前言
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Selenium
1.功能
-
框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。 使用简单,可使用Java,Python等多种语言编写用例脚本。 -
因为数据被JS加密了想要获取到数据要解密,但想要解密又不是那么简单,所以说,如果用 Selenium 来驱动浏览器加载网页的话,就可以直接拿到 JavaScript渲染的结果了,不用担心使用的是什么加密系统。
2.安装Selenium
- chromedriver下载地址:
http://chromedriver.storage.googleapis.com/index.html - 查看自己有Chrome浏览器的版本,再下载相同版本的chromedriver
查看自己有Chrome浏览器的版本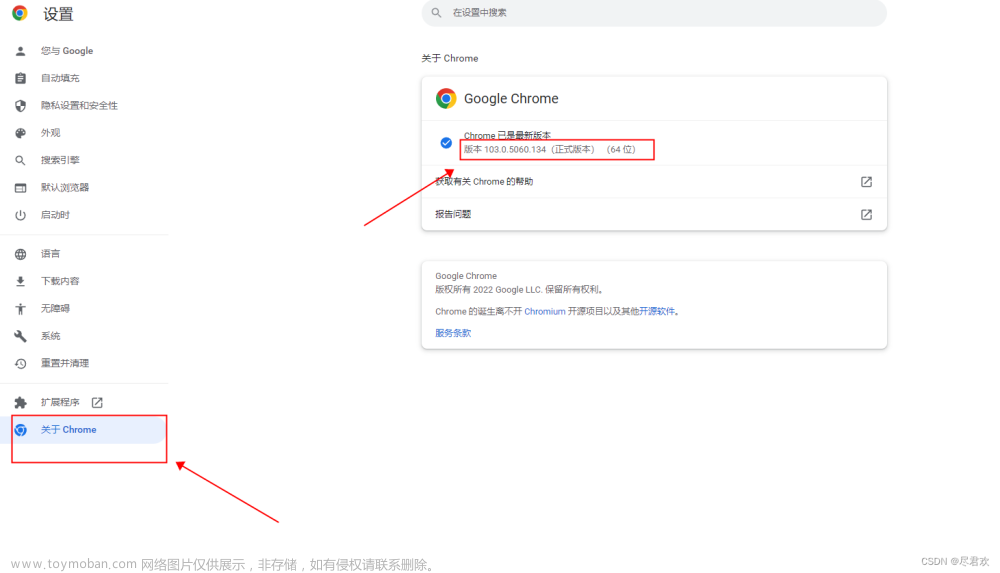 下载以Chrome浏览器相同版本的chromedriver
下载以Chrome浏览器相同版本的chromedriver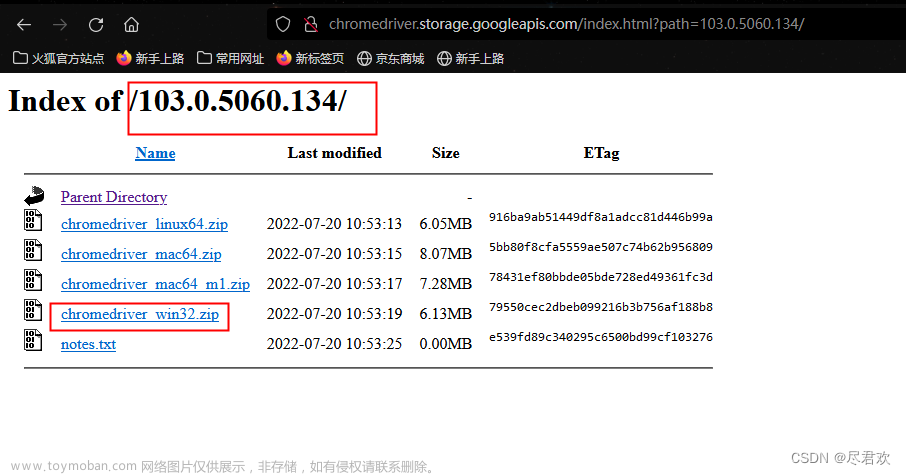
3. 解压 chromedriver包,将 chromedriver.exe复制到python的安装目录中的Python3.8(自己是什么版本就在那)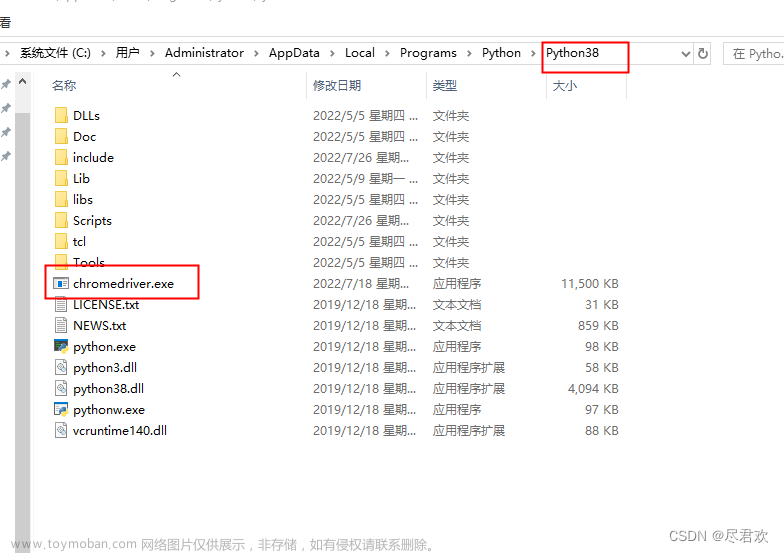
4. 再将 chromedriver.exe,将其复制到 chrome浏览器的所在的位置
选中Chrome 浏览器,右击鼠标,再点击打开文件所在位置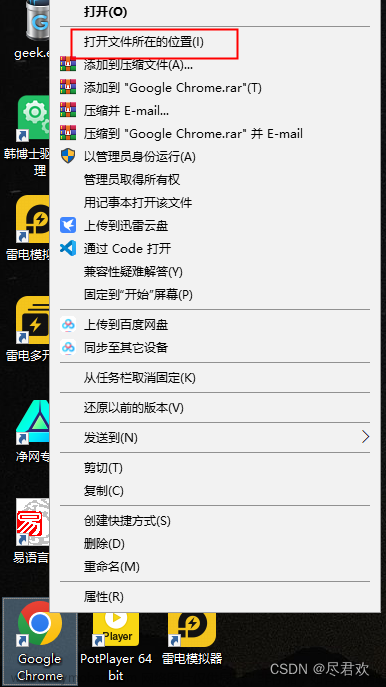
要将 chromedriver.exe 复制到 chrome浏览器的所在的位置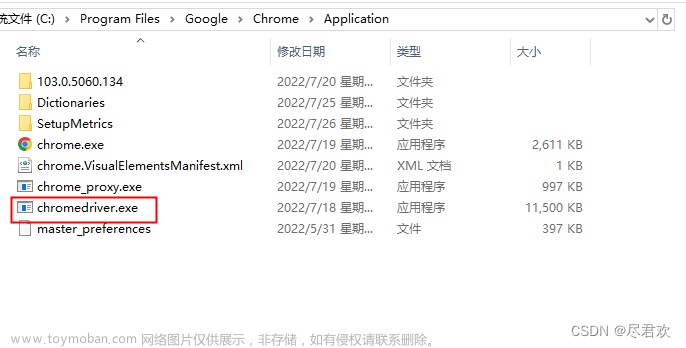
5. 配置环境变量:双击此电脑→双击计算机→系统属性→系统信息→高级系统设置→环境变量→系统变量→双击Path→编辑→新建,将 chrome浏览器的所在的位置路径复制上去 ,然后不要忘记后续全部点击确定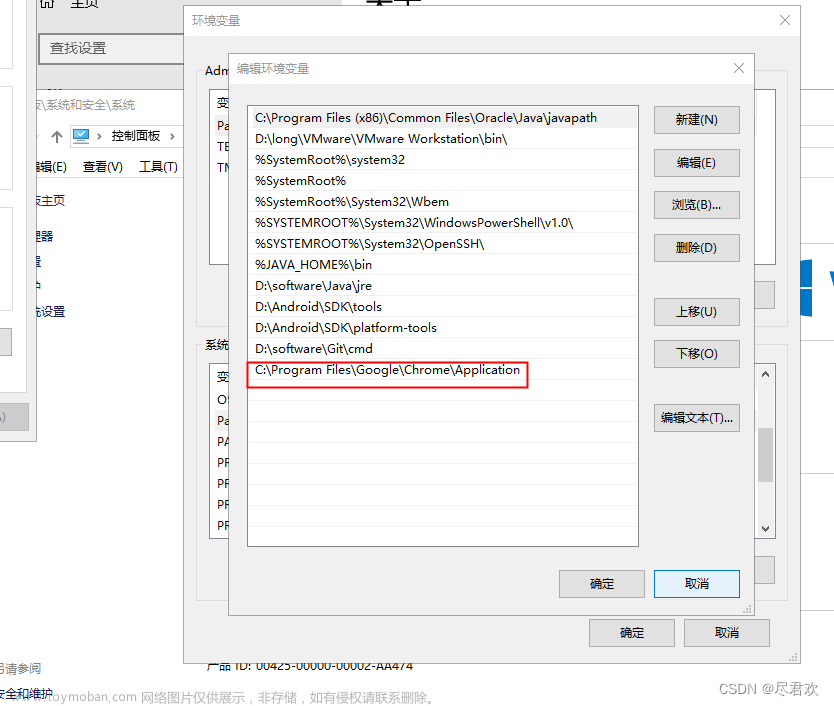
二、使用步骤
1.引入库
- 正确安装好 Python 的 Selenium 库。
pip install Selenium
代码如下(示例):
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
from lxml import etree
from selenium.webdriver.common.keys import Keys
