基于Diffusion模型的AIGC生成算法日益火热,其中文生图,图生图等图像生成技术普遍成熟,很多算法从业者开始从事视频生成算法的研究和开发,原因是视频生成领域相对空白。

AIGC视频算法发展现状
从2023年开始,AIGC+视频的新算法层出不穷,其中最直接的是把图像方面的成果引入视频领域,并结合时序信息去生成具有连续性的视频。随着Sora的出现,视频生成的效果又再次上升了一个台阶,因此有必要将去年一年到现在的视频领域进展梳理一下,为以后的视频方向的研究提供一点思路。

AIGC视频算法分类
AIGC视频算法,经过梳理发现,可以大体分为:文生视频,图生视频,视频编辑,视频风格化,人物动态化,长视频生成等方向。具体的输入和输出形式如下:
文生视频:输入文本,输出视频
图生视频:输入图片(+控制条件),输出视频
视频编辑:输入视频(+控制条件),输出视频
视频风格化:输入视频,输出视频
人物动态化:输入图片+姿态条件,输出视频
长视频生成:输入文本,输出长视频

具体算法梳理
▐ 文生视频
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
机构:清华
时间:2022.5.29
https://github.com/THUDM/CogVideo.
简单介绍:基于两阶段的transformer(生成+帧间插值)来做文生视频

IMAGEN VIDEO
机构:Google
时间:2022.10.5
简单介绍:基于google的Imagen来做的时序扩展,而Imagen和Imagen video都没有开源
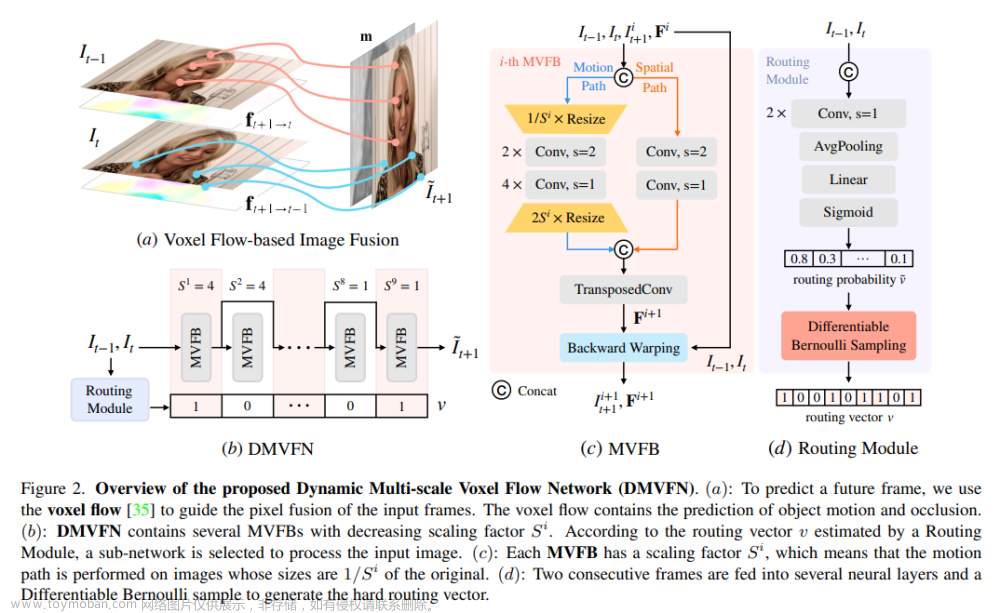
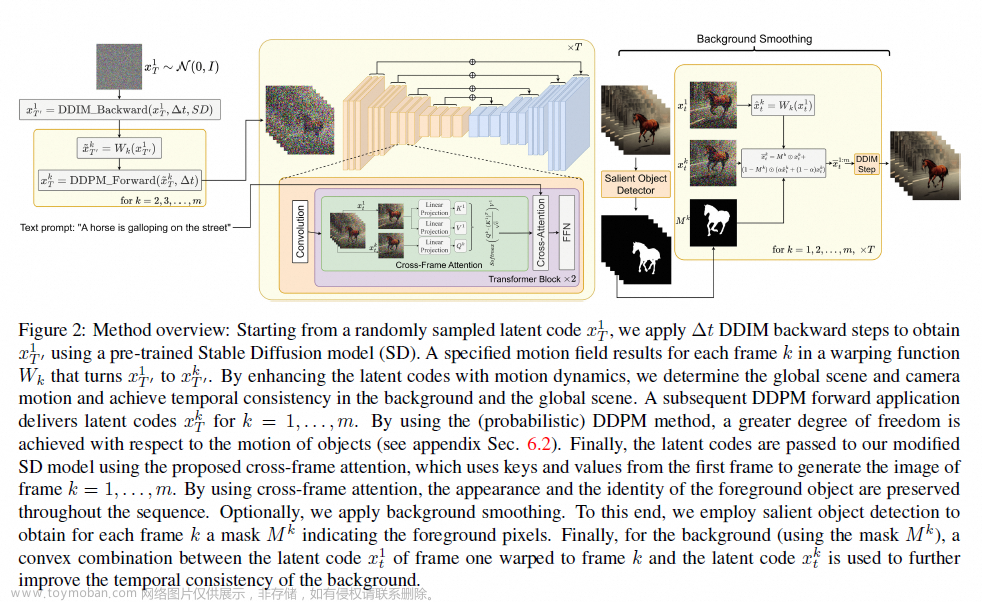
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
机构:Picsart AI Resarch
时间:2023.3.23
https://github.com/Picsart-AI-Research/Text2Video-Zero
简单介绍:基于图像diffusion model引入corss-frame attention来做时序建模,其次通过显著性检测来实现背景平滑。
MagicVideo: Efficient Video GenerationWith Latent Diffusion Models
机构:字节
时间:2023.5.11
简单介绍:直接将图像SD架构扩展成视频,增加了时序信息

