参考:《计算机视觉中的深度学习》
概述
目标检测的挑战:
- 减少目标定位的准确度
- 减少背景干扰
- 提高目标定位的准确度
目标检测系统常用评价指标:检测速度和精度
提高精度:有效排除背景,光照和噪声的影响
提高检测速度:精简检测流程,简化图像处理算法
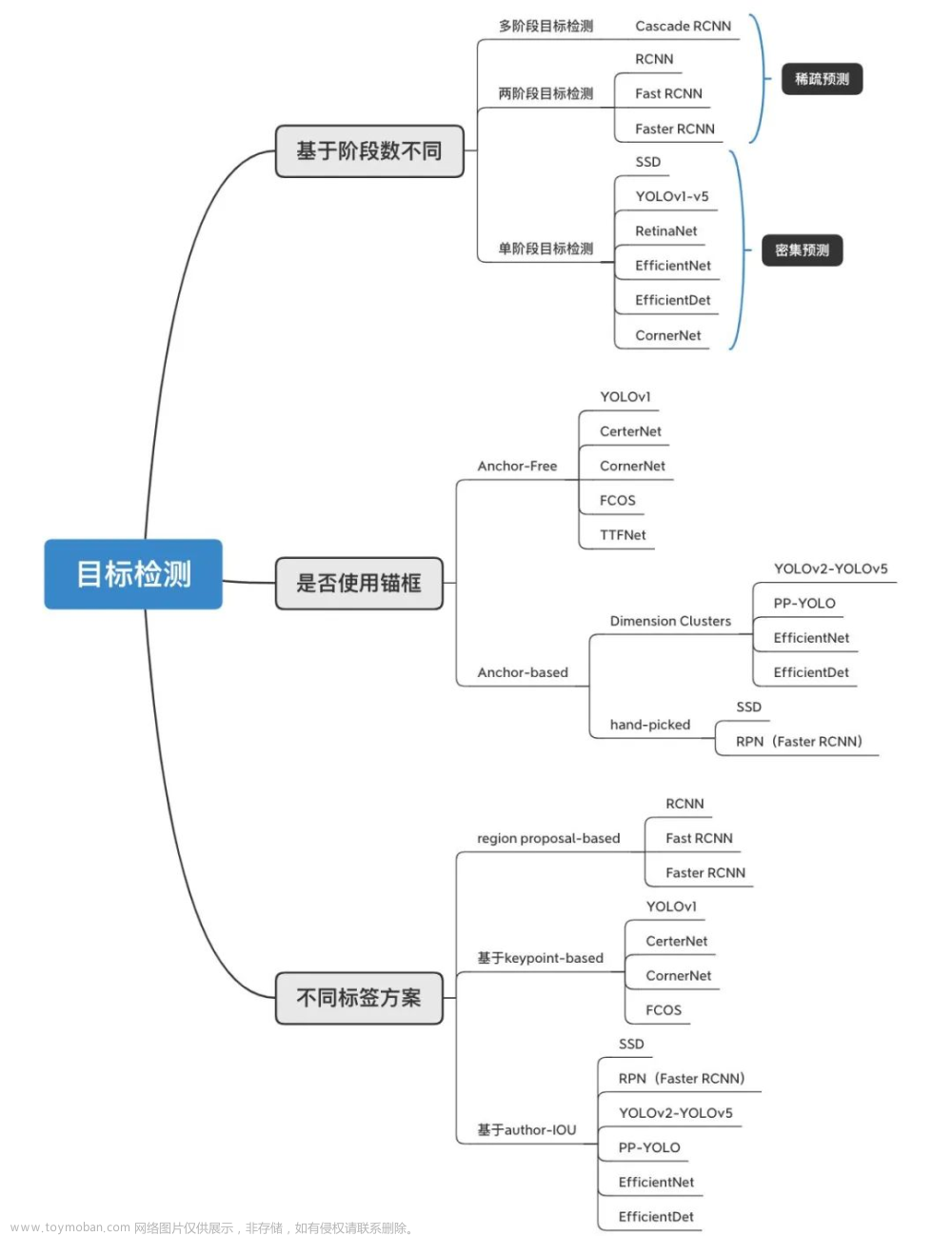
算法概述:传统目标算法、基于候选区域的两步算法、基于回归的单步算法
1.传统目标算法
对于区域选择,传统目标检测最常用的两种模型是滑动窗口模型与缩放窗口模型。滑动窗口模型,顾名思义,是通过设计好的窗口在图像上进行滑动来检测目标。基于滑动窗的检测算法的主要实现方法有两种,分别为缩放检测图像法和缩放窗口法。缩放检测图像法将待检图像进行不同尺度的缩放,形成一个缩放图像集,然后用固定大小的滑动窗口扫描缩放图像集中的每幅图像,利用训练好的分类器对扫描窗口进行判定,将目标窗口标记出来得到最终结果;缩放窗口法,其改变前一种算法对图像进行缩放的思想,改为对窗口进行缩放,利用多种尺度和移动步长的扫描窗口扫描待检图像,最终同样利用分类器进行判定并输出结果。
2、基于候选区域的两步算法
基于候选区域的目标检测算法指需要两步实现的采用 CNN 的目标检测方法。首先需要进行区域生成(region proposal),获得有可能包含待检物体的候选框:然后对对应区域使用 CNN 对特征进行提取;再对样本分类:最后回归候选框使其包含区域更加精确。总体流程可归纳为“区域生成一特征提取→分类及定位回归一后处理”
该类算法使用候选区域替代原有的滑动窗口来实现特征区域的提取。基于候选区域的两步算法的目的是:在几乎所有目标物体都有能够区别于背景信息的特性的前提下,找到目标物体可能的存在位置,作为候选区域的形式输出;再对这些候选区域提取特征向量,利用训练好的分类器判定候选区域是否包含目标物体并输出结果。这样做的优点在于大大减少了需要提取特征的图像块,可以使用复杂的特征和分类器对目标物体进行描述,以此提高目标检测的性能。
该类算法通过将候选区域选取与特征提取两个步骤加入深度学习优化框架中,实现了端到端的优化,相较于传统方法得到了更优秀的结果。
3.基于回归的单步算法
Faster R-CNN作为基于候选区域的目标检测算法的经典代表,将一直以来分离的候选区域选取和卷积网络融为一个整体,使用端到端网络进行目标检测。这样的处理使得模型在速度上和精度上都得到了有效的提高。虽然在一定程度上解决了效率问题,但 FasteR-CNN 还是达不到实时的目标检测的要求。因此,虽然候选区域算法和 CNN 极大地推动了目标检测的发展,但是候选区域的生成需要耗费大量时间,达不到实时检测的要求,这使得候选区域成为实时检测的瓶颈。
