目录
1 概述
2 Hugetlbfs
2.1 hstate
2.2 nr_hugepages
2.3 hugetlbfs
3 THP
3.1 enabled
3.2 defrag
3.3 migrate type
3.4 memory migration
3.5 memory compaction
1 概述
参考链接:https://www.kernel.org/doc/Documentation/vm/transhuge.txt
大页的主要使用场景为:
Performance critical computing applications dealing with large memory working sets are already running on top of libhugetlbfs and in turn hugetlbfs.
使用大页主要有两点收益:
- TLB Miss更快,如果发生tlb miss,mmu需要遍历页表,对于hugepage,其页表深度更小,因为需要的访存次数更少;
- TLB Miss更少,一个tlb entry可以覆盖更大的内存区域;
通过cpuid,我们可以知道cpu的tlb大小,
cpuid -1 | grep -i tlb
cache and TLB information (2):
0x63: data TLB: 1G pages, 4-way, 4 entries
0x03: data TLB: 4K pages, 4-way, 64 entries
0x76: instruction TLB: 2M/4M pages, fully, 8 entries
0xb5: instruction TLB: 4K, 8-way, 64 entries
0xc3: L2 TLB: 4K/2M pages, 6-way, 1536 entries
目前使用大页有两种方式,hugetlbfs与transparent hugepage;我们分别看下。
对于大页的性能收益,这里使用qemu-kvm为测试场景,配置方法参考:
这里我们选用两个测试用例,一个是在虚拟机中的/dev/shm下编译内核,一个是跑stream;
| 是否开启大页 | 时间 |
| 是 | 12m17s |
| 否 | 11m31s |
| 是否开启大页 | Copy | Scale | Add | Traid |
| 是 | 0.048282 | 0.070584 | 0.090897 | 0.090779 |
| 否 | 0.047912 | 0.068092 | 0.089300 | 0.089001 |
2 Hugetlbfs
hugetlb机制是一种使用大页的方法,与THP(transparent huge page)是两种完全不同的机制,它需要:
- 管理员通过系统接口reserve一定量的大页,
- 用户通过hugetlbfs申请使用大页,
核心组件如下图:
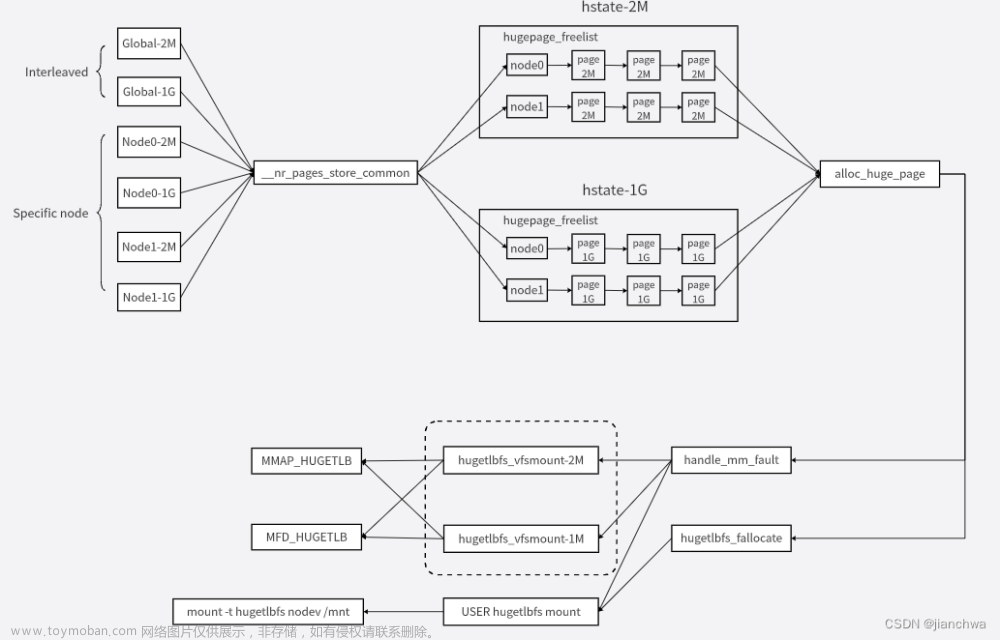
围绕着保存大页的核心数据结构hstate,
- 不同的系统接口,通过__nr_pages_store_common()将申请大页,并存入hstate;
- 不同的hugetlbfs挂载,通过alloc_huge_page()从hstate中申请大页使用;
下面,我们分别详解这些组件。
2.1 hstate
如上图中,hstate用于保存huge page,
关于hstate,参考以下代码:
struct hstate hstates[HUGE_MAX_HSTATE];
gigantic_pages_init()
---
/* With compaction or CMA we can allocate gigantic pages at runtime */
if (boot_cpu_has(X86_FEATURE_GBPAGES))
hugetlb_add_hstate(PUD_SHIFT - PAGE_SHIFT);
---
hugetlb_init()
---
hugetlb_add_hstate(HUGETLB_PAGE_ORDER);
if (!parsed_default_hugepagesz) {
...
