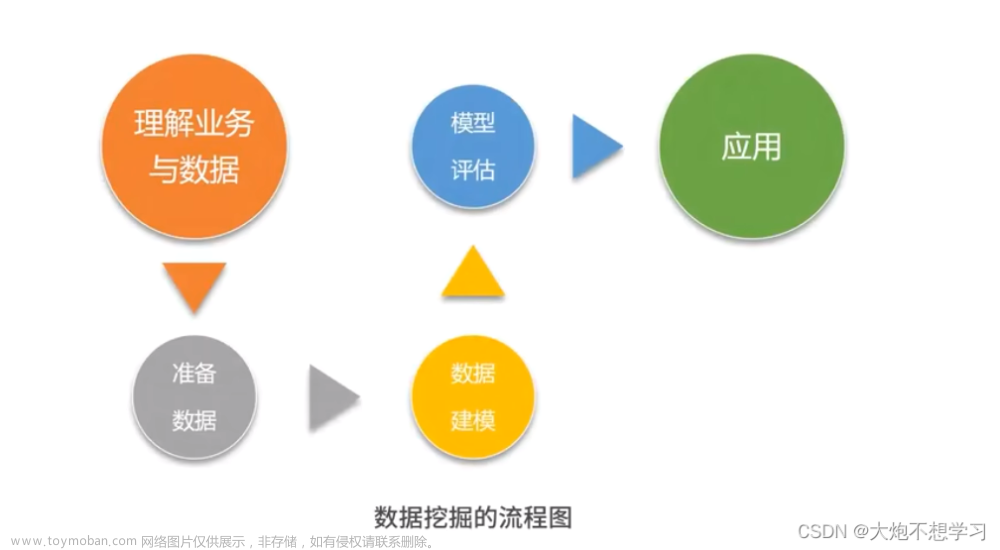
11、对数据分析的看法,你怎么理解数据分析师这个职业?
①职责是收集、处理和分析大量的数据,并从中提取出有用的信息。
②工作范围包括数据清洗、数据建模、数据可视化等。
数据收集和清洗:收集各种来源的数据,并清洗、转换为可分析的格式。
数据分析和建模:应用统计学、机器学习和数据挖掘技术对数据进行分析和建模,以发现隐藏的模式和见解。
数据可视化:使用图表、图形和仪表板将数据呈现给非技术人员,以便他们更好地理解数据。
解释和报告:解释分析结果,并撰写报告或演示,向业务决策者提供有关数据的见解和建议。
持续改进:监测和评估数据分析的有效性,并不断改进方法和流程。
12、rfm模型介绍一下?
①RFM模型是一种被广泛使用的营销模型,又称客户价值模型,通过R、F、M这3个指标对客户进行分类,用来衡量客户价值和创收能力。
②rfm由R、F、M三个指标组成。
Recency(最近购买时间):最近一次消费至今的时间。离得越远,用户越有流失可能,越应该唤醒用户。
Frequency(购买频率):一定时间内重复消费频率。频次越低,越需要用一次性手段(比如促销、赠礼),频次越高,越可以用持续性手段(积分)来维护。
Monetary(购买金额): 一定时间内累计消费金额。消费越多,用户价值越高,越应该重点关注。
13、请你说说假设检验是什么?
假设检验是用来判断样本与样本,样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。其基本原理是先对总体的特征作出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受作出推断。
14、假设检验的原理和步骤。
①原理:先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。
②步骤
(1)确定假设。首先明确定义零假设(H0)和备择假设(H1)。
(2)选择适当的检验方法。常见的假设检验方法包括 t 检验、ANOVA、卡方检验等。
(3)确定显著性水平α。通常选择0.05或0.01作为显著性水平。
(4)收集样本数据。收集与研究问题相关的样本数据,并确保数据满足所选假设检验方法的前提条件。
(5)计算统计量。根据收集到的样本数据,计算所选假设检验方法的统计量。统计量的计算方式根据所选的假设检验方法而异。
(6)计算 p 值。根据计算得到的统计量,利用统计分布的理论或抽样方法计算 p 值。p 值表示在零假设为真的情况下,观察到样本数据或更极端情况的概率。
(7)做出决策。比较计算得到的 p 值与显著性水平。如果 p 值小于显著性水平,则拒绝零假设,接受备择假设;如果 p 值大于等于显著性水平,则接受零假设。
(8)做出结论。根据假设检验的结果,对研究问题进行解释并做出相应的结论。
15、PCA知道吗?
