Carl Hewitt 在1973年对Actor模型进行了如下定义:"Actor模型是一个把'Actor'作为并发计算的通用原语". Actor是异步驱动,可以并行和分布式部署及运行的最小颗粒。也就是说,它可以被分配,分布,调度到不同的CPU,不同的节点,乃至不同的时间片上运行,而不影响最终的结果。因此Actor在空间(分布式)和时间(异步驱动)上解耦的。而Akka是Lightbend(前身是Typesafe)公司在JVM上的Actor模型的实现。我们在了解actor模型之前,首先来了解actor模型主要是为了解决什么样的问题。
在akka系统的官网上主要介绍了现代并发编程模型所遇到的问题,里面主要提到了三个点
1) 在面向对象的语言中一个显著的特点是封装,然后通过对象提供的一些方法来操作其状态,但是共享内存的模型下,多线程对共享对象的并发访问会造成并发安全问题。一般会采用加锁的方式去解决
加锁会带来一些问题
- 加锁的开销很大,线程上下文切换的开销大
- 加锁导致线程block,无法去执行其他的工作,被block无法执行的线程,其实也是占据了一种系统资源
- 加锁在编程语言层面无法防止隐藏的死锁问题
2)Java中并发模型是通过共享内存来实现,cpu中会利用cache来加速主存的访问,为了解决缓存不一致的问题,在java中一般会通过使用volatile或者Atmoic来标记变量,让jmm的happens before机制来保障多线程间共享变量的可见性。因此从某种意义上来说是没有共享内存的,而是通过cpu将cache line的数据刷新到主存的方式来实现可见。 因此与其去通过标记共享变量或者加锁的方式,依赖cpu缓存更新,倒不如每个并发实例之间只保存local的变量,而在不同的实例之间通过message来传递。
3)call stack的问题 当我们编程模型异步化之后,还有一个比较大的问题是调用栈转移的问题,如下图中主线程提交了一个异步任务到队列中,Worker thread 从队列提取任务执行,调用栈就变成了workthread发起的,当任务出现异常时,处理和排查就变得困难。
那么akka 的actor的模型是怎样处理这些问题的,actor模型中的抽象主体变为了actor,
- actor之间可以互相发送message。
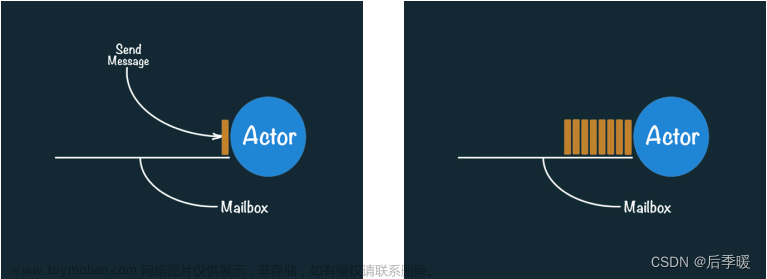
- actor在收到message之后会将其存入其绑定的Mailbox中。
- Actor中Mailbox中提取消息,执行内部方法,修改内部状态。
- 继续给其他actor发送message。
可以看到下图,actor内部的执行流程是顺序的,同一时刻只有一个message在进行处理,也就是actor的内部逻辑可以实现无锁化的编程。actor和线程数解耦,可以创建很多actor绑定一个线程池来进行处理,no lock,no block的方式能减少资源开销,并提升并发的性能

通俗解释:
在Actor模型中,actor是一个并发原语,简单的说,一个actor就是一个工人,与进程或线程一样都能够工作或处理任务。其实这还有点不好理解,我们可以把它想象成面向对象编程语言中的一个对象实例。在OOP中一个对象可以访问或修改另一个对象的属性,也可以直接调用另一个对象的方法。例如下图,person1给person2发送了一个消息,直接调用方法就行了。深入底层执行逻辑的话,结果就是JVM转到sayHello的代码区,一步步执行。
public class HelloWorld {
private String name = "";
public HelloWorld(String name){
this.name = name;
}
public String getName(){
return this.name;
}
public void sayHello(HelloWorld to, String msg){
System.out.println(to.getName()+" 收到 "+name+" 的消息:"+ msg);
}
}
public class OOPInvoke {
public static void main( String[] args ) {
HelloWorld person1 = new HelloWorld("Person1");
HelloWorld person2 = new HelloWorld("Person2");
person1.sayHello(person2,"Hello world");
}
}sayHello在一个线程中执行基本没有问题,但是多个线程执行时,就可能出问题了,因为在执行sayHello的时候person2的name值可能被其他线程修改。这是一个name字段,意外修改没有关系,但如果是一个金额字段呢?
