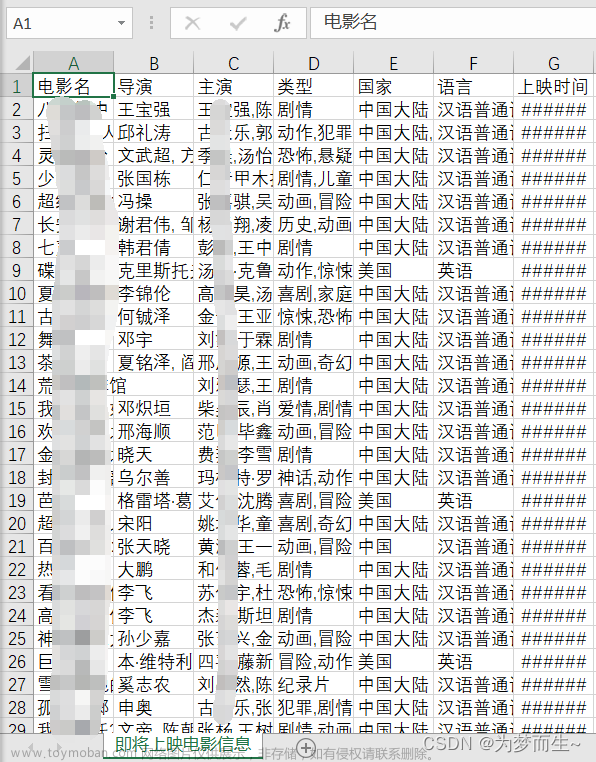
1. 分析爬取地址
打开某乎首页,点击热榜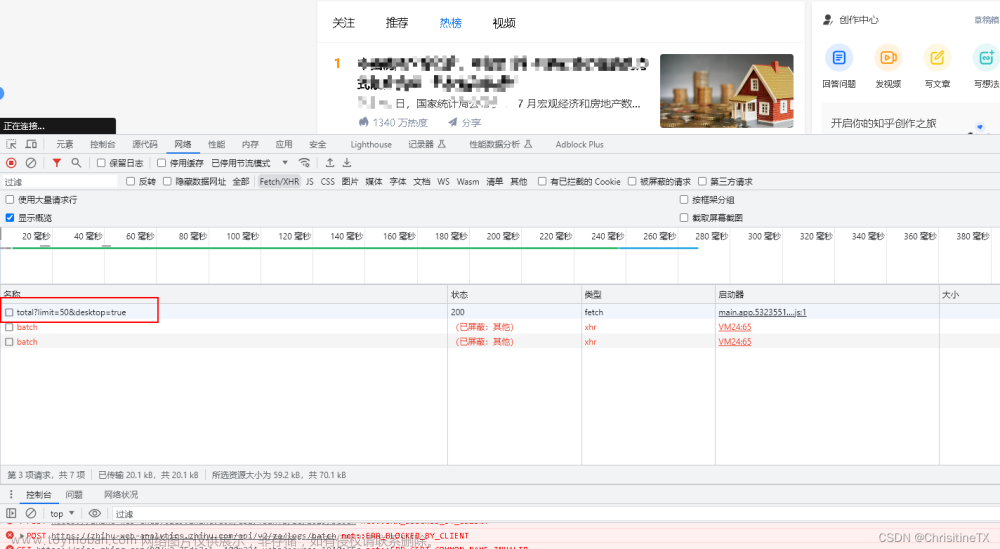
这个就是我们需要爬取的地址,取到地址某乎/api/v3/feed/topstory/hot-lists/total?limit=50&desktop=true
定义好请求头,从Accept往下的请求头全部复制,转换成json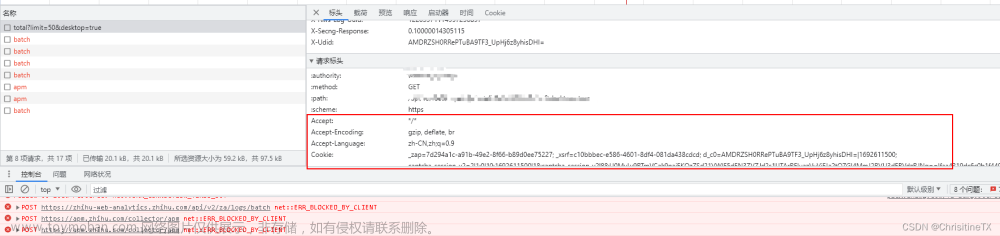
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': '你的请求头中的cookie',
'Sec-Ch-Ua': 'Not/A)Brand\';v=\'99\', \'Google Chrome\';v=\'115\', \'Chromium\';v=\'115',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': 'Windows',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
'X-Ab-Param': '',
'X-Ab-Pb': 'CgInBxIBAA==',
'X-Api-Version': '3.0.76',
'X-Requested-With': 'fetch',
'X-Zse-93': '101_3_3.0',
'X-Zse-96': '2.0_6hUp=vt8=9zOcwtPHcLjutT0sL2PhwOPys0v=fvQr7yneBCmMO2zkvXcYfoc5esu'
}
2. 分析请求结果
通过请求可以看出,hot-lists/total?limit=50&desktop=true请求后的返回参数直接是json格式,则不需要单独处理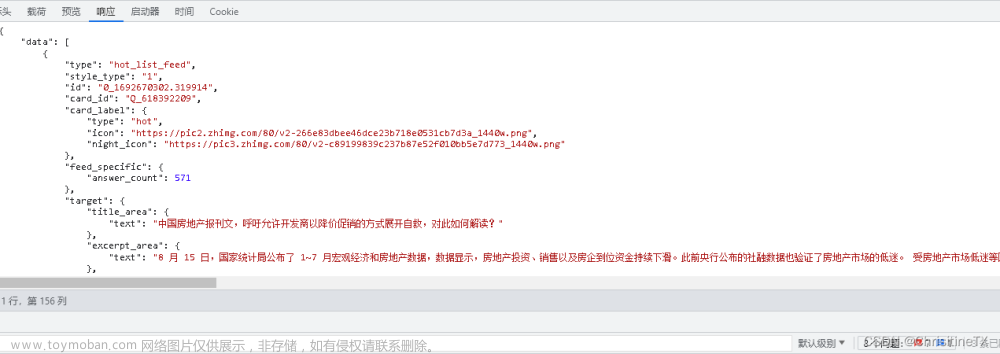
定义好需要抓取的参数按元素获取即可
order_list = [] # 热榜排名
title_list = [] # 热榜标题
desc_list = [] # 热榜描述
url_list = [] # 热榜链接
hot_value_list = [] # 热度值
answer_count_list = [] # 回答数
