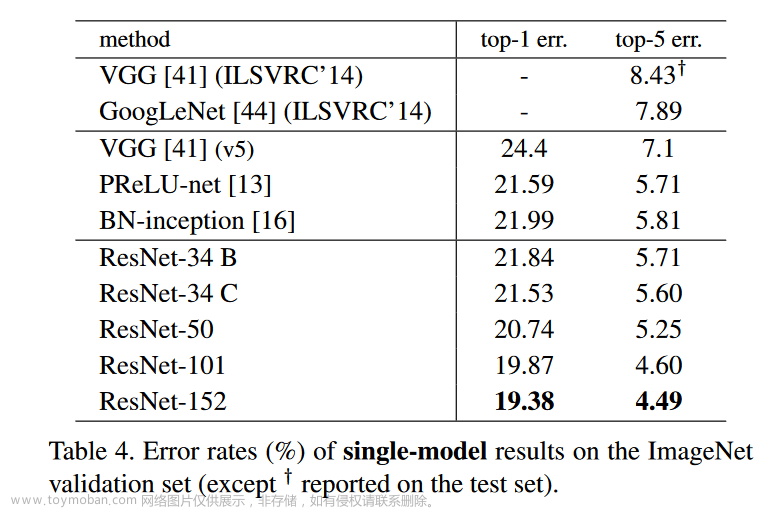
Top-1 错误率:指预测输出的概率最高的类别与人工标注的类别相符的准确率,就是你预测的label取最后概率向量里面最大的那一个作为预测结果,如过你的预测结果中概率最大的那个分类正确,则预测正确,否则预测错误。比如预测100张图像的类别,每张图像的最高概率错误的有2张,那么top-1为2%;
Top-5 错误率:指预测输出的概率最高的前5个类别,就是最后概率向量最大的前五名中,只要出现了正确概率(与人工标注类别一致)即为预测正确,否则预测错误。比如预测100张图像的类别,每张图像前5个最高概率类别中没有一个正确时的张数有3张,那么top-5错误率为3%;
Top-1 错误率是指概率最大的预测结果不在正确标签中的概率。
Top-5 错误率是指概率前五的预测结果不在正确标签中的概率。计算公式如下:
TOP-1 正确率 =(所有测试图片中正确标签包含在最高分类概率中的个数)除以(总的测试图片数)
TOP-1 错误率 =(所有测试图片中正确标签不在最高分类概率中的个数)除以(总的测试图片数)
TOP-5 正确率 =(所有测试图片中正确标签包含在前五个分类概率中的个数)除以(总的测试图片数)
TOP-5 错误率 =(所有测试图片中正确标签不在前五个概率中的个数)除以(总的测试图片数)
代码实现:
# acc.py
import torch
def accu(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
# torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) -> (Tensor, LongTensor)
# input:输入张量
# k:指定返回的前几位的值
# dim:排序的维度
# largest:返回最大值
# sorted:返回值是否排序
# out:可选输出张量
# 注:如需要top-3,可将上述代码(acc.py)改为 output.topk( , 3, , )以及对应的train代码里面改topk=(3, )。# train.py
# 计算Top1
pred1_train, pred2_train = accu(outputs, lables, topk=(1, ))
train_top1.update(pred1_train[0], val_images.size(0))
#train_top2.update(pred2_train[0], val_images.size(0))
t_top1 = train_top1.avg
#t_top2 = train_top2.avg