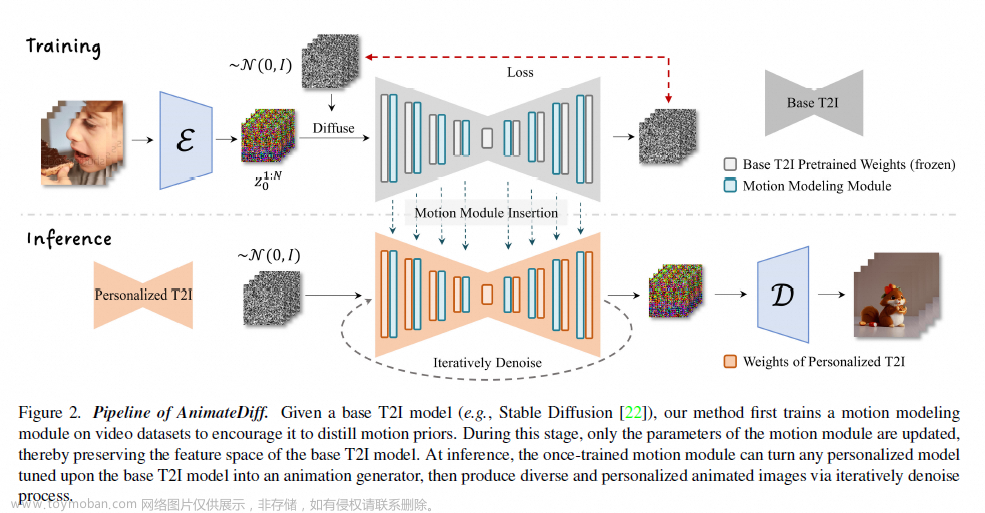
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
机构:上海 AI Lab
时间:2023.7.11
https://animatediff.github.io/
简单介绍:基于图像diffusion model,训练一个运动建模模块,来学习运动信息
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
机构:腾讯 AI Lab
时间:2023.10.30
https://ailab-cvc.github.io/videocrafter
简单介绍:基于diffusion模型,网络架构采用空间和时序attention操作来实现视频生成

