What is NLP?
NLP represents a facet of artificial intelligence focussed on examining, comprehending, andproducing human languages as they are naturally spoken and written.
NLP代表了人工智能的一个方面,专注于检查、理解和生成人类自然说话和书写的语言。
Why do we need them?
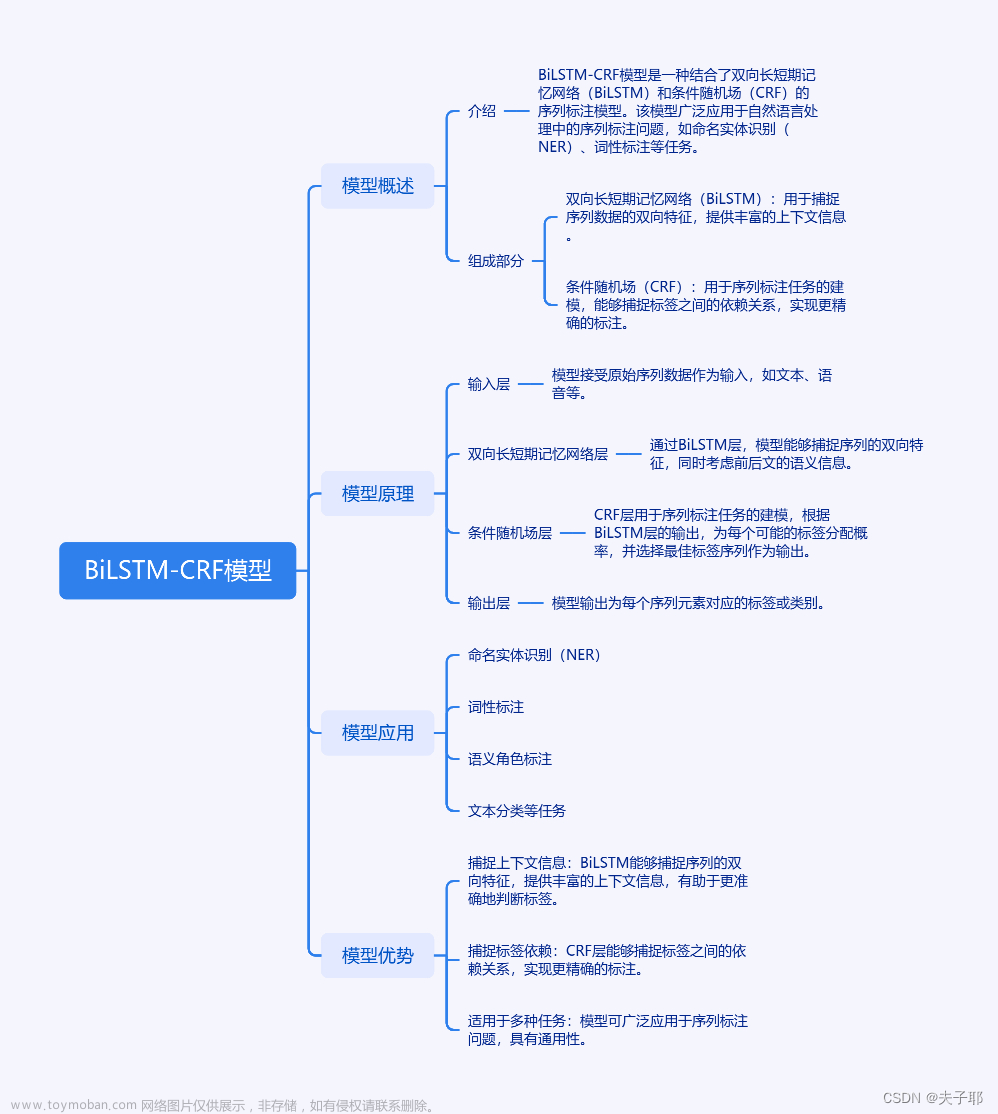
NOISE REDUCTION
Remove special characters,punctuation, and irrelevantinformation to clean the data.
去除特殊字符、标点符号和无关信息以清洗数据。
TOKENIZATION
Break text into smaller units(words/subwords) for better analysis.
将文本分解为更小的单位(单词/子词)以便更好地分析。
NORMALIZATION
Standardise words (lowercase,stemming, lemmatization) forreduced vocabulary size.
标准化单词(小写、词干提取、词形还原)以减少词汇量。
STOP WORD REMOVAL
Eliminate common words withlittle semantic value toreduce noise.
