说明1:使用Flex和Bison工具实现SQL解析器,完整代码见:
SQL解析器完整实例https://mp.csdn.net/mp_blog/creation/editor/132514880
说明2:该笔记是在学习编译原理相关视频时整理,视频链接如下:
编译原理学习视频https://www.bilibili.com/video/BV17W41187gL/?spm_id_from=333.337.search-card.all.click
说明3:编译原理学习视频课件链接如下:
编译原理学习视频课件https://download.csdn.net/download/weixin_47156401/88281380
特别说明:如需word版笔记请在评论区留言!!!
如需word版笔记请在评论区留言!!!
如需word版笔记请在评论区留言!!!
SQL 语句解析过程详解:
1.输入SQL语句
2.词法分析------Flex
使用词法分析器(由Flex生成)将SQL语句分解为一个个单词(字符流到记号流的转换),这些单词被称为“记号”。标记包括关键字、标识符、运算符、分隔符等。

2.1 词法分析器介绍
2.2.1 词法分析器任务
(1)分割SQL语句:将输入的SQL语句分割成多个独立的词法单元。常见的词法单元包括关键字(SELECT、FROM、WHERE等)、标识符(表名、列名等)、运算符(=、<、>等)、分隔符(逗号、分号等)和常量(字符串、数字等)。
(2)去除空白字符:将SQL语句中的空格、制表符和换行符等空白字符去除,因为它们对于词法分析没有实际意义。
(3)标识符处理:对于标识符(如表名、列名等),词法分析器需要识别它们,并将其作为单独的词法单元返回。标识符通常需要遵循一定的命名规则,如不能以数字开头,不能包含特殊字符等。
(4)常量处理:对于常量(如字符串、数字等),词法分析器需要将它们识别并返回为单独的词法单元。常量可能需要进行类型检查和转换。
(5)错误处理:词法分析器还需要检测和处理输入SQL语句中的错误,如拼写错误、不支持的字符等。在遇到无法识别的字符或语法错误时,词法分析器应该能够报告错误并提供相应的错误信息。
2.2.2 词法分析器实现方法
1、手动实现
(1)实现难度高且易于出错:手动实现词法分析器需要编写大量的代码来处理不同的词法规则和语法规则,对编译原理和语法分析有较深的理解要求。
(2)灵活性高:手动实现的词法分析器可以根据具体的需求进行定制和调整,可以处理一些特定的语法规则或语言特性。
(3)可读性好:手动实现的词法分析器可以根据开发者的编码风格和习惯编写,代码结构清晰,易于理解和维护。
手动实现比较流行的方法有GCC、LLVM等;
2、自动实现
(1)实现简单:自动实现的词法分析器通常使用工具或库来生成,开发者只需定义词法规则和语法规则,工具会自动生成相应的词法分析器代码。
(2)效率高:自动实现的词法分析器通常使用高效的算法和数据结构,能够快速准确地进行词法分析。
(3)一致性好:自动实现的词法分析器生成的代码具有一致性,不受个人编码风格的影响,易于团队协作和维护。
自动实现比较流行方法有Lex、Flex、JFlex、ANTLR等;
2.2 正则表达式(RE)
(1). 匹配除换行符”\n”以外的任何单个字符;
(2)* 匹配前面表达式的零个或多个拷贝;
(3)[] 匹配括号中任意字符的字符类,如果第一个字符是 “^”,则匹配除括号中的字符以外的任意字符;“-” 指示一个字符范围,例如“[0-9]”和“[0123456789]”含义相同;除了以 “\” 开始的转义序列,元字符在括号内没有任何含义;
(4)^ 作为正则表达式的行首匹配行的开头,也用于方括号中的否定;
(5)$ 作为正则表达式的行尾匹配行的结尾;
(6)\ 用于转义元字符,也作为常用的C转义序列的一部分,例如”\n”表示换行,“\*” 表示非元字符的星号;
(7)+ 匹配前面的正则表达式一次或多次出现;
(8)? 匹配前面的正则表达式零次或一次出现;
(9)| 匹配前面的正则表达式或随后的正则表达式;
(10)“…” 引号中的每个字符解释为字面意义,除C转义序列外元字符会失去其特殊含义;
(11)() 将一系列正则表达式组成一个新的正则表达式,例如(01),表示字符序列 01;
(12){} 当括号中包含一个或两个数字时,指示前面的模式允许被匹配多少次,例如{1,3}表示匹配字母一次到三次;
2.3 有限状态自动机
有限状态自动机(Finite State Automaton,FSA)是一种用于描述计算模型的数学模型。它是由有限个状态以及在这些状态之间转移的规则组成的。
有限状态自动机包含以下几个要素:
(1)状态(States):有限状态自动机的行为取决于其所处的状态。在有限状态自动机中,状态可以是起始状态、接受状态或中间状态。
(2)转移(Transitions):有限状态自动机根据输入符号从一个状态转移到另一个状态。转移可以是确定性的,即给定一个输入符号,只能有一种转移路径;也可以是非确定性的,即给定一个输入符号,可能有多种转移路径。转移可以用箭头表示,箭头上标注了触发转移的输入符号。
(3)输入符号(Input Symbols):有限状态自动机接受来自输入源的输入符号。输入符号可以是字符、字节、标记或任何其他形式的输入。
(4)接受状态(Accepting States):有限状态自动机可以定义一个或多个接受状态。当有限状态自动机在某个接受状态上结束时,它表示已接受一串输入符号序列。
有限状态自动机可以分为两种主要类型:
(1)有限确定性自动机(Deterministic Finite Automaton,DFA):对于给定的输入符号和当前状态,DFA只有一种转移路径。每个输入符号只能触发一次转移。词法分析器就是典型的DFA。
(2)有限非确定性自动机(Non-deterministic Finite Automaton,NFA):对于给定的输入符号和当前状态,NFA可以有多种转移路径。每个输入符号可以触发多次转移,或者可以选择不进行转移。
词法分析器通常使用确定性有限状态自动机(DFA)而不是非确定性有限状态自动机(NFA)的主要原因有以下几点:
(1)效率:DFA在处理输入时具有更高的效率。由于DFA的转移是确定性的,每个输入符号只能触发一次转移,这使得它的状态转移表可以被预先计算并存储。相比之下,NFA的转移是非确定性的,每个输入符号可以触发多次转移,这导致在运行时需要进行更多的状态转移计算,使得NFA的处理速度相对较慢。
(2)简洁性:DFA的状态转移表相对较小且易于理解。每个状态只需记录与输入符号相关的单个转移目标,这使得DFA的状态转移图更加简洁和直观。相比之下,NFA的转移目标可以是多个状态,需要使用ε转移(空转移)来表示非确定性的转移,这增加了状态转移图的复杂性。
(3)可预测性:DFA的行为是可预测的。给定一个输入符号和当前状态,DFA始终只有一条确定的转移路径。这种确定性的行为使得DFA更易于分析和调试。相比之下,NFA的行为是非确定的,对于同一输入符号和当前状态,可能有多条转移路径可供选择,这增加了分析和调试的复杂性。
2.4 词法分析器自动生成
词法分析器自动生成,即由正则表达式到词法分析器代码,流程如下:
 2.4.1 Thompson算法
2.4.1 Thompson算法
Thompson算法是一种用于将正则表达式转换为等价的非确定有限状态自动机(NFA)的算法,它由Ken Thompson在1968年提出。NFA是一种用于匹配字符串模式的计算模型。
下面是Thompson算法的基本步骤:
1、定义NFA的基本构建块:
(1)空状态(ε):表示一个空转移。
(2)字符状态:表示匹配一个特定的字符。
2、对于给定的正则表达式,递归地应用以下规则构建NFA:
(1)对于空正则表达式,创建两个空状态,并通过ε边将它们连接起来。

