作者:禅与计算机程序设计艺术
1.简介
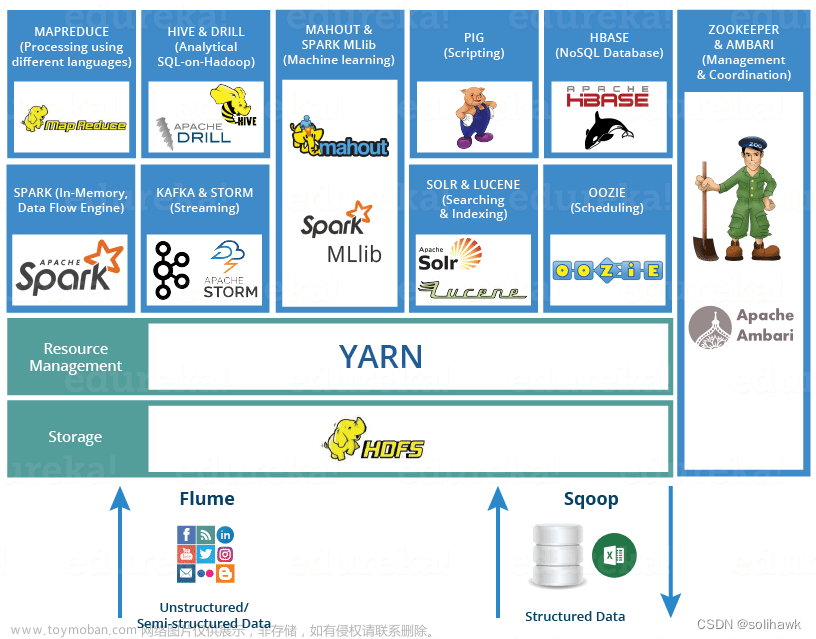
Apache Beam(波) 是一个开源的分布式计算框架,主要用于数据处理管道的编写。它具有统一的编程模型,能够运行在多种执行环境中,包括本地机器、云计算平台和大数据集群。Beam 提供了许多内置的功能和扩展点,包括基于 MapReduce 的批处理、基于流的实时计算、机器学习和图形分析等。Beam 可以有效地解决复杂的数据处理任务,并可保证高效的数据处理速度和低延迟的数据交互。
目前,Apache Beam 已经成为一个活跃的开源项目,它的最新版本为 2.34.0 。该版本的发布标志着 Beam 在数据处理领域的蓬勃发展,提供了丰富的新特性和功能。本文将根据 Apache Beam 发行版本及最新特性的内容,讨论其中的一些重要概念和术语。欢迎大家参与到本文的撰写和评论中来,共同推动 Beam 的发展。
2.核心概念术语
Pipeline
Apache Beam 中的 pipeline 是指一系列的 PTransform(变换),用于对输入数据集进行变换处理后得到输出数据集。Pipeline 中最底层的元素是 PCollection(集合),用于表示输入或输出数据的集合。PTransform 表示数据处理逻辑单元,如 Map 和 Flatten,分别用于数据转换和数据整合。文章来源:https://www.toymoban.com/news/detail-730579.html
如上图所示,一个典型的 Beam Pipeline 由多个 PTransform 操作和三个 PCollection 组成。其中左侧灰色框中的元素是用户自定义的逻辑,而右侧蓝色框中的元素则为 Beam SDK 提供的基础类库。通过连接 PTransform 和 PCollection,就可以构建出数据处理任务依赖图。文章来源地址https://www.toymoban.com/news/detail-730579.html
到了这里,关于开源分布式计算框架 Apache Beam 中的一些重要概念和术语的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!