引言
在当今信息爆炸的时代,数据的力量无处不在。如何高效地存储、搜索和分析海量数据成为了技术世界中的热门话题。ElasticSearch,作为分布式搜索和分析引擎的领军者,以其卓越的性能和易用性赢得了广泛的赞誉。本文将带你深入ElasticSearch的源码,揭示其运行原理,并提供实战代码Demo,助你在数据的海洋中乘风破浪。
分享内容直达
2024最全大厂面试题无需C币点我下载或者在网页打开全套面试题已打包
AI绘画关于SD,MJ,GPT,SDXL百科全书
ElasticSearch简介
ElasticSearch是一个基于Apache Lucene构建的开源搜索引擎。它提供了一个分布式、多用户能力的全文搜索引擎,基于RESTful Web接口。ElasticSearch的分布式特性使其能够处理PB级别的数据,并能够达到实时搜索的能力。
ElasticSearch运行原理解析
1. 分布式架构
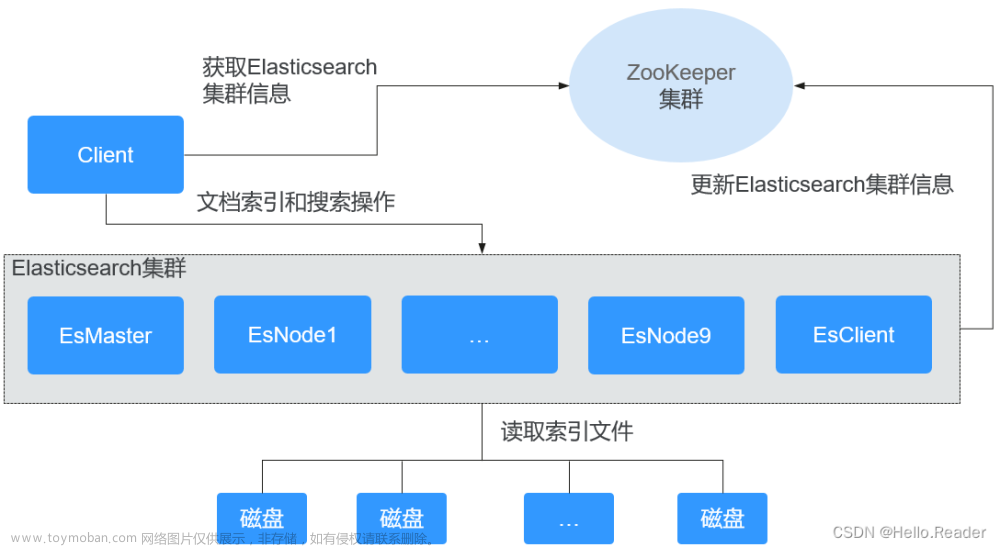
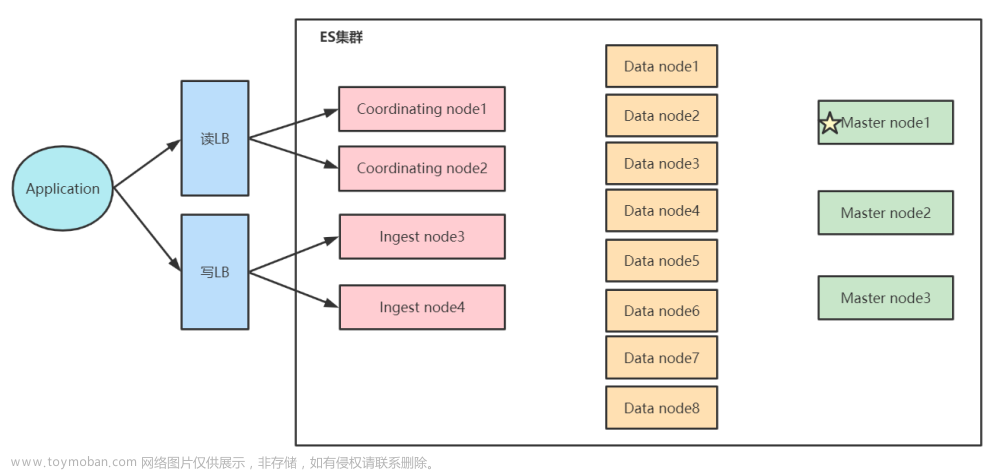
ElasticSearch的分布式架构是其核心特性之一。它将数据分片(Shards)存储在不同的节点上,每个分片可以有零个或多个副本(Replicas),以此来提供数据的高可用性和容错能力。
2. 数据模型
ElasticSearch中的数据模型包括三个主要层次:索引(Index)、类型(Type)和文档(Document)。索引类似于数据库中的数据库,类型类似于数据库中的表,而文档则是实际的数据记录。
3. 数据分片与复制
ElasticSearch在创建索引时,会自动将数据分为多个分片,每个分片可以有零个或多个副本。分片的数量和副本的数量可以在创建索引时指定,也可以在后续进行动态调整。
4. 搜索与分析
ElasticSearch提供了强大的搜索和分析功能。它支持多种查询类型,如全文搜索、范围查询、布尔查询等。同时,ElasticSearch还支持聚合操作,可以用来进行数据分析和统计。
实战代码Demo
以下是一个简单的ElasticSearch实战代码Demo,展示如何使用Java High Level REST Client进行数据的索引和搜索。
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class ElasticSearchDemo {
public static void main(String[] args) {
try (RestHighLevelClient client = new RestHighLevelClient(/* 配置省略 */)) {
// 索引文档
String indexName = "my_index";
String typeName = "my_type";
String documentId = "1";
String jsonString = "{" +
" \"title\": \"Quick Brown Foxes!\"," +
" \"content\": \"Quick brown foxes jump!\"" +
"}";
IndexRequest request = new IndexRequest(indexName, typeName, documentId)
.source(jsonString, XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
// 搜索文档
SearchRequest searchRequest = new SearchRequest(indexName);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("content", "foxes"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 处理搜索结果...
