faster-whisper 这个项目是基于 OpenAI whisper 的模型,在上面的一个重写。
使用的是 CTranslate2 的这样的一个库,CTranslate2 是用于 Transformer 模型的一个快速推理引擎。
在相同精度的情况下,faster-whisper 的速度比 OpenAI whisper 快 4 倍,并且使用更少的内存。

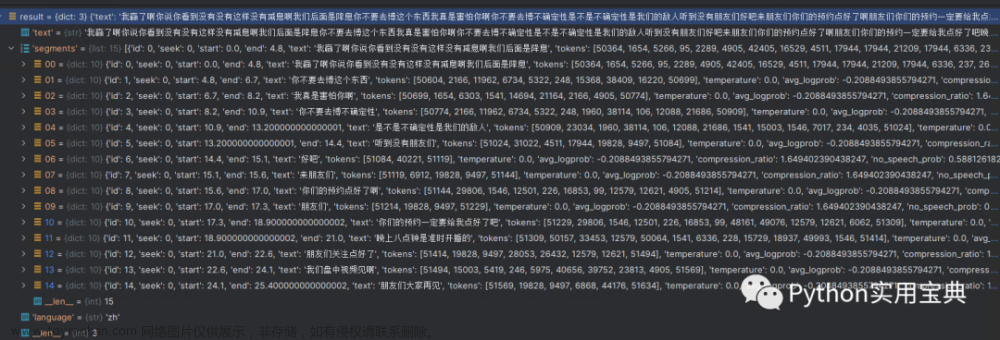
这是 faster-whisper 与 OpenAI whisper 的测试对比结果,使用了一个13分钟的音频做的测试。
OpenAI whisper 用了4分30秒,faster-whisper 只用了54秒。
并且,faster-whisper 使用的 CPU 和 GPU 都只有 OpenAI whisper 的三分之一左右。
性能大幅提升,资源占用大幅降低,就是马跑的更快了,吃的更少了。
感紧跑起来试试。
本地安装运行
faster-whisper 需要 Python 3.8 之后的版本,可以创建Python虚拟环境来实现。
安装 faster-whisper :
pip install faster-whisper
Python代码:
from faster_whisper import WhisperModel
# 指定模型
model_size = "large-v3"
# or run on CPU with INT8
model = WhisperModel(model_size, device="cpu", compute_type="int8")
# 加载音频,执行语音识别
segments, info = model.transcribe("Haul.mp3", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))

第一次执行时,会自动加载模型。

然后开始识别,输出识别结果。
以上是在 CPU 上的运行过程,如果想要更好的运行效率,自然是在 GPU 上跑。
想使用 GPU,需要安装一些辅助。
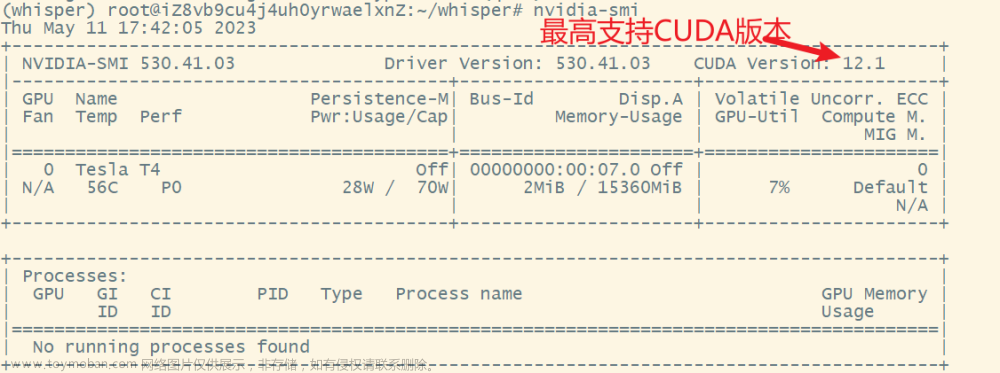
以 N 卡为例,先安装 NVIDIA 相关的东西。
打开网页:
developer.nvidia.com/cudnn
下载安装。
打开网页:
developer.nvidia.com/cuda-downloads
下载安装。
安装完成后,打开安装目录,例如我的是:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin
找到其中的文件 cublas64_12.dll,复制一份,改名为 cublas64_11.dll。
打开网页:
github.com/Purfview/whisper-standalone-win/releases/tag/libs
下载解压,根据提示放入相应位置。
安装依赖库:
pip install nvidia-cublas-cu11 nvidia-cudnn-cu11
然后就可以使用 GPU 运行了。
Python 代码:
from faster_whisper import WhisperModel
model_size = "large-v3"
# 使用 GPU 运行,指定精度 INT8
model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# 加载音频并执行识别
segments, info = model.transcribe("Haul.mp3", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
怎么样,感觉不错吧,有兴趣的话,快试试吧。
项目地址:
github.com/SYSTRAN/faster-whisper
#AI 人工智能,#OpenAI whisper, #fast-whisper,#ChatGPT,#语音转文字,#gpt890文章来源:https://www.toymoban.com/news/detail-843831.html
信息来源 gpt890.com/article/35文章来源地址https://www.toymoban.com/news/detail-843831.html
到了这里,关于超快的 AI 实时语音转文字,比 OpenAI 的 Whisper 快4倍 -- 开源项目 Faster Whisper的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!