大家好,我是带我去滑雪!
在本期中,首先介绍如何爬取房价数据与清洗数据,对处理后的数据进行简单分析,最后使用粒子群优化的支持向量机对房价进行预测。基于粒子群优化的支持向量机(Particle Swarm Optimization-based Support Vector Machine,PSO-SVM)房价预测分析是一种结合了优化算法和机器学习方法的预测模型。支持向量机(SVM)是一种监督学习算法,适用于回归和分类问题。而粒子群优化(PSO)是一种启发式优化算法,模拟了鸟群觅食的过程,通过不断调整粒子的速度和位置来寻找最优解。在房价预测分析中,PSO-SVM模型的基本思想是利用PSO算法来寻找SVM模型的最佳参数,从而使得SVM模型能够更准确地拟合房价数据。具体而言,PSO算法通过不断更新粒子的位置和速度来搜索参数空间,并利用目标函数的优化值来评估粒子的性能。而SVM模型则利用找到的最佳参数来构建一个具有较高泛化能力的回归模型,用于预测房价。下面开始代码实战。
目录
(1)爬取数据并进行数据转换
(2)绘制词云图与热力图
(3)基于粒子群优化的支持向量机房价预测
(1)爬取数据并进行数据转换
import asyncio
import aiohttp
from lxml import etree
import logging
import datetime
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(['房源', '房子信息', '所在区域', '单价', '关注人数和发布时间', '标签'])
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
start = datetime.datetime.now()
class Spider(object):
def __init__(self):
self.semaphore = asyncio.Semaphore(6)
self.header = {
"Host": "xxxx",
"Referer": "https://xxxx/ershoufang/",
"Cookie": "lianjia_uuid=db0b1b8b-01df-4ed1-b623-b03a9eb26794; _smt_uid=5f2eabe8.5e338ce0; UM_distinctid=173ce4f874a51-0191f33cd88e85-b7a1334-144000-173ce4f874bd6; _jzqy=1.1596894185.1596894185.1.jzqsr=baidu.-; _ga=GA1.2.7916096.1596894188; gr_user_id=6aa4d13e-c334-4a71-a611-d227d96e064a; Hm_lvt_678d9c31c57be1c528ad7f62e5123d56=1596894464; _jzqx=1.1596897192.1596897192.1.jzqsr=cd%2Elianjia%2Ecom|jzqct=/ershoufang/pg2/.-; select_city=510100; lianjia_ssid=c9a3d829-9d20-424d-ac4f-edf23ae82029; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1596894222,1597055584; gr_session_id_a1a50f141657a94e=33e39c24-2a1c-4931-bea2-90c3cc70389f; CNZZDATA1253492306=874845162-1596890927-https%253A%252F%252Fwww.baidu.com%252F%7C1597054876; CNZZDATA1254525948=1417014870-1596893762-https%253A%252F%252Fwww.baidu.com%252F%7C1597050413; CNZZDATA1255633284=1403675093-1596890300-https%253A%252F%252Fwww.baidu.com%252F%7C1597052407; CNZZDATA1255604082=1057147188-1596890168-https%253A%252F%252Fwww.baidu.com%252