actor和对象的不同之处在于,actor的状态不能直接读取、修改,actor的方法不能直接调用。actor只能通过消息传递的方式与外界通信。
每个对象都有一个this指针,代表对象的地址,可以通过该地址调用方法或存取状态;
与此类似,actor也有一个代表本身的地址,但只能向该地址发送消息。
简单点说,actor通过消息传递的方式与外界通信。消息传递是异步的。每个actor都有一个邮箱,该邮箱接收并缓存其他actor发过来的消息,actor一次只能同步处理一个消息,处理消息过程中,除了可以接收消息,不能做任何其他操作。这就是actor模型的本质。
Actor模型的另一个好处就是可以消除共享状态,因为它每次只能处理一条消息,所以actor内部可以安全的处理状态,而不用考虑锁机制。
说白了如果是个普通对象,它内部是异步的,你获取到的名字,或者金额等属性可能在前面0.1s被异步修改过了,所以你是在错误的值上进行修改,然后得到一个可能错误的值。比如本来100,你想要加20,但它被异步修改成50,你还是100+20 = 120,实际上应该是50+20 = 70。但是actor内部就是同步的,你是先获取,再修改,或者先修改,在获取,是固定的,安全的。
Flink内部节点之间的通信是用Akka,比如JobManager和TaskManager之间的通信。而operator之间的数据传输是利用Netty。
Flink通过Akka进行的分布式通信的实现,在0.9版中采用。使用Akka,所有远程过程调用现在都实现为异步消息。这主要影响组件JobManager,TaskManager 和JobClient。将来,甚至有可能将更多的组件转换为参与者,从而允许它们发送和处理异步消息。
RPC框架是Flink任务运行的基础,Flink整个RPC框架基于Akka实现,并对Akka中的ActorSystem、Actor进行了封装和使用,Flink整个通信框架的组件主要由RpcEndpoint、RpcService、RpcServer、AkkaInvocationHandler、AkkaRpcActor等构成。RpcEndpoint定义了一个Actor的路径;RpcService提供了启动RpcServer、执行代码体等方法;RpcServer/AkkaInvocationHandler提供了与Actor通信的接口;AkkaRpcActor为Flink封装的Actor。
一、Akka与Actor模型
Akka是一个开发并发、容错和可伸缩应用的框架。它是Actor Model的一个实现,和Erlang的并发模型很像。在Actor模型中,所有的实体被认为是独立的actors。actors和其他actors通过发送异步消息通信。Actor模型的强大来自于异步。它也可以显式等待响应,这使得可以执行同步操作。但是,强烈不建议同步消息,因为它们限制了系统的伸缩性。每个actor有一个邮箱(mailbox),它收到的消息存储在里面。另外,每一个actor维护自身单独的状态。一个Actors网络如下所示:

每个actor是一个单一的线程,它不断地从其邮箱中poll(拉取)消息,并且连续不断地处理。对于已经处理过的消息的结果,actor可以改变它自身的内部状态或者发送一个新消息或者孵化一个新的actor。
1、 Actor系统
