1、位移不变性
它指的是无论物体在图像中的什么位置,卷积神经网络的识别结果都应该是一样的。
因为CNN就是利用一个kernel在整张图像上不断步进来完成卷积操作的,而且在这个过程中kernel的参数是共享的。换句话说,它其实就是拿了同一张“通缉令”在“全国范围”内查找“嫌疑犯”,这样一来理论上就具备了位移不变性了(当然,受限于步进跨度、卷积核大小等因素的影响,某些条件下CNN也可能会存在“漏”的情况)。
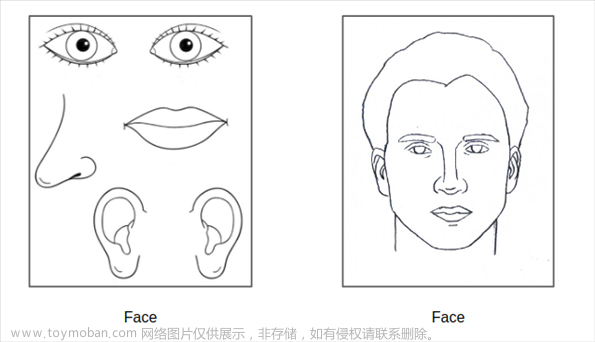
图 ‑ CNN缺乏“空间整体”理解
CNN会将上述两个图都判定为face——这是因为组成face的各个部件确实都在图像中出现了,只不过它们的排列是混乱的。但对于人类来说,这样的预测结果显然是比较“滑稽可笑”的,或者说无法接受的。
Capsule Network据说可以给出有效的解决办法
2、 尺寸不变性
尺度不变性,简单来讲就是指物体在被测试图像中的尺寸大小原则上不会影响模型的预测结果。
卷积神经网络,它的kernel size做为超参数是固定大小的,并不会动态调节。
通过小尺寸filter的堆叠来达到同样的效果,实际上比直接用大尺寸filter更节省参数数量,所以可以看到现在各个主流的神经网络框架中用的filter size普遍都不大(或者小尺寸filter占比高)。当然,这也并不代表大尺寸的filter“一无事处”。如果某些情况下大尺寸的filter刚好可以匹配到特征,那么此时它的效率要高于小尺寸的堆叠。正是基于这样的考虑,有些神经网络框架会选择“大小通吃”的策略来选择卷积核,比如著名的inception model。
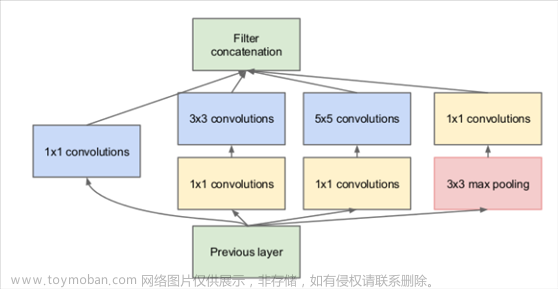
所以简单来说,卷积神经网络就是通过“大”和“小”卷积核的搭配和层叠,来满足图像识别中的尺度不变性的要求,同时降低参数数量的。
3、 旋转不变性
旋转不变性,简单来讲是指物体的旋转角度不会影响模型的预测结果。
(1) 池化层的“顺带”作用
我们知道,max pooling是针对数据在一定范围内取它们的最大值,比如下面所示的是2*2空间大小的操作范例:
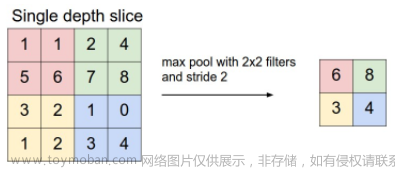
这种操作过程“顺带”赋予了CNN一个关键能力——即物体在旋转一定的小角度后,有某些概率下得到的结果值不会产生变化,从而让它似乎“具备”了旋转不变性。
从上述的描述中我们也可以看到,CNN的这种旋转不变性其实是“不可靠”的,带有一定的随机性质。
(2) 数据增强起到了作用
正因为算法层面对于旋转不变性没有特殊的设计,所以我们在应用卷积神经网络时更要重视这一问题。一种典型的办法就是采用数据增强,以“人为构造数据的方式”提升训练出来的模型在应对“旋转”问题时的鲁棒性。文章来源:https://www.toymoban.com/news/detail-647364.html
数据增强在深度神经网络中的重要性是毋庸置疑的。文章来源地址https://www.toymoban.com/news/detail-647364.html
到了这里,关于CNN的特性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!