data_list = json_data['data']
order = 1 # 热榜排名初始值
GET请求接口文章来源:https://www.toymoban.com/news/detail-667089.html
response = requests.get(url=url, headers=headers)
json_data = response.json()
循环数组json并赋值文章来源地址https://www.toymoban.com/news/detail-667089.html
order_list.append(order)
# 热榜标题
title = data['target']['title_area']['text']
print(order, '热榜标题:', title)
title_list.append(title)
desc_list.append(data['target']['excerpt_area']['text'])
url_list.append(data['target']['link']['url'])
hot_value_list.append(data['target']['metrics_area']['text'])
answer_count_list.append(data['feed_specific']['answer_count'])
order += 1```
将结果导出到csv,注意定义一下编码集为utf_8_sig
df = pd.DataFrame(
{
'热榜排名': order_list,
'热榜标题': title_list,
'热榜链接': url_list,
'热度值': hot_value_list,
'回答数': answer_count_list,
'热榜描述': desc_list,
}
)
# 保存结果到csv文件
df.to_csv('知乎热榜.csv', index=False, encoding='utf_8_sig')
### 3. 结果验证

### 注意:如果请求返回的json格式乱码,调整请求头Accept-Encoding,去掉br后即可
到了这里,关于python爬虫实战(3)--爬取某乎热搜的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!