default_hstate_idx = hstate_index(size_to_hstate(HPAGE_SIZE));
...
}
---
#define HPAGE_SHIFT PMD_SHIFT
#define HUGETLB_PAGE_ORDER (HPAGE_SHIFT - PAGE_SHIFT)
default_hugepagesz_setup()
---
...
default_hstate_idx = hstate_index(size_to_hstate(size));
...
---
__setup("default_hugepagesz=", default_hugepagesz_setup);其中有以下几个关键点:
- x86_64架构存在两个hstate,2M和1G
- 系统中存在一个default hstate,默认是2M的,可以通过kernel commandline设置;
我们在/proc/meminfoh中看到的:
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
HugePages开头的这几个都是default hstate的数据,换句话说,是2M的;1G的hugetlbs数据并不会体现在其中,参考代码:
hugetlb_report_meminfo()
---
for_each_hstate(h) {
unsigned long count = h->nr_huge_pages;
total += huge_page_size(h) * count;
if (h == &default_hstate)
seq_printf(m,
"HugePages_Total: %5lu\n"
"HugePages_Free: %5lu\n"
"HugePages_Rsvd: %5lu\n"
"HugePages_Surp: %5lu\n"
"Hugepagesize: %8lu kB\n",
count,
h->free_huge_pages,
h->resv_huge_pages,
h->surplus_huge_pages,
huge_page_size(h) / SZ_1K);
}
seq_printf(m, "Hugetlb: %8lu kB\n", total / SZ_1K);
---这我们再贴一段hstate处理hugepage的代码:
dequeue_huge_page_nodemask()
-> dequeue_huge_page_node_exact()
---
list_move(&page->lru, &h->hugepage_activelist);
set_page_refcounted(page);
ClearHPageFreed(page);
h->free_huge_pages--;
h->free_huge_pages_node[nid]--;
---
非常简单,链表维护,减少计数。
2.2 nr_hugepages
hugetlb需要系统管理员将一定量的内存reserve给hugetlb,可以通过以下途径:
- /proc/sys/vm/nr_hugepages,参考代码hugetlb_sysctl_handler_common(),它会向default_hstate注入大页,也就是2M;
- /sys/kernel/mm/hugepages/hugepages-size/nr_hugepages,这里可以指定size向2M或者1G的hstate注入大页,node策略为interleaved,
-
/sys/devices/system/node/node_id/hugepages/hugepages-size/nr_hugepages,通过该接口,不仅可以指定size,还可以指定node;
参考代码:
// /sys/kernel/mm/hugepages
hugetlb_sysfs_init()
---
hugepages_kobj = kobject_create_and_add("hugepages", mm_kobj);
...
for_each_hstate(h) {
err = hugetlb_sysfs_add_hstate(h, hugepages_kobj,
hstate_kobjs, &hstate_attr_group);
...
}
---
hugetlb_register_node()
---
struct node_hstate *nhs = &node_hstates[node->dev.id];
...
nhs->hugepages_kobj = kobject_create_and_add("hugepages",
&node->dev.kobj);
...
for_each_hstate(h) {
err = hugetlb_sysfs_add_hstate(h, nhs->hugepages_kobj,
nhs->hstate_kobjs,
&per_node_hstate_attr_group);
...
