在PostgreSQL中,实现自动创建分区表主要依赖于表的分区功能,这一功能从PostgreSQL 10开始引入。分区表可以帮助管理大量数据,通过分布数据到不同的分区来提高查询效率和数据维护的便捷性。以下是在PostgreSQL中自动创建分区表的一般步骤:
1. 创建分区表
首先,你需要创建一个父表,定义好你的表结构。这个父表将作为所有分区的模板。
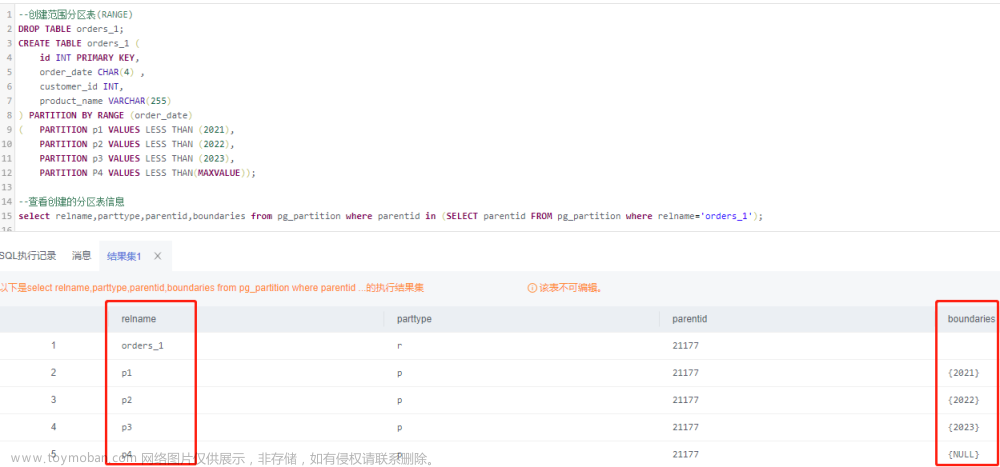
CREATE TABLE test (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);在这个例子中,test表被定义为一个分区表,分区策略是按照logdate字段的范围来分区。
2. 创建分区
然后,你可以为父表创建具体的分区。每个分区都是一个独立的表,但它们都继承自父表的结构。
CREATE TABLE test_y2024m01 PARTITION OF test
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
CREATE TABLE test_y2024m02 PARTITION OF test
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');这些分区表会自动继承test表的结构,并根据logdate字段的值来存储数据。
3. 自动创建分区
尽管PostgreSQL不直接支持自动创建新分区,但你可以通过定时作业或触发器来自动化这个过程。以下是一个触发器函数的示例,该函数在插入数据时检查相应的分区是否存在,如果不存在,则创建它:
CREATE OR REPLACE FUNCTION create_partition_and_insert()
RETURNS TRIGGER AS $$
BEGIN
-- 替换为动态生成分区名和分区范围的逻辑
IF NEW.logdate >= '2024-01-01' AND NEW.logdate < '2024-02-01' THEN
CREATE TABLE IF NOT EXISTS test_y2024m01 PARTITION OF test
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
RETURN NEW;
ELSIF NEW.logdate >= '2024-02-01' AND NEW.logdate < '2024-03-01' THEN
CREATE TABLE IF NOT EXISTS test_y2024m02 PARTITION OF test
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');
RETURN NEW;
-- 添加更多条件以处理其他时间段
ELSE
RAISE EXCEPTION 'Date out of range. No partition available for %', NEW.logdate;
END IF;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER insert_test_partition
AFTER INSERT
ON public.test
FOR EACH ROW
EXECUTE FUNCTION public.create_partition_and_insert();最终创建表如图:


注意,需要根据你的实际情况进行调整。特别是,你需要修改函数内的条件来匹配你的分区策略和时间范围。
4. 注意事项:
触发器的使用可能会略微减慢插入操作的速度,因为每次插入时都需要运行额外的逻辑。
确保分区键的范围与你的数据插入模式相匹配,以避免频繁地创建和维护大量的分区。
定期检查和维护分区策略,确保数据均衡分布在各个分区中。
通过以上方法,你可以实现PostgreSQL中分区表日期字段的自动创建和维护。
总结
自动创建分区可以帮助你管理大型的数据集,使得数据更加易于管理和查询。通过使用触发器,你可以减少手动创建分区的需求,从而使数据管理过程更加自动化和高效。然而,自动化分区管理需要仔细设计,确保触发器和定时任务的逻辑与你的业务需求和数据增长模式相匹配。还有一个重要的注意点是,自动化创建分区的策略和逻辑应该与你的实际数据使用模式密切匹配。如果你的数据有非常特定的增长模式,例如,如果数据主要是基于时间序列增长的,则你的分区策略很明确,并且你的自动化脚本应该能够预测并创建相应时间段的分区。
此外,在实施自动分区方案之前,确保对数据库性能进行基准测试,以了解触发器可能对数据库性能产生的影响。对于高频更新的数据库,触发器可能会导致性能下降。在这种情况下,可能更适合使用定时任务在低峰时段提前创建分区。文章来源:https://www.toymoban.com/news/detail-831612.html
最后,保持分区表的维护和监控,确保分区大小保持合理,避免单个分区过大,从而失去分区的优势。同时,定期回顾和调整分区策略,以适应数据增长和变化的业务需求。文章来源地址https://www.toymoban.com/news/detail-831612.html
到了这里,关于PostgreSQL按日期列创建分区表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!