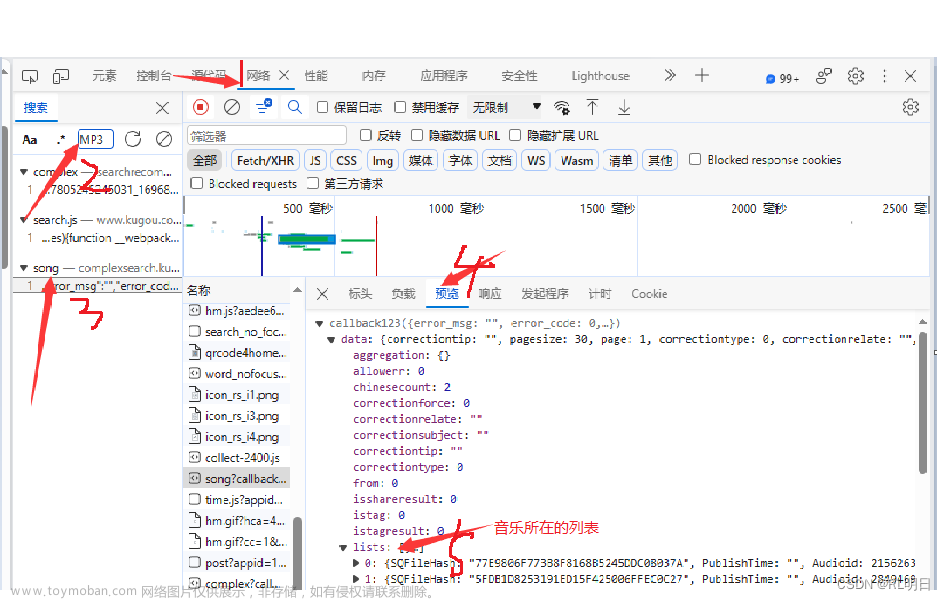
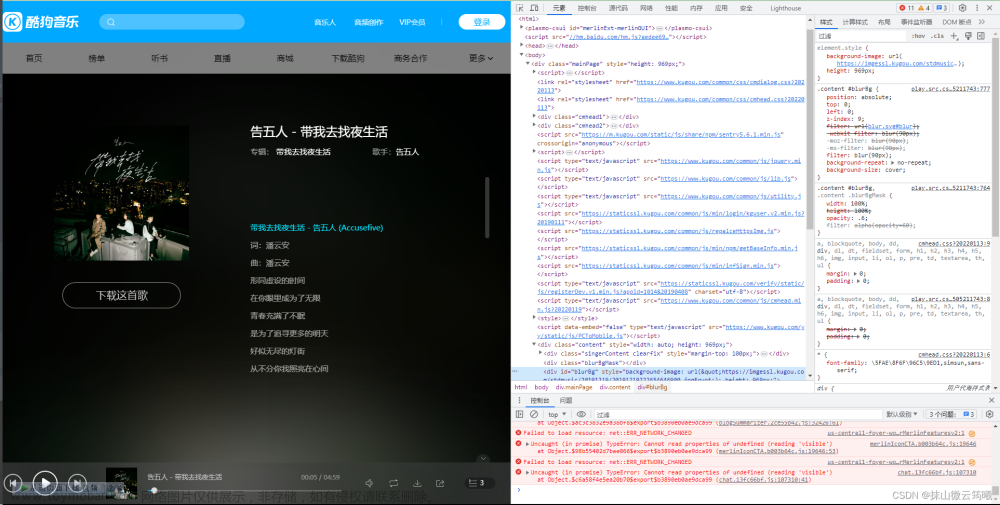
今天来爬爬音乐,一丝丝的无聊

前期准备
软件环境
- Python3.8
- pycharm
模块
requests、re、os 三个
其中requests是第三方模块需要手动安装一下
re、os都是内置模块,不需要安装
浏览器开发者工具
咱们需要学会如何使用开发者工具。
对此很多小伙伴都不会,因为每个浏览器的开发者工具细节上多少有一些差别,我建议都用谷歌浏览器,英文看不懂的话可以调成中文。
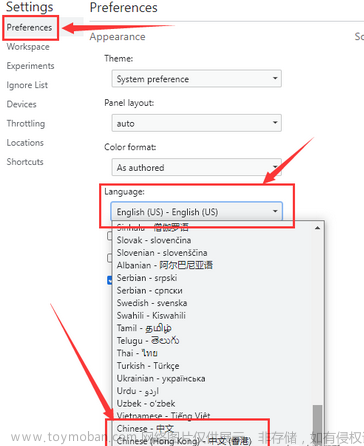
打开开发者工具,点击省略号,点击 shortcuts
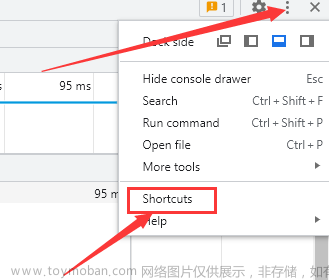
依次点击 preferences - language ,
直接拉到最下方选择中文即可。
代码实现
本次实现步骤大致分为以下五步:
- 发送请求
- 获取数据
- 解析数据
- 保存数据
这里我就不讲怎么分析开发者工具了,有空(摸鱼 )做一个详细的教程,讲解开发者工具。
导入模块
import requests
import re
import os
发送请求
url = 'https://网址自己打一下/discover/toplist?id=3778678'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
获取数据
result = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a></li>', response.text)
for music, title in result:
music_url = f'http://music.163.com/song/media/outer/url?id={music}.mp3'
music_content = requests.get(url=music_url, headers=headers).content
保存数据
with open(filename + title + '.mp3', mode='wb') as f:
f.write(music_content)
print(title)
当然这只是最简单的爬取榜单歌曲,
评论、歌词等等都可以爬取,
还有制作词云图、通过搜索下载,音乐下载器,
等等各种实现下载的方式。
好了,今天的分享就到这里,完整代码下方名片获取哈~文章来源:https://www.toymoban.com/news/detail-460942.html
 文章来源地址https://www.toymoban.com/news/detail-460942.html
文章来源地址https://www.toymoban.com/news/detail-460942.html
到了这里,关于20行代码来爬取某某云的榜单音乐的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!