}
---
nr_hugepages_store_common()
---
h = kobj_to_hstate(kobj, &nid);
return __nr_hugepages_store_common(obey_mempolicy, h, nid, count, len);
---
static struct hstate *kobj_to_hstate(struct kobject *kobj, int *nidp)
{
int i;
for (i = 0; i < HUGE_MAX_HSTATE; i++)
if (hstate_kobjs[i] == kobj) {
if (nidp)
*nidp = NUMA_NO_NODE;
return &hstates[i];
}
return kobj_to_node_hstate(kobj, nidp);
}
另外,hugetlb还有overcommit功能,参考Redhat官方给出的解释:
/proc/sys/vm/nr_overcommit_hugepages
Defines the maximum number of additional huge pages that can be created and used by the system through overcommitting memory. Writing any non-zero value into this file indicates that the system obtains that number of huge pages from the kernel's normal page pool if the persistent huge page pool is exhausted. As these surplus huge pages become unused, they are then freed and returned to the kernel's normal page pool.
不过,在实践中,我们通常不会使用这个功能,hugetlb reserve的内存量都是经过预先计算的预留的;overcommit虽然提供了一定的灵活性,但是增加了不确定性。
2.3 hugetlbfs
hugetlb中的所有大页,都需要通过hugetlbfs以文件的形式呈现出来,供用户读写;接下来,我们先看下hugetlbfs的文件的使用方法。
const struct file_operations hugetlbfs_file_operations = {
.read_iter = hugetlbfs_read_iter,
.mmap = hugetlbfs_file_mmap,
.fsync = noop_fsync,
.get_unmapped_area = hugetlb_get_unmapped_area,
.llseek = default_llseek,
.fallocate = hugetlbfs_fallocate,
};hugetlbfs的文件并没有write_iter方法,如果我们用write系统调用操作该文件,会报错-EINVAL,具体原因可以索引代码中的FMODE_CAN_WRITE的由来;不过,hugetlbfs中的文件可以通过read系统调用读。fallocate回调存在意味着,我们可以预先通过fallocate给文件分配大页。另外,从hugetlb这个名字中我们就可以知道,它主要跟mmap有关,我们看下关键代码实现:
handle_mm_fault()
-> hugetlb_fault()
-> hugetlb_no_page()
-> alloc_huge_page()
hugetlbfs_fallocate()
-> alloc_huge_page()所以,hugetlbfs的大页是从mmap后的pagefault分配或者fallocate提前分配好的;
关于hugetlbfs的大页的分配,还需要知道reserve的概念;
hugetlbfs_file_mmap()
-> hugetlb_reserve_pages()
-> hugetlb_acct_memory()
-> gather_surplus_pages()
---
needed = (h->resv_huge_pages + delta) - h->free_huge_pages;
if (needed <= 0) {
h->resv_huge_pages += delta;
return 0;
}
---
alloc_huge_page()
-> dequeue_huge_page_vma()
---
if (page && !avoid_reserve && vma_has_reserves(vma, chg)) {
SetHPageRestoreReserve(page);
h->resv_huge_pages--;
}
---
//如果是fallocate路径,avoid_reserve就是truehugetlb_acct_memory()用于执行reserve,但是并不会真的分配;
这里并不是文件系统的delay allocation功能,大页的累计有明确的数量和对齐要求;reserve只是为了符合mmap的语义,即mmap时不会分配内存,page fault才分配;
hugetlbfs的mount参数中有一个min_size,可以直接在mount的时候reserve大页,如下:
hugepage_new_subpool()
---
spool->max_hpages = max_hpages;
spool->hstate = h;
spool->min_hpages = min_hpages;
if (min_hpages != -1 && hugetlb_acct_memory(h, min_hpages)) {
kfree(spool);
return NULL;
}
spool->rsv_hpages = min_hpages;
---而在实践中,这也没有必要;与overcommit类似,hugetlb最关键的特性就是确定性,它能确保用户可以使用到huge page,所以,资源都是提供计算预留好的,甚至包括,哪个进程能用多少等,所以,做这种mount reserve没有意义。
hugetlbfs除了用户通过mount命令挂载的,系统还给每个hstate一个默认挂载;
init_hugetlbfs_fs()
---
/* default hstate mount is required */
mnt = mount_one_hugetlbfs(&default_hstate);
...