①定义:PCA是Principal Component Analysis(主成分分析)的缩写,是一种常用的降维技术。PCA利用降维(线性变换)的思想,把多个自变量转化为几个不相关的主成分,会损失少量信息。
②数学原理:主成分是原始变量的线性组合,主成分的数量相对于原始变量数量更少,主成分保留了原始成分的大量信息,各主成分之间相互独立。
③特征根(特征值)含义:每个主成分都会有一个特征根,表示主成分的重要性,特征根越大,表示该组成分越重要。
④方差贡献率:某一特征值除以所有特征值的和就是该特征向量的方差贡献率。
⑤PCA步骤
(1)标准化数据:对原始数据进行标准化处理,使得每个特征的均值为0,标准差为1。
(2)计算协方差矩阵:根据标准化后的数据计算特征之间的协方差矩阵。
(3)计算特征值和特征向量:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
(4)选择主成分:根据特征值的大小,选择最重要的几个特征向量作为主成分。
(5)数据转换:将原始数据投影到选定的主成分上,得到降维后的数据。
16、评价指标有哪些?
①准确率(Accuracy):分类任务中预测正确的样本数与总样本数之比。
②精确率(Precision):在所有被预测为正类别的样本中,真正为正类别的样本所占的比例 TP/(TP+FP)。
③召回率(Recall):在所有真正为正类别的样本中,被预测为正类别的样本所占的比例 TP/(TP+FN)。
④ROC曲线(Receiver Operating Characteristic Curve):以真正类别率(TPR,召回率)为纵轴,假正类别率(FPR,1-特异度)为横轴所绘制的曲线。
⑤AUC值(Area Under Curve):ROC曲线下的面积,用于衡量模型对正负样本的区分能力。
⑥F1分数(F1 Score):精确率和召回率的调和平均数,综合考虑了模型的准确性和完整性。
⑦均方误差(Mean Squared Error,MSE):回归任务中预测值与真实值之间差异的平方和的均值。
⑧平均绝对误差(Mean Absolute Error,MAE):回归任务中预测值与真实值之间差异的绝对值的平均值。
17、有哪些数据分析经历?
18、更倾向于业务方向还是技术方向?
业务方向和技术方向都需要,数据分析需要使用各种数据处理和分析工具、编程语言以及统计和机器学习算法等技术手段,而数据分析的最终目标是为业务决策提供支持和指导。
19、说一下abtest的流程?
①基本原理:ABtest就是当我们在A、B两个方案之间犹豫不决的时候,直接把两个方案测试一把,看看哪个效果好,把测试结果作为参考依据。
②流程
第一步:明确要检验的A、B两个对象
第二步:明确要检验的指标,是平均值,还是比例
第三步:根据检验目的,给出原假设/备选假设
第四步:根据要检验的指标,选择检验统计量
第五步:给定显著性水平,计算统计量,得出结果:支持原假设还是推翻原假设
20、ROC的了解情况,怎么画ROC?
①ROC(Receiver Operating Characteristic)曲线是用于评估二分类模型性能的常用工具,它展示了在不同阈值下真正例率(True Positive Rate,TPR)与假正例率(False Positive Rate,FPR)之间的关系。
②基本步骤:
(1)计算预测概率:使用训练好的二分类模型对测试集样本进行预测,并得到每个样本属于正例的概率(预测概率)。
(2)选择阈值:选择一个阈值(通常在0到1之间),用于将预测概率转换为类别标签(正例或负例)。对于每个不同的阈值,都可以计算出对应的TPR和FPR。
(3)计算TPR和FPR:根据选择的阈值,分别计算出真正例率(TPR)和假正例率(FPR)。
TPR = TP / (TP + FN),其中TP为真正例数,FN为假负例数。
FPR = FP / (FP + TN),其中FP为假正例数,TN为真负例数。
(4)绘制ROC曲线:ROC曲线的横轴是FPR,纵轴是TPR,因此ROC曲线越靠近左上角(0,1),模型性能越好。文章来源:https://www.toymoban.com/news/detail-843600.html
(5)计算AUC值:计算ROC曲线下的面积(AUC,Area Under Curve),AUC值用于量化模型的整体性能,取值范围在0到1之间。AUC值越接近1,表示模型性能越好;越接近0.5,则表示模型性能越一般;低于0.5则表示模型性能较差,甚至比随机猜测还要差。文章来源地址https://www.toymoban.com/news/detail-843600.html
到了这里,关于数据分析面试题(11~20)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!