F%7C1597052309; _qzjc=1; gr_session_id_a1a50f141657a94e_33e39c24-2a1c-4931-bea2-90c3cc70389f=true; _jzqa=1.3828792903266388500.1596894185.1596897192.1597055585.3; _jzqc=1; _jzqckmp=1; sensorsdata2015jssdkcross=%7B%22distict_id%22%3A%22173ce4f8b4f317-079892aca8aaa8-b7a1334-1327104-173ce4f8b50247%22%2C%22%24device_id%22%3A%22173ce4f8b4f317-079892aca8aaa8-b7a1334-1327104-173ce4f8b50247%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _gid=GA1.2.865060575.1597055587; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1597055649; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiOWQ4ODYyNmZhMmExM2Q0ZmUxMjk1NWE2YTRjY2JmODZiZmFjYTc2N2U1ZTc2YzM2ZDVkNmM2OGJlOWY5ZDZhOWNkN2U3YjlhZWZmZTllNGE3ZTUwYjA3NGYwNDEzMThkODg4NTBlMWZhZmRjNTIwNDBlMDQ2Mjk2NTYxOWQ1Y2VlZjE5N2FhZjUyMTZkOTcyZjg4YzNiM2U1MThmNjc5NmQ4MGUxMmU2YTM4MmI3ZmU0NmFhNTJmYmMyYWU1ZWI3MjU5YWExYTQ1YWFkZDUyZWVjMzM2NTFjYTA2M2NlM2ExMzZhNjEwYjFjYzQ0OTY5MTQwOTA4ZjQ0MjQ3N2ExMDkxNTVjODFhN2MzMzg5YWM3MzBmMTQxMjU4NzAwYzk5ODE3MTk1ZTNiMjc4NWEzN2M3MTIwMjdkYWUyODczZWJcIixcImtleV9pZFwiOlwiMVwiLFwic2lnblwiOlwiYmExZDJhNWZcIn0iLCJyIjoiaHR0cHM6Ly9jZC5saWFuamlhLmNvbS9lcnNob3VmYW5nLyIsIm9zIjoid2ViIiwidiI6IjAuMSJ9; _qzja=1.726562344.1596894309336.1596897192124.1597055583833.1597055601626.1597055649949.0.0.0.12.3; _qzjb=1.1597055583833.3.0.0.0; _qzjto=3.1.0; _jzqb=1.3.10.1597055585.1; _gat=1; _gat_past=1; _gat_global=1; _gat_new_global=1; _gat_dianpu_agent=1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
}
async def scrape(self, url):
async with self.semaphore:
session = aiohttp.ClientSession(headers=self.header)
response = await session.get(url)
result = await response.text()
await session.close()
return result
async def scrape_index(self, page):
url = f'https://xxxx/ershoufang/pg{page}/'
text = await self.scrape(url)
await self.parse(text)
async def parse(self, text):
html = etree.HTML(text)
lis = html.xpath('//*[@id="content"]/div[1]/ul/li')
for li in lis:
house_data = li.xpath('./div[@class="title"]/a/text()')[0]
house_info = li.xpath('.//div[@class="houseInfo"]/text()')[0]
address = ' '.join(li.xpath('.//div[@class="positionInfo"]/a/text()'))
price = li.xpath('.//div[@class="priceInfo"]/div[2]/span/text()')[0]
attention_num = li.xpath('.//div[@class="followInfo"]/text()')[0]
tag = ' '.join(li.xpath('.//div[@class="tag"]/span/text()'))
sheet.append([house_data, house_info, address, price, attention_num, tag])
logging.info([house_data, house_info, address, price, attention_num, tag])
def main(self):
scrape_inde_tasks = [asyncio.ensure_future(self.scrape_index(page)) for page in range(1, 101)]
loop = asyncio.get_event_loop()
tasks = asyncio.gather(*scrape_index_tasks)
loop.run_until_complete(taks)
if __name__ == '__main__':
spider = Spider()
spider.main()
部分爬取数据展示:
2024-02-28 00:31:09,451 - INFO: ['招商海屿城 精装修 满两年 一线观滇', '4室2厅 | 139.43平米 | 东南 | 精装 | 高楼层(共11层) | 板楼', '招商海屿城 滇池半岛', '15,062元/平', '3人关注 / 一年前发布', '近地铁 VR看装修 随时看房'] 2024-02-28 00:31:09,452 - INFO: ['此房户型方正 有15平左右没有计入房产证面积诚心出售', '3室2厅 | 92.7平米 | 南 北 | 毛坯 | 低楼层(共13层) | 板楼', '航空艺术港 呈贡', '5,049元/平', '8人关注 / 7个月以前发布', 'VR看装修 随时看房'] 2024-02-28 00:31:09,454 - INFO: ['滇池俊府5跃6端户 视野开阔 带车位 急售', '4室2厅 | 130平米 | 东南 | 毛坯 | 中楼层(共8层) | 板楼', '滇池俊府 滇池半岛', '17,693元/平', '4人关注 / 一年前发布', 'VR房源 随时看房'] 2024-02-28 00:31:09,456 - INFO: ['河畔俊园 精装修4房带负一层大车位 满二 可观滇', '4室2厅 | 103.15平米 | 东南 | 精装 | 高楼层(共25层) | 板塔结合', '河畔俊园 新亚洲', '13,573元/平', '0人关注 / 7个月以前发布', 'VR看装修 随时看房'] 2024-02-28 00:31:09,457 - INFO: ['生活方便 视野开阔 交通便利', '3室2厅 | 111.23平米 | 南 北 | 精装 | 低楼层(共17层) | 板楼', '绿地滇池国际健康城蓝湾 呈贡', '6,743元/平', '3人关注 / 11个月以前发布', 'VR看装修 随时看房'] 2024-02-28 00:31:09,459 - INFO: ['保利堂悦品质小区,为您打造优质居住需求', '3室2厅 | 115.76平米 | 东南 | 精装 | 低楼层(共32层) | 板楼', '保利堂悦 巫家坝', '12,094元/平', '6人关注 / 一年前发布', 'VR看装修 随时看房'] 2024-02-28 00:31:09,461 - INFO: ['河畔俊园精装修四 房 房东诚心出售', '4室2厅 | 110.34平米 | 东南 | 精装 | 高楼层(共19层) | 板塔结合', '河畔俊园 新亚洲', '10,876元/平', '1人关注 / 一年前发布', 