一个Actor系统包含了所有存活的actors。它提供的共享服务包括调度、配置和日志等。Actor系统同时包含一个线程池,所有actor从这里获取线程。
多个Actor系统可以在一台机器上共存。如果一个Actor系统通过RemoteActorRefProvider启动,它就可以被其他机器上的Actor系统发现。Actor系统能够自动识别消息是发送给本地机器还是远程机器的Actor系统。在本地通信的情况下,消息通过共享存储器高效的传输。在远程通信的情况下,消息通过网络栈发送。
所有Actors都是继承来组织的。每个新创建的actor将其创建的actor视作父actor。继承被用来监督。每个父actor对自己的子actor负责监督。如果在一个子actor发生错误,父actor将会收到通知。如果这个父actor可以解决这个问题,它就重新启动这个子actor。如果这个错误父actor无法处理,它可以把这个错误传递给自己的父actor。
第一个actor通过系统创建,由/user 这个actor负责监督。详细的Actor的继承制度可以参考https://doc.akka.io//docs/akka/snapshot/general/supervision.html。
2、 Flink中的Actor
Actor是一个包含状态和行为的容器。actor线程顺序处理收到的消息。这样就让用户摆脱锁和线程管理的管理,因为一次只有一个线程对一个actor有效。但是,必须确保只有这个actor线程可以处理其内部状态。Actor的行为由receive函数定义,该函数包含收到的消息的处理逻辑。
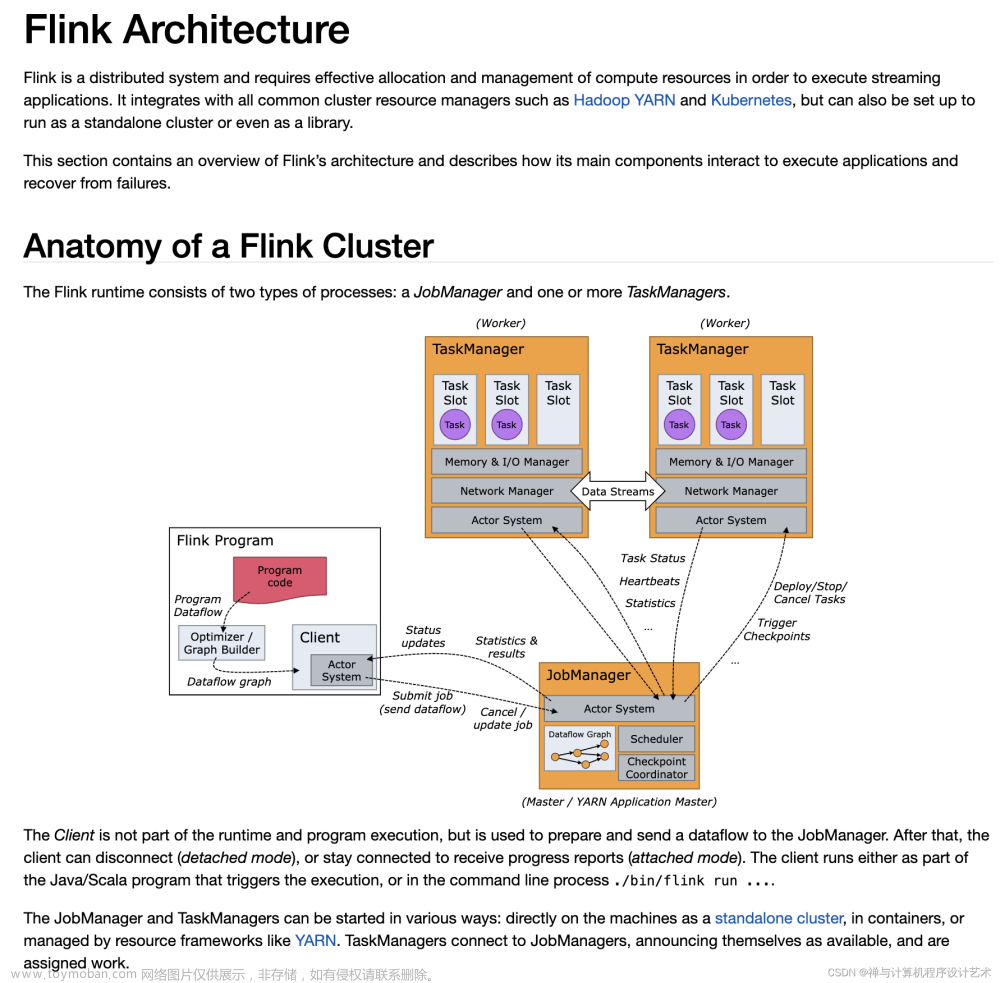
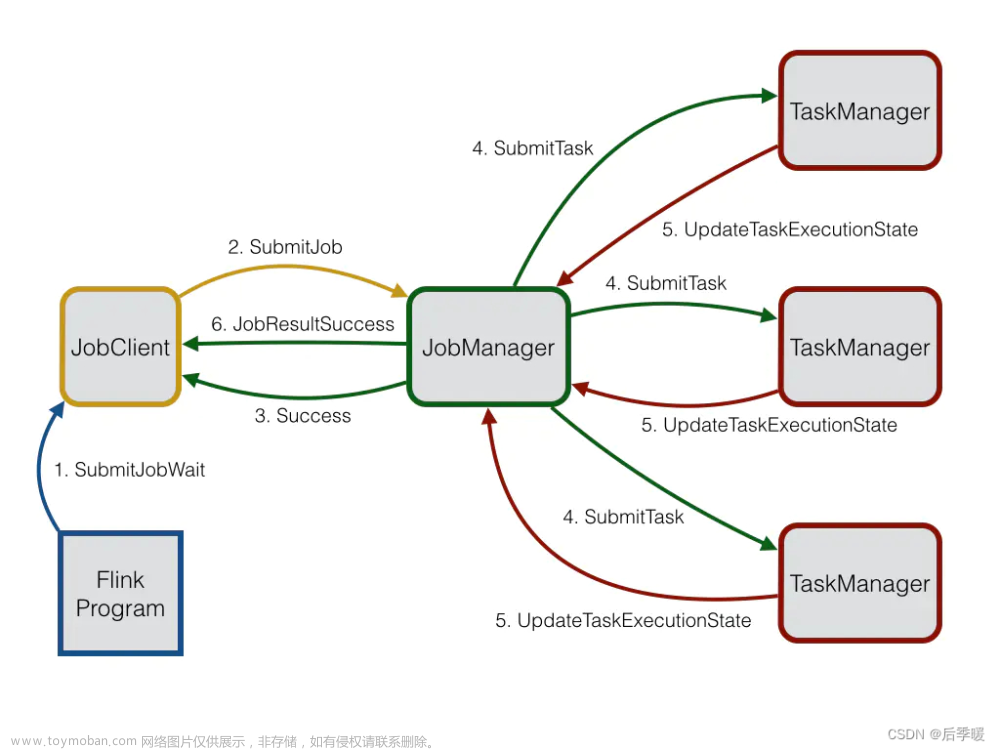
Flink系统由3个分布式组件构成:JobClient,JobManager和TaskManager。JobClient从用户处得到Flink Job,并提交给JobManager。JobManager策划这个job的执行。首先,它分配所需的资源,主要就是TaskManagers上要执行的slot。
在资源分配之后,JobManager部署单独的任务到响应的TaskManager上。一旦收到一个任务,TaskManager产生一个线程用来执行这个任务。状态的改变,比如开始计算或者完成计算,将被发送回JobManager。基于这些状态的更新,JobManager将引导这个job的执行直到完成。一旦一个job被执行完,其结果将会被发送回JobClient。Job的执行图如下所示:
3、 异步VS同步消息
在任何地方,Flink尝试使用异步消息和通过futures来处理响应。Futures和很少的几个阻塞调用有一个超时时间,以防操作失败。这是为了防止死锁,当消息丢失或者分布式足觉crash。但是,如果在一个大集群或者慢网络的情况下,超时可能会使得情况更糟。因此,操作的超时时间可以通过“akka.timeout.timeout”来配置。
在两个actor可以通信之前,需要获取一个ActorRef。这个操作的查找同样需要一个超时。为了使得系统尽可能快速的失败,如果一个actor还没开始,超时时间需要被设置的比较小。为了以防经历查询超时,可以通过“akka.lookup.timeout”配置增加查询时间。
