Apache Doris是一款开源的实时数据仓库,由百度旗下的技术团队开发。它具有高性能、高可靠性、易扩展等特点,能够满足大规模数据实时查询和分析的需求。目前,Apache Doris已经成为国内外众多企业的首选数据仓库解决方案,包括阿里巴巴、美团、京东、滴滴等知名企业。
作为被众多大型互联网企业广泛采用的实时数据仓库,Doris拥有一些核心优势和独特的特点。我们从它的架构设计和使用场景来看一下这些优势。
01—架构上的优势
Doris在架构上通过分布式存储和计算、实时计算引擎、数据治理和质量控制、多维度数据分析以及可视化展示等方面的优势,能够为用户提供强大的支持,满足实时数据仓库的需求。
Doris在架构上具有以下优势:
1、统一数仓架构:一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Kudu、Hbase、Phoenix 组成的旧架构,架构大大简化。
2、数据湖联邦查询:通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
3、分布式存储和计算架构:Doris采用了分布式存储和计算的架构,可以将数据分散存储在多个节点上,实现数据的分布式处理和高可扩展性。这使得Doris能够处理大规模的数据集,并提供更高的性能和可靠性。
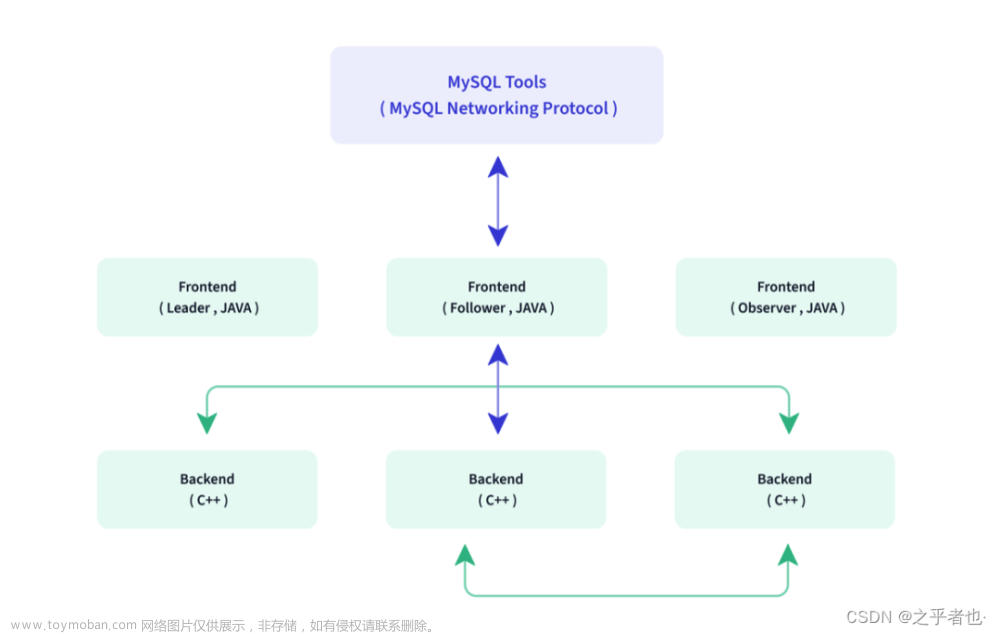
Doris整体架构如下图所示,Doris 架构非常简单,只有两类进程:
-
Frontend(FE),主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
-
Backend(BE),主要负责数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。
4、实时计算引擎:Doris内置了实时计算引擎,能够实时处理和分析数据,满足实时数据查询和分析的需求。即席查询(Ad-hoc Query),面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
5、支持高并发的查询:比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
6、数据管理和权限系统:Doris提供了元数据管理功能和权限管理功能。有Doris 新的权限管理系统参照了 Mysql 的权限管理机制,做到了行级别细粒度的权限控制,基于角色的权限访问控制,并且支持白名单机制。下图是 Doris 元信息所存储的内容。
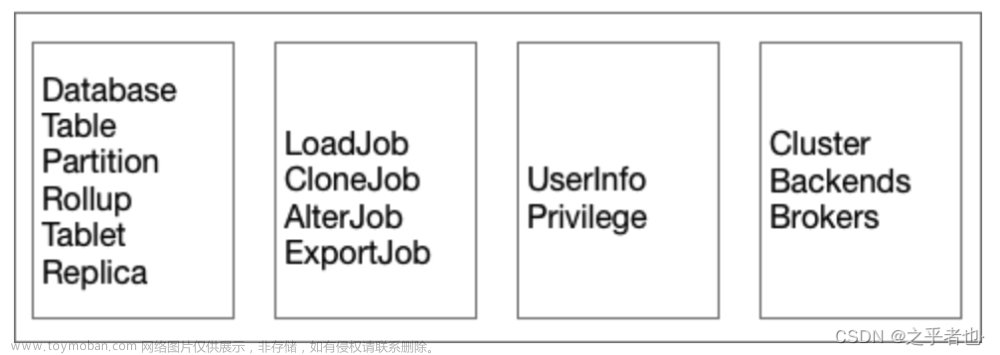
如上图,Doris 的元数据主要存储4类数据:
1、用户数据信息。包括数据库、表的 Schema、分片信息等。
2、各类作业信息。如导入作业,Clone 作业、SchemaChange 作业等。
3、用户及权限信息。
4、集群及节点信息。
多维度数据分析:Doris支持多维度数据分析,可以对数据进行灵活的切片和聚合,提供丰富的数据分析功能。通过Doris,用户可以从多个维度的角度进行数据探索和分析,发现数据中的隐藏关联和趋势。
弹性扩容:Doris 可以很方便的扩容和缩容 FE、BE、Broker 实例。FE是管理节点,BE是存储节点和计算节点。