2015 年提出的 YOLO(You Only Look Once)!模型将目标检测问题看成一个回归问题,把输入图像分割成边界框和相应类别的概率。YOLO模型使用单一的网络,能够直接从整幅图像输出预测边界框和所属类别的概率。因为整个检测在同一个网络内进行,所以它可以实现真正的端到端的训练和检测,还能够达到实时目标检测的要求。YOLO模型把目标框的生成与识别进行结合,可以做到一步输出。由于没有候选区域的限制,模型能够考虑更多的上下文信息,从而在很大程度上减少背景样本的干扰,更能够满足目标检测应用领域对实时性的要求。然而 YOLO 模型是通过提取整幅图像的特征来预测边框的,而在许多图像中背景区域远远大于目标区域,这使得这类没有候选区域的目标检测算法在一些滉下表现并不好,因此 YOLO 模型在精度上比 Faster R-CNN 等基于候选区域的模型略微逊色,但是速度上的巨大提升依然体现出基于回归的但不算法潜力,随后推出的SSD,YOLO哥哥版本改进都推动了基于回归的单步算法改进
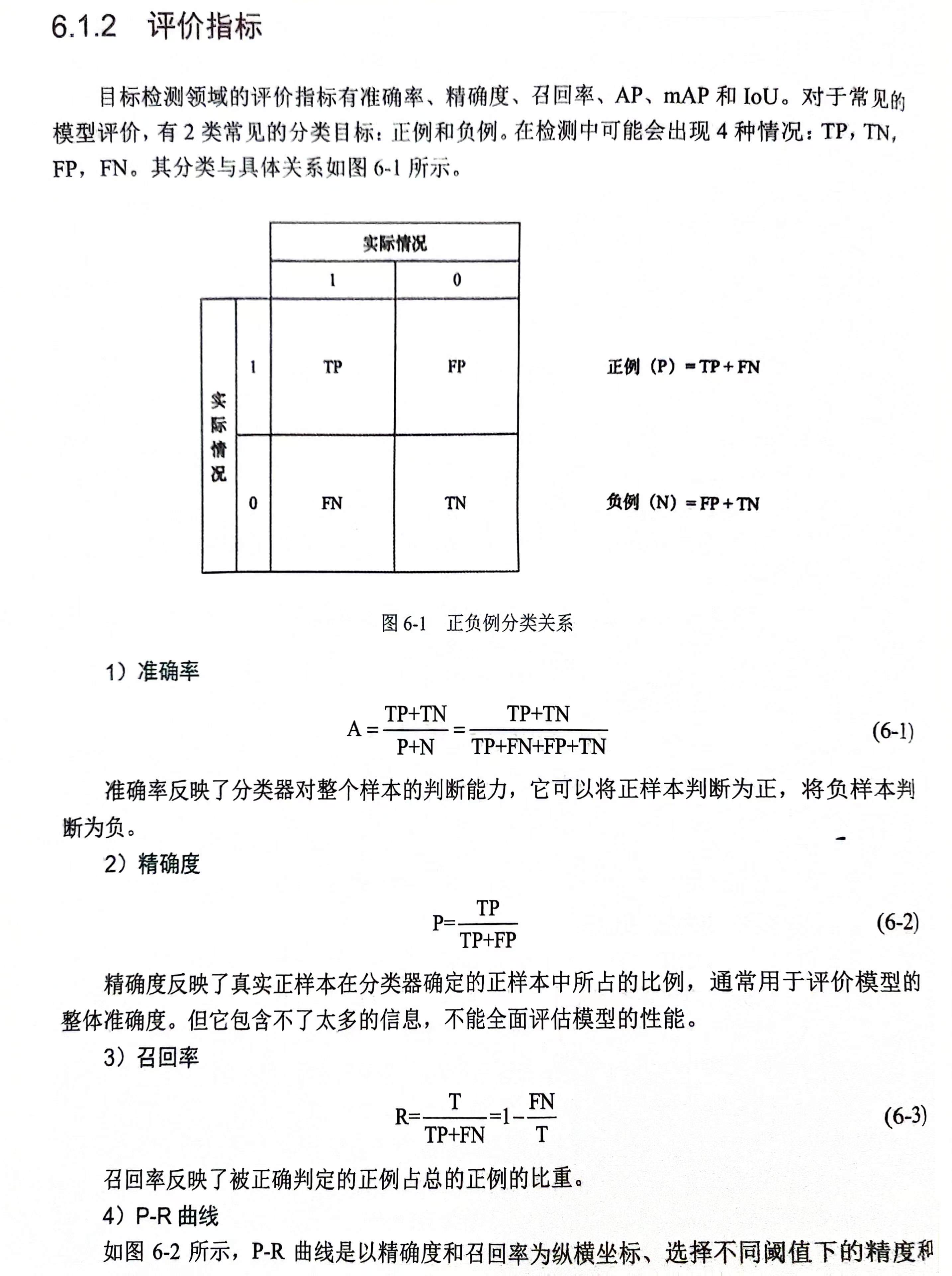
评价指标
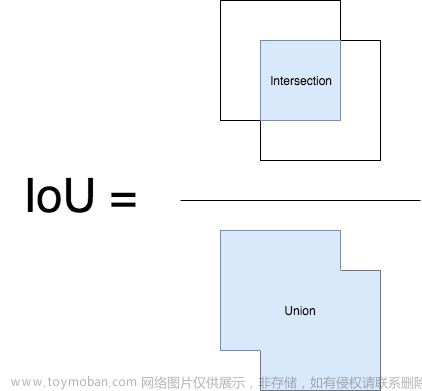
准确率,精确度,召回率,AP,mAP,IOU

传统目标检测算法

找到一个划分超平面,让训练样本与超平面之间有最大距离间隔,保证分类结果健壮性。
2.AdaBoost
AdaBoost 算法是 Boosting 算法的改进版,其核心思想是将多个弱分类器组合起来构成强分类器,且这些弱分类器是针对同一训练集训练的。在训练的过程中,首先赋予训练样本相同的初始权值。在经过不同的弱分类器过程中,样本分类的准确度决定了该样本的权重值,即样本若被正确分类,则在构建下一级分类器时其权重值降低,选中的概率随之减小,反之提高。这样使得在构建分类器的过程中更加关注被错误分类的样本,错误样本在不断地经过分类器训练后,被正确分类的概率提高,最终达到提高分类器准确度的目的。
基于候选区域的两步算法
候选区域的思想与图像兴趣点检测的思想类似,图像兴趣点利用人们自动将注意力放在一幅图像中最显著且最具分辨力的位置上的视觉特性,计算出这些点的位置,这大大减少了后续图像处理的计算量:类似地,目标候选区域通过计算出可能存在目标物体的窗口,这大大减少了目标检测计算量。
6.3.1 R-CNN 的实现