(2)对于单个字符的正则表达式,创建两个状态,并使用字符状态将它们连接起来。

(3)对于连接操作(例如:AB),递归地构建A和B的NFA,并将A的接受状态与B的起始状态通过ε边连接起来。

(4)对于选择操作(例如,A|B),递归地构建A和B的NFA,并创建两个新状态作为起始状态和接受状态。然后,使用ε边将新起始状态与A和B的起始状态连接,并使用ε边将A和B的接受状态与新接受状态连接。

(5)对于闭包操作(例如,A*),递归地构建A的NFA,并创建两个新状态作为起始状态和接受状态。然后,使用ε边将新起始状态与A的起始状态和新接受状态连接,并使用ε边将A的接受状态与A的起始状态和新接受状态连接。

3、构建完成后,标记接受状态。
4、最终得到的NFA可以用于执行模式匹配操作。可以使用NFA进行字符串匹配,从起始状态开始,根据输入字符和边的转移条件,沿着边移动到下一个状态。重复此过程,直到达到接受状态或无法继续移动。如果最终达到接受状态,则表示输入字符串与正则表达式匹配。
Thompson算法是正则表达式引擎的基础之一,它提供了一种有效的方法来将正则表达式转换为可执行的自动机。这种转换使得正则表达式的匹配过程可以高效地执行,并在实际应用中得到广泛应用,例如文本搜索、编译器设计和网络安全等领域。
示例:

2.4.2 子集构造算法
子集构造算法(Subset Construction Algorithm)是一种用于将非确定有限状态自动机(NFA)转换为等价的确定有限状态自动机(DFA)的算法。DFA是一种更简单且易于处理的自动机模型,用于匹配字符串模式。
下面是子集构造算法的基本步骤:
1、给定一个NFA,其中包含一组状态和转移函数。
2、创建一个空的DFA,并将NFA的起始状态作为DFA的起始状态。
3、为DFA的每个状态执行以下步骤:
(1)对于给定的输入字符,计算该字符在NFA的当前状态下的ε闭包。ε闭包是从当前状态出发,通过任意数量的ε转移可达的所有状态的集合。
(2)对于NFA中的每个状态,计算它们在给定输入字符下的转移结果。转移结果是通过在输入字符上进行转移得到的状态的集合,包括通过ε转移到达的状态。
(3)将转移结果作为DFA中当前状态的转移函数。
(4)重复步骤3,直到为DFA的每个状态都计算了转移函数。
(5)标记DFA中的接受状态。如果DFA的状态集合中包含NFA的接受状态,则将该状态标记为接受状态。
(6)最终得到的DFA可以用于执行模式匹配操作。可以使用DFA进行字符串匹配,从起始状态开始,根据输入字符和转移函数,沿着转移路径移动到下一个状态。重复此过程,直到达到接受状态或无法继续移动。如果最终达到接受状态,则表示输入字符串与正则表达式匹配。
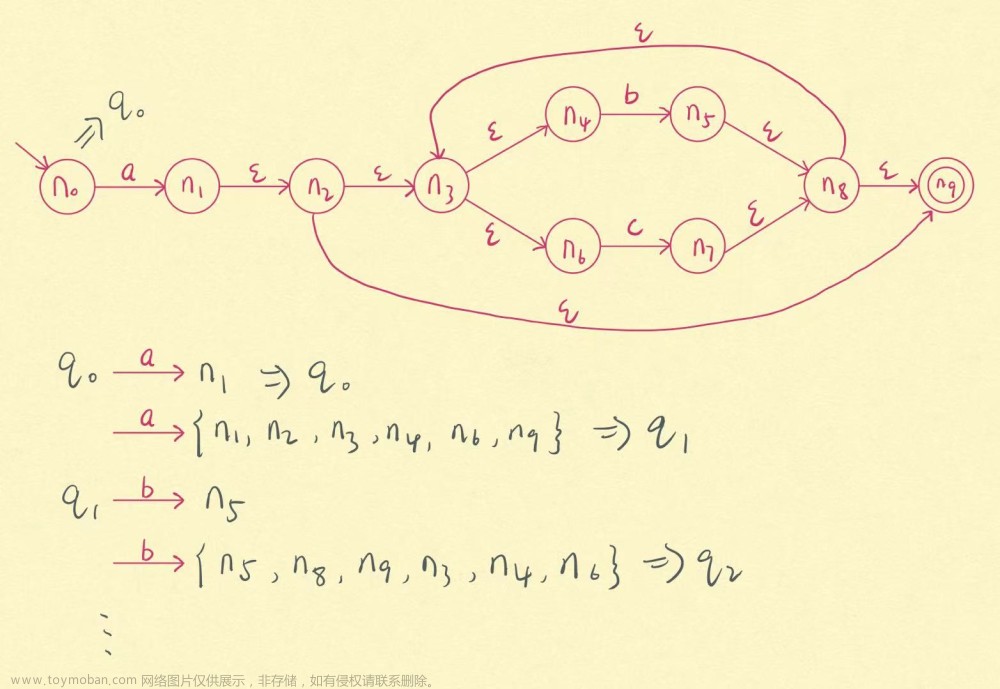
子集构造算法通过将NFA转换为DFA,消除了NFA中的非确定性,使得匹配过程更加明确和高效。DFA的状态数量通常比NFA少,因此在实际应用中,使用DFA进行模式匹配可以提高匹配性能。子集构造算法在编译器设计、正则表达式引擎和网络安全等领域中得到广泛应用。
示例一:
ε—闭包的计算:深度优先
/* ε-closure: 基于深度优先遍历的算法 */
set closure = {};
void eps_closure (x)
closure += {x}
foreach(y: x--ε--> y)
if(!visited (y))
eps_closure (y)
ε—闭包的计算:广度优先
/* ε-closure: 基于深度优先遍历的算法 */
set closure = {};
Q = []; //queue
void eps_closure (x)
Q = [x];
while (Q not empty)
q <- deQueue (Q)
closure += q
foreach (y: q--ε--> y)
if (!visited (y))
enQueue (Q, y)示例二:

#-------子集构造算法思想------#
q0 <- eps_closure ( n0 )
Q <- { q0 }
worklist <- q0
while ( worklist != [] )
remove q from worklist
foreach ( character c )
t <- eps_closure ( delta (q, c) ) #delta(q, c)即是在 q 状态基础上输入 c 得到的下一个状态
DFA[ q, c ] <- t
if ( t \ not \ in Q )
add t to Q and worklist
2.4.3 Hopcroft最小化算法
Hopcroft最小化算法(Hopcroft's Algorithm)是一种用于将确定有限状态自动机(DFA)转换为等价的最小化DFA的算法(即去掉非必要或者合并一些状态)。最小化DFA是指具有最少状态数量的等价DFA,它可以提高自动机的效率和性能。
Hopcroft最小化算法的基本思想是通过将状态划分为等价类来减少状态的数量。算法的步骤如下:
(1)初始化状态划分:将DFA的所有非接受状态和接受状态划分为两个初始等价类。
(2)构建等价类划分表:对于每个输入符号,根据当前状态的划分,计算状态转移后的等价类划分。如果两个状态在同一等价类中,并且它们在给定输入符号下转移到的状态属于不同的等价类,则将这两个状态划分到不同的等价类中。
(3)更新等价类划分:重复步骤2,直到等价类划分不再发生变化。也就是说,直到在每个输入符号下的状态转移都不会导致状态从一个等价类划分到另一个等价类。
(4)最终的等价类划分就是最小化DFA的状态划分。每个等价类代表一个合并后的状态。
(5)构建最小化DFA:使用最终的等价类划分来构建最小化DFA。将每个等价类作为最小化DFA的一个状态,并根据等价类划分表中的转移信息构建转移函数。
通过Hopcroft最小化算法,可以将原始的DFA转换为具有最少状态数量的等价DFA。最小化DFA通常比原始DFA更紧凑,可以提高自动机的匹配性能和效率。该算法在编译器设计、正则表达式引擎和模式匹配等领域中得到广泛应用。
#------Hopcroft最小化算法思想(基于等价类)------#
split(S)
foreach(character c)
if(c can split S)
split S into T1,T2,…,Tk
hopcroft()
split all nodes into N,A
while(set is still changes)
split(S)
示例一:

示例二:a(b|c)*

示例三:

2.4.4 从DFA生成词法分析器代码
从概念上讲,DFA就是一个有向图,使用不同的代码表示来表示DFA(即最终的词法分析器代码),常用代码表示方法有:转移表、哈希表、跳转表等(根据实际需求合理选择)。

1、转移表
转移表是一个二维表格,其中的行表示状态,列表示输入字符。每个单元格中的值表示从当前状态经过对应输入字符的转移后的下一个状态。通过查询转移表,可以根据当前状态和输入字符快速确定下一个状态。
(1)根据DFA状态转移表编写对应代码
FDA如下所示:

转移表如下所示:
| 状态\字符 |
a |
b |
c |
| 0 |
1 |
||
| 1 |
1 |
1 |
转移表代码如下所示:
char table[M][N];
table[0][‘a’]=1;
table[1][‘b’]=1;
table[1][‘c’]=1;
#other table entries are ERROR(2)驱动代码
#在匹配字符串时,遵从最长匹配原则
#-----------------------------------
即输入两个字符串:if、ifabc;
在匹配过程中先匹配 ifabc
如果 ifabc 匹配不上,则回退匹配 if
#-----------------------------------
nextToken()
state = 0
stack = []
while(state != ERROR)
c = getChar()
if(state is ACCEPT)
clear(stack)
push(state)
state = table[state][c]
while(state is not ACCEPT)
state = pop();
rollback();
2、跳转表
nextToken()
state = 0
stack = []
goto q0
q0:
c = getChar()
if(state is ACCEPT)
clear(state)
push(state)
if(c == ‘a’)
goto q1
q1:
c = getChar()
if(state is ACCEPT)
clear(state)
push(state)
if(c == ‘b’ || c == ‘c’)
goto q1
跳转表不需要维护二维数组(类似转移表中的二维数组),通常情况下跳转表的效率比转移表效率高,如:flex中使用的就是跳转表。
3.语法分析------Bison
使用语法分析器(由Bison生成)根据语法规则进行语法分析,生成抽象语法树。语法树是一种树形结构,它表示SQL语句的语法结构。语法分析器会检查语法树是否符合SQL语法规则,如果不符合,则会抛出语法错误。