负载均衡:当部署多个 FE 节点时,用户可以在多个 FE 之上部署负载均衡层来实现 Doris 的高可用。但是需要用户在多个 FE 上架设一层 proxy,来实现自动的连接负载均衡。ProxySQL是灵活强大的MySQL代理层, 是一个能实实在在用在生产环境的MySQL中间件,可以实现读写分离,支持 Query 路由功能,支持动态指定某个 SQL 进行 cache,支持动态加载配置、故障切换和一些 SQL的过滤功能。
02—应用场景上的优势
Doris 之所以被比较多的人使用,Doris在具体应用场景上进行了深入的功能优化,通过提供更丰富的功能和易用性,减少了用户编写额外代码的需求,并简化了与其他组件的集成。进而也进一步简化系统的技术架构,让架构更加单一。
以下是常见的一些优化:
一、不同应用场景的数据模型创建方式
Doris 支持聚合模型,Unique 模型、明细模型,这三种模型主要是面对不同应用场景,聚合模型是进入数据仓库的数据需要进行聚合的,比如sum,replace、MAX、MIN等操作;Unique 模型 是用来不需要进行聚合的场景,例如在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。而明细模型则许多数据仓库提供最普通的数据模型的建模方式。因此Doris 建模是对于多维分析的不同场景提供更加优化的建模功能以应对不同的使用场景。
二、不同应用场景的数据索引创建方式
Doris作为实时数据仓库,支持多种类型的索引,每种索引都有不同的应用场景。以下是几种常见的索引类型和相应的应用场景:
1、倒排索引(inverted index):可以用来进行文本类型的全文检索、普通数值日期类型的等值范围查询,快速从海量数据中过滤出满足条件的行。
2、Bitmap过滤索引(BloomFilter):通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
3、唯一索引(Unique Index):适用于需要保证某个字段的唯一性的场景,比如用户ID、订单号等唯一标识。
4、主键索引(Primary Key Index):适用于需要在表中快速查找某一行数据的场景。
5、聚簇索引(Clustering Index):适用于根据某个字段进行数据聚集和排序的场景,可以提高多种查询的性能。
6、非聚簇索引(Non-Clustering Index):适用于需要通过非聚簇字段进行查询的场景,可以加快查询速度。
7、全文索引(Full-Text Index):适用于需要进行全文搜索的场景,比如文章内容、产品描述等。
8、空间索引(Spatial Index):适用于需要对地理位置进行快速查询的场景,比如地理信息系统、GPS轨迹等。
9、Bitmap索引(Bitmap Index):适用于高基数列(Cardinality)的查询,比如男性/女性分类、标签等。
根据具体的业务需求和数据特点,选择合适的索引类型可以提升查询性能和数据管理效率。
三、不同应用场景的数据导入导出操作
Doris支持按照不同的应用场景对数据进行导入和导出操作。下面是一些常见的数据导入导出操作:
1、批量导入:Doris支持通过批量导入的方式,将大量数据一次性导入到数据仓库中。可以使用Stream Load 用于将本地文件导入到 Doris 中或者通过MySql LOAD语句将数据导入。
2、外部存储系统导入:例如(HDFS,所有支持S3协议的对象存储)
3、实时数据流入:Doris支持实时数据流入的方式,可以通过订阅 Kafka 日志
实时数据导入到Doris中。这样可以实现数据的实时更新和分析。