R-CNN(Region-CNN)3]是Ross Girshick于 2013年提出的基于候选区域的 CNN 结构。该网络首次表明,将CNN与候选区域和特征提取结合,能够比手工特征提取在目标检测网络上得到更好的性能,深度学习方法也自此在目标检测领域确立了绝对的优势。其检测过程如图 6-7,具体如下
① 利用选择性搜索(Selective Search)算法对输入图像进行区域选择,提取 2000个左右的候选区域。
②)由于网络结构中存在全连接层,需要将提取出的候选区域统一尺寸,此处将尺寸缩放至 227 像素x227 像素,再适当扩大以获取更多上下文信息。
③ 使用卷积网络对每个归一化后的候选区域做特征提取操作,从每个候选区域提取4096 维的特征向量。
④)使用 SVM 对提取到的特征进行分类识别,
⑤使用边框回归(Bounding Box Regression)微调边框位置:



基于回归的单步算法
2015年提出的Yolo【You Only Look Once】模型将目标检测问题看成一个回归问题,把输入图像分割成边界框和相应类别的概率。
YOLO算法本质:将图片特征均匀分成n*n不重叠区域,每个区域生成锚框,对每个区域做softmax和bounding box预测。
优点:
- 端到端训练(End-to-End Training):YOLO直接从整张图片预测边界框和类别,不需要复杂的多步骤流程,简化了训练过程,使得模型更加紧凑和高效。比SSD还简单
- 整体上下文感知(Context Awareness):由于YOLO在整个图像上进行全局预测,因此它可以更好地捕捉到目标间的空间关系和全局上下文信息
- 实时性(Speed):YOLO算法的核心优势在于其快速的检测速度。通过一次性对整个图像进行预测,而不是像滑动窗口或多阶段检测那样逐个区域处理,大大减少了计算量,从而实现了接近实时甚至实时的检测速度。
缺点:
-
对小物体检测精度不高:
由于YOLO算法将输入图像划分为固定的格子(grid cells),每个格子负责预测一定数量的边界框(bounding boxes)。对于较小的目标,它们可能会落在一个格子的较小部分,导致预测的边界框不够精确或者漏检。YOLO早期版本可能存在网格划分过粗的问题,导致对小目标特征提取不足。
-
对重叠和密集物体检测不佳:
YOLO在面对紧密排列或严重重叠的目标时,可能出现分配错误的问题,即一个格子可能无法准确地为多个相互覆盖的目标分别生成合适的边界框。 -
精度相对较低:
相比于两阶段检测器如Faster R-CNN,在同等条件下,YOLO可能牺牲了一定的定位精度以换取速度。特别是在早期版本中,YOLO在回归边界框的位置和尺寸时的误差较大,从而影响最终检测的精度。