'VR看装修 随时看房'] 2024-02-28 00:31:09,464 - INFO: ['龙熙一号,证在手,满两年一梯两户公摊小 带产权车位', '3室2厅 | 120.05平米 | 东南 | 毛坯 | 低楼层(共11层) | 板楼', '中建龙熙壹号 北部客运站', '8,830元/平', '4人关注 / 6个月以前发布', 'VR看装修 随时看房'] 2024-02-28 00:31:09,466 - INFO: ['水逸康桥电梯房 通透端户 看房方便采光好', '3室2厅 | 101.44平米 | 东 西 | 精装 | 中楼层(共11层) | 板楼', '水逸康桥 高新', '12,816元/平', '0人关注 / 一年前发布', '近地铁 VR看装修 随时看房'] 2024-02-28 00:31:09,468 - INFO: ['金沙小区二楼二室二厅证在手,房东诚心出售', '2室2厅 | 76.15平米 | 南 | 简装 | 低楼层(共7层) | 板楼', '金沙小区 金沙', '6,803元/平', '5人关注 / 一年前发布', 'VR看装修 随时看房']
数据转换,将txt文档转换成csv文件:
f_path=r'E:\工作\硕士\博客\博客粉丝问题\data.txt'
with open(f_path,encoding = "UTF-8") as f:
data=f.read()
print(data)
import xlwt
def txt_xls(filename,xlsname):
try:
f = open(r"E:\工作\硕士\博客\博客粉丝问题\data.txt",encoding = "UTF-8")
xls=xlwt.Workbook()
sheet = xls.add_sheet('sheet1',cell_overwrite_ok=True)
x = 0
while True:
line = f.readline()
if not line:
break
for i in range(len(line.split(','))):
item=line.split(',')[i]
sheet.write(x,i,item)
x += 1
f.close()
xls.save(xlsname)
except:
raise
if __name__ == "__main__" :
filename = "E:\工作\硕士\博客\博客粉丝问题\data.txt"
xlsname = "E:\工作\硕士\博客\博客粉丝问题\data.csv"
txt_xls(filename,xlsname)结果展示:

(2)绘制词云图与热力图
词云图的数据采用爬取数据中的广告标题,进一步分析哪些是卖房的热点词:
import jieba
import matplotlib.pyplot as plt
report = open('词云图数据.txt','r',encoding="UTF-8").read()
words = jieba.cut(report)
report_words = []
for word in words:
if len(word) >= 4:
report_words.append(word)
from collections import Counter
result = Counter(report_words).most_common(50)
from wordcloud import WordCloud
content = ' '.join(reportwords)
wc = WordCloud(font_path='simhei.ttf',
background_color='white',
width=5300,
height=3000,
).generae(content)
wc.to_file('词云图.png')
plt.savefig("squares4.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果展示:

绘制处理后变量的箱线图与热力图:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.svm import LinearSVR
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
