DefaultMQPushConsumerImpl拉取消息
首先,DefaultMQPushConsumerImpl 是一个实现了 RocketMQ 的消费者客户端接口的类。该类的主要作用是从 RocketMQ 的 Broker 获取消息并进行消费。
主要可以通过pullMessage方法进行获取对应的操作,如下图所示。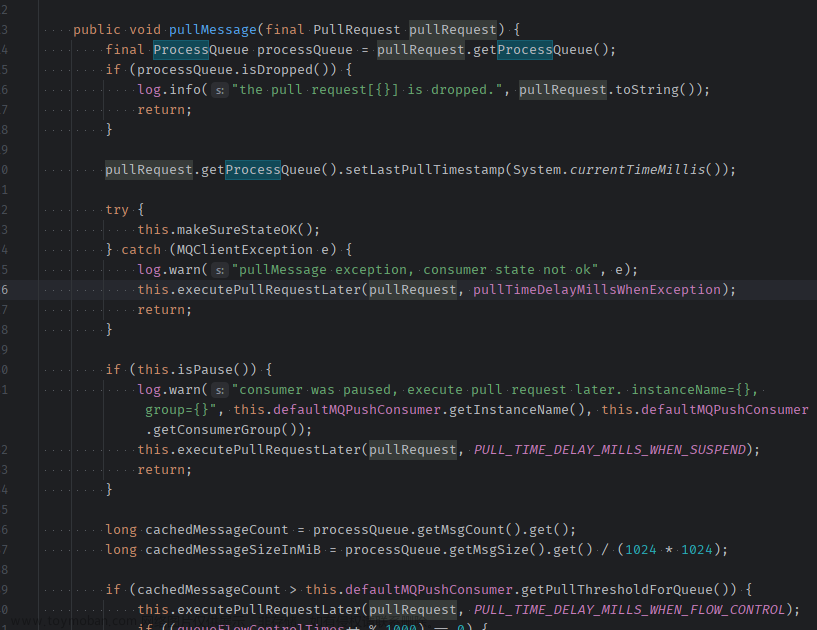
在消费消息时,DefaultMQPushConsumerImpl 会将获取到的消息放入一个processQueue中,processQueue包含了一个TreeMap数据结构,它按照消息的 commitLogOffset 顺序来排列。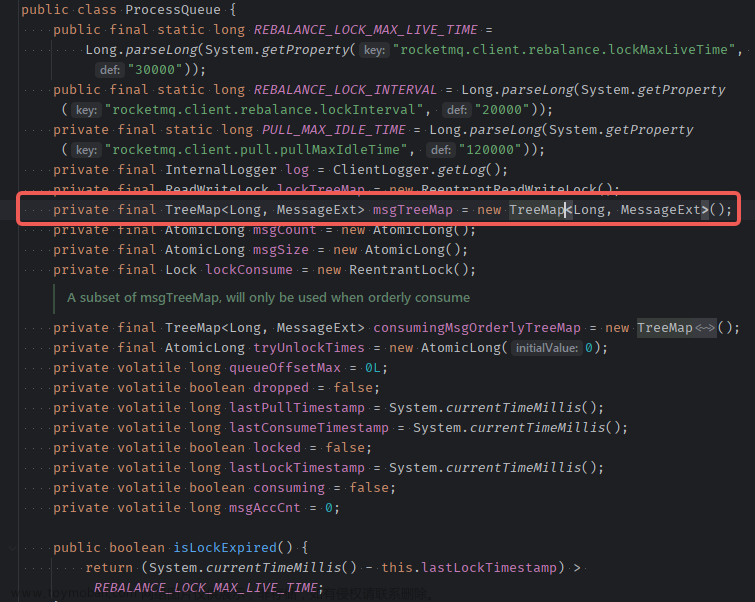
DefaultMQPushConsumerImpl 通过定时的方式,从 Broker 上拉取消息。具体来说,它会调用DefaultMQPushConsumerImpl 自身定义的PullMessageService类,该类会定时的从消息服务器中拉取消息。
源码如下所示。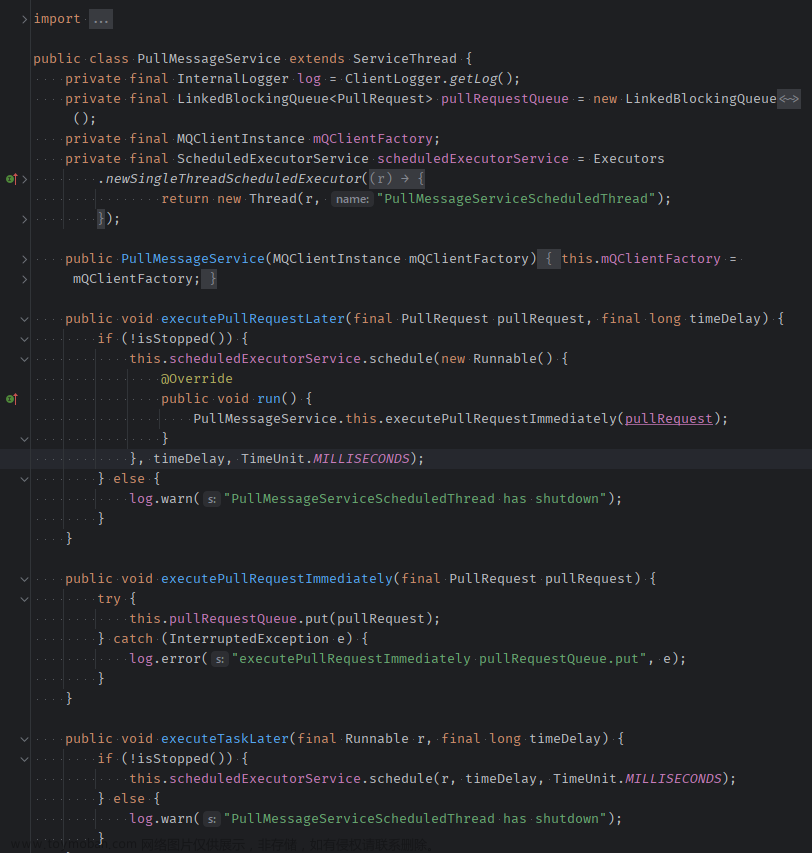
一旦消息拉取成功,PushConsumer 会将消息交给 processQueue 中的一个队列进行处理,这个队列对应同一个消息主题的同一个消息队列。
processQueue 中的每个消息都会根据消息的commitLogOffset排列位置。这个位置决定了消息被消费的顺序。也就是说,processQueue 存放的顺序决定了消息消费的顺序。
org.apache.rocketmq.client.impl.consumer.DefaultMQPushConsumerImpl#pullMessage
boolean dispatchToConsume = processQueue.putMessage(pullResult.getMsgFoundList());
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispatchToConsume);
consumeMessageService的并发消费和顺序消费
consumeMessageService 是一个用于消费消息的服务方法,它可以实现消息的并发消费和顺序消费。当使用 consumeMessageService 时,需要考虑业务的实际需求以及消息处理的性质,权衡使用并发消费和顺序消费。
并发消费
并发消费是指多个消费者同时消费同一批消息以提高处理速度,需要注意消息幂等性以避免重复消费。
DefaultMQPushConsumer的consumeMessageBatchMaxSize参数默认值为1,表示默认批量消费的消息数量是1个。在并发消费方式下,若一个队列中拉取到32条消息,则会创建32个ConsumeRequest对象,每个ConsumeRequest对象对应1条消息,提交到线程池中运行。
顺序消费
顺序消费则是按照消息产生的顺序逐个消费,适合处理需要顺序进行的业务逻辑,如订单处理,但实现可能带来性能瓶颈,需谨慎设计。指同一时刻,一个 queue 只有一个线程在消费。只让一个线程消费,由加锁来实现,而顺序则由 TreeMap 来实现。
一个队列中拉取到32条消息,则只会创建一个ConsumeRequest对象,该对象会被提交到线程池中,在ConsumeRequest.run方法中会按照消息的offset顺序一条一条地消费,直到TreeMap为空。
concurrently 创建 ConsumeRequest
public void submitConsumeRequest(
final List<MessageExt> msgs,
final ProcessQueue processQueue,
final MessageQueue messageQueue,
final boolean dispatchToConsume) {
final int consumeBatchSize = this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
if (msgs.size() <= consumeBatchSize) {
ConsumeRequest consumeRequest = new ConsumeRequest(msgs, processQueue, messageQueue);