停用词移除:消除常见的语义价值低的词语以减少噪音。
HANDLING OOV WORDS
Replace out-of-vocabularywords with unknown tokens oruse subword tokenization.
用未知标记替换词汇表外的单词或使用子词分词。
SENTENCE SEGMENTATION
Separate text into sentencesfor individual analysis.
将文本分割成句子进行单独分析。
FEATURE ENGINEERING
Extract linguistic features(n-grams, POS tags) toenhance understanding.
提取语言特征(n-grams,词性标注)以增强理解。
Preprocessing Techniques
RegEx
Q:What is RegEx?
A:Regular Expressions (RegEx) is a string of text that lets you create patterns that help match, locate, and manage text.
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),可以用来描述和匹配字符串的特定模式。
import re
string = 'I am am not a booy, I am not a giirl.'
re.findall('[not]',string) #[] 所有匹配的字符
re.findall('b..y',string) #. 任意字符(除了换行符)
re.findall('^I',string) #^ 以...开始(整个字符串)
re.findall('giirl.$',string) #$ 以...(前置)结束(整个字符串)
re.findall('o*y',string) #* 0个或多个...(前置)
re.findall('i+rl',string) #+ 1个或多个...(前置)
re.findall(' ?booy',string) #? 0个或者1个...(前置)
re.findall('o{2}y',string) #{num} num个...(前置)
re.findall('booy|giirl',string) #| ...(前置)或...
re.findall('(am)+',string) #(content) content整体进行匹配(通常搭配其他符号使用)['n', 'o', 't', 'o', 'o', 'n', 'o', 't']
['booy']
['I']
['giirl.']
['ooy']
['iirl']
[' booy']
['ooy']
['booy', 'giirl']
['am', 'am', 'am']import re
string = 'Today is March 8, 2024. I am reviewing my course.'
re.findall('.m',string) #匹配并返回字符串中所有匹配项
re.search('..i',string) #匹配字符串中匹配项并返回位置
re.split(' ',string) #将字符串以...分割成多个
re.sub('March..','March eighth',string) #将匹配项替换为...['am', ' m']
<re.Match object; span=(4, 7), match='y i'>
['Today', 'is', 'March', '8,', '2024.', 'I', 'am', 'reviewing', 'my', 'course.']
Today is March eighth, 2024. I am reviewing my course.

NLTK
Q:What is NLTK?
A:NLTK(Natural Language Toolkit) is the primary python API for NLP which contains useful functions for preprocessing.
NLTK(Natural Language Toolkit)是用于自然语言处理的主要Python API,其中包含了一些对于预处理非常有用的函数。
Examples include:
Tokenization
Stop word removal
Lemmatization/Stemming
Tagging POS(parts of speech)
>pip install NLTK
Tokenization 分词
▪ Tokenization refers to separating a piece of text into smaller ‘tokens’.
▪ Tokens can be words, characters or subwords(n-gram).
▪ The most common form of tokenization is to use space as a delimiter, resulting in individualwords forming tokens.
-
分词指的是将一段文本分割成更小的“令牌”(tokens)。
-
令牌可以是单词、字符或子词(n-gram)。
-
分词的最常见形式是使用空格作为分隔符,从而将单个单词分割成令牌。
Stemming 词干提取
▪ It is the process of reducing inflected words to their ‘stem’
▪ Stemming removes the last few characters of a given word to obtain a shorter form.(Note, sometimes this form may not carry any meaning.)
-
词干提取是将屈折变化的词汇还原为其“词干”的过程。
-
词干提取通过移除给定单词的最后几个字符来获得更短的形式。(注意,有时这种形式可能不携带任何意义。
Advantages 优势
▪ Improved model performance:Stemming reduces the number of uniquewords that the algorithm needs toprocess.
▪ Grouping of similar words:Words with a similar meaning can begrouped together even if they possessdifferent forms.
▪ Reduces complexity of text:Stemming reduces the size of thevocabulary, hence making texts easier toanalyze and understand.
- 提高模型性能:词干提取减少了算法需要处理的唯一词汇数量。
- 相似词汇的分组:即使词汇形式不同,具有相似含义的词也可以被分组在一起。
- 减少文本复杂性:词干提取减少了词汇量的大小,因此使文本更易于分析和理解。
Disadvantages 劣势
▪ Overstemming:The algorithm may reduce unrelated words to the same word stem.E.g.: university, universal, universe == universi.
▪ Understemming:The algorithm does not reduce the word enough, resulting insynonyms bearing different stems.E.g.: alumnus, alumni, alumnae are not reduced to the same stem.