随着YOLO算法的迭代更新,比如YOLOv3以及后续版本,针对上述部分问题进行了改进,如引入多尺度预测机制以提高对不同尺寸目标的检测性能,采用更好的主干网络架构增强特征提取能力,以及调整损失函数改善定位精度等措施。


在的关联性





约束力位置预测的范围后,网络参数变得更容易学习,网络变得稳定,与唯独聚类结合后,使用直接位置预测的 YOLOv2与手选锚框预测偏移值的方法相比,mAP 提高了约 5%。
6.多尺度训练
YOLO 的网络采用固定输入 448x448 像素,为了使输入图像能够实现多尺寸,YOLOv2每经过 10轮的训练,会重新选择图像的输入尺寸,图像的尺寸在320x320到608x608 像素之间,以 32的倍数递增,调整好图像尺寸后,调节网络到相应的维度继续进行训练。这种策略使得网络针对不同分辨率的图像可以更好地预测,更适用于实际的检测场景。此外,YOLOv2 还提出了一种新的分类骨干网 Darknet-19,它有 19个卷积层和五个最大池化层,处理图像所需的操作较少,但精度较高。以Resnet作为主干网的Faster R-CNN能实现 76.4%的 mAP 和5帧/秒,SSD500 能实现 76.8%的 mAP 和 19 帧/秒,而 Yolov2 能达到 78.6%的 mAP 和 40 帧/秒。如上所述,YOLOv2 可以实现高精度和高速度,这得益于七项主要的改进和一个新的主干网络。
YOLO 多个版本改进
YOLO算法各个版本的改进和效果
YOLO(You Only Look Once)算法自2016年首次提出以来,经历了多个重要版本的改进,每个版本都在速度、精度、小目标检测能力等方面有所突破。下面列举几个关键版本的改进点和效果:
-
YOLOv1
提出时间:2016年
主要特点:首次引入了端到端的目标检测方法,通过单次前向传播就能预测出图像中的多个边界框及其所属类别,实现了非常快的速度。
改进点:相比传统的多阶段检测方法,YOLO大幅度提升了检测速度,但精度相对较低,特别是对于小目标的检测效果一般。 -
YOLOv2
提出时间:2017年
主要改进:
引入了批量归一化(Batch Normalization),加快了训练速度并提高了模型的泛化能力。
使用了 anchor boxes(先验框)的概念,有助于更好定位不同尺寸和比例的目标。
采用了更高效的卷积层设计,比如使用了称为“Darknet-19”的新型网络结构。
实现了Anchor-based目标检测,提升了对多种尺寸目标的检测效果。
提出了维度聚类(Dimension Clusters)方法优化先验框的选择。
通过细粒度特征融合,整合了不同层次的特征图,增强了对小目标的检测能力。