# 打印结果
print('[epoch %d] train_loss: %.3f test_loss: %.3f val_accuracy: %.3f top1: %.4f' %
(epoch + 1, running_loss / train_steps, testing_loss / test_steps , val_accurate, t_top1))
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += float(val) * n
self.count += n
self.avg = self.sum / self.count
参考博文:学习笔记30-Top1和Top5定义与代码复现_李卓璐的博客-CSDN博客
机器学习的监督学习中,为了方便绘制和展示,我们常用表格形式的混淆矩阵(Confusion Matrix)作为评估模式。这在无监督学习中一般叫做匹配矩阵。
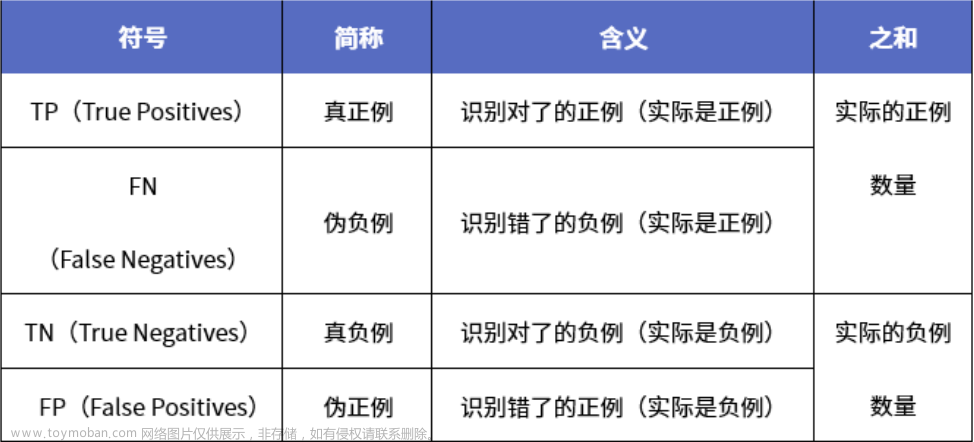
True Positive(TP) :预测为正例,实际为正例,即算法预测正确(True)
False Positive(FP) :预测为正例,实际为负例,即算法预测错误(False)
True Negative(TN) :预测为负例,实际为负例,即算法预测正确(True)
False Negative(FN) :预测为负例,实际为正例,即算法预测错误(False)
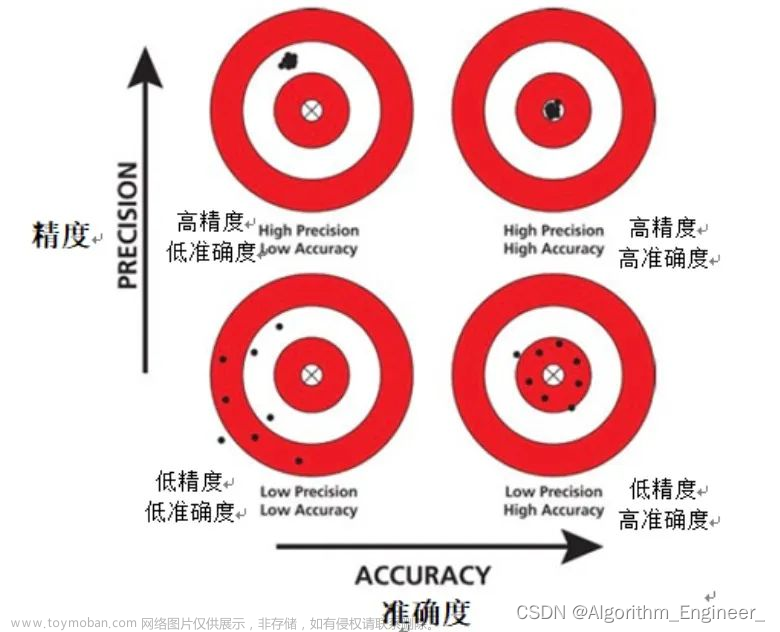
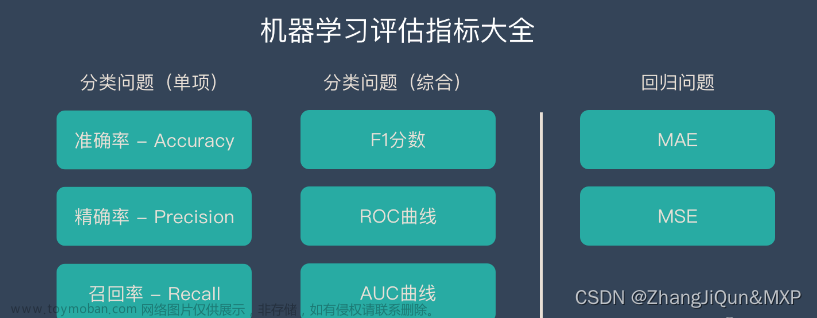
① Accuracy:准确率,指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是负例,反映的是模型算法整体性能,其公式如下:

② Precision:精确率,指的是正确预测的正样本数占所有预测为正样本的数量的比值,也就是说所有预测为正样本的样本中有多少是真正的正样本,它只关注正样本,这是区别于Accuracy的地方,其公式如下:

③ F1-Score:F1分数,是统计学中用来衡量二分类模型精确度的一种指标,它被定义为精确率和召回率的调和平均数,它的最大值是1,最小值是0,其公式如下:

即:
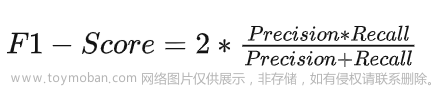
④ Recall:召回率,指的是正确预测的正样本数占真实正样本总数的比值,也就是指能从这些预测样本中能够正确找出多少个正样本,其公式如下:
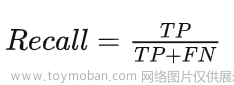
