一、概念
1、Hive
1. Hive是hadoop数据仓库管理工具,严格来说,不是数据库,本身是不存储数据和处理数据的,其依赖于HDFS存储数据,依赖于MapReducer进行数据处理。
2. Hive的优点是学习成本低,可以通过类SQL语句(HSQL)快速实现简单的MR任务,不必开发专门的MR程序。
3. 由于Hive是依赖于MapReducer处理数据的,因此有很高的延迟性,不适用于实时数据处理(数据查询,数据插入,数据分析),适用于离线数据的批处理。
2、HBase
1.HBase是一种分布式、可扩展、支持海量数据存储的NOSQL数据库
2.HBase主要适用于海量数据的实时数据处理(随机读写)
3.由于HDFS不支持随机读写,而HBase正是为此而诞生的,弥补了HDFS的不可随机读写。
二、共同点
hbase与hive都是架构在hadoop之上的。都是用HDFS作为底层存储。
三、区别
1.Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。总的来说,hive是适用于离线数据的批处理,hbase是适用于实时数据的处理。
2.Hive本身不存储和计算数据,它完全依赖于HDFS存储数据和MapReduce处理数据,Hive中的表纯逻辑。
3.hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
4.由于HDFS的不可随机读写,hive是不支持随机写操作,而hbase支持随机写入操作。
5.HBase只支持简单的键查询,不支持复杂的条件查询
四、关系
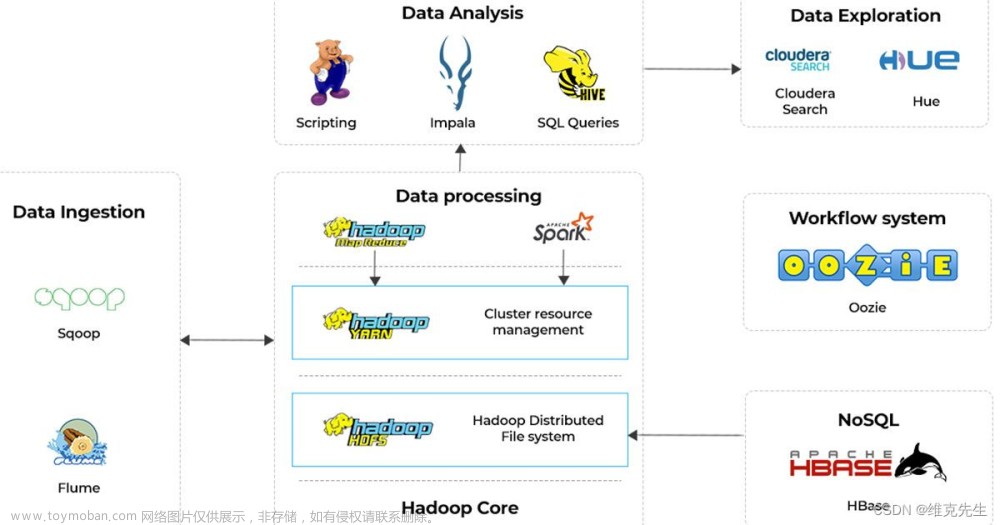
在大数据架构中,Hive和HBase是协作关系,这里就举例一种常用的协作关系,具体流程如下图:

在大数据架构中,Hive和HBase是协作关系,流程如下:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
五、总结
做一个总结,Hive和HBase都是Hadoop集群下的工具,Hive是对MapReduce的优化,而HBase则是HDFS数据存储的大管家。那么,这两者各适用于哪些场景呢?
- Hive中的表为纯逻辑表,仅仅对表的元数据进行定义。Hive没有物理存储的功能,它完全依赖HDFS和MapReduce。这样就可以将结构化的数据文件映射为为一张数据库表,并提供完整的SQL查询功能,并将SQL语句最终转换为MapReduce任务进行运行。HBase表则是物理表,适合存放非结构化的数据。
- Hive是在MapReduce的基础上对数据进行处理,而MapReduce的数据处理依照行模式;而HBase为列模式,这样使得对海量数据的随机访问变得可行。
- HBase的存储表存储密度小,因而用户可以对行定义成不同的列;而Hive是逻辑表,属于稠密型,即定义列数,每一行对列数都有固定的数据。
- Hive使用Hadoop来分析处理数据,而Hadoop系统是批处理系统,所以数据处理存在延时的问题;而HBase是准实时系统,可以实现数据的实时查询。
- Hive没有row-level的更新,它适用于大量append-only数据集(如日志)的批任务处理。而基于HBase的查询,支持和row-level的更新。
- Hive全面支持SQL,一般可以用来进行基于历史数据的挖掘、分析。而HBase不适用于有join,多级索引,表关系复杂的应用场景。
两者使用场景的区别:
- HBase的应用场景通常是采集网页数据的存储,因为它是key-value型数据库,从而可以到各种key-value应用场景,例如存储日志信息,对于内容信息不需要完全结构化出来的类CMS应用等。注意hbase针对的仍然是OLTP应用为主。
- hive主要针对的是OLAP应用,其底层是hdfs分布式文件系统,重点是基于一个统一的查询分析层,支撑OLAP应用中的各种关联,分组,聚合类SQL语句。hive一般只用于查询分析统计,而不能是常见的CUD操作,要知道HIVE是需要从已有的数据库或日志进行同步最终入到hdfs文件系统中,当前要做到增量实时同步都相当困难。
以上就是关于Hive和HBase有哪些区别与联系及适用场景的论述,希望对学大数据分析的同学有所帮助。
HIVE和HBASE的区别和联系-CSDN博客
Hive与HBase有什么区别 - 云计算 - 亿速云文章来源:https://www.toymoban.com/news/detail-854508.html
Spark、Hive、Hbase比较_spark hive_好啊啊啊啊的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-854508.html
到了这里,关于Hive、HBase对比【相同:HDFS作为底层存储】【区别:①Hive用于离线数据的批处理,Hbase用于实时数据的处理;②Hive是纯逻辑表,无物理存储功能,HBase是物理表,放非结构数据】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!