Akka的另一个特点是限制发送的最大消息大小。原因是它保留了同样数据大小的序列化buffer和不想浪费空间。如果你曾经遇到过传输失败,因为消息超过了最大大小,你可以增加“akka.framesize”配置来增加大小。
下面分别是JobManager和TaskManager的概念图:
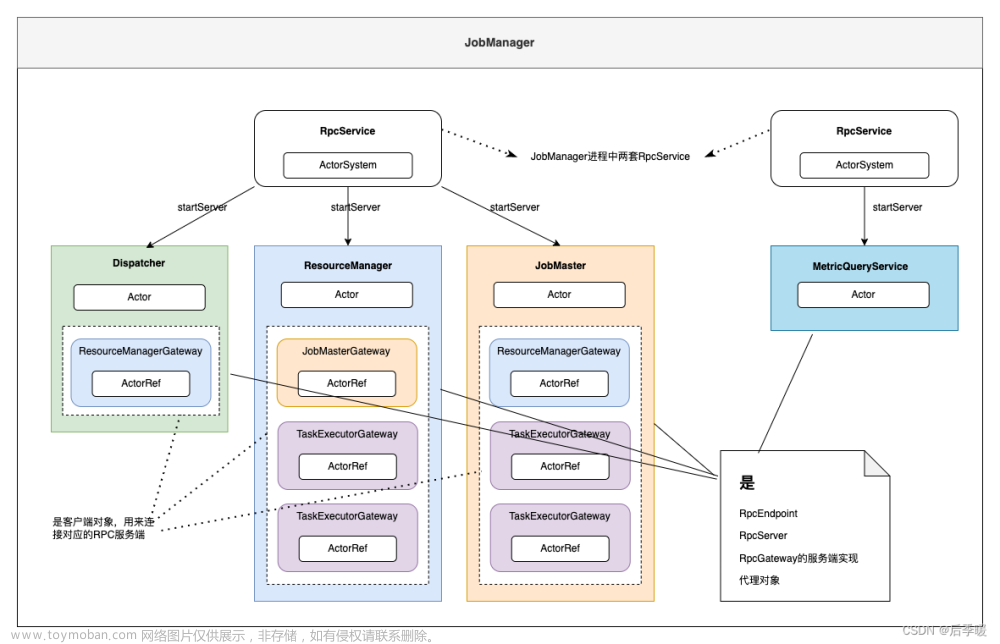

其中Dispatcher、ResourceManager、JobMaster是JobManager进程中的Rpc服务,TaskExecutor是TaskManager进程中的Rpc服务,MetricQueryService在JobManager和TaskManager进程中都有。
RpcGateway
- 用于定义RPC协议,是客户端和服务端沟通的桥梁。
- 服务端实现了RPC协议,即实现了接口中定义的方法,做具体的业务逻辑处理。
- 客户端实现了RPC协议,客户端是Proxy生成的代理对象,将对RpcGateway接口方法的调用转为Akka的消息发送。
RpcEndpoint
- RPC服务端的抽象,实现了该接口即为Rpc服务端,是Akka中Actor的封装。
- Actor收到ActorRef发送的消息(消息被封装为RpcInvocation对象),会通过RpcInvocation对象中的方法、参数等信息以反射的方式调用RpcGateway接口对应的方法。
RpcService
- 是 RpcEndpoint 的运行时环境,是Akka中ActorSystem的封装。
- 一个ActorSystem系统中有多个Actor,同样在Flink中一个RpcService中有多个RpcEndpoint,即多个Rpc服务。
- Flink中RpcService也有多套,JobManager和TaskManager进程中都有两套RpcService。
- RpcService 提供了启动Rpc服务(startServer)、停止Rpc服务(stopServer)、连接远端Rpc服务等方法。
- 实现类是AkkaRpcService,内有属性ActorSystem actorSystem,Map<ActorRef, RpcEndpoint> actors。
RpcServer
是Rpc服务端自身的代理对象,设计上是供服务端调用自身非Rpc方法。
二、使用Akka
Akka系统的核心ActorSystem和Actor,若需构建一个Akka系统,首先需要创建ActorSystem,创建完ActorSystem后,可通过其创建Actor(注意:Akka不允许直接new一个Actor,只能通过 Akka 提供的某些 API 才能创建或查找 Actor,一般会通过 ActorSystem#actorOf和ActorContext#actorOf来创建 Actor),另外,我们只能通过ActorRef(Actor的引用,其对原生的 Actor 实例做了良好的封装,外界不能随意修改其内部状态)来与Actor进行通信。如下代码展示了如何配置一个Akka系统。
// 1. 构建ActorSystem
// 使用缺省配置
ActorSystem system = ActorSystem.create("sys");
