一、XPath简介
XPath即XML路径查询语言(XML Path Language),是一种用于确定XML文档中部分节点位置的语言。它起初只支持搜索XML文档,更新后能支持搜索HTML文档。
XPath是如何搜索XML或HTML文档的?
XPath基于XML或HTML的节点树,沿着节点树的节点关系定位到目标节点所在的位置,并选取节点或节点集。为了形象地描述出搜索节点的路径,XPath提供简洁明了的路径表达式,通过路径表达式可以快速地定位与选取XML或HTML文档中的一个节点或者一组节点集。
路径表达式
路径表达式描述了从一个节点到另一个节点或一组节点的路径。这些路径与在常规的计算机文件系统中见到的路径非常相似。例如,“/学生名单/班级/学生/籍贯”就是一个路径表达式,该路径表达式也是用“/”字符进行分割的,只不过它分割的是节点,而不是目录。
XML文档,XML节点树与路径表达式的关系
XML文档
<bookstore>
<book category="WEB">
<title>Learing XML</title>
<author>Erik T.Ray</author>
<year>2003</year>
<price>39,95</price>
</book>
</bookstore>
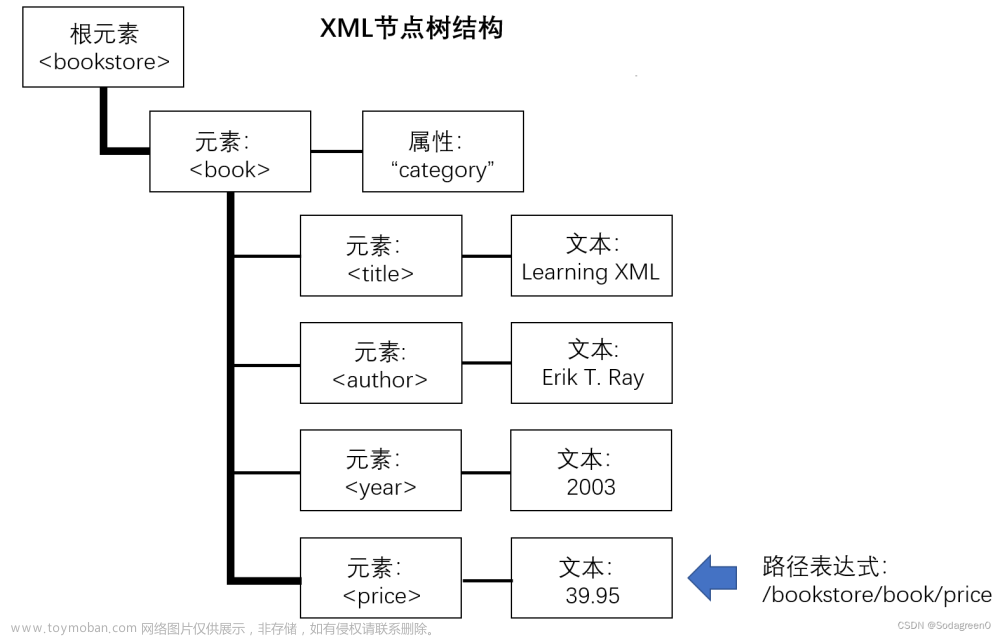
在上图中,从上到下,依次为XML文档、XML节点树和路径表达式。其中路径表达式为:“/bookstore/book/price”,它对应的路径为XML节点树种加粗的线条,用于选取节点price对应的文本39.95
二、XPath的安装(chrome)
本章选取的XPath版本为2.0.2,并在chrome中添加扩展,请保持chrome为最新版。
压缩包地址:XPath压缩包,密码:fxd1
1.下载解压到桌面。
2.打开chrome,打开设置在左边工具栏中找到扩展程序,点开就能看到所有的扩展程序,确保自己打开了开发者模式。
3.将桌面上的解压缩文件拖到刚刚的界面进行添加程序。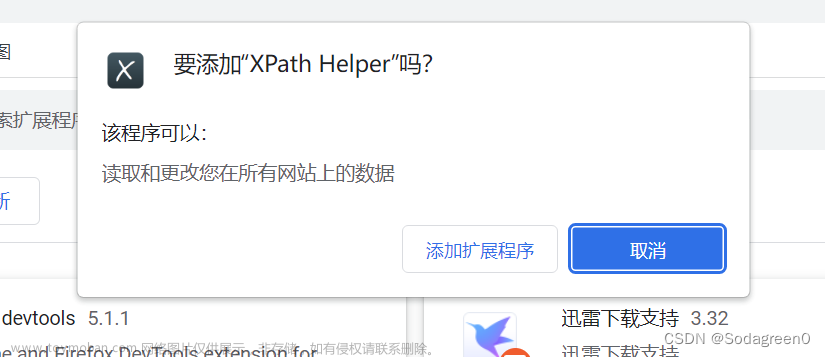
4.添加完成扩展程序中就新增了一个XPath Helper。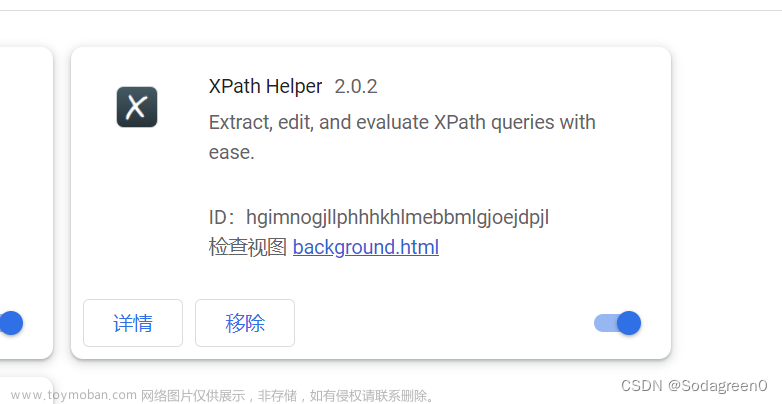
5.可以通过浏览器右上角扩展程序将XPath添加到工具栏。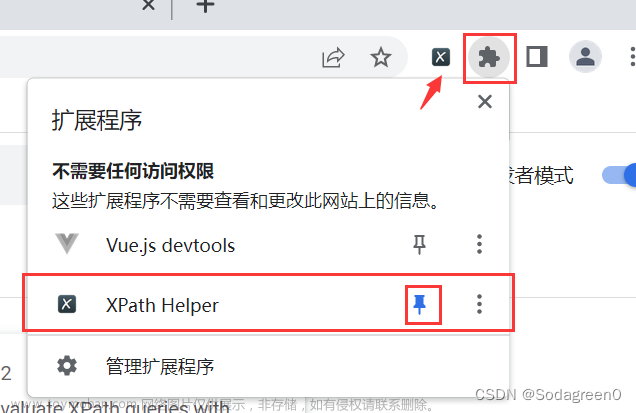
6.检查是否成功添加XPath到浏览器。
点击XPath程序页面出现黑色输入框即为添加成功。
三、如何使用XPath
我们要编写一个路径表达式,则要先了解XPath的语法,才能使用路径表达式正确的选取节点。
1.XPath语法
(1).选取节点
| 表达式 | 说明 |
|---|---|
| 节点名称 | 选取此节点的所有子节点 |
| / | 从根节点开始选取直接子节点,相当于绝对路径 |
