Ajax介绍
Ajax(Asynchronous JavaScript and XML)是一种用于在Web应用程序中实现异步通信的技术。它允许在不刷新整个网页的情况下,通过在后台与服务器进行数据交换,实时更新网页的一部分。Ajax的主要特点包括:
-
异步通信: Ajax是异步的,这意味着它可以在不阻塞用户界面的情况下进行通信。用户可以继续与网页交互,而不必等待服务器响应。
-
数据交换: Ajax允许在客户端和服务器之间交换数据,通常使用XML、JSON或其他数据格式。这使得网页能够实时加载、显示和更新数据,而无需完全重新加载整个页面。
-
无需页面刷新: 传统的Web应用程序通常在每次与服务器进行交互时都需要刷新整个页面。而Ajax可以仅刷新页面的一部分,从而提供更流畅的用户体验。
-
动态内容: Ajax使开发人员能够创建动态的、实时更新的网页内容,这些内容可以根据用户的操作和需求进行动态加载和修改。
-
多种用途: Ajax不仅可以用于加载数据,还可以用于提交表单、验证用户输入、自动完成搜索、实时聊天和其他许多Web应用程序中的交互性功能。
Ajax通常由以下几个核心组件组成:
-
XMLHttpRequest对象: 这是Ajax的核心,它允许JavaScript代码与服务器进行通信,发送HTTP请求并接收响应。现代Web开发中通常使用
fetch API代替XMLHttpRequest,因为它更简单和强大。 -
服务器端脚本: 服务器端需要提供接受Ajax请求的端点,并能够处理这些请求,执行相应的操作,并返回响应数据。
-
异步事件处理: JavaScript代码需要能够在后台处理Ajax请求和响应,以确保不会阻塞用户界面。这通常涉及到使用回调函数或Promise来处理异步操作。
-
数据格式: Ajax可以使用多种数据格式来交换信息,包括XML、JSON、HTML和纯文本等。
