本文介绍如何使用PostgreSQL作为向量数据库构建和扩展一个示例的Airbnb推荐服务。
PostgreSQL拥有丰富的扩展和解决方案生态系统,可以让我们将数据库用于通用AI应用。这篇指南将引导您完成使用PostgreSQL构建生成式AI应用程序所需的步骤。
首先,我们将介绍pgvector扩展,该扩展使得Postgres具备向量数据库特定的功能。然后,我们将讨论提高在PostgreSQL上运行的AI应用程序性能和可扩展性的方法。最后,我们将拥有一个完全功能的生成式AI应用程序,为那些前往旧金山的旅行者推荐Airbnb房源。
Airbnb推荐服务
这个示例应用程序是一个住宿推荐服务。想象一下,你计划访问旧金山,并希望住在靠近金门大桥的一个漂亮社区。你打开这个服务,输入你的提示信息,应用程序将会给出三个与你的提示信息最相关的住宿选择。
该应用程序支持两种不同的模式:

OpenAI Chat模式:在这种模式下,Node.js后端利用OpenAI Chat Completion API和GPT-4模型根据用户输入生成住宿推荐。虽然本指南不专注于此模式,但鼓励您进行实验。
Postgres嵌入模式:初始时,后端使用OpenAI Embeddings API将用户的提示信息转换为嵌入向量(文本数据的向量化表示)。接下来,应用程序在Postgres或YugabyteDB(分布式PostgreSQL)中进行相似度搜索,以找到与用户提示相匹配的Airbnb房源。Postgres利用pgvector扩展在数据库中进行相似度搜索。本指南将深入探讨应用程序中这种特定模式的实现细节。
前提条件
拥有可以访问嵌入模型的OpenAI订阅。
最新版本的Node.js。
最新版本的Docker。
启动带有pgvector的PostgreSQL
pgvector扩展为Postgres添加了向量数据库的所有基本功能。它使您能够存储和处理具有数千个维度的向量,计算向量化数据之间的欧氏距离和余弦距离,并执行准确和近似的最近邻搜索。
1. 在Docker中启动一个带有pgvector的Postgres实例:
docker run --name postgresql \ -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=password \ -p 5432:5432 \ -d ankane/pgvector:latest
2. 连接到数据库容器并打开psql会话:
docker exec -it postgresql psql -h 127.0.0.1 -p 5432 -U postgres
3. 启用pgvector扩展:
create extension vector;
4. 确认vector扩展在扩展列表中存在:
select * from pg_extension; oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition -------+---------+----------+--------------+----------------+------------+-----------+-------------- 13561 | plpgsql | 10 | 11 | f | 1.0 | | 16388 | vector | 10 | 2200 | t | 0.5.1 | | (2 rows)
加载Airbnb数据集
该应用程序使用了一个包含超过7,500个在旧金山出租的房产的Airbnb数据集。每个房源都提供详细的属性描述,包括房间数量、设施类型、位置和其他特点。这些信息非常适合与用户提示进行相似度搜索。
按照以下步骤将数据集加载到已启动的Postgres实例中:
1. 克隆应用程序存储库:
git clone https://github.com/YugabyteDB-Samples/openai-pgvector-lodging-service.git
2. 将Airbnb模式文件复制到Postgres容器中(将{app_dir}替换为应用程序目录的完整路径):
docker cp {app_dir}/sql/airbnb_listings.sql postgresql:/home/airbnb_listings.sql3. 从下面的Google Drive位置下载带有Airbnb数据的文件。文件大小为174MB,并且已经包含了使用OpenAI嵌入模型为每个Airbnb房产的描述生成的嵌入向量。
4. 将数据集复制到Postgres容器中(将{data_file_dir}替换为应用程序目录的完整路径):
docker cp {data_file_dir}/airbnb_listings_with_embeddings.csv postgresql:/home/airbnb_listings_with_embeddings.csv5. 创建Airbnb模式并将数据加载到数据库中:
# 创建模式 docker exec -it postgresql \ psql -h 127.0.0.1 -p 5432 -U postgres \ -a -q -f /home/airbnb_listings.sql # 加载数据 docker exec -it postgresql \ psql -h 127.0.0.1 -p 5432 -U postgres \ -c "\copy airbnb_listing from /home/airbnb_listings_with_embeddings.csv with DELIMITER '^' CSV;"
每个Airbnb的嵌入向量是一个具有1536个浮点数维度的数组。它是Airbnb房产描述的数值/数学表示。
docker exec -it postgresql \ psql -h 127.0.0.1 -p 5432 -U postgres \ -c "\x on" \ -c "select name, description, description_embedding from airbnb_listing limit 1"
输出(部分截取):
name | Monthly Piravte Room-Shared Bath near Downtown !3 description | In the center of the city in a very vibrant neighborhood. Great access to other parts of the city with all modes of public transportation steps away Like the general theme of San Francisco, our neighborhood is a melting pot of different people with different lifestyles ranging from homeless people to CEO''s description_embedding | [0.0064848186,-0.0030366974,-0.015895316,-0.015803888,-0.02674906,...]