3.1语法分析器介绍
3.1.1语法分析器任务
语法分析器(Parser)的任务是将词法分析器生成的词法单元序列(tokens)转换为语法树(Syntax Tree)或抽象语法树(Abstract Syntax Tree),以便进一步进行语义分析和代码生成。
语法分析器的主要任务包括以下几个方面:
1、语法规则定义:定义SQL语句的语法规则,包括SELECT语句、FROM子句、WHERE子句、JOIN子句等。语法规则可以使用上下文无关文法(Context-Free Grammar)或其扩展形式(如EBNF)来描述。
2、语法分析算法选择:选择适合SQL语句的语法分析算法。常见的语法分析算法包括递归下降分析、LL(k)分析、LR(k)分析等。根据SQL语句的特点和复杂程度,选择合适的算法进行语法分析。
3、语法分析器实现:根据选择的语法分析算法,使用合适的编程语言编写SQL语句语法分析器的代码。语法分析器的实现过程通常包括以下几个步骤:
(1)定义语法规则:将SQL语句的语法规则转换为相应的产生式(Production)或规则。
(2)构建语法分析表:根据语法规则构建语法分析表,用于支持语法分析算法的执行。
(3)实现语法分析算法:根据选择的算法,编写相应的语法分析算法代码,如递归下降分析、LL(k)分析或LR(k)分析等。
(4)执行语法分析:调用语法分析器函数,将输入的SQL语句作为输入,执行语法分析过程,并生成语法树或抽象语法树。
4、错误处理:处理语法错误,包括语法不匹配、缺失或多余的关键字、表达式错误等。在语法分析过程中,如果遇到语法错误,语法分析器应该能够检测到并提供有关错误的相关信息。
5、语法树构建:根据语法分析的结果,构建语法树或抽象语法树。语法树反映了SQL语句的语法结构,包括查询的各个部分、表达式、关系操作等。
3.1.2语法分析器实现方法
1、手动实现
手动实现语法分析器需要编写自己的语法分析算法代码,根据选择的算法(如递归下降分析、LL(k)分析、LR(k)分析等)来编写相应的分析器代码。手动实现的优点是可以根据具体需求进行灵活的定制和优化,但需要较多的工作量和对语法分析算法的深入理解。
手动实现的步骤通常包括:
(1)定义语法规则:将语法规则转换为相应的产生式或规则。
(2)构建语法分析表(如果适用):根据语法规则构建语法分析表,用于支持语法分析算法的执行。
(3)实现语法分析算法:根据选择的算法,编写相应的语法分析算法代码,如递归下降分析、LL(k)分析或LR(k)分析等。
(4)执行语法分析:调用语法分析器函数,将输入的符号序列作为输入,执行语法分析过程,并生成语法树或抽象语法树。
2、自动实现
自动实现语法分析器可以使用专门的工具或生成器来生成语法分析器的代码这些工具通常根据给定的语法规则自动生成相应的语法分析器代码,减少了手动编写代码的工作量。常用的自动生成工具包括ANTLR、Bison、Yacc等。
自动实现的步骤通常包括:
(1)定义语法规则:使用工具提供的语法规则描述语言(如BNF、EBNF等)来定义语法规则。
(2)生成语法分析器代码:使用工具提供的生成器,根据语法规则自动生成语法分析器的代码。
(3)集成和调用:将生成的语法分析器代码集成到项目中,并根据需要调用语法分析器进行语法分析。
自动实现的优点是可以节省开发时间,尤其适用于大型和复杂的语法规则。然而,自动生成的代码可能不够灵活,难以进行个性化定制和优化。
3.2上下文无关文法
上下文无关文法(Context-Free Grammar,CFG)是一种形式语言的描述方法,用于描述上下文无关语言。它由四个部分组成:终结符(Terminals)、非终结符(Non-terminals)、产生式(Productions)和起始符号(Start symbol)。
(1)终结符(Terminals)
终结符是语法规则中的基本符号,表示语言中的最小单位。终结符可以是字母、数字、标点符号或其他词法单元。可以使用%token来定义终结符,以下是一个示例:
%token NUMBER
%token PLUS MINUS TIMES DIVIDE
%token IDENTIFIER
%token SEMICOLON在这个示例中,我们定义了几个终结符,包括数字(NUMBER)、加号(PLUS)、减号(MINUS)、乘号(TIMES)、除号(DIVIDE)、标识符(IDENTIFIER)和分号(SEMICOLON)等。终结符是语法规则中的基本符号,代表语言中的最小单元或词汇元素。终结符在语法分析的过程中与输入字符串的实际内容进行匹配,帮助构建解析树或语法分析树。在 Bison 文件中,终结符通常以大写字母或使用引号括起来的字符串表示。
(2)非终结符(Non-terminals)
非终结符是语法规则中的符号,表示语言中的语法结构。非终结符可以由一个或多个终结符和非终结符组成。可以用%type来定义非终结符的类型。以下是一个示例:
%type <expr> expression
%type <term> term
%type <factor> factor在这个示例中,定义了三个非终结符 expression、term 和 factor,并指定了它们的类型。这些类型标记可以在产生式的操作部分使用,以便对解析树节点进行更复杂的操作。非终结符在语法分析树中代表了一些更高级的结构,可以用来执行语义操作、构建解析树,并帮助描述语言的抽象语法结构。在 Bison 文件中,非终结符通常以小写字母开头。
(3)产生式(Productions)
产生式描述了语言中的语法规则,它指定了如何从一个符号派生出另一个符号。每个产生式由一个非终结符作为左部和一个由终结符和非终结符组成的右部组成。产生式可以表示符号的替换、扩展或重组。
(4)起始符号(Start symbol)
起始符号是CFG中的一个特殊非终结符,表示整个语言的起始点。从起始符号开始,通过一系列的产生式推导,可以生成语言中的句子。
上下文无关文法可以用于描述各种编程语言的语法、自然语言的语法以及其他形式语言的结构。它是形式语言理论和编译原理中的重要概念,被广泛应用于编译器、解析器和自然语言处理等领域。
3.3二义性文法
二义性文法(Ambiguous Grammar)是指存在多个解析树或多个推导序列的上下文无关文法。当一个文法可以生成多个不同的解析树或推导序列时,就称该文法为二义性文法。
二义性文法可能导致语法分析的歧义,使得解析过程无法确定唯一的语法结构。这可能会导致解析器产生错误的结果或无法正确解析输入。
二义性文法的产生通常是由于模糊的语法规则或缺乏明确的优先级和结合性规则。例如,一个表达式文法中可能存在模糊的运算符优先级,导致同一表达式可以有多种不同的解析方式。
二义性文法例子如下所示:

说明:坐标的文法规则可以同时推导出两个语法树,右上角的语法树计算结果为:23;右下角的语法树计算结果为:35(错误结果)。
解决二义性文法的方法包括:
(1)重新设计文法:通过修改文法的规则或引入额外的规则,消除二义性。可以通过调整运算符的优先级和结合性规则、明确操作符的操作数数量等方式来解决二义性。
(2)使用优先级和结合性规则:通过明确定义操作符的优先级和结合性规则,可以消除二义性。例如,使用算符优先文法(Operator Precedence Grammar)或优先级下降分析方法(Precedence Parsing)等。
(3)引入语义动作:在语法分析过程中,通过引入语义动作(Semantic Actions)来处理二义性。语义动作可以在解析过程中执行特定的操作,根据语法上下文和语义信息来确定正确的解析方式。
(4)使用更强大的语法分析方法:如果无法通过简单的文法修改解决二义性,可以考虑使用更强大的语法分析方法,如上下文相关文法(Context-Sensitive Grammar)或属性文法(Attribute Grammar)。
(5)在设计和实现语法分析器时,避免使用二义性文法是很重要的,因为二义性可能导致解析错误和不确定性。因此,在定义语法规则时应该尽量避免产生二义性,或者在出现二义性时进行明确的规则设计和处理。
3.4语法分析算法
语法分析器(Parser)是用于将输入的字符串(通常是源代码)按照给定的语法规则进行解析和分析的工具或算法。它的主要任务是确定输入是否符合语法规则,并构建相应的语法树或语法分析树。常见语法分析算法包括:自顶向下分析算法和自底向上分析算法。
3.4.1自顶向下分析算法
自顶向下分析算法基本思想:
(1)从文法的起始符号开始,选择一个合适的产生式规则进行推导。
(2)对于选取的产生式规则中的每个符号,根据其类型执行相应的操作:
1)如果是非终结符,则递归地调用相应的子程序进行处理,即向下展开。
2)如果是终结符,则进行匹配操作,将当前输入与该终结符进行比较。
(3)根据匹配结果决定下一步的动作:
1)如果匹配成功,继续分析下一个符号。
2)如果匹配失败,进行错误处理或回溯。
(4)重复步骤1-3,直到达到终止条件(例如分析完成或无法继续推导)。
从上述思想来看,该算法需要用到回溯,效率比较低下;为了避免回溯,从而引出了递归下降分析算法和LL(1)分析算法。
1、递归下降分析算法
递归下降分析算法也称为预测分析算法,该算法的基本思想为:
(1)每一个非终结符构造一个分析函数;
(2)用前看符号指导产生式规则的选择;
示例如下:

推导句子:gdw
#------递归下降分析算法基本思想------#
parse_S()
parse_N()
parse_V()
parse_N()
Parse_N()
token =tokens[i++]
if ( token==s || token==t || token==g || token==w)
return ;
error( "..." );
parse_V()
token=tokens[i++]
...// leave this part to you递归下降分析算法优缺点:
(1)分析高效(线性时间),但仍存在回溯风险;
(2)容易实现(方便手工编码);
(3)错误定位和诊断信息准确;
2、LL(1)分析算法
LL(1)分析算法从左向右读入程序,最左推导,采用一个前看符号;该算法基本思想是:表驱动的分析算法。ANTLR语法分析器工具采用的就是该算法。
LL分析器架构如下图所示:

(1)FIRST集
1)FIRST集定义
说明:此时并未考虑非终结符可能为空的情况,后面会给出FIRST完成定义和算法!

2)FIRST集的不动点算法
#------FIRST集不动点算法思想------#
foreach(nonterminai N)
FIRST(N)={ }
while(some set is changing)
foreach(production p: N -> β1 ... βn)
if(β1 == a ...)
FIRST(N) U= {a}
if(β1 == M...)
FIRST(N) U= FIRST(M)
示例:

| N\FIRST |
0 |
1 |
2 |
3 |
4 |
| S |
{} |
{} |
{s,t,g,w} |
{s,t,g,w} |
|
| N |
{} |
{s,t,g,w} |
{s,t,g,w} |
{s,t,g,w} |
|
| V |
{} |
{e,d} |
{e,d} |
{e,d} |
上述示例FIRST集如下表所示:
| N\FIRST |
|
| S |
{s,t,g,w} |
| N |
{s,t,g,w} |
| V |
{e,d} |
由FIRST集得到LL(1)分析表如下:
| N\T |
s |
t |
g |
w |
e |
d |
| S |
0 |
0 |
0 |
0 |
||
| N |
1 |
2 |
3 |
4 |
||
| V |
5 |
6 |
表中的数据代表每一条产生式的第一个可能前看符号,例如:N的第一个前看符号可能是s、t、g、w,所以N所在行的数据分别为s、t、g、w所对应的行号。在进行语法分析时,直接查看该表即可,必定不会出现回溯的情况。
(2)LL(1)分析表的冲突
1)LL(1)分析表冲突示例

对应LL(1)分析表如下:
| N\T |
s |
t |
g |
w |
e |
d |
| S |
0 |
0 |
0 |
0 |
||
| N |
1 |
2 |
3 |
4,5 |
||
| V |
5 |
6 |
LL(1)分析表中 5 的存在导致对应产生式有两条可以选,即当一条产生式匹配不成功时会进行另一条产生式的匹配,从而出现回溯的情况。
2)冲突检测定义
对N的两条产生式规则 和
和 ,要求
,要求 。
。
如: ,所以上述示例存在冲突。
,所以上述示例存在冲突。
如果LL(1)分析表中存在冲突时,则该文法不是LL(1)文法,也就不能用LL(1)分析算法。
(3)NULLABLE集合
NULLABLE集是在语法分析中用于确定一个非终结符号是否能够推导出空串(ε)。
NULLABLE集合定义
非终结符X属于集合NULLABLE,当且仅当:
(1)基本情况:X->ε (ε为空)
(2)归纳情况:X->Y1,…,Yn (Y1,…,Yn 是n个非终结符,且都属于NULLABLE集)
1)NULLABLE集合算法
#------NULLABLE集合算法------#
NULLABLE={};
while (nu1lable is still changing)
foreach (production p:x->3)
if (β == s)
NULLABLEU U= {x}
if(β == Y1 ... Yn)
if (Y1 ∈NULLABLE && ... && Yn ∈NULLABLE)
NULLABLE U= {x}
2)NULLABLE集合计算示例

| NULLABLE |
0 |
1 |
2 |
3 |
| {} |
{Y,X} |
{Y,X} |
说明:0、1、2、3为循环遍历次数;
(4)FIRST集完整计算公式
FIRST集是在语法分析中用于确定一个符号串的首个终结符号集合。
1)FIRST集定义
(1)基本情况:X->a
FIRSTX∪={a}
(2)归纳情况:X->Y1,…,Yn
FIRSTX∪={Y1}
if Y1∈NULLABLE, FIRSTX∪={Y2}
if Y2∈NULLABLE, FIRSTX∪={Y3}
…
2)FIRST集的不动点算法
#------FIRST集不动点算法------#
foreach (nonterminal N)
FIRST(N)={}
whi1e( some set is changing)
foreach (production p:N->β1 ... βn)
foreach(β i from β1 upto βn)
if(βi == a ...)
FIRST(N) U= {a}
break
if(βi == M ...)
FIRST(N) U= FIRST(M)
if(M is not in NULLABLE)
break;
3)FIRST集计算示例