hugetlbfs_vfsmount[default_hstate_idx] = mnt;
/* other hstates are optional */
i = 0;
for_each_hstate(h) {
if (i == default_hstate_idx) {
i++;
continue;
}
mnt = mount_one_hugetlbfs(h);
if (IS_ERR(mnt))
hugetlbfs_vfsmount[i] = NULL;
else
hugetlbfs_vfsmount[i] = mnt;
i++;
}
--
hugetlb_file_setup()
---
hstate_idx = get_hstate_idx(page_size_log);
...
mnt = hugetlbfs_vfsmount[hstate_idx];
...
inode = hugetlbfs_get_inode(mnt->mnt_sb, NULL, S_IFREG | S_IRWXUGO, 0);
...
---
ksys_mmap_pgoff()
---
if (!(flags & MAP_ANONYMOUS)) {
...
} else if (flags & MAP_HUGETLB) {
...
hs = hstate_sizelog((flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
...
len = ALIGN(len, huge_page_size(hs));
...
file = hugetlb_file_setup(HUGETLB_ANON_FILE, len,
VM_NORESERVE,
&ucounts, HUGETLB_ANONHUGE_INODE,
(flags >> MAP_HUGE_SHIFT) & MAP_HUGE_MASK);
...
}
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
---
memfd_create()
---
...
if (flags & MFD_HUGETLB) {
...
file = hugetlb_file_setup(name, 0, VM_NORESERVE, &ucounts,
HUGETLB_ANONHUGE_INODE,
(flags >> MFD_HUGE_SHIFT) &
MFD_HUGE_MASK);
}
...
fd_install(fd, file);
---默认hugetlbfs挂载主要用于:
- memfd,MEMFD_HUGETLB,直接从hugetlb中申请大页,创建匿名mem文件;
- mmap,MMAP_HUGETLB,直接总hugetlb中申请大页,mmap到程序中;
3 THP
hugetlbfs需要系统管理员提前预留内存,并且需要通过mmap将来自hugetlbfs的文件映射金进程地址空间,这就需要修改原来的代码;而Transparent Huge Page,则不需要对代码做任何修改,系统会自动为其分配大页。
THP机制目前仅对匿名页和tmpfs生效,且匿名页仅支持PMD级别(x86_64 2M);它有两个控制接口:
- /sys/kernel/mm/transparent_hugepage/enabled,有三个选项,
- always,所有任务的所有内存都使用大页
- madvise,仅MADV_HUGEPAGE区域使用THP
- never,从不使用THP
- /sys/kernel/mm/transparent_hugepage/defrag,有以下选项:
- "always" means that an application requesting THP will stall on allocation failure and directly reclaim pages and compact memory in an effort to allocate a THP immediately.
- "defer" means that an application will wake kswapd in the background to reclaim pages and wake kcompactd to compact memory so that THP is available in the near future. It's the responsibility of khugepaged to then install the THP pages later.
- "defer+madvise" will enter direct reclaim and compaction like "always", but only for regions that have used madvise(MADV_HUGEPAGE); all other regions will wake kswapd in the background to reclaim pages and wake kcompactd to compact memory so that THP is available in the near future.
- "madvise" will enter direct reclaim like "always" but only for regions that are have used madvise(MADV_HUGEPAGE). This is the default behaviour.
- "never" should be self-explanatory.
下面我们分别看下它们是如何实现的。
3.1 enabled
THP的控制参考如下代码路径:
__handle_mm_fault()
---
if (pud_none(*vmf.pud) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pud(&vmf);
---
/* No support for anonymous transparent PUD pages yet */
if (vma_is_anonymous(vmf->vma))
goto split;
if (vmf->vma->vm_ops->huge_fault) {
vm_fault_t ret = vmf->vma->vm_ops->huge_fault(vmf, PE_SIZE_PUD);
...