▐ 图生视频
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
机构:上海 AI Lab
时间:2023.7.11
https://animatediff.github.io/
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
机构:腾讯 AI Lab
时间:2023.10.30
https://ailab-cvc.github.io/videocrafter
stable video diffusion
机构:Stability AI
时间:2023.11.21
https://stability.ai/news/stable-video-diffusion-open-ai-video-model
简单介绍:基于SD2.1增加时序层,来进行视频生成
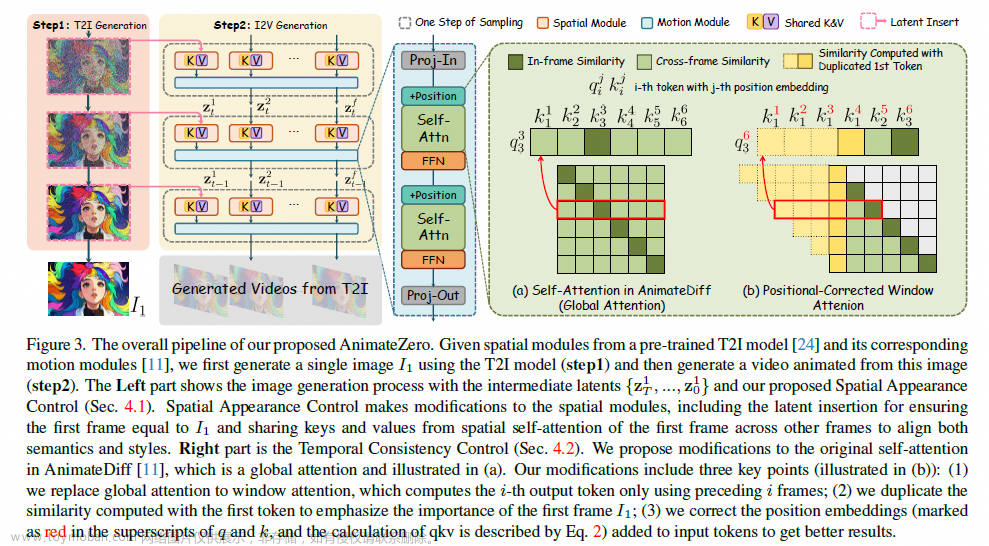
AnimateZero: Video Diffusion Models are Zero-Shot Image Animators
机构:腾讯 AI Lab
时间:2023.12.6
https://github.com/vvictoryuki/AnimateZero(未开源)
简单介绍:基于Animate Diff增加了位置相关的attention
AnimateAnything: Fine-Grained Open Domain Image Animation with Motion Guidance
机构:阿里
时间:2023.12.4
https://animationai.github.io/AnimateAnything/
简单介绍:可以针对特定位置进行动态化,通过学习运动信息实现时序信息生成

LivePhoto: Real Image Animation with Text-guided Motion Control
机构:阿里
时间:2023.12.5
https://xavierchen34.github.io/LivePhoto-Page/(未开源)
简单介绍:将参考图,运动信息拼接作为输入,来进行图像的动态化

▐ 视频风格化
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation
机构:南洋理工
时间:2023.12.17
https://www.mmlab-ntu.com/project/rerender/
简单介绍:基于SD+controlnet,结合cros-frame attention来风格化视频序列

DCTNet
机构:阿里达摩院
时间:2022.7.6
https://github.com/menyifang/DCT-Net/
简单介绍:基于GAN的框架做的视频风格化,目前支持7种不同的风格

▐ 视频编辑
主要是将深度图或者其他条件图(canny/hed),通过网络注入Diffusion model中,控制整体场景生成,并通过prompt设计来控制主体目标的外观。其中controlnet被迁移进入视频编辑领域,出现了一系列controlnetvideo的工作。
Structure and Content-Guided Video Synthesis with Diffusion Models
机构:Runway
时间:2023.2.6
https://research.runwayml.com/gen1

Animate diff+ControlNet(基于WebUI API)
Video-P2P: Video Editing with Cross-attention Control
机构:港中文,adobe
时间:2023.3.8
https://video-p2p.github.io/

Pix2Video: Video Editing using Image Diffusion
机构:Abode
时间:2023.3.22
https://duyguceylan.github.io/pix2video.github.io/

InstructVid2Vid: Controllable Video Editing with Natural Language Instructions
机构:浙大
时间:2023.5.21

ControlVideo: Training-free Controllable Text-to-Video Generation
机构:华为
时间:2023.5.22
https://github.com/YBYBZhang/ControlVideo