import pymongo
# pymongo有自带的连接池和自动重连机制,但是仍需要捕捉AutoReconnect异常并重新发起请求。
from pymongo.errors import AutoReconnect
from retry import retry
# logging 用来输出信息
import logging
2.设置反屏蔽与无头模式
-
没有加入反屏蔽,这个很容易被检查出来,因为在大多数情况下,检测的基本原理是检测当前浏览器窗口下的 window.navigator 对象是否包含 webdriver 这个属性。因为在正常使用浏览器的情况下,这个属性是 undefined,在使用了 Selenium,Selenium 会给 window.navigator 设置 webdriver 属性。很多网站就通过 JavaScript 判断如果 webdriver 属性存在,那就直接屏蔽。
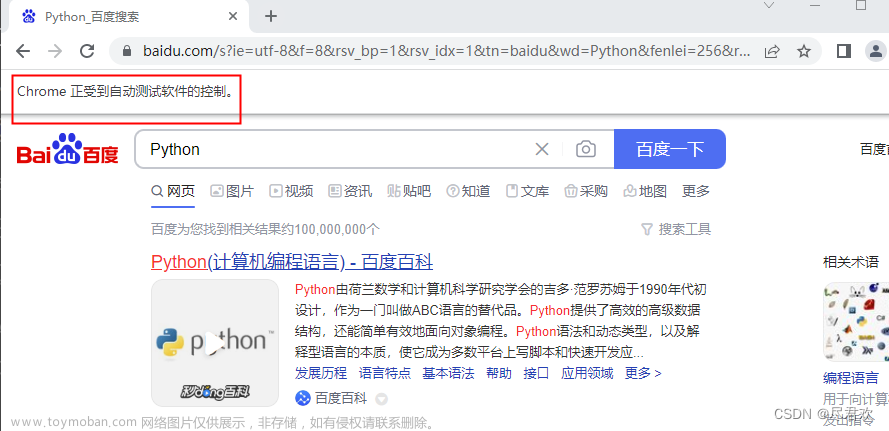
-
可以使用 CDP(即 Chrome Devtools-Protocol,Chrome 开发工具协议)来解决这个问题,通过它我们可以实现在每个页面刚加载的时候执行 JavaScript 代码,执行的 CDP 方法叫作 Page.addScriptToEvaluateOnNewDocument,然后传入上文的 JavaScript 代码即可,这样我们就可以在每次页面加载之前将 webdriver 属性置空了。另外,我们还可以加入几个选项来隐藏 WebDriver 提示条和自动化扩展信息
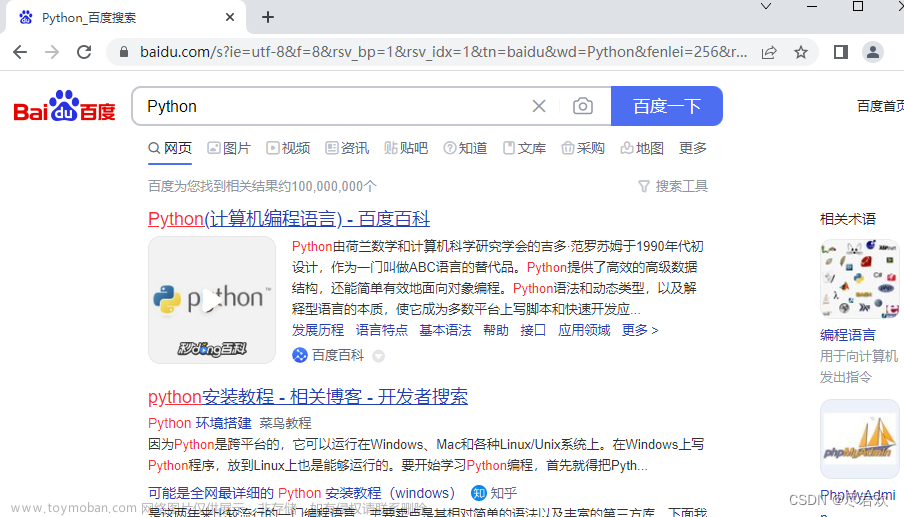
代码如下(示例):
option = ChromeOptions()
# 开启 无头模式
option.add_argument('--headless')
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('https://www.endata.com.cn/BoxOffice/BO/Year/index.html')
# 显式等待 10 秒
wait = WebDriverWait(browser, 10)
# 在10秒内如果找到 XPATH 就退出until
wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="OptionDate"]')))
time.sleep(2)
3.获得数据
- 用 browser.page_source 来输出已响应的代码,传到 Get_the_data方法中,就可以能基础的处理方式来进行提取数据了
代码如下(示例):