| N\FIRST |
0 |
1 |
2 |
| Z |
{} |
{d} |
{d,c,a} |
| Y |
{} |
{c} |
{c} |
| X |
{} |
{c,a} |
{c,a} |
(5)FOLLOW集不动点算法
FOLLOW集是在语法分析中用于判断一个非终结符号(非终结符号是语法规则中的左侧符号)的后继可能出现的终结符号的集合。
1)FOLLOW集不动点算法
#------FOLLOW集不动点算法------#
foreach (nonterminal N)
FOLLOW(N) = {}
whi1e (some set is changing)
foreach (production p:N->β1 ... βn)
temp = FOLLOW(N)
foreach( βi from n downto β1) //逆序!
if(βi == a ...)
temp = {a}
if(βi == M ..)
FOLLOW(N) U= temp
if(M is not NULLABLE)
temp = FIRST(M)
else temp U= FIRST(M)
2)FOLLOW集计算示例

由前面计算可知,示例中NULLABLE集和RIRST分别如下:
NULLABLE集:NULLABLE={X,Y};
FIRST集如下表:
| X |
Y |
Z |
|
| FIRST |
{a,c} |
{c} |
{a,c,d} |
由FOLLOW集不动点算法可得FOLLOW集如下表:
| N\FOLLOW |
0 |
1 |
2 |
| Z |
{} |
{} |
{} |
| Y |
{} |
{a,c,d} |
{a,c,d} |
| X |
{} |
{a,c,d} |
{a,c,d} |
(6)FIRST_S集合
FISRT_S集即把FIRST集推广到一个串上。
1)FIRST_S集不动点算法
#------FIRST_S集不动点算法------#
foreach (production P)
FIRST_S(P) = {}
calculte_FIRST_S (production P: N-> β1... βn)
foreach(βi from β1 to βn)
if(βi == a...)
FIRST_S(P) U= {a}
return;
if(βi == M...)
FIRST_S(p) U= FIRST(M)
if(M is not NULLABLE)
return ;
FIRST_S(p) U= FOLLOW(N)
2)FIRST_S集计算示例

由前面计算可知,示例中NULLABLE集和RIRST分别如下:
NULLABLE集:NULLABLE={X,Y};
FIRST集和FOLLOW集如下表:
| X |
Y |
Z |
|
| FIRST |
{a,c} |
{c} |
{a,c,d} |
| FOLLOW |
{a,c,d} |
{a,c,d} |
{} |
由FIRST_S集不动点算法可得FIRST_S集如下表:
| 0 |
1 |
2 |
3 |
4 |
5 |
|
| FIRST_S |
{d} |
{a,c,d} |
{c} |
{a,c,d} |
{a,c,d} |
{a} |
说明:0,1,2,3,4,5分别对应着每条产生式!
由FIRST_S集可得LL(1)分析表如下:
| a |
c |
d |
|
| Z |
1 |
1 |
0,1 |
| Y |
3 |
2,3 |
3 |
| X |
4,5 |
4 |
4 |
LL(1)分析算法可理解为在自顶而下算法基础上增加了一个LL(1)分析表,以避免回溯,提高效率。
(7)LL(1)文法中的冲突处理
LL(1)文法冲突:当LL(1)分析表中的某些表项包含两个或更多的元素时,依然会存在回溯,此时便不再适用LL(1)文法。
1)LL(1)文法冲突示例

左递归:E->E+T,第0条产生式中E处于递归状态;
T->T*F,第2条产生式中T处于递归状态;
FIRST_S集如下表:
| 0 |
1 |
2 |
3 |
4 |
|
| FIRST_S |
{n} |
{n} |
{n} |
{n} |
{n} |
LL(1)分析表如下:
| n |
+ |
* |
|
| E |
0,1 |
||
| T |
2,3 |
||
| F |
4 |
2)LL(1)文法冲突处理
(1)消除左递归
消除左递归即设法把左递归改成右递归,右递归一般都符合LL(1)文法。上述示例改为右递归结果如下:

右递归:E->TE‘,第0条产生式中E’处于递归状态;
T->FT‘,第2条产生式中T’处于递归状态;
注意:产生式中TE’=T+TE’(替换E’时不加小括号);
消除左递归后的LL(1)分析表如下:
| n |
+ |
* |
|
| E |
0 |
||
| E’ |
1 |
||
| T |
3 |
||
| T’ |
5 |
4 |
|
| F |
6 |
(2)提取左公因子
提取左公因子消除左递归示例:

提取左公因子前,部分LL(1)分析表如下:
| a |
|
| X |
0,1 |
提取左公因子后结果如下:

提取左公因子后,部分LL(1)分析表如下:
| a |
|
| X |
0 |
(8)LL(1)分析算法优缺点
LL(1)分析算法优点:
(1)分析高效(线性时间);
(2)错误定位和诊断信息准确;
(3)有现成的工具可用,如:ANTLR,JavaCC
LL(1)分析算法缺点:
(1)能分析的文法类型有限;
(2)往往需要文法的改写(当LL(1)表存在冲突时,即某一个表项存在多个可选项,如上图中非终结符N的第一个可能前看符号同时存在:w和wm);
3.4.2自底向上分析算法
LR算法(LR Parsing):LR算法是一种自底向上的分析方法,其中LR表示从左到右扫描输入,从右到左推导产生式的右部。LR算法使用移进-归约(Shift-Reduce)操作来逐步构建语法树。常见的LR算法包括LR(0)、SLR(1)、LALR(1)和LR(1)等。
自底向上分析算法基本思想(从左到右称替换,从右到左称规约):

引入:点记号
点记号是为了方便标记语法分析器已经读入了多少输入,通常以“圆点“表示。

引入点记号后:

LR分析器架构如下图所示:

1、LR(0)分析算法
LR(0)分析算法是一种用于构建LR(0)分析表并解析上下文无关文法的自底向上语法分析算法。它是一种强大的自动化分析技术,用于验证给定输入串是否符合给定的上下文无关文法。
(1)LR(0)分析算法基本思想