get_ipython().run_line_magic('matplotlib', 'inline')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from IPython.core.interactiveshell import InteractiveShell
InteractieShell.ast_node_interactivity = 'all'
import warnings
data=pd.read_csv(r'E:\工作\硕士\博客\博客粉丝问题\data2.csv',encoding="gbk")
print(data)
data.info()#查看数据
import missingno as msno
%matplotlib inline
msno.matrix(data)#查看是否存在缺失值,黑色的位置表示有数据
#查看变量的箱线图分布
columns = data.columns.tolist()
dis_cols = 4
dis_rows = len(columns)
plt.figure(figsie=(4 * dis_cols, 4 * dis_rows))
for i in range(len(columns)):
plt.subplot(dis_rows,dis_cols,i+1)
sns.boxplot(data=data[columns[i]], orient="v",width=0.5)
plt.xlabel(columns[i],fontsize = 20)
plt.tight_layout()
plt.savefig(r'E:\工作\硕士\博客\博客粉丝问题\变量的箱线图分布.png',
bbox_inches ="tight",
pad_inces = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')
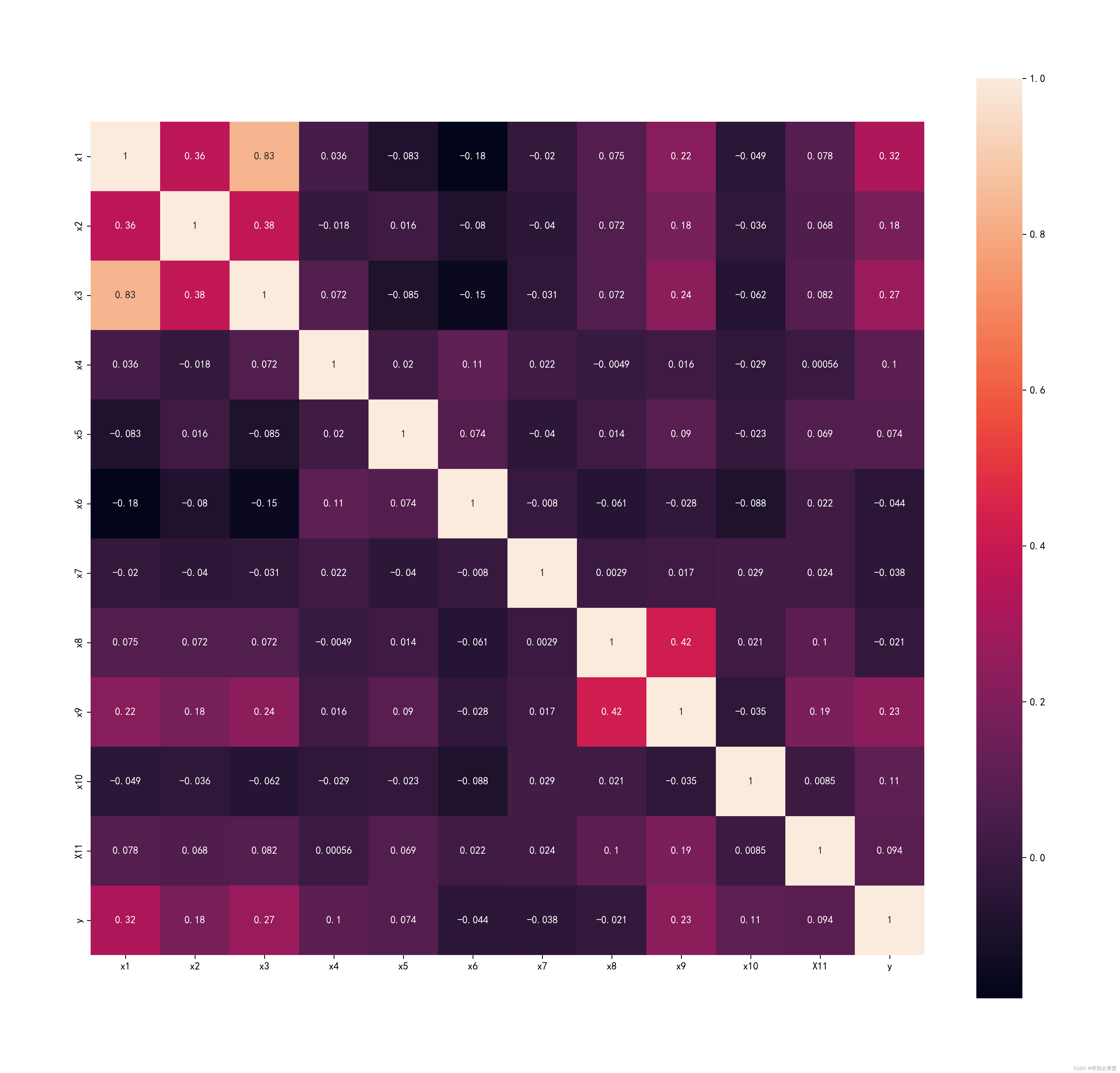
corr = plt.subplots(figsize = (18,16),dpi=300)
corr= sns.heatmap(data.corr(method='spearman'),annot=True,square=True)
plt.savefig(r'E:\工作\硕士\博客\博客粉丝问题\变量间的热力图.png',
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果展示:
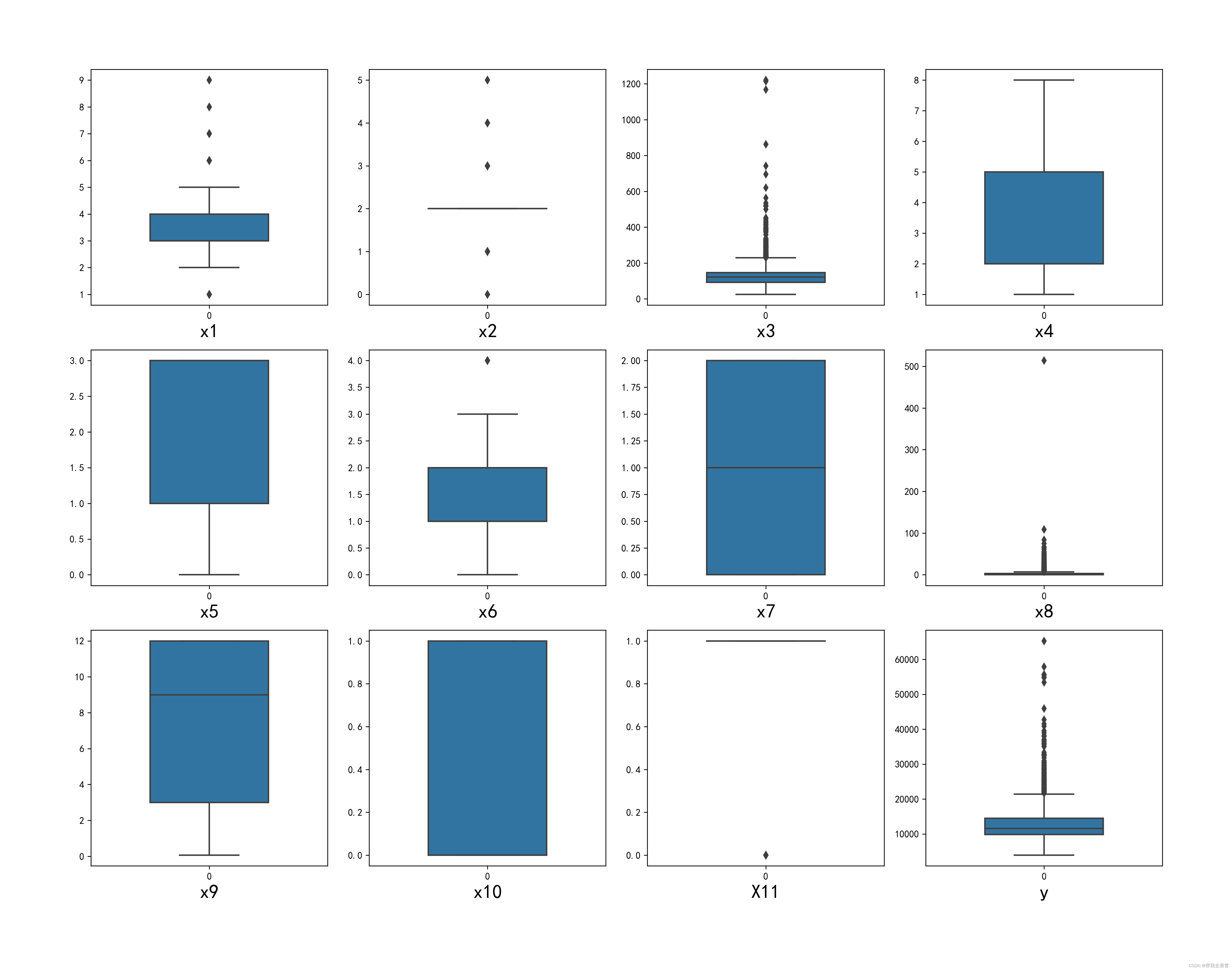
(3)基于粒子群优化的支持向量机房价预测
import csv
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from datetime import datetime
from sklearn.metrics import explained_variance_score
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import explained_variance_score
from sklearn import metrics
from sklearn.metrics import mean_absolute_error # 平方绝对误差
import random
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.svm import LinearSVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
data = pd.read_csv(r'E:\工作\硕士\博客\博客粉丝问题\data3.csv')
data
feature=data.iloc[:,:-1]
print(feature)
targets = data.iloc[:,-1]
print(targets)输出结果展示:
x1 x2 x3 x4 x5 x6 x7 x8 0 4 139 5 3 1 2 3 12 1 3 93 2 1 1 0 8 7 2 4 130 5 1 1 1 4 12 3 4 103 5 3 3 2 0 7 4 3 111 2 3 1 0 3 11 ... .. ... .. .. .. .. .. .. 2987 3 98 5 3 2 2 0 11 2988 4 117 2 3 1 2 0 5 2989 3 127 1 3 2 0 1 10 2990 3 73 2 2 1 1 0 9 2991 3 75 5 3 1 0 0 120 47.76 1 212.97 2 43.48 3 71.53 4 133.61 ... 2987 84.64 2988 66.03 2989 91.14 2990 111.36 2991 86.79 Name: y, Length: 2992, dtype: float64
构建支持向量机模型并计算得分:
feature_train, feature_test, target_train, target_test = train_test_split(feature, targets, test_size=0.3,random_state=1)
feature_test=feature[int(len(feature)*0.7):int(len(feature))]
target_test=targets[int(len(targets)*0.7):int(len(targets))]
print(feature_train)
print(feature_test)
print(target_test)
scaler = StandardScaler()
scaler.fit(feature_train)
feature_train_s=scaler.fit_transform(feature_train)
feature_test_s=scaler.fit_transform(feature_test)
model_svr = SVR(kernel='rbf',C=1,epsilon=0.1,gamma='auto',degree=3)
model_svr.fit(feature_train_s,target_train)
predict_results=model_svr.predict(feature_test_s)
print("MSE:",mean_squared_error(target_test,predict_results))
print("R2 = ",metrics.r2_score(target_test,predict_results))
print("MAE = ",mean_absolute_error(target_test,predict_results))
model_svr.score(feature_test_s,target_test)输出结果展示:
Name: y, Length: 898, dtype: float64 MSE: 565.0098041734449 R2 = 0.5224357380910136 MAE = 17.46518738106188 0.5224357380910136
使用粒子群优化算法进行参数寻优优化:
class PSO:
def __init__(self, parameters):
"""
particle swarm optimization
parameter: a list type, like [NGEN, pop_size, var_num_min, var_num_max]
"""
# 初始化
self.NGEN = parameters[0] # 迭代的代数
self.pop_size = parameters[1] # 种群大小
self.var_num = len(parameters[2]) # 变量个数
self.bound = [] # 变量的约束范围
self.bound.append(parameters[2])
self.bound.appen(parameters[3])
self.pop_x = np.zeros((self.pop_size, self.var_num)) # 所有粒子的位置
self.pop_v = np.zeros((self.pop_size, self.var_num)) # 所有粒子的速度
self.p_best = np.zeros((self.pop_size, self.var_num)) # 每个粒子最优的位置
self.g_best = np.zeros(( self.var_num)) # 全局最优的位置
# 初始化第0代初始全局最优解
temp = -1
for i in range(self.pop_size):