}
---
} else {
...
}
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
...
if (pmd_none(*vmf.pmd) && __transparent_hugepage_enabled(vma)) {
ret = create_huge_pmd(&vmf);
}
...
---
static inline bool __transparent_hugepage_enabled(struct vm_area_struct *vma)
{
[Condion 1]
/*
* If the hardware/firmware marked hugepage support disabled.
*/
if (transparent_hugepage_flags & (1 << TRANSPARENT_HUGEPAGE_NEVER_DAX))
return false;
[Condion 2]
if (!transhuge_vma_enabled(vma, vma->vm_flags))
return false;
if (vma_is_temporary_stack(vma))
return false;
[Condion 3]
if (transparent_hugepage_flags & (1 << TRANSPARENT_HUGEPAGE_FLAG))
return true;
[Condion 4]
if (vma_is_dax(vma))
return true;
[Condion 5]
if (transparent_hugepage_flags &
(1 << TRANSPARENT_HUGEPAGE_REQ_MADV_FLAG))
return !!(vma->vm_flags & VM_HUGEPAGE);
return false;
}我们关注其中几个关键的控制条件:
- Condition 2,MADV_NOHUGEPAGE可以显式的禁止在某段地址的THP
- Condition 3,对应/sys/kernel/mm/transparent_hugepage/enabled为always
- Condition 4,对于DAX文件系统,则可忽略THP的enabled配置
- Condition 5,对应/sys/kernel/mm/transparent_hugepage/enabled为madvise
3.2 defrag
defrag用于控制,当任务没有申请到大页内存时,如代码注释中所说,not available immediately,接下来所采取的措施,参考代码:
/*
* always: directly stall for all thp allocations
* defer: wake kswapd and fail if not immediately available
* defer+madvise: wake kswapd and directly stall for MADV_HUGEPAGE, otherwise
* fail if not immediately available
* madvise: directly stall for MADV_HUGEPAGE, otherwise fail if not immediately
* available
* never: never stall for any thp allocation
*/
gfp_t vma_thp_gfp_mask(struct vm_area_struct *vma)
{
const bool vma_madvised = vma && (vma->vm_flags & VM_HUGEPAGE);
/* Always do synchronous compaction */
if (test_bit(TRANSPARENT_HUGEPAGE_DEFRAG_DIRECT_FLAG, &transparent_hugepage_flags))
return GFP_TRANSHUGE | (vma_madvised ? 0 : __GFP_NORETRY);
/* Kick kcompactd and fail quickly */
if (test_bit(TRANSPARENT_HUGEPAGE_DEFRAG_KSWAPD_FLAG, &transparent_hugepage_flags))
return GFP_TRANSHUGE_LIGHT | __GFP_KSWAPD_RECLAIM;
/* Synchronous compaction if madvised, otherwise kick kcompactd */
if (test_bit(TRANSPARENT_HUGEPAGE_DEFRAG_KSWAPD_OR_MADV_FLAG, &transparent_hugepage_flags))
return GFP_TRANSHUGE_LIGHT |
(vma_madvised ? __GFP_DIRECT_RECLAIM :
__GFP_KSWAPD_RECLAIM);
/* Only do synchronous compaction if madvised */
if (test_bit(TRANSPARENT_HUGEPAGE_DEFRAG_REQ_MADV_FLAG, &transparent_hugepage_flags))
return GFP_TRANSHUGE_LIGHT |
(vma_madvised ? __GFP_DIRECT_RECLAIM : 0);
return GFP_TRANSHUGE_LIGHT;
}这里我们关注的是该函数如何通过gfp flags实现控制的,主要有以下类型:
- directly stall,GFP_HUGEPAGE,GFP_HUGEPAGE_LIGHT | __GFP_DIRECT_RECLAIM
- defer,GFP_HUGEPAGE_LIGHT | __GFP_KSWAP_RECLAIM
- never,GFP_HUGEPAGE_LIGHT
看下以上gfp flags的定义:
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | \
__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)
__GFP_COMP,并不是compaction,而是compound,参考代码:
__GFP_COMP doesn't mean compaction but compound,
* %__GFP_COMP address compound page metadata.