Ajax已经成为现代Web应用程序开发的重要组成部分,它提供了一种有效的方式来实现实时、交互性和动态性的用户体验。很多流行的Web应用程序和框架(如React、Angular和Vue.js)都使用Ajax来处理数据的加载和交互。通过Ajax,Web应用程序可以更好地响应用户的需求,提供更好的用户体验。
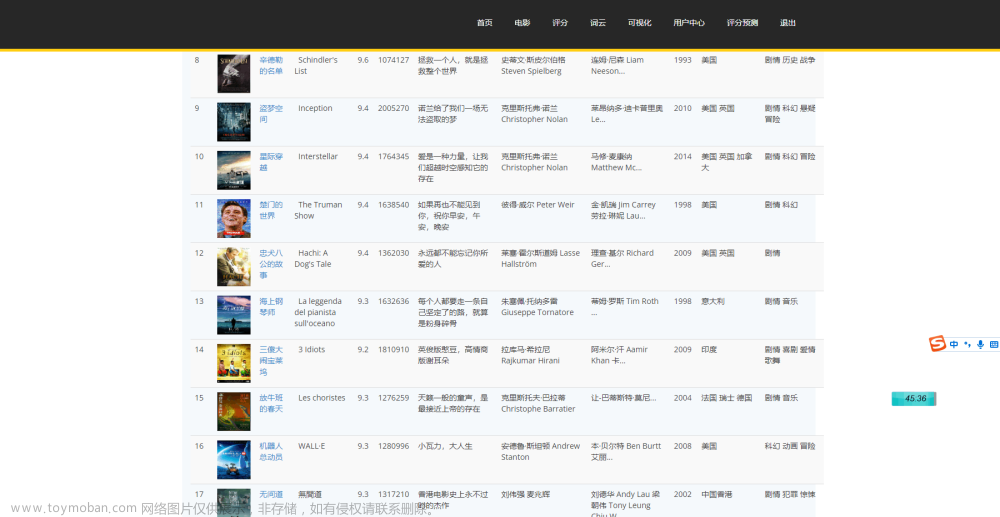
案列实战
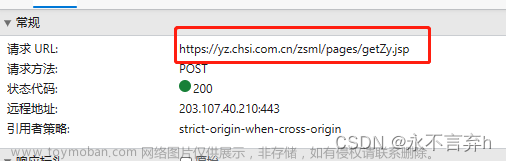
在上篇文章基础上https://blog.csdn.net/rubyw/article/details/132714499?spm=1001.2014.3001.5501使用Ajax动态渲染页面爬取,并存储到本地mongo数据库中
网站链接:https://spa1.scrape.center
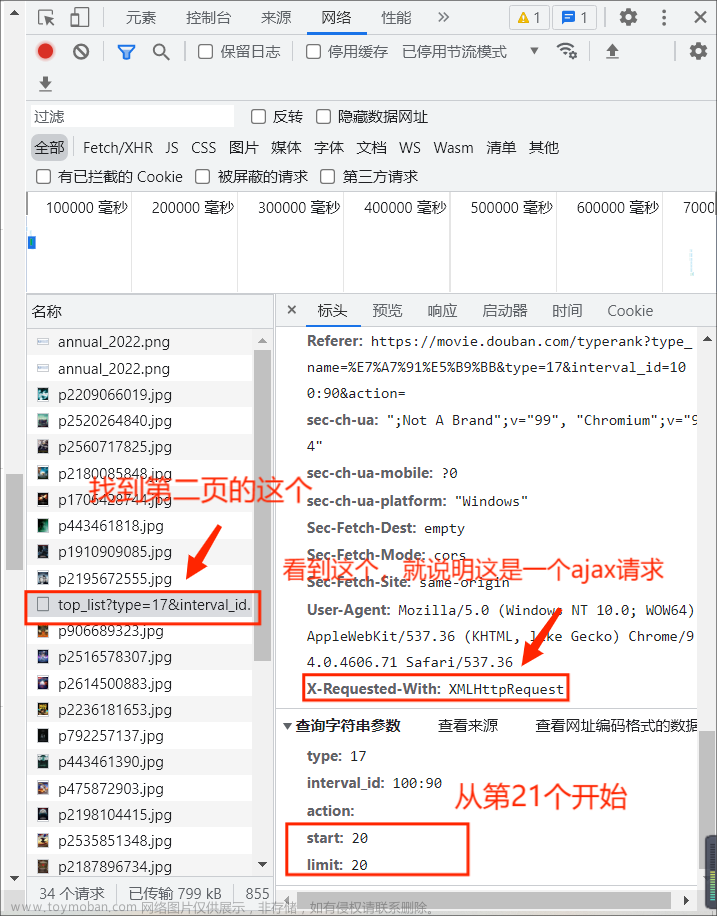
只看菜单XHR下的信息,观察页面变化时的情况
第一页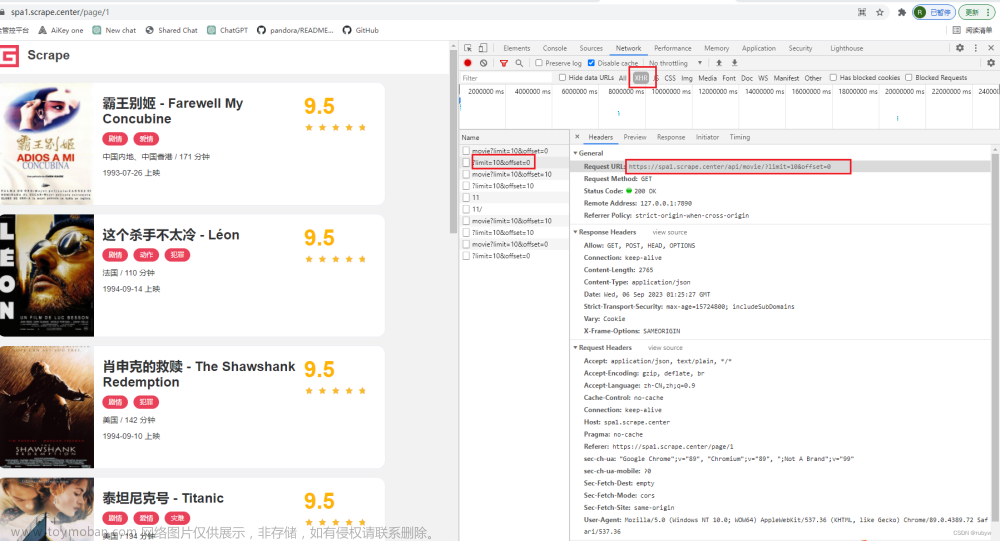
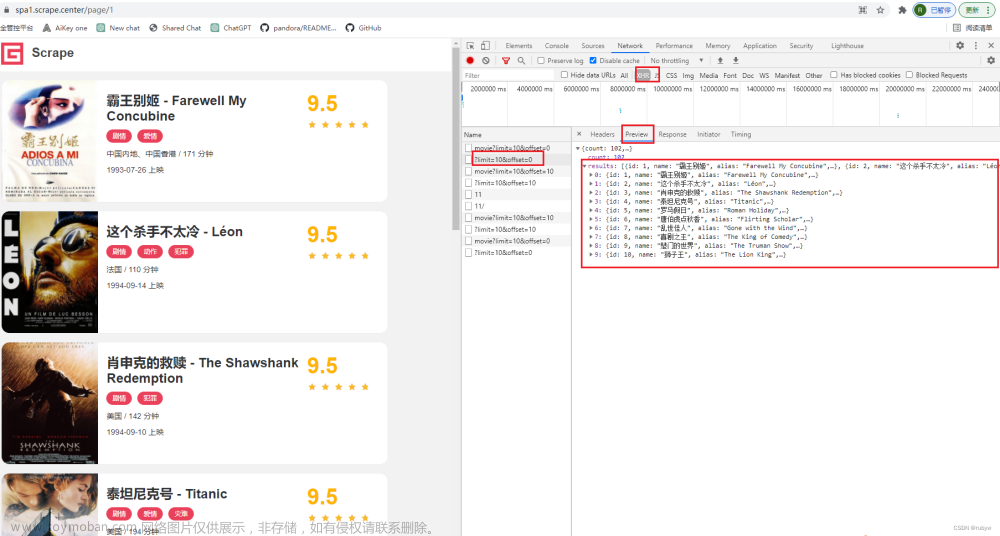
详情页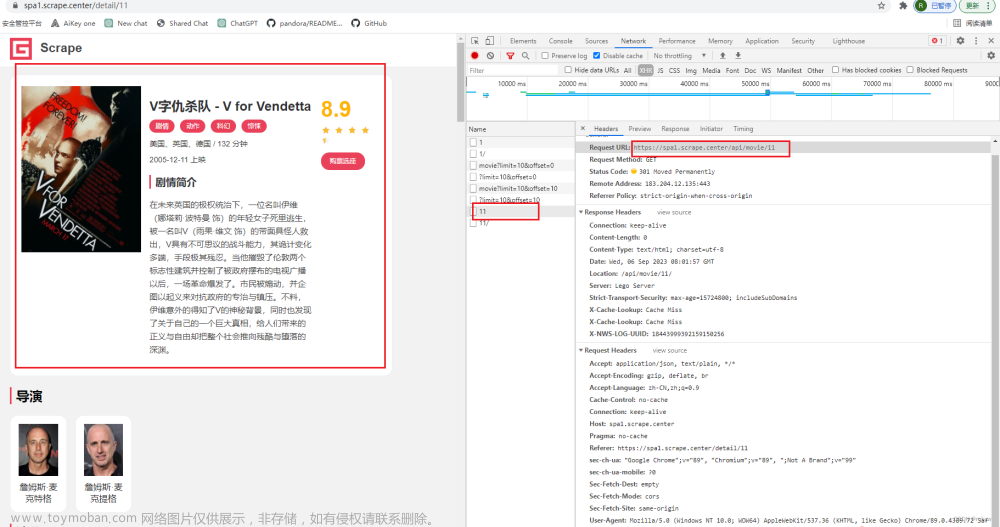
# Ajax + MongoDB存储
import pymongo
import requests
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
INDEX_URL = 'https://spa1.scrape.center/api/movie/?limit={limit}&offset={offset}'