效果:YOLOv2在保持较快的速度基础上,显著提高了检测精度。 -
YOLOv3
提出时间:2018年
主要改进:
使用了更深更大的网络结构Darknet-53作为基础网络,增加了特征提取的能力。
引入了多尺度预测机制,分别从不同分辨率的特征图上预测边界框,提升了对不同大小目标的适应性。
使用更多的锚框数量,进一步优化目标匹配策略。
对损失函数进行了调整,使模型在训练过程中能更好地平衡各种类型目标的学习。
效果:YOLOv3在保持实时性的同时,进一步提高了检测精度,尤其是对小目标的识别能力有了显著提升。 -
YOLOv4
提出时间:2020年
主要改进:
应用了更强大的Backbone网络CSPDarknet53,融合了Cross-Stage Partial Network (CSPNet) 架构,减少冗余计算,提高效率。
引入了Spatial Pyramid Pooling (SPP) 和 Path Aggregation Network (PANet),聚合多尺度特征,加强特征表达能力。
使用了Mish激活函数、DropBlock正则化等新技术优化模型性能。
在训练策略上使用了多种数据增强方法,以及CIOU loss来改进边界框定位误差。
效果:YOLOv4在各项指标上取得了重大突破,不仅保持了原有的实时性,而且在COCO数据集上的mAP(平均精度均值)大幅提高,成为当时性能极佳的实时目标检测模型。文章来源:https://www.toymoban.com/news/detail-843767.html -
YOLOv5
提出时间:2020年后
主要改进:
由 Ultralytics 团队开发,基于PyTorch框架实现,代码开源易于使用和扩展。
结构上继续优化,网络更为轻量化,针对移动端和嵌入式设备做了适配。
使用跨层特征融合和轻量级Backbone,例如CSPDarknet-tiny、CSPDarknet-S等。
在训练技巧上也有多项改进,包括对预训练权重的选择、数据增强策略、模型量化等方面。
效果:YOLOv5在保持实时性的同时,进一步提升了模型性能,尤其适合于对速度要求较高的应用场景,同时在资源受限的环境下也能良好运行。
总体来说,YOLO系列算法的每次升级都围绕着提高检测精度、优化小目标检测、提高运行速度和减轻模型体积等方面进行,不断推动着目标检测技术的发展。文章来源地址https://www.toymoban.com/news/detail-843767.html
到了这里,关于《计算机视觉中的深度学习》之目标检测算法原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!