try {
this.consumeExecutor.submit(consumeRequest);
} catch (RejectedExecutionException e) {
this.submitConsumeRequestLater(consumeRequest);
}
} else {
for (int total = 0; total < msgs.size(); ) {
List<MessageExt> msgThis = new ArrayList<MessageExt>(consumeBatchSize);
for (int i = 0; i < consumeBatchSize; i++, total++) {
if (total < msgs.size()) {
msgThis.add(msgs.get(total));
} else {
break;
}
}
ConsumeRequest consumeRequest = new ConsumeRequest(msgThis, processQueue, messageQueue);
try {
this.consumeExecutor.submit(consumeRequest);
} catch (RejectedExecutionException e) {
for (; total < msgs.size(); total++) {
msgThis.add(msgs.get(total));
}
this.submitConsumeRequestLater(consumeRequest);
}
}
}
}
消费者在消费消息时,根据批量消费的大小来决定是将任务提交到线程池中一次性消费,还是将任务分成多次提交到线程池中进行消费。
首先判断msgs中消息的数量是否小于等于一个批量消费数量consumeBatchSize,如果小于等于,那么将所有消息封装成一个ConsumeRequest对象并提交到consumeExecutor线程池中,其中dispatchToConsume表示是否立即分发给消费者消费。
如果消息数量大于批量消费数量,那么将消息分段提交到线程池中进行消费。首先通过两层循环,将msgs中的消息按照consumeBatchSize分成若干个小的MessageExt列表,每个小的MessageExt列表封装成一个ConsumeRequest对象并提交到consumeExecutor线程池中。
如果线程池提交任务出现拒绝执行异常,说明该线程池已经满了,这时候需要将当前小的MessageExt列表继续循环并依次每次取出一个消息封装成ConsumeRequest对象进行提交,直到所有的小的MessageExt列表被完整地提交到线程池中。若还有未提交的列表,则将该ConsumeRequest对象提交到一个新的线程池中进行定时的重复提交。
concurrently ConsumeRequest#run 消费主体逻辑
消息消费者消费消息的地方,listener.consumeMessage方法会被消费者调用,将消息列表和消息处理上下文传入。
status = listener.consumeMessage(Collections.unmodifiableList(msgs), context);
-
msgs是需要消费的消息列表,这里使用了Collections.unmodifiableList方法来创建一个不可修改的消息列表,这是为了保证消息的安全性,防止消息在消费过程中被意外或恶意修改。
-
context是消息处理的上下文,可能包含消费者的订阅信息、消费进度等信息,可根据业务需要进行扩展和使用。
-
consumeMessage方法返回消费结果,通常是一个枚举类型,表示消费结果的状态,如消费成功、消费失败等。消费结果会影响消息处理的下一步流程。
消费结束之后清除数据
主要用于移除已经消费完成的消息。直接从 msgTreeMap 中删除消息,并返回 msgTreeMap 中第一条消息的 queue offset 值。
org.apache.rocketmq.client.impl.consumer.ProcessQueue#removeMessage
public long removeMessage(final List<MessageExt> msgs) {
long result = -1;