prep_new_page()
---
if (order && (gfp_flags & __GFP_COMP))
prep_compound_page(page, order);
---
prep_compound_page()
---
__SetPageHead(page);
for (i = 1; i < nr_pages; i++) {
struct page *p = page + i;
p->mapping = TAIL_MAPPING;
set_compound_head(p, page);
}
set_compound_page_dtor(page, COMPOUND_PAGE_DTOR);
set_compound_order(page, order);
atomic_set(compound_mapcount_ptr(page), -1);
...
---
__GFP_COMP是告诉我们,申请来的高order page,以一个整体的形式使用。
其他几个flag,涉及篇幅较长,我们在接下来几个小节讨论。
3.3 migrate type
本小节与__GFP_MOVABLE关。
关于什么是migrate type,我们可以参考链接:Making kernel pages movable [LWN.net]https://lwn.net/Articles/650917/
中的一段话:
What you are suggesting does exist, and is called "grouping pages by mobility". Hugepage-large blocks of memory are marked with a "migratetype" as movable, unmovable, or reclaimable (for slab caches where freeing can be requested). All allocations declare their migratetype and the allocator tries to find free page in the matching block first.
关于movable,我们可以参考__GFP_MOVABLE的定义,
* %__GFP_MOVABLE (also a zone modifier) indicates that the page can be
* moved by page migration during memory compaction or can be reclaimed.
migrate type是为memory compaction服务的,是为了避免unmovable的page(例如内核组件申请的内存)在movable(例如匿名页、page cache等)的page block中形成unmovable的空洞,无法在后续的内存compaction中形成大块的连续内存。
内存在初始化时都是MIGRATE_MOVABLE的,参考代码:
memmap_init_zone_range()
---
memmap_init_range(end_pfn - start_pfn, nid, zone_id, start_pfn,
zone_end_pfn, MEMINIT_EARLY, NULL, MIGRATE_MOVABLE);
---如果申请内存时,没有申请到对应的类型,有一套fallback策略,
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};MIGRATE_RECLAMABLE可以参考其对应的gfp flags的定义:
* %__GFP_RECLAIMABLE is used for slab allocations that specify
* SLAB_RECLAIM_ACCOUNT and whose pages can be freed via shrinkers.reclaimable是unmovable分出的子类,它是可以通过shrinker进行回收的。
如果内核要申请unmovable或者reclaimable,则需要从movable中补充,参考代码:
__rmqueue_fallback()
-> steal_suitable_fallback()接下来我们看下内核的主要内存申请路径有关migrate type的gfp flag,
inode_init_always()
---
mapping_set_gfp_mask(mapping, GFP_HIGHUSER_MOVABLE);
---
do_anonymous_page()
-> alloc_zeroed_user_highpage_movable()
-> alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, vaddr)
__bread()
---
return __bread_gfp(bdev, block, size, __GFP_MOVABLE);
---
以上分别是page cahce、匿名页、buffer的申请路径。
3.4 memory migration
内存迁移是指,将某个page block上的busy的page内容迁移到空闲page,进而让整个page block变为free;它主要分为两步,isolate和migrate,参考代码:
isolate_migratepages()
---
low_pfn = fast_find_migrateblock(cc);
block_start_pfn = pageblock_start_pfn(low_pfn); // round down to pageblock_nr_pages
/* Only scan within a pageblock boundary */
block_end_pfn = pageblock_end_pfn(low_pfn); // round up
for (; block_end_pfn <= cc->free_pfn;
fast_find_block = false,
cc->migrate_pfn = low_pfn = block_end_pfn,
block_start_pfn = block_end_pfn,
block_end_pfn += pageblock_nr_pages) {
...