这些嵌入向量是使用OpenAI的text-embedding-ada-002模型生成的。如果你需要使用不同的模型,那么:
在{app_dir}/backend/embeddings_generator.js和{app_dir}/backend/postgres_embeddings_service.js文件中更新模型。
通过使用`node embeddings_generator.js`命令启动生成器来重新生成嵌入向量。
找到最相关的Airbnb房源
到此为止,Postgres已经准备好向用户推荐最相关的Airbnb房产。应用程序可以通过比较用户的提示嵌入向量和Airbnb描述的嵌入向量来获得这些推荐。
首先,启动一个Airbnb推荐服务实例:
1. 使用你的OpenAI API密钥更新`{app_dir}/application.properties.ini`文件:
OPENAI_API_KEY=<your key>
2. 启动Node.js后端:
cd {app_dir}
npm i
cd backend
npm start3. 启动React前端:
cd {app_dir}/frontend
npm i
npm start应用程序界面应该会自动在你的默认浏览器中打开。否则,可以在地址http://localhost:3000/打开它。
现在,从应用程序界面中选择Postgres Embeddings模式,并要求应用程序根据以下提示推荐几个与之最相关的Airbnb房产:
I'm looking for an apartment near the Golden Gate Bridge with a nice view of the Bay.
该服务将推荐三个住宿选项:
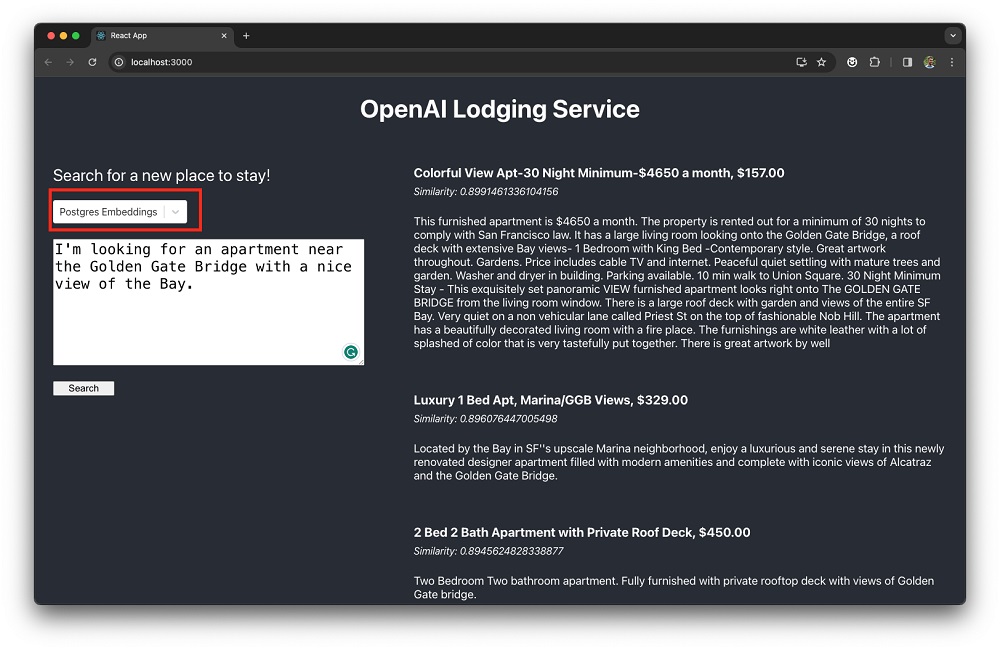
在内部,应用程序执行以下步骤生成推荐结果(具体请参考`{app_dir}/backend/postgres_embeddings_service.js`):
1. 应用程序使用OpenAI嵌入模型(text-embedding-ada-002)生成了用户提示的向量化表示:
const embeddingResp = await this.#openai.embeddings.create(
{model: "text-embedding-ada-002",
input: prompt});2. 应用程序使用生成的向量来检索存储在Postgres中的最相关的Airbnb房产:
const res = await this.#client.query( "SELECT name, description, price, 1 - (description_embedding <=> $1) as similarity " + "FROM airbnb_listing WHERE 1 - (description_embedding <=> $1) > $2 ORDER BY description_embedding <=> $1 LIMIT $3", ['[' + embeddingResp.data[0].embedding + ']', matchThreshold, matchCnt]);
相似度是通过计算描述嵌入向量列和用户提示向量之间的余弦距离来计算的。
3. 推荐的Airbnb房产以JSON格式返回给React前端:
let places = [];
for (let i = 0; i < res.rows.length; i++) {
const row = res.rows[i];
places.push({
"name": row.name,
"description": row.description,