final long now = System.currentTimeMillis();
try {
this.lockTreeMap.writeLock().lockInterruptibly();
this.lastConsumeTimestamp = now;
try {
if (!msgTreeMap.isEmpty()) {
result = this.queueOffsetMax + 1;
int removedCnt = 0;
for (MessageExt msg : msgs) {
MessageExt prev = msgTreeMap.remove(msg.getQueueOffset());
if (prev != null) {
removedCnt--;
msgSize.addAndGet(0 - msg.getBody().length);
}
}
msgCount.addAndGet(removedCnt);
if (!msgTreeMap.isEmpty()) {
result = msgTreeMap.firstKey();
}
}
} finally {
this.lockTreeMap.writeLock().unlock();
}
} catch (Throwable t) {
log.error("removeMessage exception", t);
}
return result;
}
具体来说,它接收一个 MessageExt 类型的消息列表msgs,通过遍历msgs,查找msgTreeMap中相应的消息,将找到的消息删除并计数,更新msgCount和msgSize这两个计数器。代码中也使用了重入锁lockTreeMap来保证线程安全。函数将返回result,表示下一步应该消费的消息的offset,如果没有可消费的消息,则返回-1。
orderly 创建 ConsumeRequest
在消息消费过程中,判断是否需要立即将消息分发给消费者进行消费。
public void submitConsumeRequest(
final List<MessageExt> msgs,
final ProcessQueue processQueue,
final MessageQueue messageQueue,
final boolean dispathToConsume) {
if (dispathToConsume) {
ConsumeRequest consumeRequest = new ConsumeRequest(processQueue, messageQueue);
this.consumeExecutor.submit(consumeRequest);
}
}
首先判断参数dispathToConsume为true,如果为true,表示需要立即分发给消费者消费;否则就不需要进行分发,因为可能等待其他条件触发再进行消费。
如果需要立即分发,那么将该消息的消息队列和消息处理队列封装成ConsumeRequest对象,并将该对象提交到consumeExecutor线程池中进行执行。每个消费者线程从consumeExecutor线程池中取出ConsumeRequest对象并进行消费。
orderly ConsumeRequest#run 消费主体逻辑
先简单介绍一下 RocketMQ 消息消费的流程:消费者将消息从 Broker 中拉取到本地的 ProcessQueue 中,然后在 ProcessQueue 中进行消息消费。
// 获取锁
final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
synchronized (objLock) {
for (boolean continueConsume = true; continueConsume; ) {
// 从 TreeMap 中获得消息
List<MessageExt> msgs = this.processQueue.takeMessags(consumeBatchSize);
if (!msgs.isEmpty()) {
status = messageListener.consumeMessage(Collections.unmodifiableList(msgs), context);
} else {
continueConsume = false;
}
}
...