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'movies'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client['movies']
collection = db['movies']
# 处理 JSON 接口
def scrape_api(url):
logging.info('scraping %s...', url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
else:
logging.error('get invalid status code %s while scraping %s',
response.status_code, url)
return None
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
LIMIT = 10
def scrape_index(page):
url = INDEX_URL.format(limit=LIMIT, offset=LIMIT * (page - 1))
return scrape_api(url)
DETAIL_URL = 'https://spa1.scrape.center/api/movie/{id}'
def scrape_detail(id):
url = DETAIL_URL.format(id=id)
return scrape_api(url)
TOTAL_PAGE = 10
def save_data(data):
collection.update_one({
'name': data.get('name') # 根据name进行查询
}, {
'$set': data # 表示更新操作
}, upsert=True) # 存在即更新,不存在即插入
def main():
for page in range(1, TOTAL_PAGE + 1):
index_data = scrape_index(page)
for item in index_data.get('results'):
id = item.get('id')
detail_data = scrape_detail(id)
logging.info('detail data %s', detail_data)
save_data(detail_data)
logging.info('data saved successfully')
if __name__ == '__main__':
main()
可视化工具RoboMongo/Robo 3T,它使用简单,功能强大,官方网站为https://robomongo.org/,三大平台都支持,下载链接为https://robomongo.org/download。文章来源:https://www.toymoban.com/news/detail-704269.html
最终在本地mongo数据库中可以看到最终爬取保存的结果: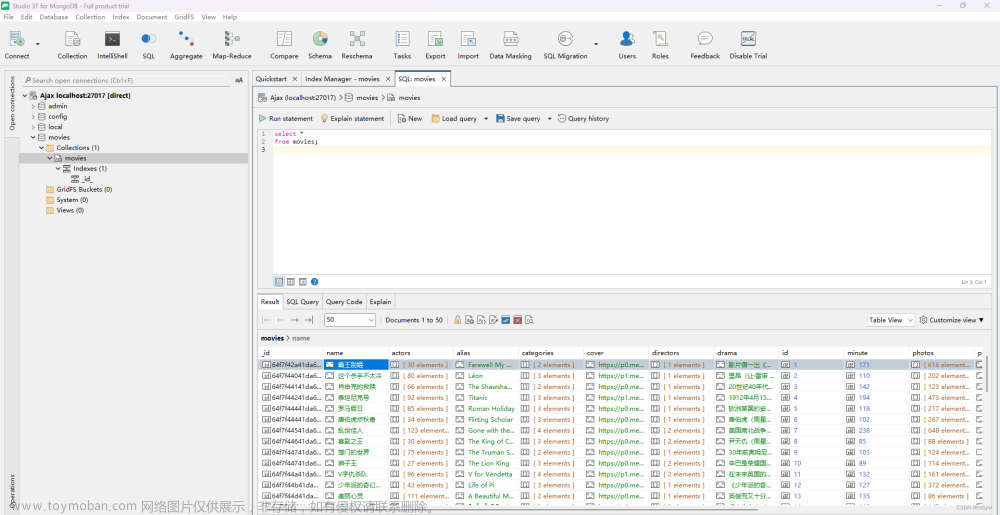 文章来源地址https://www.toymoban.com/news/detail-704269.html
文章来源地址https://www.toymoban.com/news/detail-704269.html
到了这里,关于Python爬取电影信息:Ajax介绍、爬取案例实战 + MongoDB存储的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!