"price": row.price,
"similarity": row.similarity });
}
return places;扩展方式
现在,Postgres存储了超过7,500个Airbnb房产。数据库只需几毫秒就能执行精确的最近邻搜索,比较用户提示和Airbnb描述的嵌入向量。
然而,精确的最近邻搜索(全表扫描)也有其局限性。随着数据集的增长,Postgres执行多维向量的相似度搜索所需时间会变长。
为了在数据量和流量增加的情况下保持Postgres的性能和可扩展性,你可以使用专门针对向量化数据的索引,或者使用分布式版本的Postgres来水平扩展存储和计算资源。
pgvector扩展支持多种索引类型,包括性能最佳的HNSW索引(Hierarchical Navigable Small World)。该索引对向量化数据执行近似最近邻搜索(ANN),即使在大数据量下,数据库也能保持低延迟和可预测性。但是,由于搜索是近似的,搜索的召回率可能不是100%相关/准确,因为索引仅遍历数据的子集。
例如,以下是如何为Airbnb嵌入向量在Postgres中创建HNSW索引的示例:
CREATE INDEX ON airbnb_listing USING hnsw (description_embedding vector_cosine_ops) WITH (m = 4, ef_construction = 10);
要深入了解HNSW索引是如何构建并在Airbnb数据上执行ANN搜索的,请查看此视频:
通过分布式PostgreSQL,当单个数据库服务器的容量不再足够时,你可以轻松扩展数据库的存储和计算资源。尽管PostgreSQL最初是为单服务器部署而设计的,但它的生态系统现在包括了几个扩展和解决方案,使其能够在分布式配置中运行。其中一个解决方案是YugabyteDB,它是一种分布式SQL数据库,扩展了Postgres在分布式环境中的功能。
YugabyteDB从2.19.2版本开始支持pgvector扩展。它将数据和嵌入向量分布在一个节点集群上,便于进行大规模的相似度搜索。因此,如果你想在分布式版本的Postgres上运行Airbnb服务:
1. 部署一个多节点的YugabyteDB集群。
2. 在`{app_dir}/application.properties.ini`文件中更新数据库连接设置:
# Configuration for a locally running YugabyteDB instance with defaults. DATABASE_HOST=localhost DATABASE_PORT=5433 DATABASE_NAME=yugabyte DATABASE_USER=yugabyte DATABASE_PASSWORD=yugabyte
3. 重新加载数据(或使用YugabyteDB Voyager从正在运行的Postgres实例进行迁移),然后重启应用程序。由于YugabyteDB与Postgres在功能和运行时兼容,因此不需要进行其他代码级别的更改。文章来源:https://www.toymoban.com/diary/sql/624.html
祝你在使用Postgres构建可扩展的AI应用程序时玩得开心!如果你想了解有关将Postgres作为向量数据库的更多信息,请告诉我。文章来源地址https://www.toymoban.com/diary/sql/624.html
到此这篇关于如何在Postgres中构建可扩展的AI应用程序_PostgreSQL入门和扩展的文章就介绍到这了,更多相关内容可以在右上角搜索或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!