map
1 介绍
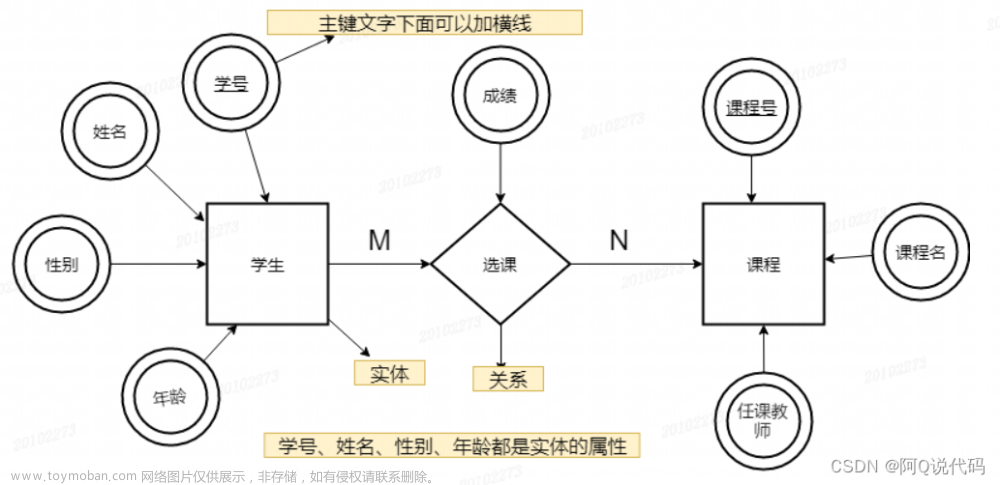
映射类似于函数的对应关系,每个x对应一个y,而map是每个键对应一个值。会python的朋友学习后就会知道这和python的字典非常类似。
比如说:学习 对应 看书,学习 是键,看书 是值。
学习->看书
玩耍 对应 打游戏,玩耍 是键,打游戏 是值。
玩耍->打游戏
Cpp
map特性:map会按照键的顺序从小到大自动排序,键的类型必须可以比较大小
2 函数方法
2.1 函数方法
| 代码 | 含义 |
|---|---|
mp.find(key ) |
返回键为key的映射的迭代器 O(logN) 注意:用find函数来定位数据出现位置,它返回一个迭代器。当数据存在时,返回数据所在位置的迭代器,数据不存在时,返回mp.end() |
mp.erase(it) |
删除迭代器 的键和值O(1) |
mp.erase(key) |
根据映射的键删除键和值 O(logN) |
mp.erase(first,last) |
删除左闭右开区间迭代器对应的键和值O(last−first) |
mp.size() |
返回映射的对数$ O(1)$ |
mp.clear() |
清空map中的所有元素O(N) |
mp.insert() |
插入元素,插入时要构造键值对 |
mp.empty() |
如果map为空,返回true,否则返回false |
mp.begin() |
返回指向map第一个元素的迭代器(地址) |
mp.end() |
返回指向map尾部的迭代器(最后一个元素的下一个地址) |
mp.rbegin() |
返回指向map最后一个元素的迭代器(地址) |
mp.rend() |
返回指向map第一个元素前面(上一个)的逆向迭代器(地址) |
mp.count(key) |
查看元素是否存在,因为map中键是唯一的,所以存在返回1,不存在返回0 |
mp.lower_bound() |
返回一个迭代器,指向键值>= key的第一个元素 |
mp.upper_bound() |
返回一个迭代器,指向键值> key的第一个元素 |
2.2 注意点
下面说明部分函数方法的注意点
注意:
查找元素是否存在时,可以使用
①mp.find()②mp.count()③mp[key]
但是第三种情况,如果不存在对应的key时,会自动创建一个键值对(产生一个额外的键值对空间)
所以为了不增加额外的空间负担,最好使用前两种方法
2.3 迭代器进行正反向遍历
-
mp.begin()和mp.end()用法:
用于正向遍历map
map<int,int> mp;
mp[1] = 2;
mp[2] = 3;
mp[3] = 4;
auto it = mp.begin();
while(it != mp.end()) {
cout << it->first << " " << it->second << "\n";
it ++;
}Cpp
结果:
1 2
2 3
3 4None
-
mp.rbegin()和mp.rend()
用于逆向遍历map
map<int,int> mp;
mp[1] = 2;
mp[2] = 3;
mp[3] = 4;
auto it = mp.rbegin();
while(it != mp.rend()) {
cout << it->first << " " << it->second << "\n";
it ++;
}Cpp
结果:
3 4
2 3
1 2None
2.4 二分查找
二分查找lower_bound() upper_bound()
map的二分查找以第一个元素(即键为准),对键进行二分查找
返回值为map迭代器类型
#include<bits/stdc++.h>
using namespace std;
int main() {
map<int, int> m{{1, 2}, {2, 2}, {1, 2}, {8, 2}, {6, 2}};//有序
map<int, int>::iterator it1 = m.lower_bound(2);
cout << it1->first << "\n";//it1->first=2
map<int, int>::iterator it2 = m.upper_bound(2);
cout << it2->first << "\n";//it2->first=6
return 0;
}
Cpp
3 添加元素
//先声明
map<string, string> mp;Cpp
- 方式一:
mp["学习"] = "看书";
mp["玩耍"] = "打游戏";Cpp
- 方式二:插入元素构造键值对
mp.insert(make_pair("vegetable","蔬菜"));Cpp
- 方式三:
mp.insert(pair<string,string>("fruit","水果"));Cpp
- 方式四:
mp.insert({"hahaha","wawawa"});Cpp
4 访问元素
4.1 下标访问
(大部分情况用于访问单个元素)
mp["菜哇菜"] = "强哇强";
cout << mp["菜哇菜"] << "\n";//只是简写的一个例子,程序并不完整Cpp
4.2 遍历访问
- 方式一:迭代器访问
map<string,string>::iterator it;
for(it = mp.begin(); it != mp.end(); it++) {
// 键 值
// it是结构体指针访问所以要用 -> 访问