// 也可显示指定appsys配置
ActorSystem system1 = ActorSystem.create("helloakka",ConfigFactory.load("appsys"));
// 2. 构建Actor,获取该Actor的引用,即
ActorRefActorRef helloActor = system.actorOf(Props.create(HelloActor.class),"helloActor");
// 3. 给helloActor发送消息
helloActor.tell("hello helloActor", ActorRef.noSender());
// 4. 关闭
ActorSystemsystem.terminate();1、 Actor路径
在Akka中,创建的每个Actor都有自己的路径,该路径遵循ActorSystem 的层级结构,大致如下:
1)本地路径
在上面代码中,本地Actor路径为 akka://sys/user/helloActor
含义如下:
-
sys,创建的ActorSystem的名字;
-
user,通过ActorSystem#actorOf和ActorContext#actorOf 方法创建的 Actor 都属于/user下,与/user对应的是/system, 其是系统层面创建的,与系统整体行为有关,在开发阶段并不需要对其过多关注
-
helloActor,我们创建的HelloActor
2)远程路径
在上面代码中,远程Actor路径为 akka.tcp://sys@l27.0.0.1:2020/user/remoteActor
含义如下:
-
akka.tcp,远程通信方式为tcp;
-
sys@127.0.0.1:2020,ActorSystem名字及远程主机ip和端口号。
-
user,与本地的含义一样
-
remoteActor,创建的远程Actor
2、 获取Actor
若提供了Actor的路径,可以通过路径获取到ActorRef,然后与之通信,代码如下所示:
ActorSystem system = ActorSystem.create("sys");
ActorSelection as= system.actorSelection("/path/to/actor");
Timeout timeout =new Timeout(Duration.create(2, "seconds"));
Future<ActorRef> fu = as.resolveOne(timeout);
fu.onSuccess(newOnSuccess<ActorRef>() {
@Overridepublic void onSuccess(ActorRef actor) {
System.out.println("actor:" +actor);
actor.tell("hello actor",ActorRef.noSender());
}
},system.dispatcher());
fu.onFailure(newOnFailure() {
@Override public void onFailure(Throwable failure) {