ControlVideo: Conditional Control for One-shot Text-driven Video Editing and Beyond
机构:清华
时间:2023.11.28
https://github.com/thu-ml/controlvideo

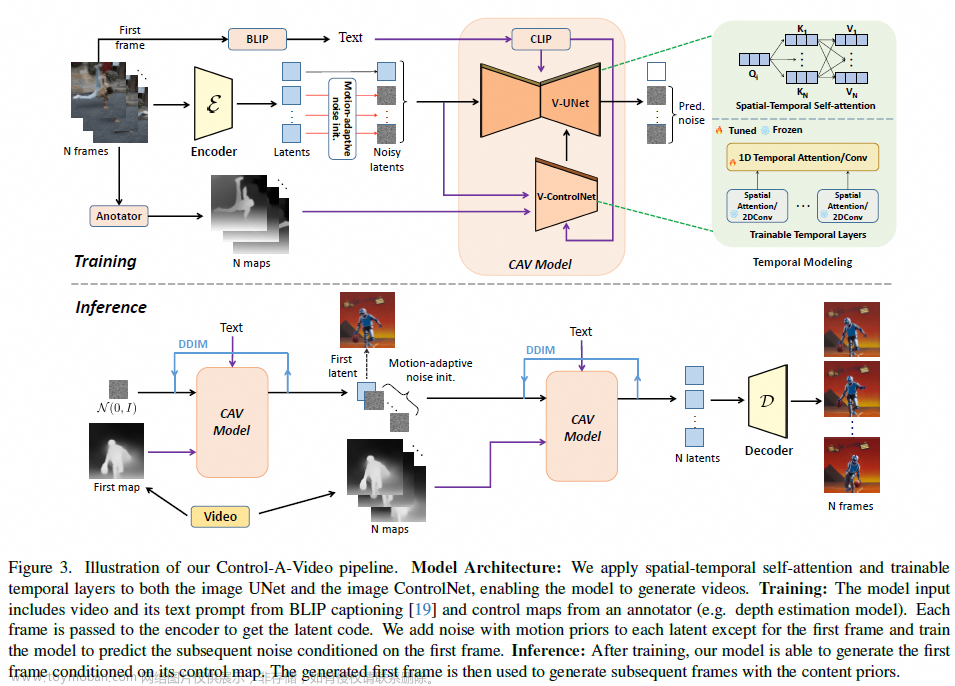
Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models
时间:2023.12.6
https://controlavideo.github.io/
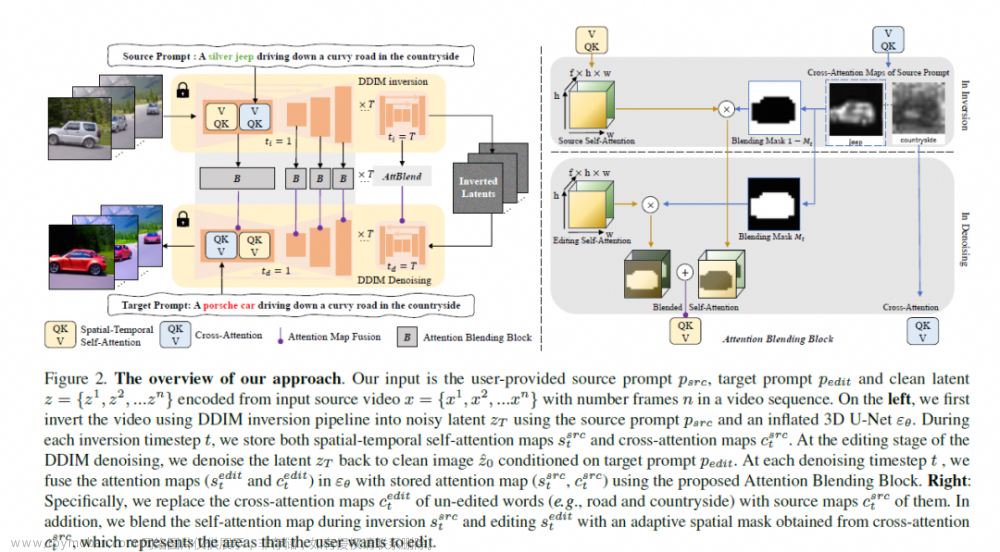
StableVideo: Text-driven Consistency-aware Diffusion Video Editing
机构:MSRA
时间:2023.8.18
https://github.com/rese1f/StableVideo