cout << it->first << " " << it->second << "\n";
//*it是结构体变量 访问要用 . 访问
//cout<<(*it).first<<" "<<(*it).second;
}Cpp
- 方式二:智能指针访问
for(auto i : mp)
cout << i.first << " " << i.second << endl;//键,值Cpp
- 方式三:对指定单个元素访问
map<char,int>::iterator it = mp.find('a');
cout << it -> first << " " << it->second << "\n";Cpp
- 方式四:c++17特性才具有
for(auto [x, y] : mp)
cout << x << " " << y << "\n";
//x,y对应键和值Cpp
5 与unordered_map的比较
这里就不单开一个大目录讲unordered_map了,直接在map里面讲了。
5.1 内部实现原理
map:内部用红黑树实现,具有自动排序(按键从小到大)功能。
unordered_map:内部用哈希表实现,内部元素无序杂乱。
5.2 效率比较
map:
-
优点:内部用红黑树实现,内部元素具有有序性,查询删除等操作复杂度为O(logN)
-
缺点:占用空间,红黑树里每个节点需要保存父子节点和红黑性质等信息,空间占用较大。
unordered_map:
- 优点:内部用哈希表实现,查找速度非常快(适用于大量的查询操作)。
- 缺点:建立哈希表比较耗时。
两者方法函数基本一样,差别不大。
注意:
随着内部元素越来越多,两种容器的插入删除查询操作的时间都会逐渐变大,效率逐渐变低。
使用
[]查找元素时,如果元素不存在,两种容器都是创建一个空的元素;如果存在,会正常索引对应的值。所以如果查询过多的不存在的元素值,容器内部会创建大量的空的键值对,后续查询创建删除效率会大大降低。查询容器内部元素的最优方法是:先判断存在与否,再索引对应值(适用于这两种容器)
// 以 map 为例 map<int, int> mp; int x = 999999999; if(mp.count(x)) // 此处判断是否存在x这个键 cout << mp[x] << "\n"; // 只有存在才会索引对应的值,避免不存在x时多余空元素的创建Cpp
另外:
还有一种映射:
multimap键可以重复,即一个键对应多个值,如要了解,可以自行搜索
例题
P5266 【深基17.例6】学籍管理 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
要设计一个学籍管理系统,最开始学籍数据是空的,然后该系统能够支持下面的操作(不超过 105105 条):
- 插入与修改,格式
1 NAME SCORE:在系统中插入姓名为 NAME(由字母和数字组成不超过 20 个字符的字符串,区分大小写) ,分数为 SCORESCORE(0<SCORE<2310<SCORE<231) 的学生。如果已经有同名的学生则更新这名学生的成绩为 SCORE。如果成功插入或者修改则输出OK。 - 查询,格式
2 NAME:在系统中查询姓名为 NAME 的学生的成绩。如果没能找到这名学生则输出Not found,否则输出该生成绩。 - 删除,格式
3 NAME:在系统中删除姓名为 NAME 的学生信息。如果没能找到这名学生则输出Not found,否则输出Deleted successfully。 - 汇总,格式
4:输出系统中学生数量。
输入格式
无
输出格式
无
输入输出样例
输入 #1文章来源:https://www.toymoban.com/news/detail-828024.html
5 1 lxl 10 2 lxl 3 lxl 2 lxl 4
输出 #1文章来源地址https://www.toymoban.com/news/detail-828024.html
OK 10 Deleted successfully Not found 0
解决代码
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
map<string, long long> a;
int key, i = 1;
cin >> i;
string name;
long long score;
while (i--) {
cin >> key;
switch (key) {
case 1:
cin >> name >> score;
a[name] = score;
cout << "OK" << endl;
break;
case 2:
cin >> name;
if (a.count(name)) {
cout << a[name] << endl;
} else {
cout << "Not found" << endl;
}
break;
case 3:
cin >> name;
if (a.find(name) != a.end()) {
a.erase(name);
cout << "Deleted successfully" << endl;
} else {
cout << "Not found" << endl;
}
break;
case 4:
cout << a.size() << endl;
break;
}
}
return 0;
}
到了这里,关于数据结构map的基本知识与用法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!