优质博文:IT-BLOG-CN
树模型是机器学习中最常用的一类模型,包括随机森林、AdaBoost、GBDT(XGBoost和Lightgbm)等,基本原理都是通过集成弱学习器的即式来进一步提升准确度。这里的弱学习器包括线性模型和决策树模型,本期介绍的就是决策树模型(DecisionTree)。
决策树属于有监督学习,即可用于回归问题也能解决分类问题,对应的模型称为回归树和分类树。模型的结构采用树图形式展示: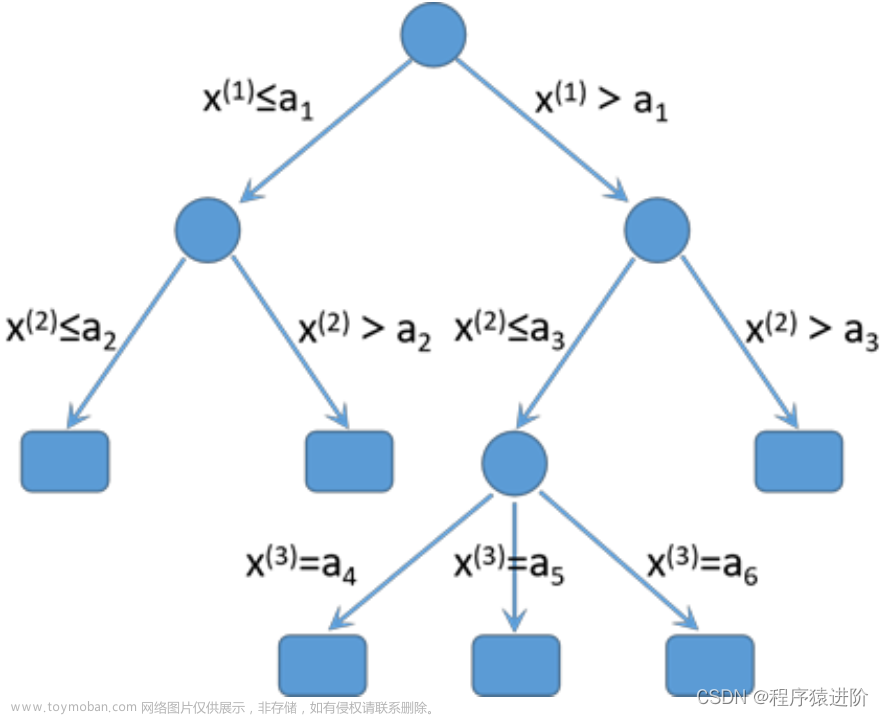
其中圆圈表示分裂节点,矩形(右子结点)表示输出结果y。树也可以认为是运用if-then规则做预测的算法,而模型训练的本质就是寻找最优分裂节点(非右子结点)。
CART算法
常见的树模型有ID3、C4.和CART,其中CART全称为分类不回归树(ClassificationAndRe-gressionTee),本文主要介绍CART树。
假训训练集D中为特征集,为输出变量。CART采用二叉树结构,方内部节点特征的取值为“是”和“否”,左分支取值为“是”,右分支取值为“否”。一般使用递归方法生成树: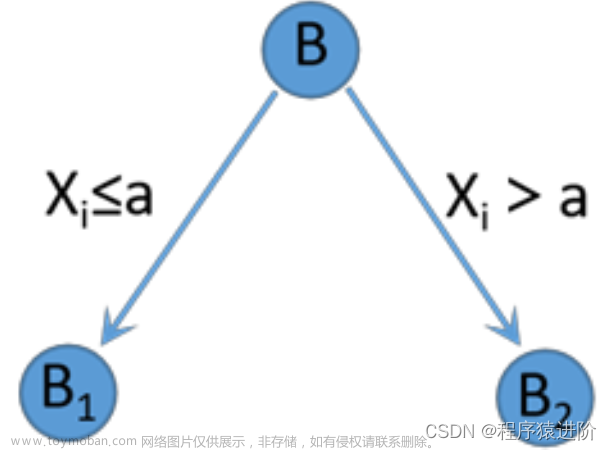
其中Xi为切分变量,a为切分点,CART树的生成过程就是寻找这两个变量的最优值过程。
回归树生成算法
首先根据给定的切分变和切分点定义B1和B2子集: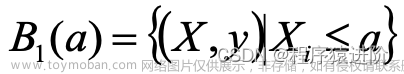 和
和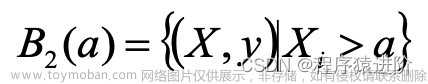
对于落入同一子集内的数据,CART树会输出相同的值 ,一般采用平方误差(MSE)最小的准则来确定
,一般采用平方误差(MSE)最小的准则来确定 ,以B1为例:
,以B1为例:
针对给定的切分变量Xi,优化下式可得到最优切分点a: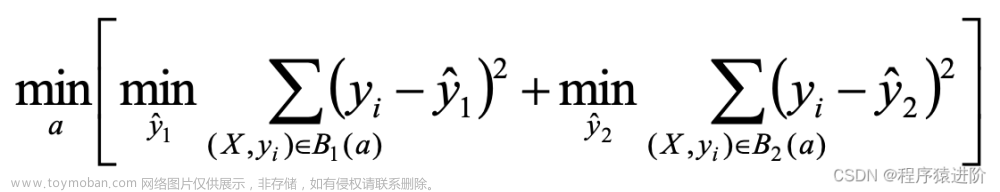
通过遍历所有的特征变量找出最优切分变量,再以同样的方式对B1和B2子集做划分,直到满足停止条件