# 日志输出格式
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
def Get_the_data(html):
# 格式化 html 代码
selector = etree.HTML(html)
data_set = selector.xpath('//*[@id="TableList"]/table/tbody/tr')
for data in data_set:
movie_name = data.xpath('td[2]/a/p/text()')[0]
movie_type = data.xpath('td[3]/text()')[0]
Total_box_office = data.xpath('td[4]/text()')[0]
Average_ticket_price = data.xpath('td[5]/text()')[0]
sessions = data.xpath('td[6]/text()')[0]
country = data.xpath('td[7]/text()')[0]
Release_date = data.xpath('td[8]/text()')[0]
movie_data = {
'影片名称': movie_name,
'类型': movie_type,
'总票房(万)': Total_box_office,
'平均票价': Average_ticket_price,
'场均人次': sessions,
'国家及地区': country,
'上映日期': Release_date
}
logging.info('get detail data %s', movie_data)
logging.info('saving data to mongodb')
save_data(movie_data)
logging.info('data saved successfully')
4.翻页动作
- 在 Perform_the_action 方法中模拟点击动作 先点击那个向下箭头,要按键盘上的向下箭头,再按回车
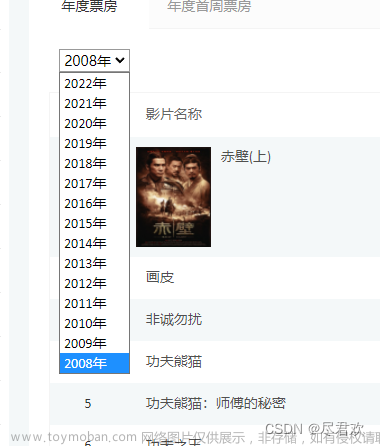
代码如下(示例):
def Perform_the_action():
for i in range(1, 15):
action = browser.find_element(By.XPATH, '//*[@id="OptionDate"]')
time.sleep(1)
action.click()
# 然后用 send_keys 方法,再用 Keys 方法输入回车键
time.sleep(1)
# 按下向下箭头
action.send_keys(Keys.ARROW_DOWN)
