前言
介绍一篇最近看的低照度增强方面的论文——自校准照明,文中所给的方法取得了非常不错的效果,值得我们去学习和思考。
论文名称:Toward Fast, Flexible, and Robust Low-Light Image Enhancement(实现快速、灵活和稳健的低光照图像增强)
论文信息:由大连理工大学2022年4月发表在CVPR Oral上的一篇文章。
论文地址:https://arxiv.org/abs/2204.10137
论文主要贡献总结如下:
1.我们提出了一个自校正的共享权重照明学习模块,使各阶段的结果收敛,提高了曝光稳定性,大大减少了计算量。据我们所知,这是第一个利用在学习过程中加速弱光图像增强算法的工作。
2.我们定义了无监督训练损失,在自校正模块的作用下约束各阶段的输出,赋予了对不同场景的适应能力。属性分析表明,SCI具有操作不敏感的适应性和模型无关的通用性,这是现有文献所没有的。
3.我们进行了大量的实验,以证明我们的方法优于其他最先进的方法。进一步在黑暗人脸检测和夜间语义分割方面的应用,揭示了本文方法的实用价值。简而言之,SCI重新定义了基于网络的微光图像增强领域的视觉质量、计算效率和下游任务的性能的峰值点。
下图是跟其他的弱光图像增强方法进行了对比,总的来说就是一个“六边形战士”。
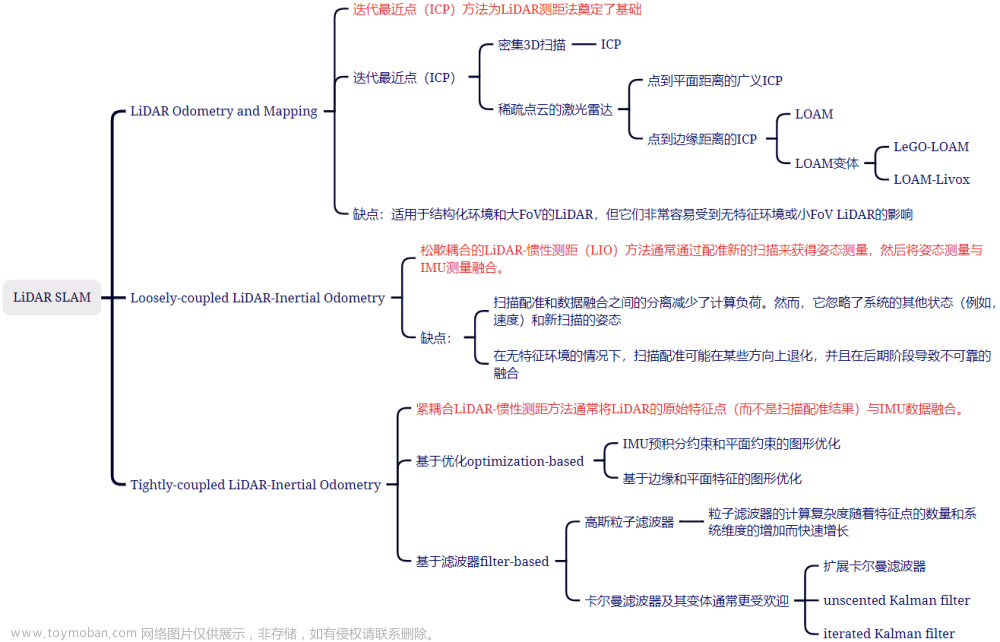
一、基本原理
文章创新性的提出了Self-Calibrated Illumination(自校准照明)学习框架,通过引入自校准模块大幅降低了级联机制下较大的推理代价,加快了推理速度。
网络的基本原理依旧是基于经典的Retinex理论,下面来说一下这个理论。
-
Retinex图像分解理论
一幅图像 S S S可看做是光照分量 I I I 和反射分量 R R R的乘积,即
S = I × R S=I ×R S=I×R 反射分量 R 反射分量R 反射分量R: 物体的本身性质决定的恒定的部分 物体的本身性质决定的恒定的部分 物体的本身性质决定的恒定的部分
光照分量 I :受外界光照影响的部分 光照分量I:受外界光照影响的部分 光照分量I:受外界光照影响的部分
思路:通过对光照分量 I 进行校正,来达到增强图像的目的。 思路:通过对光照分量I进行校正,来达到增强图像的目的。 思路:通过对光照分量I进行校正,来达到增强图像的目的。 -
因此对于一张低光照图像 y y y,就等于它的清晰图像 z z z(对应它的反射分量)乘以光照量 x x x。即:
y = z ⊗ x \bold y=\bold z\otimes\bold x y=z⊗x
-
总之核心思想:获得表现本质信息的反射图像。通过分离入射图像,就有可能减弱因光照因素产生的对图像的影响,可以增强图像的细节信息,获得代表图像本质信息的内容。
针对我们现在已经获得的一副图像数据 S ( x , y ) S(x,y) S(x,y),如果要得到增强后的图像 R ( x , y ) R(x,y) R(x,y) ,现在的关键是如何得到 I ( x , y ) I(x,y) I(x,y)。
单尺度Retinex算法(SSR)
- 对于式子:
S
=
I
×
R
S = I \times R
S=I×R,两边取对数可得:
L o g [ R ( x , y ) ] = L o g [ S ( x , y ) ] − L o g [ I ( x , y ) ] Log[R(x,y)] = Log[S(x,y)]-Log[I(x,y)] Log[R(x,y)]=Log[S(x,y)]−Log[I(x,y)]
R
e
t
i
n
e
x
Retinex
Retinex 理论的提出者指出这个
I
(
x
,
y
)
I(x,y)
I(x,y)可以通过对原图
S
(
x
,
y
)
S(x,y)
S(x,y)进行高斯模糊而得到:
至于高斯模糊的具体过程,大家可以百度一下。
- 而这个I(x,y)是否可以经高斯模糊后准确得到,个人认为目前应该没有准确的数学证明,也不过是作为一个近似的处理方法而已。
- 那么另一种方法就是借助CNN的优势,可以通过设计网络的形式将这个尤为关键的光照量 I ( x , y ) I(x,y) I(x,y)经过数据训练的方式得到它。而自校准照明就是其中一种学习照明量的网络。
二、论文内容
1.网络结构