| // | 从当前节点开始选取后代节点,相当于相对路径 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性节点 |
(2).常用的XPath函数
| 函数 | 说明 |
|---|---|
| position() | 返回当前被处理的节点位置 |
| last() | 返回当前节点集中的最后一个节点 |
| count() | 返回节点的总数目 |
| max((arg,arg…)) | 返回大于其他参数的参数 |
| min((arg,arg…)) | 返回小于其它参数的参数 |
| name() | 返回当前节点的名称 |
| current-date() | 返回当前的日期(带有时区) |
| current-time() | 返回当前的时间(带有时区) |
| contains(string1,string2) | 若string1包含string2,则返回True,否则返回False |
(3).选取未知节点
| 通配符/函数 | 说明 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型节点 |
(4).选取若干路径
在XPath中,我们可以使用“|”运算符连接多个路径表达式,根据多个路径选取对应的节点。
//book/title | //book/price # 选取属于book的子节点title和price
//title | //price # 选取所有title节点和price节点
/bookstore/book/title | //price # 选取属于/bokstore/的所有title节点和文档中的所有节点
2.使用XPath插件
下面以豆瓣电影TOP250为例,来说明怎么获取所有的电影名称。
网址:豆瓣电影TOP250
1.打开豆瓣TOP250网站,按下F12进入开发者模式,可以看到该网页的HTML代码
2.点击开发者模式左上角小箭头图标,进入检查模式。
3.鼠标移到电影名称,点击,就会在开发者模式中看到电影名称的html标签。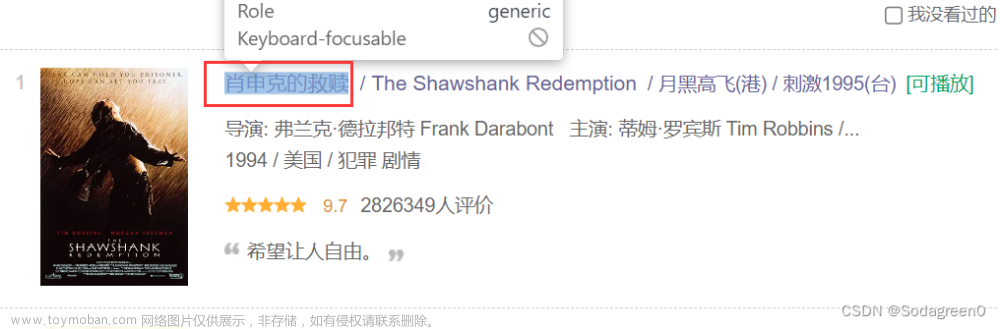

4.鼠标右键名称,赋值XPath路径。
5.打开XPath插件,将刚刚赋值的路径粘贴到XPath输入框中。
我们就看到了我们选取的电影名
6.要选取所有的电影名称我们就需要更改路径。
观察当前名称的html标签位置,找出规则。
所有电影名称的XPath路径为:文章来源:https://www.toymoban.com/news/detail-735016.html
//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]
在XPath输入框中输入上述路径,得出所有电影名称。
至此我们学会了怎么使用XPath。文章来源地址https://www.toymoban.com/news/detail-735016.html
到了这里,关于XPath的安装与使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!