⑤ TPR(True Positive rate):真阳率,指的是在所有实际为阳性的样本中,被正确地判断为阳性的比率,同召回率,其公式如下:

⑥ FPR(False Positive rate):假阳率,指的是在所有实际为阴性的样本中,被错误地判断为阳性的比率,其公式如下:
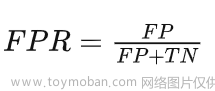
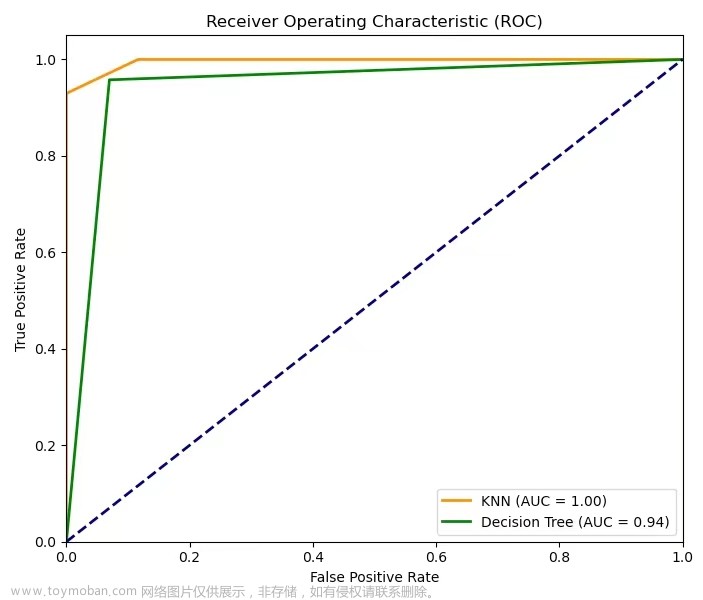
⑦ ROC(Receiver Operating Characteristic):受试者工作特征曲线,其以FPR假阳率为X轴坐标,以TPR真阳率为Y轴坐标,曲线越靠近左上角则说明模型算法性能越好 。
⑧ AUC(Area Under Curve):ROC曲线下的面积,模型通常对应于其对角线,通常AUC的值范围为0.5~1,其值越大说明模型算法的性能越好,AUC为0.5时模型算法为“随机猜测”,其值为1时说明模型算法达到理想状态。通常我们可以使用sklearn.metrics.auc(fpr, tpr)来求得AUC值。
⑨ PRC(Precision-Recall Curve):精准率-召回率曲线也叫PR曲线,其以Recall为X轴坐标,以Precision为Y轴坐标,通过对模型算法设定不同的阈值会得到不同的precision和recall值,将这些序列绘制到直角坐标系上就得到了PR曲线,PR曲线下的面积为1时则说明模型算法性能最为理想。
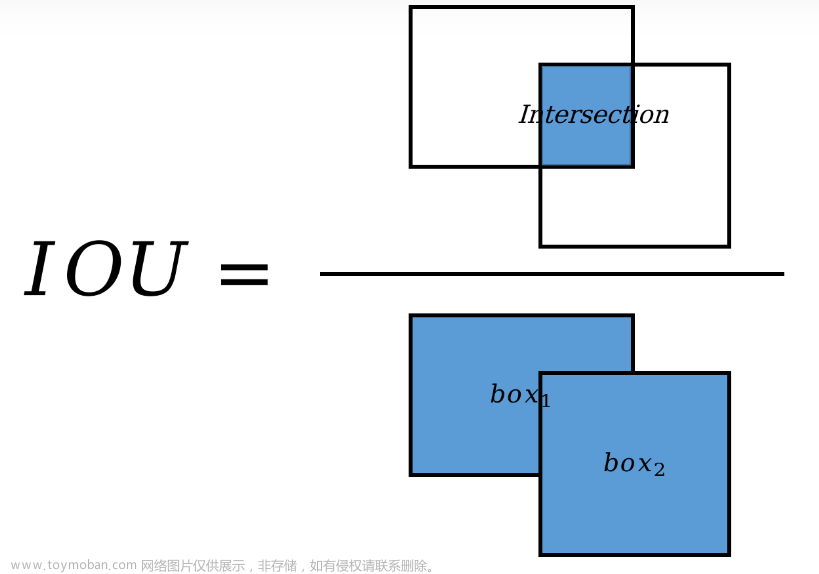
⑩ IOU(Intersection over Union):交并比,目标检测模型中常用的指标,指的是ground truth bbox与predict bbox的交集面积占两者并集面积的一个比率,IoU值越大说明预测检测框的模型算法性能越好,通常在目标检测任务里将 IoU>=0.7 的区域设定为正例(目标),而将IoU<=0.3的区域设定为负例(背景),其余的会丢弃掉,形象化来说可以用如下图来解释IoU:
如果我们用A表示ground truth bbox的面积,B表示predict bbox的面积,而I表示两者的交集面积,那么IoU的计算公式如下:
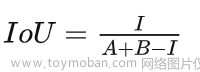
pytorch中的IOU值计算:
def box_area(boxes):
return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
def box_iou(boxes1, boxes2):
area1 = box_area(boxes1)
area2 = box_area(boxes2)