time.sleep(1)
# 按下回车
action.send_keys(Keys.ENTER)
time.sleep(2)
# 返回 html 源码
response = browser.page_source
Get_the_data(response)
# print(i)
5.读入数据
- 将数据保存到Mongodb数据库中

代码如下(示例):文章来源:https://www.toymoban.com/news/detail-470687.html
# 指定 mongodb 的连接IP,库名,集合
MONGO_CONNECTION_STRING = 'mongodb://192.168.27.101:27017'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client['movie_data']
collection = db['movie_data']
@retry(AutoReconnect, tries=4, delay=1)
def save_data(data):
"""
将数据保存到 mongodb
使用 update_one() 方法修改文档中的记录。该方法第一个参数为查询的条件,第二个参数为要修改的字段。
upsert:
是一种特殊的更新,如果没有找到符合条件的更新条件的文档,就会以这个条件和更新文档为基础创建一个新的文档;如果找到了匹配的文档,就正常更新,upsert非常方便,不必预置集合,同一套代码既能用于创建文档又可以更新文档
"""
# 存在则更新,不存在则新建,
collection.update_one({
# 保证 数据 是唯一的
'影片名称': data.get('影片名称')
}, {
'$set': data
}, upsert=True)
6.最后方法调用
代码如下(示例):文章来源地址https://www.toymoban.com/news/detail-470687.html
if __name__ == '__main__':
# 返回 html 源码
response = browser.page_source
Get_the_data(response)
Perform_the_action()
browser.close()
总结
- 本节是对 Selenium 的常规用法,使用 Selenium来处理 JavaScript 渲染的页面不再是难事
到了这里,关于Selenium实战案例之爬取js加密数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频](https://imgs.yssmx.com/Uploads/2024/04/855397-1.png)