for j in range(self.var_num):
self.pop_x[i][j] = random.uniform(self.bound[0][j], self.bound[1][j])
self.pop_v[i][j] = random.uniform(0, 1)
self.p_best[i] = self.pop_x[i] # 储存最优的个体
fit = self.fitness(self.best[i])
if fit > temp:
self.g_best = self.p_best[i]
temp = fit
def fitness(self, ind_var):
X = feature_train
y = target_train
"""
个体适应值计算
"""
x1 = ind_var[0]
x2 = ind_var[1]
x3 = ind_var[2]
if x1==0:x1=0.001
if x2==0:x2=0.001
if x3==0:x3=0.001
clf = SVR(C=x1,epsilon=x2,gamma=x3)
clf.fit(X, y)
predictval=clf.predict(feature_test)
print("R2 = ",metrics.r2_score(target_test,predictval)) # R2
return metrics.r2_score(target_test,predictval)
def update_operator(self, pop_size):
"""
更新算子:更新下一时刻的位置和速度
"""
c1 = 2 # 学习因子,一般为2
c2 = 2
w = 0.4 # 自身权重因子
for i in range(pop_size):
# 更新速度
self.pop_v[i] = w * self.pop_v[i] + c1 * random.uniform(0, 1) * (
self.p_best[i] - self.pop_x[i]) + c2 * random.uniform(0, 1) * (self.g_best - self.pop_x[i])
# 更新位置
self.pop_x[i] = self.pop_x[i] + self.pop_v[i]
# 越界保护
for j in range(self.var_num):
if self.pop_x[i][j] < self.bound[0][j]:
self.pop_x[i][j] = self.bound[0][j]
if self.pop_x[i][j] > self.bound[1][j]:
self.pop_x[i][j] = self.bound[1][j]
# 更新p_best和g_best
if self.fitness(self.pop_x[i]) > self.fitness(self.p_best[i]):
self.p_best[i] = self.pop_x[i]
if self.fitness(self.pop_x[i]) > self.fitness(self.g_best):
self.g_best = self.pop_x[i]
def main(self):
popobj = []
self.ng_best = np.zeros((1, self.var_num))[0]
for gen in range(self.NGEN):
self.update_operator(self.pop_size)
popobj.append(self.fitness(self.g_best))
print('############ Generation {} ############'.format(str(gen + 1)))
if self.fitness(self.g_best) > self.fitness(self.ng_best):
self.ng_best = self.g_best.copy()
print('最好的位置:{}'.format(self.ng_best))
print('最大的函数值:{}'.format(self.fitness(self.ng_best)))
print("---- End of (successful) Searching ----")
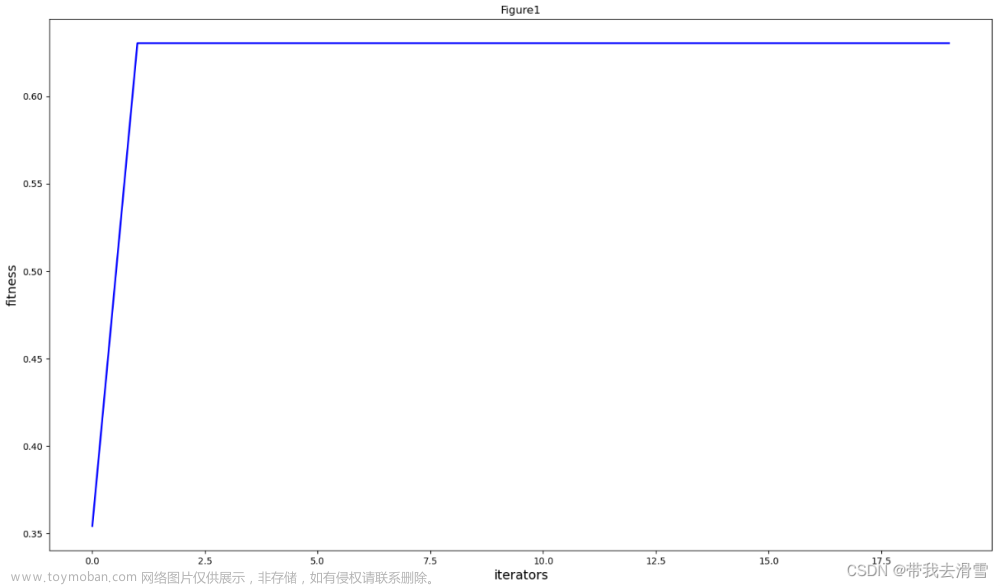
plt.figure()