MagicEdit: High-Fidelity and Temporally Coherent Video Editing
机构:字节
时间:2023.8.28
https://magic-edit.github.io/(未开源)

GROUND-A-VIDEO: ZERO-SHOT GROUNDED VIDEO EDITING USING TEXT-TO-IMAGE DIFFUSION MODELS
机构:KAIST
时间:2023.10.2
https://ground-a-video.github.io/

FateZero: Fusing Attentions for Zero-shot Text-based Video Editing
机构:腾讯AI Lab
时间:2023.10.11
https://fate-zero-edit.github.io
Motion-Conditioned Image Animation for Video Editing
机构:Meta
时间:2023.11.30
facebookresearch.github.io/MoCA(未开源)

VidEdit: Zero-shot and Spatially Aware Text-driven Video Editing
机构:Sorbonne Université, Paris, France
时间:2023.12.15
https://videdit.github.io

Zero-Shot Video Editing Using Off-The-Shelf Image Diffusion Models
时间:2024.1.4
https://github.com/baaivision/vid2vid-zero

▐ 人物动态化
主要是通过人体姿态作为条件性输入(结合controlnet等),将一张图作为前置参考图,或者直接使用文本描述生成图片。其中阿里和字节分别有几篇代表性论文,其中字节的代码有两篇已经开源,阿里的代码还在等待阶段。
Follow Your Pose
机构:腾讯AI Lab
时间:2023.4.3
https://follow-your-pose.github.io/

DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
机构:google,nvidia
时间:2023.5.4
https://grail.cs.washington.edu/projects/dreampose/

DISCO: Disentangled Control for Realistic Human Dance Generation
机构:微软
时间:2023.10.11
https://disco-dance.github.io

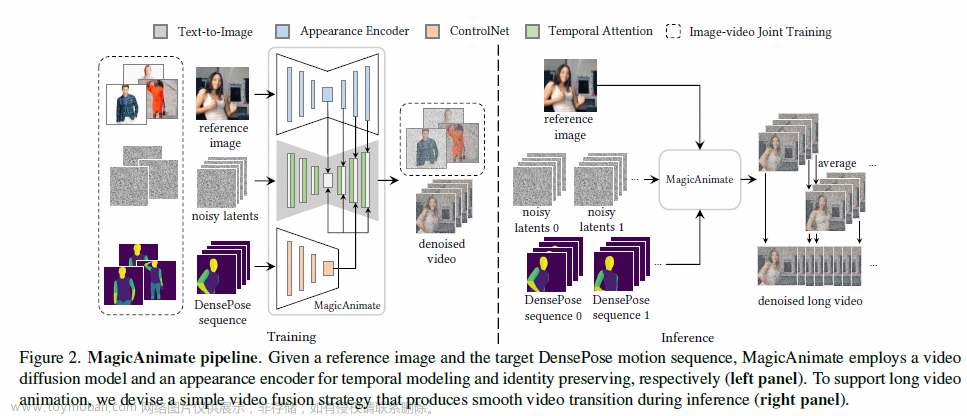
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
机构:字节
时间:2023.11.27
https://showlab.github.io/magicanimate/
MaigcDance
机构:字节
时间:2023.11.18
https://boese0601.github.io/magicdance/
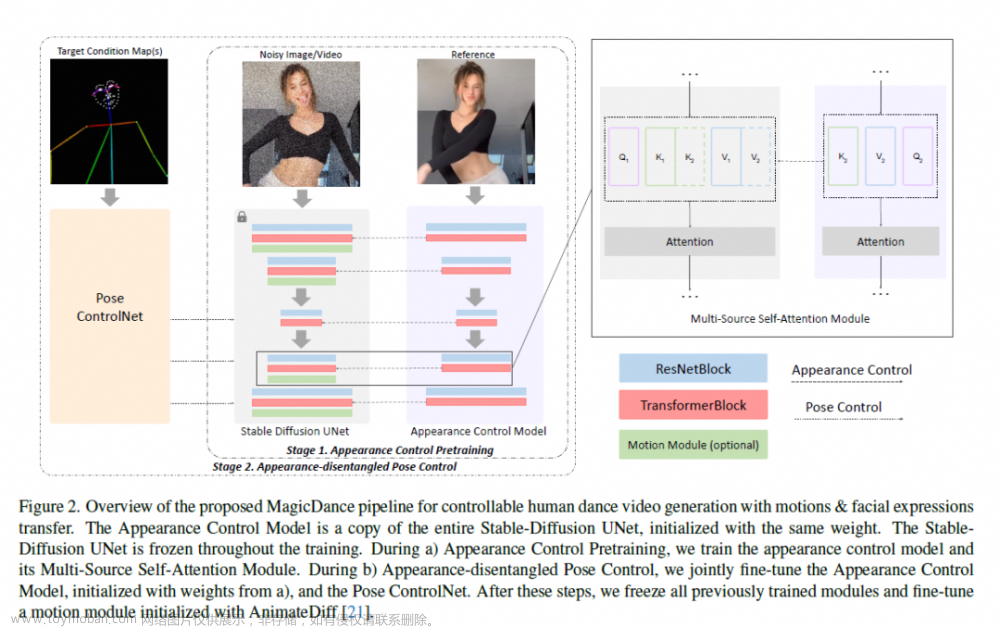
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
机构:阿里
时间:2023.12.7
https://humanaigc.github.io/animate-anyone/(未开源)

