1.背景介绍
1. 背景介绍
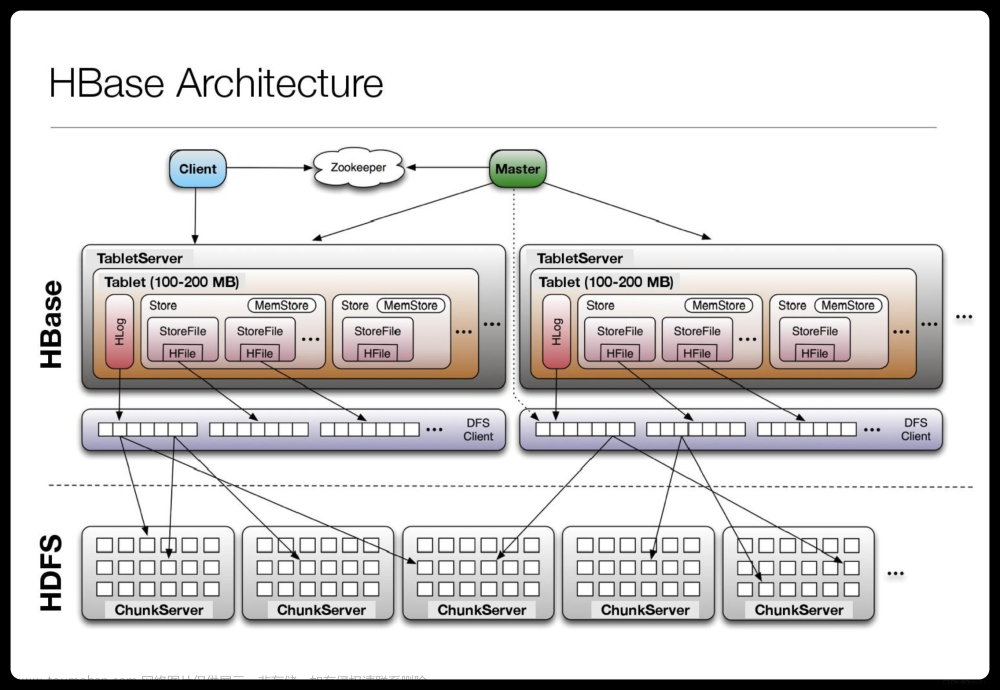
HBase是一个分布式、可扩展、高性能的列式存储系统,基于Google的Bigtable设计。它是Hadoop生态系统的一部分,可以与HDFS、MapReduce、ZooKeeper等组件集成。HBase具有高可用性、高可扩展性和高性能等优势,适用于大规模数据存储和实时数据处理。
在实际应用中,数据备份和恢复是数据安全和可靠性的重要保障措施。HBase提供了数据备份和恢复策略,以确保数据的安全性和可靠性。本文将详细介绍HBase的数据库备份与恢复策略,包括核心概念、算法原理、最佳实践、实际应用场景等。
2. 核心概念与联系
在HBase中,数据备份和恢复主要涉及以下几个核心概念:
HRegionServer:HBase中的RegionServer负责存储、管理和处理Region(区域)数据。Region是HBase中数据的基本单位,可以包含多个Row。RegionServer负责处理客户端的读写请求,并管理Region。
HRegion:RegionServer内部存储的数据单位,可以包含多个Row。Region内部数据是有序的,可以通过Row Key进行快速查找。
HTable:HBase中的表,包含多个Region。HTable是用户对数据的抽象,用户通过HTable进行数据的CRUD操作。
Snapshot:快照,是HBase中用于备份数据的一种方式。Snapshot是HBase中的一种静态数据快照,可以在不影响正常读写操作的情况下,保存数据的一致性状态。
RegionServer Failover:RegionServer故障转移,是HBase中的自动故障恢复机制。当RegionServer发生故障时,HBase会自动将故障的RegionServer的Region和数据迁移到其他RegionServer上,以确保数据的可用性和可靠性。
3. 核心算法原理和具体操作步骤及数学模型公式详细讲解
3.1 快照(Snapshot)备份
HBase支持快照备份,可以在不影响正常读写操作的情况下,保存数据的一致性状态。快照备份的原理是通过将当前时间戳作为Snapshot的唯一标识,将当前时刻的数据保存到Snapshot中。
快照备份的操作步骤如下:
客户端向HMaster发送快照备份请求,指定需要备份的HTable和Snapshot名称。
HMaster接收快照备份请求,并将请求转发给对应的RegionServer。
RegionServer将当前时刻的数据保存到指定的Snapshot中,并将Snapshot的元数据信息更新到HMaster。
快照备份完成后,客户端可以通过Snapshot名称访问备份数据。
快照备份的数学模型公式为:
$$ Snapshot = (Data, Timestamp) $$
3.2 数据恢复
HBase支持通过快照备份进行数据恢复。在数据恢复过程中,HBase会将指定的Snapshot作为恢复的数据源,将恢复的数据保存到指定的HTable中。
数据恢复的操作步骤如下:
客户端向HMaster发送数据恢复请求,指定需要恢复的HTable和Snapshot名称。
HMaster接收数据恢复请求,并将请求转发给对应的RegionServer。
RegionServer从指定的Snapshot中读取数据,并将数据保存到指定的HTable中。
数据恢复完成后,客户端可以通过HTable访问恢复的数据。
数据恢复的数学模型公式为:
$$ RecoveredData = HTable \cup Snapshot $$
3.3 RegionServer故障转移
HBase支持RegionServer故障转移,可以在RegionServer发生故障时,自动将故障的Region和数据迁移到其他RegionServer上,以确保数据的可用性和可靠性。
RegionServer故障转移的原理是通过HMaster监控RegionServer的状态,当HMaster发现RegionServer故障时,HMaster会将故障的Region和数据迁移到其他RegionServer上。
RegionServer故障转移的操作步骤如下:
HMaster监控RegionServer的状态,发现RegionServer故障。
HMaster将故障的Region和数据迁移到其他RegionServer上。
迁移完成后,HMaster更新RegionServer的元数据信息。
RegionServer故障转移的数学模型公式为:
$$ R{new} = R{old} \cup R_{failover} $$
4. 具体最佳实践:代码实例和详细解释说明
4.1 快照备份
以下是一个使用HBase快照备份的代码实例:
```java import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Snapshot; import org.apache.hadoop.hbase.util.Bytes;
import java.util.UUID;
public class SnapshotBackup { public static void main(String[] args) throws Exception { // 获取HBase配置 Configuration conf = HBaseConfiguration.create();
// 获取HTable实例
HTable table = new HTable(conf, "test");
// 创建快照
Snapshot snapshot = table.createSnapshot(UUID.randomUUID().toString());
// 关闭HTable实例
table.close();
// 输出快照名称
System.out.println("Snapshot name: " + snapshot.getNameAsString());
}} ```
4.2 数据恢复
以下是一个使用HBase数据恢复的代码实例:
```java import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Snapshot;
import java.util.UUID;
public class DataRecovery { public static void main(String[] args) throws Exception { // 获取HBase配置 Configuration conf = HBaseConfiguration.create();
// 获取HTable实例
HTable table = new HTable(conf, "test");
// 获取快照
Snapshot snapshot = table.getSnapshot(UUID.randomUUID().toString());
// 恢复数据
table.recover(snapshot, true);
// 关闭HTable实例
table.close();
// 输出恢复结果
System.out.println("Data recovery successful.");
}} ```
4.3 RegionServer故障转移
HBase的RegionServer故障转移是自动进行的,不需要手动操作。在RegionServer发生故障时,HMaster会自动将故障的Region和数据迁移到其他RegionServer上。
5. 实际应用场景
HBase的数据备份与恢复策略适用于以下实际应用场景:
- 数据安全:通过快照备份,可以确保数据的安全性和可靠性。
- 数据恢复:在数据丢失或损坏的情况下,可以通过快照备份进行数据恢复。
- 数据迁移:在数据库迁移或升级的过程中,可以通过快照备份和故障转移来确保数据的可用性和一致性。
6. 工具和资源推荐
- HBase官方文档:https://hbase.apache.org/book.html
- HBase Java API:https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/package-summary.html
- HBase快照管理:https://hbase.apache.org/book.html#quickstart.snapshot
7. 总结:未来发展趋势与挑战
HBase的数据备份与恢复策略已经在实际应用中得到了广泛的应用,但仍然存在一些挑战:文章来源:https://www.toymoban.com/news/detail-826555.html
- 快照备份和数据恢复的性能:随着数据量的增加,快照备份和数据恢复的性能可能会受到影响。未来可以通过优化算法和硬件来提高性能。
- 数据一致性:在数据备份和恢复过程中,保证数据的一致性是非常重要的。未来可以通过提高HBase的一致性算法和协议来提高数据一致性。
- 自动故障转移:HBase的RegionServer故障转移是自动进行的,但在实际应用中可能会遇到一些特殊情况,需要进一步优化和改进。
未来,HBase的数据备份与恢复策略将继续发展和完善,以应对新的技术挑战和实际应用需求。文章来源地址https://www.toymoban.com/news/detail-826555.html
到了这里,关于HBase的数据库备份与恢复策略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!