System.out.println("failure:" +failure); }
},system.dispatcher()
);若需要与远端Actor通信,路径中必须提供ip:port。
三、Actor通信
Akka有两种核心的异步通信方式:tell和ask。
1、 Tell方式
当使用tell方式时,表示仅仅使用异步方式给某个Actor发送消息,无需等待Actor的响应结果,并且也不会阻塞后续代码的运行,如:
helloActor.tell("hellohelloActor", ActorRef.noSender());
其中:第一个参数为消息,它可以是任何可序列化的数据或对象,第二个参数表示发送者,通常来讲是另外一个 Actor 的引用, ActorRef.noSender()表示无发送者((实际上是一个叫做deadLetters的Actor)。
2、 Ask方式
当我们需要从Actor获取响应结果时,可使用ask方法,ask方法会将返回结果包装在scala.concurrent.Future中,然后通过异步回调获取返回结果。如调用方:
// 异步发送消息给Actor,并获取响应结果
Future<Object> fu = Patterns.ask(printerActor, "hello helloActor", timeout);
fu.onComplete(newOnComplete<Object>() {
@Overridepublic void onComplete(Throwable failure, String success) throws Throwable {
if (failure != null) {
System.out.println("failure is " + failure); }
else { System.out.println("success is " + success); }
}
},system.dispatcher());HelloActor处理消息方法的代码大致如下:
private void handleMessage(Object object) {
if (objectinstanceof String) {
String str = (String)object;
log.info("[HelloActor] message is {},sender is {}", str, getSender().path().toString());
// 给发送者发送消息
getSender().tell(str, getSelf());
}
}上面主要介绍了Akka中的ActorSystem、Actor,及与Actor的通信;Flink借此构建了其底层通信系统。文章来源:https://www.toymoban.com/news/detail-843726.html
参考:Flink源码分析之RPC通信-腾讯云开发者社区-腾讯云 (tencent.com)文章来源地址https://www.toymoban.com/news/detail-843726.html
到了这里,关于Flink通讯模型—Akka与Actor模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!