停止条件一般有:1、子集内的训练样本数小于预训的阈值;2、子集内的MSE小于预训的阀值.
分类树生成算法
CART算法中回归树和分类树的主要区别在于计算最优切分点a时采用的准则不同,前者采用了最小化MSE,后考利用基尼系数。
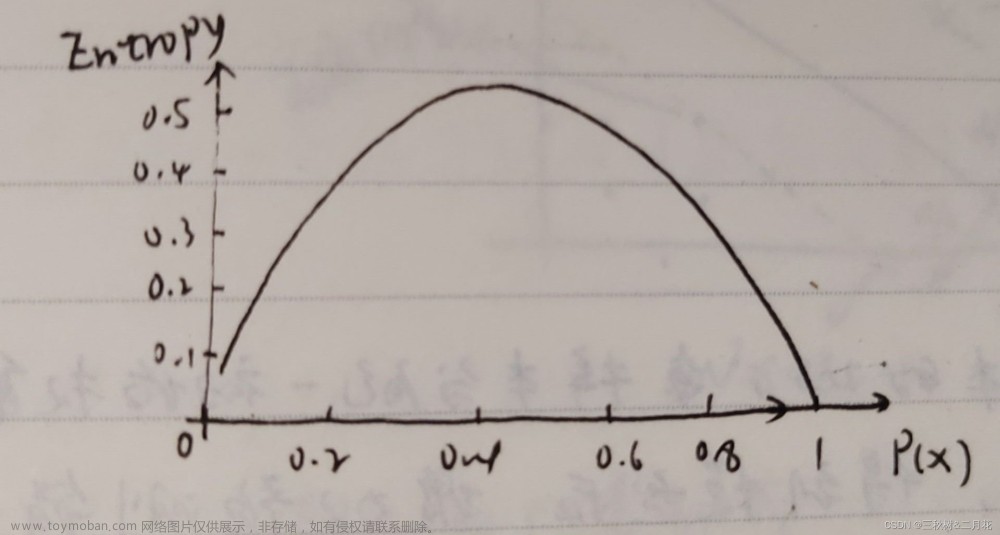
先介绍基尼系数的定义,在分类问题中,输出变量的分类水平数为K,样本数据集为B,Ci表示B中属于第i类的样本子集,则数据集B的基尼系数为:
其中 和
和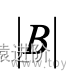 分别表示数据集C和B中的样本量。该指标反映了数据集B的不确定性,方基尼系数值越大,样本集B的不确定性越大。
分别表示数据集C和B中的样本量。该指标反映了数据集B的不确定性,方基尼系数值越大,样本集B的不确定性越大。
对于给定的切分变量Xi和切分点a,数据集B被分割成B和B2两个子集: 和
和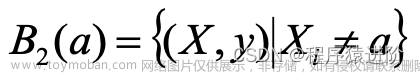
在切分变量Xi和切分点a下,数据集B的基尼系数定义为: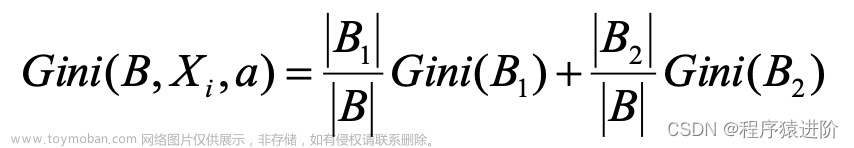
该指标反映的是数据集B经过Xi=a分割后的不确定性。
在所有可能的特征以及它们所有可能的切分点中,选择基尼系数最小的特和切分点作为最优切分特和最优切分点,依次递归生成一棵CART分类树。
在寻找每个最优分裂节点时,对特征变和切分点的遍历实际上可以做并行计算,可以有效提高模型的训练速度。另外类似于线性模型,树模型也会存在过拟合的问题。
为了防止出现过拟合现象,一般树模型的训练过程中还会有剪枝的过程。剪枝的主要过程是去除那些训练样本量很小的叶节点以及没必要继续分裂的非叶子节点,仅而减小树的复杂度。
假设已生成一棵CART树T(待剪枝),那么用于对T剪枝的损失函数为:
其中C(T)为当前训练样本的预测误差,比如平方损失(MSE);α|T|为惩罚项,非负数α称为惩罚系数,|T|表示树T的复杂度,可以是叶子节点个数。
