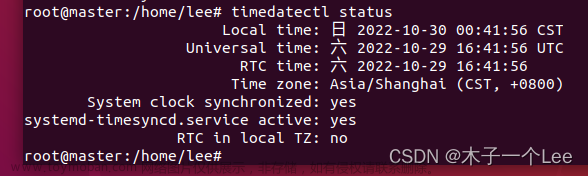
解压文件
启动zookeeper
配置kafka环境变量
查看Kafka的版本内容
分发Kafka文件到slave1、slave2
修改server.properties文件
在Master、slave1和slave2节点上分别启动Kafka
在Master节点上执行如下命令来创建Topic并查看
解压文件
tar -zxvf kafka_2.12-2.4.1.tgz -C /opt/modulemv kafka_2.12-2.4.1 kafka启动zookeeper
提前安装好在每个节点启动
zkServer.sh start配置kafka环境变量
vim /etc/profileexport KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
查看Kafka的版本内容
kafka-server-start.sh --version
分发Kafka文件到slave1、slave2
分发kafka
scp -r /opt/module/kafka slave1:/opt/modulescp -r /opt/module/kafka slave2:/opt/module修改server.properties文件
修改kafka/config/server.properties
每个节点下的id都是唯一的id为0、1、2三台分别设置文章来源:https://www.toymoban.com/news/detail-536879.html
//master
broker.id=0
listeners=PLAINTEXT://master:9092
//slave1
broker.id=1
listeners=PLAINTEXT://slave1:9092
//slave2
broker.id=2
listeners=PLAINTEXT://slave2:9092在Master、slave1和slave2节点上分别启动Kafka
kafka-server-start.sh -daemon /opt/kafka/config/server.properties
在Master节点上执行如下命令来创建Topic并查看
kafka-topics.sh --create --zookeeper master:2181 --replication-factor 2 --partitions 2 --topic installtopickafka-topics.sh --list --bootstrap-server master:9092 文章来源地址https://www.toymoban.com/news/detail-536879.html
文章来源地址https://www.toymoban.com/news/detail-536879.html
到了这里,关于Kafka搭建部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!