4、Doris 可以创建外部表。创建完成后,可以通过 SELECT 语句直接查询外部表的数据,也可以通过 INSERT INTO SELECT 的方式导入外部表的数据。
Doris 外部表目前支持的数据源包括:MySQL、Oracle、PostgreSQL、SQLServer、Hive 、Iceberg、ElasticSearch。
Doris 中的所有导入操作都有原子性保证,即一个导入作业中的数据要么全部成功,要么全部失败。不会出现仅部分数据导入成功的情况。
5、异步导出(Export):异步导出(Export)是 Doris 提供的一种将数据异步导出的功能。该功能可以将用户指定的表或分区的数据,以指定的文件格式,通过 Broker 进程或 S3协议/HDFS协议 导出到远端存储上,如 对象存储 / HDFS 等。
6、导出查询结果集:使用 SELECT INTO OUTFILE 命令进行查询结果的导出操作。
7、MYSQLDUMP 导出表结构或数据:支持通过mysqldump 工具导出数据或者表结构。
四、不同应用场景的数据仓库数据更新操作
为满足数据仓库的数据删除和更新操作,同时不影响数据仓库的查询性能,doris提供批量删除数据、更新数据、部分列更新,delete操作,满足不同的应用场景。
五、兼容数据湖的一些相关功能
数据仓库一般是建立在数据湖上的,因此需要经常从数据湖读取数据或者跨源查询数据,doris 作为实时数据仓库在这些方面也做相关的功能。
1、通过 Table Value Function 功能,Doris 可以直接将对象存储或 HDFS 上的文件作为 Table 进行查询分析。并且支持自动的列类型推断。即跨源查询
2、通过文件缓存提升数据湖查询的性能。文件缓存(File Cache)通过缓存最近访问的远端存储系统(HDFS 或对象存储)的数据文件,加速后续访问相同数据的查询。在频繁访问相同数据的查询场景中,File Cache 可以避免重复的远端数据访问开销,提升热点数据的查询分析性能和稳定性。
六、方便用户使用的一些功能
1、在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。于是doris 提供动态分区功能,动态分区只支持 Range 分区。减少用户的使用负担。
2、用户经常设置不合适的bucket,导致各种问题,这里提供一种方式,来自动设置分桶数。暂时而言只对olap表生效
3、fs_benchmark_tool 可以用于测试包括 hdfs 和对象存储在内的远端存储系统的基本服务性能,如读取、写入性能。该工具主要用于分析或排查远端存储系统的性能问题。
Doris数据库有很多功能可以供大家探索和使用,Doris还提供了丰富的管理工具和监控功能,以及与其他大数据生态系统的集成支持,如Hadoop、Spark等。这些功能可以帮助用户更好地应对不同的数据处理和分析需求。文章来源:https://www.toymoban.com/news/detail-832027.html
注:以上部分描述和来源doris的官网。文章来源地址https://www.toymoban.com/news/detail-832027.html
到了这里,关于数据仓库内容分享(十七):Doris实践分享:它做了哪些架构优化和场景优化?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!