对于惩罚系数α有三种情况:
1、当α=0时,那么Cα(T)=C(T),此时无需作剪枝,T就是最优子树;
2、当α过小时,树模型的复杂度|T|对Cα(T)的影响偏小,此时剪枝过程侧重于降低预测误差,可能导致最优子树仍存在过拟合;
3、当α过大时,树模型的复杂度|T|对Cα(T)的影响偏大,此时剪枝过程侧重于简化树,可能导致最优子树欠拟合。
对于固定的α0,则必存在对应的最优子树T0。对于α序列{α0,α1,…,αn},有对应的最优子树序列{T0,T1,…,Tn},然后取最优子树中交叉验证集(CV)效果最好的那棵树作为最织的剪枝模型输出既可。
对于某个非叶子结点而言,剪枝前后的损失函数差值为:
其中|t|是指以t为根节点的子树复杂度,当diff=0说明剪枝操作不影响损失函数(一般仍会采取剪枝来降低模型复杂度);diff>0说明该节点t需要剪枝,此时:
取等时的临界值训为αt,计算出每个非叶子结点(内节点)的临界值后,叧要获取给定的α值既可知道该节点是否需要剪枝,仅而得出最优子树Tα。
将上述有关CART树剪枝的内容整理成如下算法步骤:
(1)输入生成的CART树T;
(2)遍历各内部节点并计算α临界值: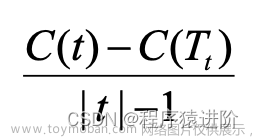
(3)获得内部节点α临界值的序列a={α0,α1,…,αn};
(4)遍历a,得到相应的最优子树序列{T0,T1,…,Tk},k≤n;
(5)用CV法把最优子树序列{T0,T1,…,Tk}中验证误差最小的子树作为剪枝后的最优模型输出。文章来源:https://www.toymoban.com/news/detail-861571.html
需要注意的是当α取不同值时,对应的最优子树可能相同,既剪枝方法相同,所以最优子树序列中的个数≤内部节点数。文章来源地址https://www.toymoban.com/news/detail-861571.html
到了这里,关于经典机器学习算法——决策树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!