} catch (Exception e) {
e.printStackTrace();
}
}
}
在这个Demo中,我们首先创建了一个包含标题和内容的文档,并将其索引到ElasticSearch中。然后,我们执行了一个搜索请求,查询包含"foxes"这个词的文档,并处理搜索结果。
应用场景
ElasticSearch的应用场景非常广泛,包括但不限于:
- 日志分析:实时分析和搜索日志数据。
- 全文搜索:为网站或应用程序提供即时搜索功能。
- 数据分析:对大量数据进行聚合分析和可视化。
由于篇幅限制,接下来我将继续深入探讨ElasticSearch的核心知识点,包括其数据存储机制、查询优化技巧、以及集群管理和监控。
ElasticSearch数据存储机制
1. 倒排索引
ElasticSearch使用倒排索引(Inverted Index)作为其主要的数据结构,用于快速全文搜索。倒排索引将文档中出现的每个单词与包含它的文档列表相关联。这种结构使得ElasticSearch能够快速响应复杂的文本查询。
2. 分片与副本
如前所述,ElasticSearch将数据分为多个分片,每个分片可以有多个副本。这种机制不仅提高了数据的可用性和容错性,还有助于提高查询和索引的性能。
3. 文档和字段
ElasticSearch中的文档是数据的基本单位,类似于关系型数据库中的行。文档由一系列字段组成,每个字段包含一个或多个值。ElasticSearch支持多种字段类型,如文本、数字、日期等。
查询优化技巧
1. 查询性能
为了优化查询性能,ElasticSearch提供了多种查询类型和优化策略。例如,使用布尔查询(Bool Query)可以组合多个查询条件,而使用过滤器(Filter)可以在不影响评分的情况下过滤结果。
2. 查询DSL
ElasticSearch的查询DSL(Domain Specific Language)提供了丰富的查询语法,使得开发者可以编写复杂而灵活的查询。掌握DSL是进行高效查询的关键。
3. 分析器
ElasticSearch支持多种内置分析器,也可以自定义分析器。选择合适的分析器对于提高搜索相关性和性能至关重要。
集群管理和监控
1. 集群健康
ElasticSearch提供了集群健康API,可以用来检查集群的状态。集群健康状态包括绿、黄、红三种,分别表示集群数据完整性和分片状态。
2. 节点管理
通过ElasticSearch的节点API,可以管理集群中的节点,包括添加、删除节点,以及查看节点信息。
3. 监控
ElasticSearch自带的监控功能可以帮助开发者监控集群的性能和状态。此外,还可以使用Elasticsearch-head、Kibana等工具进行更深入的监控和可视化。
实战代码Demo:集群健康检查
以下是一个简单的Java代码示例,展示如何使用ElasticSearch的REST API检查集群健康状态。
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.cluster.health.ClusterHealthStatus;
import org.elasticsearch.cluster.health.ClusterHealthResponse;
public class ClusterHealthDemo {
public static void main(String[] args) {
try (RestHighLevelClient client = new RestHighLevelClient(/* 配置省略 */)) {
ClusterHealthRequest healthRequest = new ClusterHealthRequest();
ClusterHealthResponse healthResponse = client.cluster().health(healthRequest, RequestOptions.DEFAULT);
ClusterHealthStatus status = healthResponse.getStatus();
System.out.println("Cluster health status: " + status);
} catch (Exception e) {
e.printStackTrace();
}
}
}
在这个Demo中,我们使用ClusterHealthRequest检查集群的健康状态,并通过ClusterHealthResponse获取状态信息。文章来源:https://www.toymoban.com/news/detail-861585.html
总结
ElasticSearch是一个功能强大的搜索引擎,其分布式架构、倒排索引、查询优化技巧和集群管理监控功能使其成为了处理大数据搜索和分析的理想选择。本文深入探讨了ElasticSearch的核心知识点,并提供了实战代码示例。如果你对ElasticSearch的其他方面还有兴趣,或者希望了解更多的实战案例,请继续提出你的问题,我们将为你提供更加详尽的内容。不要忘了点赞、评论和分享,让更多的开发者加入到ElasticSearch的学习之旅中来!🔥🌊文章来源地址https://www.toymoban.com/news/detail-861585.html
到了这里,关于ElasticSearch 源码深度剖析与实战指南的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!