如图所示,整个结构分为两部分:Self-Calibrated Module(自校正模块)和 Illumination Eastimation(照明估计模块),其中的自校正模块是一个辅助作用模块,用来减轻级联模式的计算负担。
Illumination Eastimation
并没有直接去学习图片和明亮之间的映射,作者提出了一个新的学习照明量方法。
先来看照明估计模块:
u
t
u^{t}
ut:第t阶段的残差------计算残差的方式可以极大的减少计算量和保持稳定,尤其对于曝光控制会有很好的能力。
(感觉就是ResNet思想,在这里的作用就是通过级联网络的形式每个阶段学习一点光照量,最终把整个的光照量学习到。)
X
t
X^{t}
Xt:第t阶段的光照
H
θ
H_{θ}
Hθ:光照估计网络,并且Hθ与阶段数无关,即在每一阶段光照估计网络均保持结构与参数共享状态
Self-Calibrated Module:作用使每个阶段的结果收敛到同一状态。

y
y
y:低照度图像
Z
Z
Z: 目标图像
S
S
S:自校正映射
K
ϑ
K_{ϑ}
Kϑ:参数化操作符,ϑ 参数可学习
V
t
V{t}
Vt:校准后的用于下一阶段的输入
将各个阶段的输入(第一级除外)与原始弱光输入(即第一级的输入)连接起来,间接探索各个阶段之间的收敛行为,引入了一个自校正映射S,以表示每一级输入与第一级输入之间的差异。自校准模块确保在训练过程中的不同阶段的输出均能够收敛到相同的状态。
光照优化过程的基本单元被重新公式化为:
自校准模块的引入使得不同阶段的结果能够很快地收敛到相同状态,即三个阶段的结果重合。但在没有自校准模块的情况下,无法发现这种现象。

自己根据上面内容重新绘制了一个图,用于更好的理解。

2.损失函数
论文考虑到现有配对数据的不准确性,采用无监督学习来扩大网络的能力。定义如下的无监督损失函数:
分为两个部分:保真度损失Lf和平滑损失Ls;α和β是两个平衡参数。
保真度损失
Lf用于保证估计照度和每个阶段输入之间的像素级一致性;T为总级数。
这个很好理解,xt是t阶段的光照量,括号内部分是经过自校正模块后得到的辅助量v(t-1),自校准模块的作用是想使每个阶段的结果趋于一致,那么就需要保证这两个量在每个阶段应该是非常近似的才行。
平滑损失

