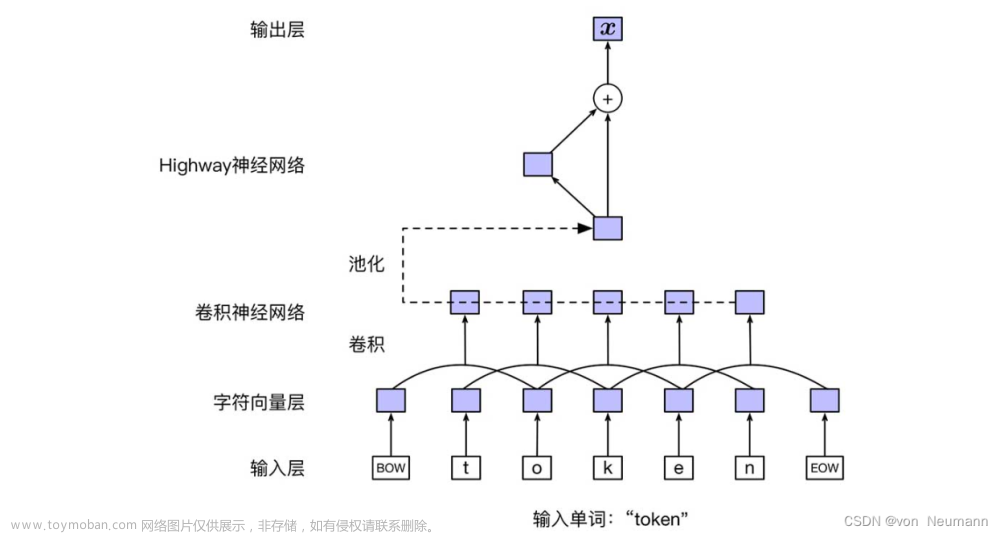
代码和报告均为本人自己实现(实验满分),只展示主要任务实验结果,如果需要详细的实验报告或者代码可以私聊博主,接实验技术指导1对1
实验要求布置请看
运行模型,测试模型在有 100% / 50% / 10% training data(通过随机 sample
原 training set 一部分的数据,10%代表低资源的设定)的情况下模型在 dev set
上的效果
BERT 模型
这里使用原代码 100%数据运行 200 轮训练,结果如下

从图中可以看出在 200 轮训练完成后在 dev set 上的 F1 结果是 0.5472,AUC 结
果为 0.5049

然后我运行 test.py 进行 testset 的文件输出,这里设置的是预测准确率大于0.2 的实体关系对才会被输出,最终提交到网站上结果如下所示

 通过查看训练过程我发现,在训练到 130 轮的时候的结果已经和 200 轮的结果是差不多的,F1 的值和 AUC 值都是很小的差距了,所以在后面只使用原数据的 50% 和 10%进行训练的时候我都调整为 130 轮进行训练。修改读取数据时候的代码即可实现随机从原数据抽出 50%和 10%进行训练测试
通过查看训练过程我发现,在训练到 130 轮的时候的结果已经和 200 轮的结果是差不多的,F1 的值和 AUC 值都是很小的差距了,所以在后面只使用原数据的 50% 和 10%进行训练的时候我都调整为 130 轮进行训练。修改读取数据时候的代码即可实现随机从原数据抽出 50%和 10%进行训练测试

BERT 模型使用原数据 50%进行训练,结果如下

从结果来看和使用 100%数据训练 130 轮的时候在 devset 测试出的 F1 值和 AUC 差距很小,大约是 0.03 左右,我猜测造成这样的原因是因为模型鲁棒性, BERT等预训练模型已经在大规模数据上进行了预训练,在训练过程中已经获得了对各种语言和任务的普遍表示能力。这种普适性可能使得模型对于即使使用只有原来一半数据量的时候,泛化能力也相对较好。
BERT 模型使用原数据 10%进行训练,结果如下

从结果来看出在 bert 模型上只使用原数据 10%进行训练的时候,模型性能显著下降,在 devset 测试出的 F1 值只有 0.254038,AUC 值为 0.11,明显能看出结果变差了很多,我猜测造成这样主要原因是因为数据缺失,因为 BERT 模型是在大型语料库上进行训练的,这使得它可以捕捉到广泛的语言特性和模式。这里只使用了原始数据的 10%,可能会失去一些重要的数据,导致模型在测试时表现不佳。
RoBERTa 模型
这里使用 RoBERTa 模型 100%数据运行 200 轮训练,结果如下

从结果 devset 的 F1 值和 AUC 值来看都要比 BERT 模型 200 轮的结果要更高
Bert 模型 200 轮在 devset 上的结果:F1 值 0.5472 AUC 值 0.5049
RoBerta 模型 200 轮在 devset 上的结果:F1 值 0.5606 AUC 值 0.5284
F1 值提高了 0.0134,AUC 值提高了 0.0235
我认为性能提升的主要原因就是 RoBERTa 采用了更长的训练时间和更大的数据集来进行预训练,这有助于模型更好地学习语言的表示。这使得 RoBERTa 在一些任务上能够更好地捕捉语义和上下文信息。然后我运行 test.py 文件把结果提交到网站上,结果如图所示
 对比使用 bert 模型输出的结果,score 提升 0.017 左右,显然确实性能有提升。
对比使用 bert 模型输出的结果,score 提升 0.017 左右,显然确实性能有提升。
RoBERTa 模型使用原数据 50%进行训练,结果如下

从 devset 上的测试结果来看,F1 和 AUC 显著下降,对比于 100%数据训练下

F1 值只有原来的 69%达到 0.3806,AUC 值只有原来的 58%达到 0.3042。再对比于 同样 50%数据训练下的 bert 模型,RoBERTa 模型训练出的结果也低很多,说明 RoBERTa 模型受数据大小对于结果的影响相比于 bert 模型更大文章来源:https://www.toymoban.com/news/detail-836042.html
RoBERTa 模型使用原数据 10%进行训练,结果如下
 文章来源地址https://www.toymoban.com/news/detail-836042.html
文章来源地址https://www.toymoban.com/news/detail-836042.html
这里发现结果相对于 50%数据训练下的结果反而不大了,F1 值为 0.23,AUC 值为 0.1342。这个时候和 bert 模型在 10%数据训练下的结果几乎一样,我认为造成这样的主要原因是数据量不足 10% 的数据实在太少,以至于两个模型都无法充分利用其潜在的能力。在这种情况下,两个模型可能都没有充分学习到任务的特征,导致它们在 devset 上表现相似。
到了这里,关于【自然语言处理】:实验4答案,预训练语言模型实现与应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!