}
public class MessageQueueLock {
private ConcurrentMap<MessageQueue, Object> mqLockTable = new ConcurrentHashMap<MessageQueue, Object>();
public Object fetchLockObject(final MessageQueue mq) {
Object objLock = this.mqLockTable.get(mq);
if (null == objLock) {
objLock = new Object();
Object prevLock = this.mqLockTable.putIfAbsent(mq, objLock);
if (prevLock != null) {
objLock = prevLock;
}
}
return objLock;
}
}
首先实例化了 MessageQueueLock,用于保证多线程环境下的线程同步和互斥。在代码的第一行中,获取到了当前 MessageQueue 的锁对象 objLock。这个锁对象是在 mqLockTable 中获取的,mqLockTable 存储了每个 MessageQueue 的锁对象,用于对不同的 MessageQueue 进行互斥控制。
在代码的后面,使用 synchronized 对 objLock 进行加锁,并进入到了循环中。在循环中,调用 processQueue.takeMessags() 方法从 ProcessQueue 中获取消息,返回的是一个消息列表。如果消息列表不为空,则调用 messageListener.consumeMessage() 方法来进行消息消费。
如果消息列表为空,说明当前的 ProcessQueue 中没有更多的消息,结束当前的循环,并退出 synchronized 块,释放了 objLock 的锁,等待下一次的消费请求。
整个逻辑是通过锁机制来实现对 ProcessQueue 进行互斥控制的,保证了多个消费者之间的消费的安全性。同时,使用了循环来进行多次消费。
顺序处理机制
take消息时,将消息从 msgTreeMap 取出,并放入 consumingMsgOrderlyTreeMap。消费完成后,清空 consumingMsgOrderlyTreeMap。将 offset 设为 this.consumingMsgOrderlyTreeMap.lastKey() + 1,表示已经消费的消息的下一条消息的 offset。
// org.apache.rocketmq.client.impl.consumer.ProcessQueue#commit
public long commit() {
try {
this.lockTreeMap.writeLock().lockInterruptibly();
try {
Long offset = this.consumingMsgOrderlyTreeMap.lastKey();
msgCount.addAndGet(0 - this.consumingMsgOrderlyTreeMap.size());
for (MessageExt msg : this.consumingMsgOrderlyTreeMap.values()) {
msgSize.addAndGet(0 - msg.getBody().length);
}
this.consumingMsgOrderlyTreeMap.clear();
if (offset != null) {
return offset + 1;
}
} finally {
this.lockTreeMap.writeLock().unlock();
}
} catch (InterruptedException e) {
log.error("commit exception", e);
}
return -1;
}
关于 offset 提交
offset 是消费者从 broker 拉取的下一条消息的偏移量
消息消费的失败
-
顺序消费:如果处理某条消息失败且重试次数小于阈值,从 consumingMsgOrderlyTreeMap 中取出这条消息并重新放入 msgTreeMap;如果重试次数超过阈值,则将消息发送回 broker 并根据重试次数决定发送消息到 SCHDULE_TOPIC_XXXX 或死信队列
-
并发消费:如果处理消息时失败,则将消息发送回 broker。如果发送失败,将会继续消费消息,直到成功消费并提交给 broker。文章来源:https://www.toymoban.com/news/detail-501411.html
发送 ConsumeRequest 的时机有两个,一是在拉取到消息后,二是在出现异常后延迟提交。文章来源地址https://www.toymoban.com/news/detail-501411.html
到了这里,关于【深入浅出RocketMQ原理及实战】「底层原理挖掘系列」透彻剖析贯穿RocketMQ的消息顺序消费和并发消费机制体系的原理分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!