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title("Figure1")
plt.xlabel("iterators", size=14)
plt.ylabel("fitness", size=14)
t = [t for t in range(self.NGEN)]
plt.plot(t, popobj, color='b', linewidth=2)
plt.show()
if __name__ == '__main__':
NGEN = 20
popsize = 20
low = [0,0,0]
up = [10,5,100]
parameters = [NGEN, popsize, low, up]
pso = PSO(parameters)
pso.main()输出结果:
将最优参数代入支持向量机模型:
model_svr = SVR(C=10,epsilon= 5)
model_svr.fit(feature_train_s,target_train)
predict_results=model_svr.predict(feature_test_s)
print("MSE:",mean_squared_error(target_test,predict_results))
print("R2 = ",metrics.r2_score(target_test,predict_results)) # R2
print("MAE = ",mean_absolute_error(target_test,predict_results)) # R2
输出结果:
MSE: 438.54080593060655 R2 = 0.6293313589352663 MAE = 16.084581589790808
计算预测值:
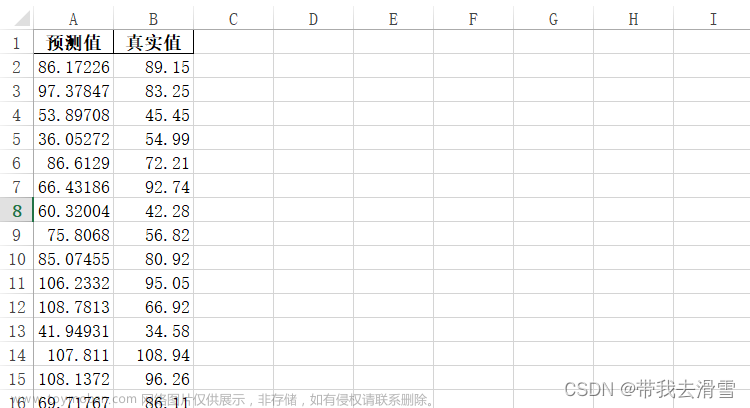
sigmoid_pred_true=pd.concat([pd.DataFrame(predict_results),pd.DataFrame(target_test)],axis = 1)#axis=1 表示按照列的方向进行操作,也就是对每一行进行操作。
sigmoid_pred_true.columns=['预测值', '真实值']
sigmoid_pred_true.to_excel(r'E:\工作\硕士\博客\博客粉丝问题\预测值与真实值.xlsx',index = False)
data1 = pd.read_csv(r'E:\工作\硕士\博客\博客粉丝问题\预测值与真实值.csv',encoding="gbk")
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号
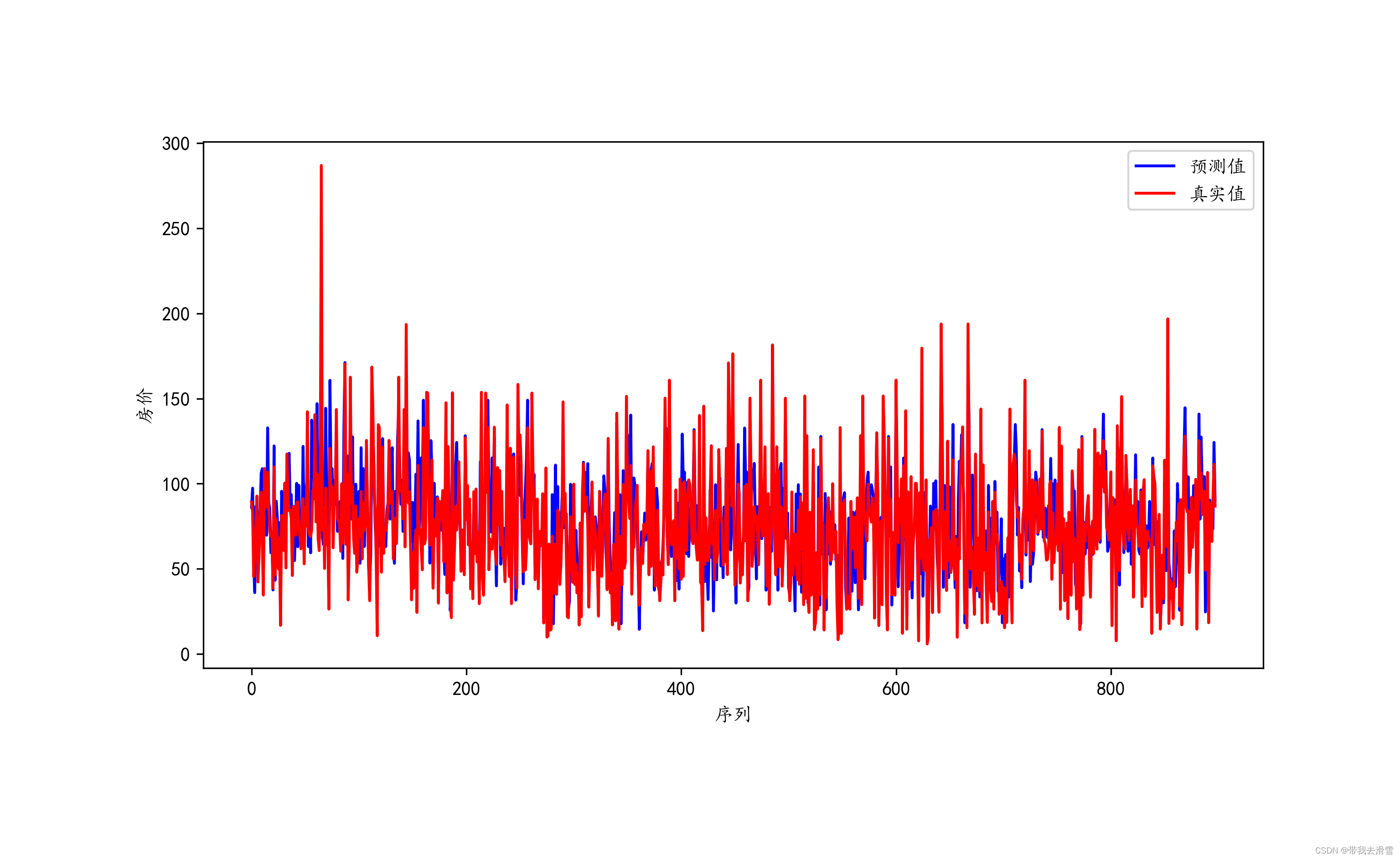
plt.subplots(figsize=(10,5))
plt.xlabel('序列', fontsize =10)
plt.ylabel('房价', fontsize =10)
plt.plot(data1.预测值, color = 'b', label = '预测值')
plt.plot(data1.真实值, color = 'r', label = '真实值')
plt.legend(loc=0)
plt.savefig(r'E:\工作\硕士\博客\博客粉丝问题\预测值与真实值对比图.png',
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果展示:
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/173deLlgLYUz789M3KHYw-Q?pwd=0ly6
提取码:2138
更多优质内容持续发布中,请移步主页查看。
若有问题可邮箱联系:1736732074@qq.com
博主的WeChat:TCB1736732074文章来源:https://www.toymoban.com/news/detail-840206.html
点赞+关注,下次不迷路!文章来源地址https://www.toymoban.com/news/detail-840206.html
到了这里,关于基于粒子群优化的支持向量机房价预测分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!