N
N
N:总像素数
i
i
i:表示第i个像素。
N
(
i
)
N (i)
N(i):表示i在其5 × 5窗口中的相邻像素
W
i
,
j
W_{i,j}
Wi,j:表示权重
我的理解是对于每一个阶段所得到的光照量,整体的亮暗分布应该是平滑的,不会是局部过亮或者过暗的情况,那么就需要让每一个像素值与周围的像素值应该非常近似。
3.讨论
Operation-Insensitive Adaptability(操作不敏感适应性,即在不同的简单操作设置下获得稳定的性能)

整个意思大概为SCI 在不同设置下都会使弱光观察变亮,显示出非常相似的增强结果。
原因在于SCI 不仅转换了照明的共识 (即残差学习),而且集成了物理原理 (即像素级除法操作)。
Model-Irrelevant Generality(模型不相关通用性,即可以应用于基于光照的现有著作以提高性能)

如果不限制与任务相关的自校正模块,我们的SCI实际上是一个广义的学习范式,所以理想情况下,它可以直接应用到实现的工作中。文章来源:https://www.toymoban.com/news/detail-457353.html
最后,作者做了一个对比实验:
直接学习照明 ———>>> 图像曝光过度
学习照明和输入之间残差 ———>>> 确实抑制了过度曝光,但总体图像质量仍然不高,尤其是对于细节的把握。
相比之下,本文的方法得到的增强结果不仅抑制了过度曝光,而且丰富了图像结构。 文章来源地址https://www.toymoban.com/news/detail-457353.html
文章来源地址https://www.toymoban.com/news/detail-457353.html
二、模型代码(官方代码)
import torch
import torch.nn as nn
from loss import LossFunction
class EnhanceNetwork(nn.Module):
def __init__(self, layers, channels):
super(EnhanceNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.ReLU()
)
self.conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.conv)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
illu = fea + input
illu = torch.clamp(illu, 0.0001, 1)
return illu
class CalibrateNetwork(nn.Module):
def __init__(self, layers, channels):
super(CalibrateNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.layers = layers
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.convs = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.convs)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
delta = input - fea
return delta
class Network(nn.Module):
def __init__(self, stage=3):
super(Network, self).__init__()
self.stage = stage
self.enhance = EnhanceNetwork(layers=1, channels=3)
self.calibrate = CalibrateNetwork(layers=3, channels=16)
self._criterion = LossFunction()
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
ilist, rlist, inlist, attlist = [], [], [], []
input_op = input
for i in range(self.stage):
inlist.append(input_op)
i = self.enhance(input_op)
r = input / i
r = torch.clamp(r, 0, 1)
att = self.calibrate(r)
input_op = input + att
ilist.append(i)
rlist.append(r)
attlist.append(torch.abs(att))
return ilist, rlist, inlist, attlist
def _loss(self, input):
i_list, en_list, in_list, _ = self(input)
loss = 0
for i in range(self.stage):
loss += self._criterion(in_list[i], i_list[i])
return loss
class Finetunemodel(nn.Module):
def __init__(self, weights):
super(Finetunemodel, self).__init__()
self.enhance = EnhanceNetwork(layers=1, channels=3)
self._criterion = LossFunction()
base_weights = torch.load(weights)
pretrained_dict = base_weights
model_dict = self.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
self.load_state_dict(model_dict)
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
i = self.enhance(input)
r = input / i
r = torch.clamp(r, 0, 1)
return i, r
总结
SCI 开辟了一个新的视角:即在训练阶段引入辅助过程来增强基本单元的模型能力。
以上内容多处夹杂着个人理解,有误的地方欢迎大家批评指正!
到了这里,关于低照度增强--论文阅读【《Toward Fast, Flexible, and Robust Low-Light Image Enhancement》】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[论文阅读笔记20]MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking](https://imgs.yssmx.com/Uploads/2024/02/597527-1.png)




![[论文阅读] BoT-SORT: Robust Associations Multi-Pedestrian Tracking](https://imgs.yssmx.com/Uploads/2024/02/434499-1.png)