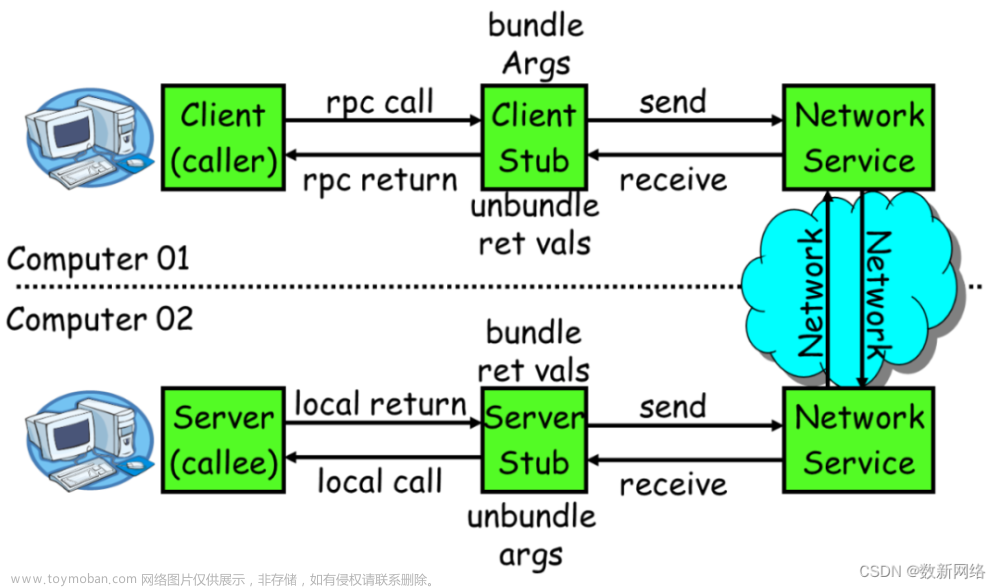
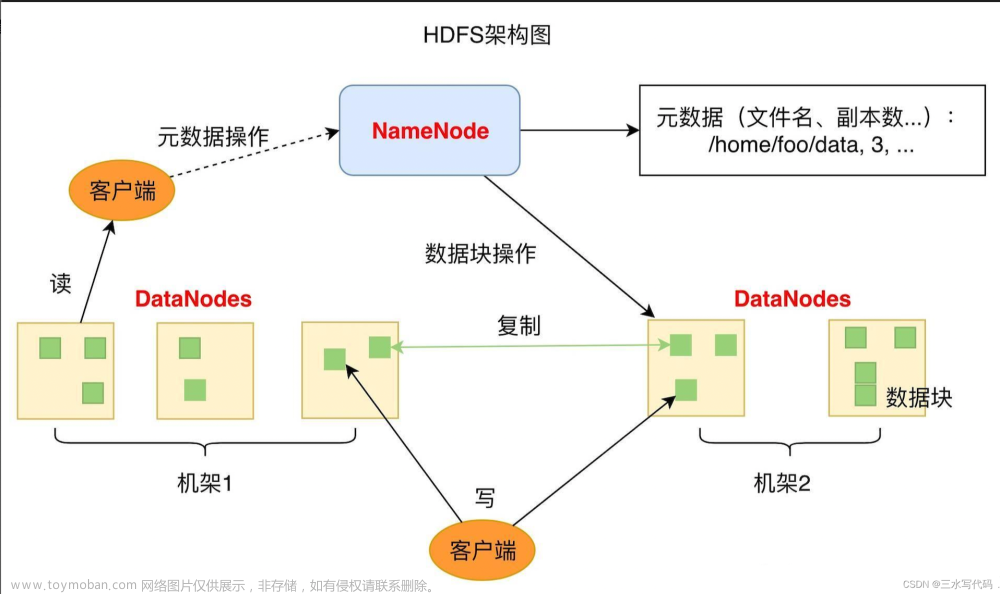
1、rpc是什么?
RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
我们使用浏览器访问某个网页是通过Http协议。
2、hdfs中哪些组件会产生rpc问题?
这里说的rpc问题是说rpc调用频繁,导致负载过高,性能降低。
NameNode
NameNode是HDFS的主节点,负责管理文件系统的命名空间和元数据,并进行客户端的元数据操作。
RPC问题可能在与NameNode的通信中出现,例如获取文件信息、创建目录等操作。
DataNode
DataNode是HDFS的从节点,负责存储实际的数据块,并处理客户端的读写请求。
RPC问题可能在与DataNode的通信中出现,例如读取数据块、写入数据块等操作。
Secondary NameNode
Secondary NameNode负责定期合并NameNode的编辑日志,以便恢复NameNode故障后的状态。
RPC问题可能在与Secondary NameNode的通信中出现,例如定期的编辑日志合并操作。
3、如何监控hdfs中的rpc问题
为了观察和监控HDFS中的RPC问题,可以采取以下方法:
-
日志分析:通过查看HDFS相关组件的日志,可以了解到RPC请求的详细信息,如请求的类型、处理时间、返回结果等。可以通过分析日志来判断是否存在RPC问题,以及确定具体发生在哪个组件上。
-
监控工具:Hadoop提供了一些监控工具,如Hadoop Metrics2和HDFS Web UI,可以用于实时监控HDFS集群的各项指标,包括RPC请求的响应时间、吞吐量等。这些指标可以帮助我们识别性能瓶颈和潜在的RPC问题。
-
分布式跟踪系统:使用分布式跟踪系统(如Apache HTrace或Zipkin),可以对HDFS中的RPC调用链进行跟踪和分析。这样可以更好地了解每个RPC请求的路径、延迟和相互之间的关系,有助于发现潜在的问题。
-
性能测试工具:使用性能测试工具(如Apache JMeter)可以模拟大量的并发RPC请求,并监测各项指标。通过这种方式,可以评估HDFS在高负载下的性能表现,并发现任何潜在的RPC问题。
4、优化hdfs中的rpc问题?
-
提高网络性能:优化网络配置,如减少网络拓扑层级、增加带宽、降低网络延迟等,以提高RPC请求的传输速度。
-
增加服务器资源:为HDFS集群增加更多的服务器资源,包括计算资源、存储资源和网络带宽,以提高RPC请求的处理能力。
-
合并小文件:将大量小文件合并为较大的文件,这样可以减少RPC请求的数量,从而降低整体系统开销。可以使用HDFS的工具或编程接口进行文件合并操作。
-
批量操作:在进行文件读写操作时,尽量采用批量操作,减少RPC请求的次数。例如,可以使用HDFS的API一次读取/写入多个文件,而不是多次单独操作每个文件。
-
使用数据本地性:优化数据在HDFS集群中的存放位置,使得数据尽可能靠近需要进行计算的节点。这样可以降低网络传输开销和RPC请求的延迟时间。
-
缓存机制:对于频繁访问的数据,可以引入缓存机制,将数据缓存在内存中,减少RPC请求的频率,提高数据访问速度。
-
在设计应用程序时考虑RPC开销:合理设计应用程序架构,减少RPC请求的频率和开销,尽量减少不必要的数据传输。
5、hdfs中rpc产生的几个原因
-
网络延迟:在分布式环境中,RPC需要通过网络进行通信,网络延迟可能导致RPC请求的响应时间增加。
-
服务器负载:当HDFS集群中的某些服务器过载或资源不足时,可能会导致RPC请求的处理速度降低,从而影响整体性能。文章来源:https://www.toymoban.com/news/detail-536118.html
-
大量小文件:如果HDFS上存在大量小文件,每个小文件都需要进行RPC请求,这将增加RPC请求的数量,从而增加了系统开销。文章来源地址https://www.toymoban.com/news/detail-536118.html
到了这里,关于聊聊hdfs中的rpc问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!