。例如,在知识图谱中进行全文搜索,查找包含特定关键词的实体。
图结构存储
图结构存储涉及两种典型的图结构定义:RDF模型和属性图模型。在这两种模型中,JanusGraph作为图数据库可以灵活适应不同的图结构存储需求。
- RDF模型:
RDF模型基于三元组的概念,表示为(s, p, o),即主语、谓语和宾语。对于基于RDF知识的三元组存储,关系数据库表的3列可以分别对应RDF知识三元组的主语、谓语和宾语,例如(实体,关系,实体)或者(实体,属性,属性值)。这种存储方式与传统的结构化数据存储方式兼容,通用性较好。JanusGraph作为支持RDF模型的图数据库,能够有效存储和查询基于三元组的知识结构。
属性图模型:
属性图模型由顶点、边、属性和标签组成,其中顶点和边可以带有标签。属性图的定义是5元组:𝑮 = (𝑽, 𝑬, 𝝆, 𝝀, 𝝈),其中𝑽是顶点的有限集合,𝑬是边的有限集合,𝝆将边关联到顶点对,𝝀为顶点或边赋予标签,𝝈为顶点或边关联属性。属性图模型更贴近实际场景,可以很好地描述业务逻辑。JanusGraph作为属性图数据库,支持灵活的图结构定义,包括顶点和边的标签,以及属性的关联。
实体关系存储
JanusGraph的存储适用于这两种图结构模型,可以根据需求选择RDF模型或属性图模型。同时,JanusGraph的扩展性和灵活性使其能够适应不同的存储内容和存储技术选型。 JanusGraph支持多种存储适配器,如Apache Cassandra、Apache HBase等,可以根据具体需求选择适合的存储技术。
JanusGraph 支持以实体为中心的存储和查询。在 JanusGraph 中,实体数据存储在 PropertyKey 和 Vertex 两个数据结构中。
PropertyKey 表示属性或关系,它包含以下属性:
- key: 属性或关系的名称。
- dataType: 属性或关系的数据类型。
- cardinality: 属性或关系的度量。
Vertex 表示实体,它包含以下属性:
- id: 实体的唯一标识符。
- label: 实体的标签。
- properties: 实体的属性。
PropertyKey 是 JanusGraph 中实体数据的基础。每个实体数据都由一个或多个 PropertyKey 组成。PropertyKey 的 key 属性表示属性或关系的名称,dataType 属性表示属性或关系的数据类型,cardinality 属性表示属性或关系的度量。
Vertex 表示实体。每个实体都包含一个 id 属性,表示实体的唯一标识符。Vertex 还可以包含一个或多个 label 属性,表示实体的标签。Vertex 的 properties 属性表示实体的属性。
JanusGraph 使用邻接表的方式存储实体数据。每个 Vertex 都包含一个 edges 属性,表示与该 Vertex 相关的边。edges 属性是一个 Map 类型的属性,其中键是边的 label,值是边的 Edge 对象。
Edge 表示边。Edge 包含以下属性:
- id: 边的唯一标识符。
- label: 边的标签。
- outVertexId: 边的源 Vertex 的 ID。
- inVertexId: 边的目标 Vertex 的 ID。
- properties: 边的属性。
Edge 的 outVertexId 属性表示边的源 Vertex 的 ID,inVertexId 属性表示边的目标 Vertex 的 ID。Edge 的 properties 属性表示边的属性。
总体而言,JanusGraph 的数据存储具有以下特点:
- 以实体为中心。
- 使用邻接表的方式存储。
- 通过分布式数据分块技术和冗余技术保证可扩展性。
知识存储技术

1. Gremlin API: JanusGraph引入了Apache TinkerPop Gremlin组件,通过Gremlin API提供了开源标准的图交互式查询语言接口。这允许用户使用通用的图查询语言来操作和查询JanusGraph中的图数据。
2. 图数据库连接: JanusGraph支持根据图数据库服务唯一标识等参数创建图数据库系统连接。这使得用户可以方便地连接到JanusGraph实例,进行数据操作和查询。
3. REST API: JanusGraph提供了REST API,包含了完整的图查询、修改、删除和管理接口。通过REST API,用户可以通过HTTP协议与JanusGraph进行通信,实现图数据库的各项操作。
4. Load Balancer支持: 通过Load Balancer,JanusGraph提供了多实例GraphServer的负荷分担。这增强了系统的可伸缩性和性能。
5. 图数据库核心引擎: JanusGraph包括了图数据库核心引擎,涵盖了数据管理、元数据管理、点、边及属性等。这为整个系统提供了基础的图数据操作和管理功能。
6. 后端存储和索引接口适配层: JanusGraph通过适配层提供了后端存储和索引的接口。这意味着JanusGraph可以与多种后端存储和索引系统集成,如Apache Cassandra、Apache HBase等。
7. 图数据访问管理: JanusGraph支持在图数据库中添加新的点,根据指定的点、关系类型和方向创建边。它还支持查询两点间的最短路径或完全路径,以及使用多种查询语言(包括Gremlin、Cypher、SQL)进行查询、删除、更新等操作。
8. 分布式KV存储: JanusGraph提供了分布式键值存储,能够处理海量的图数据存储需求。这使得JanusGraph适用于大规模、分布式的图数据库应用场景。
9. 搜索引擎: JanusGraph内置了搜索引擎,提供了二级索引,全文检索、模糊检索等能力。这使得用户能够更灵活地进行数据检索和查询。
10. 图管理: JanusGraph支持图实例的创建和删除。用户可以方便地管理图数据库中的不同实例,根据需要进行创建或删除操作。文章来源:https://www.toymoban.com/news/detail-819543.html
11. 图元数据管理: JanusGraph提供了图元数据管理功能,用户可以定义图实例的元数据信息,包括点、边及其属性。这使得用户能够更精细地控制图数据库中的数据结构。文章来源地址https://www.toymoban.com/news/detail-819543.html
到了这里,关于JanusGraph图数据库的应用以及知识图谱技术介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!