▪ Language Challenges:As the target language's morphology, spelling, and characterencoding get more complicated, stemmers become more difficultto design.E.g. French, having a larger number of verb inflections, will requirea more complicated stemmer than English.
- 过度词干提取:算法可能将不相关的词缩减为相同的词干。例如:university(大学)、universal(普遍的)、universe(宇宙)== universi。
- 词干提取不足:算法没有足够减少单词,导致具有不同词干的同义词。例如:alumnus(男校友)、alumni(校友)、alumnae(女校友)没有被缩减为相同的词干。
- 语言挑战:随着目标语言的形态学、拼写和字符编码变得更加复杂,词干提取器的设计变得更加困难。例如,法语有更多的动词变形,将需要比英语更复杂的词干提取器。
Lemmatization 词形还原
▪ It is the process of reducing inflected words to their ‘lemma’(dictionary form).
▪ As opposed to stemming, lemmatization aims to remove ONLY the inflectional ends ofwords, returning its dictionary form.
-
词形还原是将屈折变化的词还原为其“词元”(字典形式)的过程。
-
与词干提取不同,词形还原旨在仅移除单词的屈折变化结尾,返回其字典形式。
Advantages 优势
▪ AccuracyAs the word’s Part-Of-Speech(POS) is taken intoconsideration, the word’s contextis considered when lemmatizingthe word, resulting in a moreaccurate shortening of the word.
- 准确性:由于在进行词形还原时考虑了单词的词性(Part-Of-Speech, POS),因此在词形还原过程中会考虑单词的上下文,从而导致单词缩短更加准确。
Disadvantages 劣势
▪ Time-consumingLemmatization is slow and time-consuming when compared tostemming, as morphologicalanalysis is conducted on eachword to derive its meaning.
- 耗时:与词干提取相比,词形还原过程缓慢且耗时,因为需要对每个单词进行形态分析以推导其含义。
BOW 词袋模型
▪ A representation of text that describes the occurrence of words within a document.
▪ Only word counts are retained, grammatical details and word order are discarded.
▪ Considered a ‘bag’ as all information about order and grammar are discarded.
▪ Converts unstructured text into structured data in the form of fixed length vectors.
-
文本的一种表示方式,描述了单词在文档中的出现频率。
-
仅保留单词计数,语法细节和单词顺序被忽略。
-
被视为一个“袋子”,因为所有关于顺序和语法的信息都被舍弃。
-
将非结构化文本转换为固定长度向量的形式,即结构化数据。
N-grams N元组
▪ A contiguous sequences of items that are collected from a sequence of text or speech corpus.
▪ The ‘n’ in n-grams specify the number of tokens considered.
-
连续的项序列,从文本或语言语料库的序列中收集而来。
-
“n”在n-grams中指定了考虑的令牌数量
总结
Preprocessing techniques including:
- RegEx:A sequence of characters used to match, search, andmanipulate patterns in text strings.
- Stemming:The process of reducing words to their base or root form tosimplify text analysis and improve information retrieval innatural language processing.
- Lemmatization:The process of converting words to their base or dictionaryform (lemmas) to maintain the grammatical meaning andimprove language understanding in natural language processing.
-
RegEx:一系列字符,用于在文本字符串中匹配、搜索和操作模式。
-
词干提取:将单词还原到它们的基础或根形式以简化文本分析并在自然语言处理中改善信息检索的过程。
-
词形还原:将单词转换为它们的基础或字典形式(词元)以保持语法含义并在自然语言处理中改善语言理解的过程。
Key points discussed this week:
▪ NLTK:
A Python library that provides tools and resources for processing and analysing human language data.
一个提供用于处理和分析人类语言数据的工具和资源的Python库。
▪ Basic language models including:
- Bag of Words:A simple and commonly used text representation model that converts documents into vectors, disregarding grammar and word order, by counting the frequency of each word.
- N-grams:Contiguous sequences of n words in a text, used in language modeling and text analysis to capture local context andrelationships between words.
-
词袋模型:一种简单且常用的文本表示模型,通过计算每个单词的频率,将文档转换为向量,同时忽略语法和单词顺序。文章来源:https://www.toymoban.com/news/detail-843637.html
-
N-grams:文本中连续的n个单词序列,在语言建模和文本分析中用于捕捉局部上下文和单词之间的关系。文章来源地址https://www.toymoban.com/news/detail-843637.html
到了这里,关于EE6405-Natural Language Processing Week 1(LEC)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!