(2)LR(0)分析算法示例

LR(0)表如下所示:
| 动作(ACTION) |
转移(GOTO) |
||||
| 状态\符号 |
x |
y |
$ |
S |
T |
| 1 |
s2 |
g6 |
|||
| 2 |
s3 |
||||
| 3 |
s4 |
g5 |
|||
| 4 |
r2 |
r2 |
r2 |
||
| 5 |
r1 |
r1 |
r1 |
||
| 6 |
accept |
||||
说明:s2代表转移到状态2;g5代表跳转到状态5;r2代表对产生式2进行规约,即弹出当前栈中y相关的信息,压入T相关信息;
(4)LR(0)分析表中错误定位时机
示例:

LR(0)分析表如下:
| 动作(ACTION) |
转移(GOTO) |
|||
| 状态\符号 |
x |
y |
$ |
S |
| 1 |
s2 |
s3 |
g4 |
|
| 2 |
s2 |
s3 |
g5 |
|
| 3 |
r2 |
r2 |
r2 |
|
| 4 |
accept |
|||
| 5 |
r1 |
r1 |
r1 |
|
说明: 由于S的FOLLOW集,FOLLOW(S)={$},因此,当第一个r2(3,x)出现时就应该报错(第一个r2出现时,也即产生式2中的S->y规约为S,但规约后S后面输入的是x,x不是S的FOLLOW集),但实际上并没有报错,导致做了比较多的无用功;当地一个r1(5,x)出现时(即产生式1中的S->xS规约为S,规约后期望后面看到$,即状态4,但实际上输入是x,所以会报错),报错实际过晚,导致做了较多无用功。
(5)LR(0)分析表中移进-规约冲突

说明:状态3中有两个可能的动作,动作一:E->T ●+E(移进);动作二:E->T ●(规约);事实上E的FOLLOW集,FOLLOW(E)={$},如果对状态3中的第二条进行规约的话,规约后输入的是“+”,则不符合;如果移进-规约冲突处理不好的话,有可能导致回溯。
(6)LR(0)分析算法优缺点
LR(0)分析算法优点:
1)不需要对文法进行特殊处理,如:改写;
2)有现成的工具可用,如:YACC、bison、CUP、C#yacc等;
LR(0)分析算法缺点:
1)每一次规约后,后面都会紧跟一个状态,即栈顶是状态;
2)错误分析不准确,导致做无用功,从而延迟错误发现的时机;
3)LR(0)分析表中可能包含移进-规约冲突;
2、SLR分析算法
SLR(Simple LR)分析算法是一种用于构建语法分析表的自底向上的语法分析方法。它是LR(0)分析方法的一种扩展,用于处理具有左递归和回溯的文法。
(1)SLR分析算法核心思想:
对于状态i上的项目 X->α ● ,仅对输入为:y∈FOLLOW(X)时,添加ACTION[i,y](即进行规约操作)。
(2)SLR分析算法与LR(0)分析算法相比优势:
1)有可能减少需要归约的情况,但不能确保正确的规约 ;
2)有可能去除需要移进-归约冲突;
示例一:

SLR分析表如下:
| 动作(ACTION) |
转移(GOTO) |
|||
| 状态\符号 |
x |
y |
$ |
S |
| 1 |
s2 |
s3 |
g4 |
|
| 2 |
s2 |
s3 |
g5 |
|
| 3 |
|
|
r2 |
|
| 4 |
accept |
|||
| 5 |
|
|
r1 |
|
说明:由于S的FOLLOW集,FOLLOW(S)={$},因此红色字体对应的r1、r2部分不满足SLR算法条件,不规约;与LR(0)分析表相比,减少了红色字体对应的规约;
示例二:

说明:由于E的FOLLOW集,FOLLOW(E)={$},因此状态3中的 E->T ● 不满足SLR算法中的规约条件,不规约。
(3)SLR分析算法缺点:
1)仍然有冲突出现的可能;
示例:

说明:由于R的FOLLOW集,FOLLOW(R)={=,…},因此状态2中的 R->L ● 符合SLR算法中的规约条件;此时状态二存在移进、规约两种情况(即移进-规约冲突)。
3、LR(1)分析算法
LR(1)分析算法是一种自底向上的语法分析方法,它是对LR(0)分析方法的改进。LR(1)分析算法通过考虑一个前看符号(Lookahead)来解决LR(0)分析中的冲突问题,从而能够处理更多类型的文法。
(1)LR(1)分析算法核心思想
将一般形式为[A->α ● β,a]的项称为LR(1)项,其中A->α ● β是一个产生式,a是一个终结符(这里将$视为一个特殊的终结符,且a是一个集合,通常包含某一个或某几个终结符)它表示在当前状态下,A后面必须紧跟终结符,称为该项的展望符(lookahead),即前看符号。
1)LR(1)中的1指的是项的第二个分量的长度;
2)在形如[A->α ● β,a]且β≠ε的项中,前看符号a没有任何作用;
3)但是一个形如[A->α ●,a]的项在只有在下一个输入符号等于a时才可以按照A->α进行归约;且这样的a的集合总是FOLLOW(A)的子集,而且它通常是一个真子集。
说明:与SLR分析算法相比,LR(1)分析算法把A的FOLLOW集a放到了“[ ]”内部;且LR(1)分析算法的FOLLOW集a要比SLR分析算法中A的FOLLOW集a更加明确、具体。
(2)LR(1)项目构造
其他和LR(0)相同,仅闭包的计算不同:对项目[X->α ● Yβ,a],添加[Y->● γ,b]到项目集,其中bϵFIRST_S(βa)。
示例:

说明:上述示例中状态5和状态11、状态8和状态10情况近似,导致LR(1)所占空间较大。
4、LALR分析算法(bison使用的就是该分析算法)
LALR(Lookahead LR)分析算法是对LR(1)算法的一种优化,旨在减少LR(1)算法中项目集规范族和分析表的大小,从而提高分析效率。(项目集规范族(canonical collection of sets of items)是在LR分析算法中使用的一种数据结构,用于表示文法的所有可能项目集的集合。)
(1)LALR分析算法核心思想
- 把类似的项目集进行合并;
- 需要修改ACTION表和GOTO表,以反映合并效果;
示例:

说明:可以把示例中的状态5和状态11、状态8和状态10进行合并,但是合并后有一个负面作用,例如:把状态8和状态10合并后,都变成了R->L ● ,=,$,所以状态10中对前看符号的标记就不再精确了(多了个‘=’),最终导致可能出现移进-规约冲突。
(2)对二义性文法的处理
- 二义性文法无法使用LR分析算法分析(实际上现在没有任何一种分析算法能够完整的处理所有可能的二义性文法);因为二义性文法对程序的解释不是唯一的,有可能会有多个结果,而解释器无法判断哪个是正确的。
- 不过,有几类二义性文法很容易理解,因此,在LR分析器的生成工具中,可以对他们特殊处理,如:优先级、结合性等。
示例:优先级和结合性

说明:左下角的状态中存在移进-规约冲突,移进(E->E+E ●)、规约(E->E ●+E、E->E ●*E),此时可以使用‘left +’和‘left *’解决移进规约冲突,即如果该状态下一个输入是‘+’,则归于;如果该状态下一个输入是‘*’,则移进。右下角状态同理。
5、LR(0)、SLR、LR(1)和LALR的区别
LR(0)、SLR、LR(1)和LALR是常见的自底向上(bottom-up)语法分析算法,用于构建LR分析表和分析输入串的过程。它们之间的区别主要在于对于语法规则的处理、项目集的构建方式和分析表的大小。
(1)LR(0)(Lookahead Regular)分析算法:
- LR(0)算法是最简单的LR分析算法,它不考虑任何向前看符号(lookahead symbol)。
- 在构建项目集规范族(canonical collection of sets of LR(0) items)时,每个项目集中的项目只包含产生式的左部和一个点,表示产生式的扫描位置。
- LR(0)分析表中的表项包含移进(shift)和归约(reduce)操作。
(2)SLR(Simple LR)分析算法:
- SLR算法是在LR(0)算法的基础上进行了改进,引入了向前看符号。
- 在构建项目集规范族时,每个项目集中的项目除了产生式的左部和点的位置外,还考虑了可以跟随点的终结符。
- SLR分析表中的表项包含移进、归约和接受(accept)操作。接受操作表示成功分析完成。
(3)LR(1)(Lookahead Regular with 1-symbol lookahead)分析算法:
- LR(1)算法进一步扩展了向前看符号的能力,每个项目集中的项目除了产生式的左部和点的位置外,还考虑了一个向前看符号。
- 在构建项目集规范族时,考虑了更多的向前看符号信息,使得分析表更加精确。
- LR(1)分析表中的表项包含移进、归约和接受操作。
(4)LALR(Lookahead LR)分析算法:
- LALR算法是对LR(1)算法的一种优化,旨在减少LR(1)算法中项目集规范族和分析表的大小。
- 在构建项目集规范族时,LALR算法通过合并具有相同内核(核心项目集)的项目集来减少项目集的数量。
- LALR分析表中的表项与LR(1)分析表相似,包含移进、归约和接受操作,但表项的数量较少。
总结来说,LR(0)是最简单的LR分析算法,不考虑向前看符号;SLR算法在LR(0)的基础上引入了向前看符号;LR(1)算法进一步扩展了向前看符号的能力,提供更精确的分析表;LALR算法是对LR(1)的优化,通过合并项目集来减少项目集规范族和分析表的大小。这些算法在分析表的大小和分析能力上有所差异,根据具体的语法和需求选择适合的算法。
3.5抽象语法树(AST)
语法树(Syntax Tree)是在语法分析阶段构建的一种树状数据结构,用于表示源代码的语法结构。
抽象语法树是编译器前端和后端的接口,程序一旦被转换成抽象语法树,则源代码会被丢弃;且后续的阶段只处理抽象语法树。
所以抽象语法树必须编码足够多的源代码信息,例如,它必须编码每个语法结构在源代码中的位置(文件、行号、列号等);这样,后续的检查阶段才能精确的报错或者获取程序的执行刨面。
AST构建步骤:
(1)词法分析(Lexical Analysis):将源代码字符串分解成一个个的词法单元(tokens),如关键字、标识符、运算符等。词法分析器会扫描源代码字符串,并根据预定义的词法规则将其拆分成词法单元序列。
(2)语法分析(Parsing):将词法单元序列转换为语法树。语法分析器根据语法规则和词法单元序列构建语法树。常见的语法分析方法包括递归下降法、LL(1) 分析器、LR 分析器等。语法分析器会根据语法规则进行预测和推导,将词法单元序列转换为语法树的节点和边。
(3)构建语法树节点:在语法分析阶段,根据语法规则,为每个语法结构创建相应的节点。节点可以表示关键字、标识符、运算符、表达式、语句等。每个节点通常包含一个或多个子节点,形成了语法树的层次结构。
(4)连接节点:在语法分析阶段,语法分析器会根据语法规则将节点连接起来,形成语法树的结构。节点之间的连接代表了语法规则的应用关系,即父节点与子节点之间的关系。
(5)处理语法错误:在构建语法树的过程中,如果遇到语法错误,语法分析器会生成错误信息,并尽可能地继续构建语法树。语法错误可能包括不符合语法规则的输入、缺失的标识符、不匹配的类型等。在语法树构建完成后,可以根据错误信息进行错误处理和报告。
构建语法树的过程是逐步推导和构造的,通过词法分析和语法分析的协作,将源代码的结构转化为树状的数据结构。语法树的构建过程是编译器和解释器中重要的一步,它为后续的语义分析、优化和代码生成提供了基础。
4.语义分析
在语法分析的基础上,对生成的抽象语法树进行语义分析。语义分析器会检查SQL语句是否符合数据库的语义规则,例如表是否存在、列是否存在、数据类型是否匹配等。如果不符合,则会抛出语义错误。
5.优化器
在语义分析的基础上,进行优化。优化器会对SQL语句进行优化,以提高查询效率。优化器会选择最优的执行计划,包括选择最优的索引、选择最优的连接方式等。
6.执行计划生成器
在优化器的基础上,生成执行计划。执行计划是一组计算机指令,用于执行SQL语句。执行计划包括访问表、过滤数据、排序数据等操作。
7.执行计划执行器
执行计划执行器会按照执行计划执行SQL语句。执行计划执行器会访问表、过滤数据、排序数据等操作,最终返回查询结果。
8.结果集返回
执行计划执行器会将查询结果返回给客户端。查询结果可以是一张表、一组记录或一个标量值。
9.清理
在查询结束后,数据库管理系统会清理执行计划、释放资源等。文章来源:https://www.toymoban.com/news/detail-645809.html
未完,writing……文章来源地址https://www.toymoban.com/news/detail-645809.html
到了这里,关于SQL 语句解析过程详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!