DreaMoving: A Human Video Generation Framework based on Diffusion Model
机构:阿里
时间:2023.12.11
https://dreamoving.github.io/dreamoving(未开源)

▐ 长视频生成
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
机构:微软亚研院
时间:2023.3.22
https://msra-nuwa.azurewebsites.net/

Latent Video Diffusion Models for High-Fidelity Long Video Generation
机构:腾讯AI Lab
时间:2023.3.20
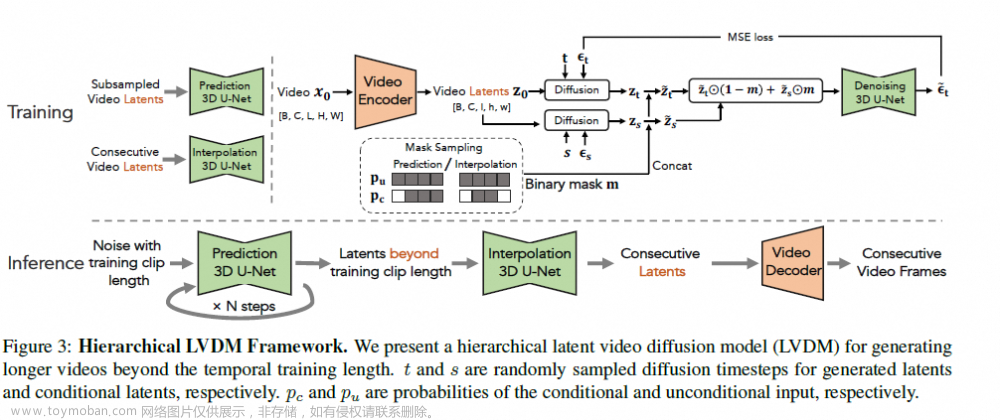
Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising
机构:上海AI Lab
时间:2023.3.29
https://github.com/G-U-N/Gen-L-Video

Sora(OpenAI)
时间:2024.2
https://openai.com/sora(未开源)
Latte: Latent Diffusion Transformer for Video Generation
机构:上海AI Lab
时间:2024.1.5
https://maxin-cn.github.io/latte_project


算法效果分析
本章节选择了一些代表性的方法进行效果分析
Animate Diff
效果:https://animatediff.github.io/,支持文生视频,图生视频,以及和controlnet结合做视频编辑
Animate Diff+ControlNet
输入视频:moonwalk.mp4
输出样例




canny和openpose
注意:要输入主语保证主体一致性(比如michael jackson或者a boy)
AnimateAnything
能够指定图片的运动区域,根据文本进行图片的动态化
效果:
Stable Video Diffusion
能够基于静止图片生成25帧的序列(576x1024)
效果:

ControlVideo
输入+输出样例:500.mp4,300.mp4,整体效果不错
问题:因为推理过程需要额外的训练,消耗时间久,第一个视频需要50min(32帧),第二个视频需要14min(8帧)
300
500
Rerender A Video
输入:
输出:
输入:
输出:
整体效果还可以,运行速度和视频帧数有关,10s视频大约在20min左右。
DCTNet
效果:整体画面稳定,支持7种风格,显存要求低(6-7G),上面视频40s左右就可以处理完
DreamPose

Animate Anyone
MagicDance
输入图片:

输出:
Sora
效果:https://openai.com/sora
能够生成长视频,质量很好,但是尚未开源

总结和展望
文生视频和图生视频算法:其中Animate Diff,VideoCrafter等已经开源,支持文/图生成视频,并且经过测试效果还不错,同时图生视频还支持通过结合不同的base模型实现视频的风格化。不过生成的视频帧数基本都在2s以内,可以作为动图的形式进行展示。其中Stable Video Diffusion是stability ai开源的一个图生视频的算法,效果相对更加逼真,视频质量更高,但是视频长度依旧很短。
视频编辑算法:比如基于controlnet的可控生成视频可以初步达到预期的效果,支持实现特定目标或者属性(颜色等)的更换,也支持人物的换装(比如颜色描述)等等,其中生成的视频长度和GPU显存相关。
视频风格化:基于diffusion 模型的视频风格化效果最好的是rerender a video,可以支持prompt描述来进行视频的风格化,整体来讲这个方法对人脸和自然环境有比较好的效果,运行成本也相对较低(相较于视频编辑算法)
特定的人物动态化算法:目前demo效果最好的animate anyone和dream moving都还没有开源。不过这两个算法都对外开放了使用接口,比如通义千问app以及modelscope平台。重点介绍一下通义实验室的Dream moving,https://www.modelscope.cn/studios/vigen/video_generation/summary是其开放的使用平台,里面支持同款的动作生成,图生视频,视频的风格化以及视频贺卡等功能,整体来讲效果很好。而目前开源的方法中,测试的效果最好的是MagicDance,但是人脸有一定的模糊,距离animate anyone和dream moving展示的效果还有差距。
长视频算法:随着Sora的出现,Diffusion Transformer的架构后续会备受关注,目前大部分算法都局限于2s左右的短视频生成,而且质量上不如Sora。后续会有更多的算法将Sora的思路融入现有的方法中,不断提升视频质量和视频长度。不过目前sora的模型和实现细节并没有在技术报告中公开,因此在未来还会有一段的摸索路要走。
整体总结:
是否可用 |
优势 |
劣势 |
适用场景 |
代表性方法 |
|
文/图生视频 |
是 |
视频质量高 |
视频长度短 |
短视频动态封面 |
Animate Diff(可扩展性强) VideoCrafter(质量较好) Stable Video Diffusion(质量更好) |
视频编辑算法 |
待定 |
算法种类多,可实现的功能多(修改任意目标的属性) |
推理速度较慢,显存要求高,视频长度短 |
人物换装(最简单的改变衣服颜色),目标编辑,用户体验 |
ControlVideo(效果好但运行时间久) |
视频风格化 |
是 |
显存要求相对视频编辑更低,推理速度更快。 |
画面存在一定的不稳定问题。但是基于GAN的DCTNet相对更稳定 |
用户体验 |
Rerender-A-Video(更灵活) DCTNet(效果更稳定) |
人物动态化 |
待定 |
用户可玩性高 |
效果最好的代码暂时没有开源,开源的代码生成的人脸会有一定的模糊 |
用户体验 |
Animate Anyone(待开源) DreamMoving(待开源) MagicDance(已开源) |
长视频生成 |
否 |
视频长度远超2s |
整体质量偏差 (Sora还没开源) |
影视制作 |
Sora |
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术文章来源:https://www.toymoban.com/news/detail-844008.html
服务端技术 | 技术质量 | 数据算法文章来源地址https://www.toymoban.com/news/detail-844008.html
到了这里,关于52个AIGC视频生成算法模型介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!