lt = torch.max(boxes1[:, :2], boxes2[:, :2])
rb = torch.min(boxes1[:, 2:], boxes2[:, 2:])
wh = rb - lt
inter = wh[:, 0] * wh[:, 1]
iou = inter / (area1 + area2 - inter)
return iou⑪ AP(Average Percision):AP为平均精度,指的是所有图片内的具体某一类的PR曲线下的面积,其计算方式有两种,第一种算法:首先设定一组recall阈值[0, 0.1, 0.2, …, 1],然后对每个recall阈值从小到大取值,同时计算当取大于该recall阈值时top-n所对应的最大precision。这样,我们就计算出了11个precision,AP即为这11个precision的平均值,这种方法英文叫做11-point interpolated average precision;第二种算法:该方法类似,新的计算方法假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, …, M/M),对于每个recall值r,该recall阈值时top-n所对应的最大precision,然后对这M个precision值取平均即得到最后的AP值。
⑫ mAP(Mean Average Percision):mAP为均值平均精度,指的是所有图片内的所有类别的AP的平均值,目前,在目标检测类里用的最多的是mAP,一般所宣称的性能是在IoU为0.5时mAP的值。
⑬ MAE(Mean Absolute Error):平均绝对误差,对于回归预测类,其能更好地反映预测值与真实值误差的实际情况,其计算公式如下:
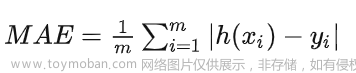
⑭ RMSE(Root Mean Square Error):均方根误差,用于衡量观测值与真实值之间的偏差,其对一组预测中的特大或特小误差反映比较敏感,常用来作为机器学习模型预测结果衡量的标准,其计算公式如下: 文章来源:https://www.toymoban.com/news/detail-447338.html
 文章来源地址https://www.toymoban.com/news/detail-447338.html
文章来源地址https://www.toymoban.com/news/detail-447338.html
到了这里,关于Top-1错误率、Top-5错误率等常见的模型算法评估指标解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!