目录
15章习题
15.1 HBase 数据库有何基本功能?
15.2 Big Table 如何对稀疏数据进行存储的?
15.3 面向行的数据存储具有何特点?面向列的数据存储具有何特点?
15.4 HDFS 与 HBase 有何区别?
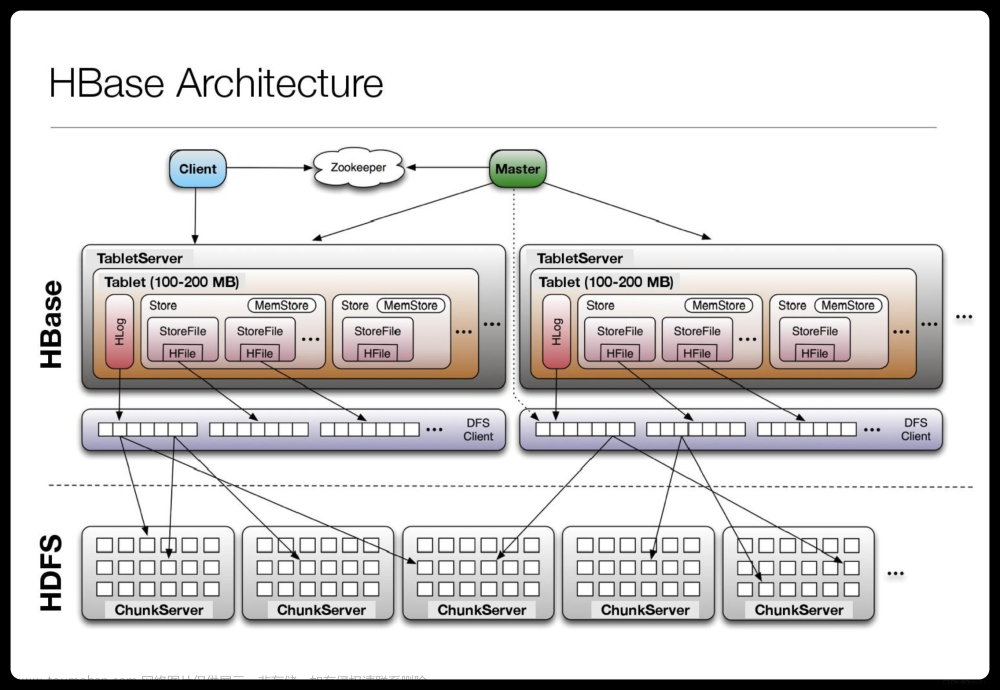
15.5 HBase 集群主要由哪几类节点构成?它们在集群中起到什么作用?
15.6 HBase 中的数据模型由那些的逻辑组件组成?
15.7 Cassandra 数据库有何特点?
15.8 Cassandra 的关键组件主要有哪些?试简述这些组件的功能。
15章习题 HBase数据库与Cassandra数据库
15.1 HBase 数据库有何基本功能?
1. HBase 是一个面向列的数据库,由开源的 Google Big Table 存储架构实现。 它可以管理结构化和半结构化数据,并具有一些内置功能,如可扩展性、版本管 理、压缩和垃圾收集。由于它适应预写式日志记录和分布式配置,因此可以提供容错和快速从单个服务器故障中恢复。建立在Hadoop/HDFS 之上的 HBase 可以使用 Hadoop 的 MapReduce 功能来进行数据存储和处理。
2. HBase 是一个开源、非关系的分布式数据库,基于 Google 的 Big Table 模型, 用 Java 编写。在 HDFS(Hadoop 分布式文件系统)之上运行,为 Hadoop 提供类似 Big Table 的功能,提供了一种容错的方式来存储大量的稀疏数据。
3. HBase 是为低时延操作而构建的系统。它提供从数十亿的记录中访问单个行的功能。通过 shell 命令、Java 编写的客户端、REST、Avro 或 Thrift 访问数据。
15.2 Big Table 如何对稀疏数据进行存储的?
用户将数据存储在标签表中。数据行含有一个可排列的键和一个任意数目的列,映射是一个抽象数学类型,由键集合和值集合组成,其中每个键关联于一个值。
15.3 面向行的数据存储具有何特点?面向列的数据存储具有何特点?
面向列:它可以管理结构化和半结构化数据,并具有一些内置功能,如可扩展性、版本管理、压缩和垃圾收集。由于它适应预写式日志记录和分布式配置,因此可以提供容错和快速从单个服务器故障中恢复。
面向行:是一个稀疏的、分布式的、持久的多维有序映射。该映射由行键、 列键和时间戳进行索引;映射中的每个值是未解释的字节数组。
15.4 HDFS 与 HBase 有何区别?
HDFS 适合于高时延的批处理操作,其数据主要通过 Map Reduce 访问,旨在进行批处理,因此不具有随机读/写的概念。
HBase 是为低时延操作而构建的系统。它提供从数十亿的记录中访问单个行的功能。通过 shell 命令、Java 编写的客户端、REST、Avro 或 Thrift 访问数据。
15.5 HBase 集群主要由哪几类节点构成?它们在集群中起到什么作用?
HBase 集 群 有 一 个 主 节 点 (称为HMaster ) 和 多 个 区 域 服 务 器 ( 称为HRegionServer)。每个区域服务器包含多个区域(称为 HRegions)。
HBase 中的 HMaster 主要负责: 执行管理任务、管理和监视集群,分配区域到区域服务器、控制负载均衡与故障转移。
HRegionServer 执行下面的任务: 托管与管理区域、自动分割区域、处理读/写请求、与客户直接通信。
15.6 HBase 中的数据模型由那些的逻辑组件组成?
HBase 中的数据模型由不同的逻辑组件组成,如表、行、列族、列、单元格和版本。
15.7 Cassandra 数据库有何特点?
1. 提供了可扩展性、容错性和一致性;
2. 面向列的数据量;
3. 其分布式设计基于 Amazon 的 Dynamo 及其 Google 的 BigTable 上的数据模型;
4. 建立在 Facebook 之上,与关系数据库管理系统有着很大的不同。
15.8 Cassandra 的关键组件主要有哪些?试简述这些组件的功能。
1. 节点(Node):数据存储的地方。
2. 数据中心(Data center):相关节点的集合。
3. 集群(Cluster):集群是包含一个或多个数据中心的组件。
4. 提交日志(Commit log):提交日志是 Cassandra 中的崩溃恢复机制。每个写入操作将被写入提交日志。
5. 内存表(Mem-table):内存表是内存驻留的数据结构。提交日志后,数据将被写入到内存表中。有些时候,对于单列族,将有多个内存表。
6. SSTable:当内容达到阈值时,从内存表中清除数据的磁盘文件。 文章来源:https://www.toymoban.com/news/detail-498023.html
7. Bloom 过滤器(Bloom filter):这不过是快速的、不确定的算法,用于测试一个元素是否是一个集合的成员。这是一种特殊的缓存。Bloom 过滤器在每个查询后被访问。文章来源地址https://www.toymoban.com/news/detail-498023.html
到了这里,关于大数据技术①|大数据第15章|HBase数据库与Cassandra数据库|18:00~18:15的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!