/* Perform the isolation */
if (isolate_migratepages_block(cc, low_pfn, block_end_pfn,
isolate_mode))
return ISOLATE_ABORT;
break;
}
---
#define pageblock_order HUGETLB_PAGE_ORDER
#define pageblock_nr_pages (1UL << pageblock_order)如代码中,它会以pageblock_nr_pages为单位,在x86_64平台上,它的值是2M,分别进行尝试isolate;扫描的起点和终点有compact_control的migrate_pfn和free_pfn成员规定;isolate的过程参考如下代码:
isolate_migratepages_block()
---
/* Time to isolate some pages for migration */
for (; low_pfn < end_pfn; low_pfn++) {
nr_scanned++;
page = pfn_to_page(low_pfn);
if (PageBuddy(page)) {
unsigned long freepage_order = buddy_order_unsafe(page);
if (freepage_order > 0 && freepage_order < MAX_ORDER)
low_pfn += (1UL << freepage_order) - 1;
continue;
}
...
if (!PageLRU(page)) {
if (unlikely(__PageMovable(page)) &&
!PageIsolated(page)) {
if (locked) {
unlock_page_lruvec_irqrestore(locked, flags);
locked = NULL;
}
if (!isolate_movable_page(page, isolate_mode))
goto isolate_success;
}
goto isolate_fail;
}
...
/* Try isolate the page */
if (!TestClearPageLRU(page))
goto isolate_fail_put;
lruvec = mem_cgroup_page_lruvec(page);
...
/* Successfully isolated */
del_page_from_lru_list(page, lruvec);
...
}
---迁移主要针对的是movable的page,这类page大多都在lru上,我们需要将其从lru上取下。
迁移过程有函数__unmap_and_move()完成,其主要有两步unmap和move,
__unmap_and_move
-> try_to_migrate()
-> try_to_migrate_one()
-> make_writable_migration_entry()/make_readable_migration_entry()
do_swap_page()
---
if (!pte_unmap_same(vmf))
goto out;
...
entry = pte_to_swp_entry(vmf->orig_pte);
if (unlikely(non_swap_entry(entry))) {
if (is_migration_entry(entry)) {
migration_entry_wait(vma->vm_mm, vmf->pmd,
vmf->address);
...
}
...
}
---
-> __migration_entry_wait()
-> put_and_wait_on_page_locked(page, TASK_UNINTERRUPTIBLE);执行unmap之后,会在原pte中存一个migration entry,当任务执行到该page时,会触发page fault,并最终进入do_swap_page(),在其中,它会等待原page unlock;当迁移copy完成之后,任务醒来,会退出page fault路径,由于pte entry已经被pte_unmap_same()清掉,再次进入page fault时,会进入正常的匿名页page fault路径。
move的执行通过一下路径:
move_to_new_page()
-> mapping->a_ops->migratepage()
iomap_migrate_page()
-> migrate_page_move_mapping()
-> migrate_page_copy()
-> copy_highpage()
-> migrate_page_states()匿名页和文件页都会最终走到migrate_page_move_mapping();注意,对于文件页,它并没有直接丢掉,而是执行了拷贝。
3.5 memory compaction
本小节与__GFP_KSWAP_RECLAIM与__GFP_DIRECT_RECLAIM有关;首先看下alloc page slow path,
__alloc_pages_slowpath()
---
/*
* For costly allocations, try direct compaction first, as it's likely
* that we have enough base pages and don't need to reclaim. For non-
* movable high-order allocations, do that as well, as compaction will
* try prevent permanent fragmentation by migrating from blocks of the
* same migratetype.
* Don't try this for allocations that are allowed to ignore
* watermarks, as the ALLOC_NO_WATERMARKS attempt didn't yet happen.
*/
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
...
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
...
/* Caller is not willing to reclaim, we can't balance anything */
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* Try direct reclaim and then allocating */
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* Try direct compaction and then allocating */
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
if (gfp_mask & __GFP_NORETRY)
goto nopage;
/*
* Do not retry costly high order allocations unless they are
* __GFP_RETRY_MAYFAIL
*/
if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))
goto nopage;
...
/* Reclaim has failed us, start killing things */
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
---
从代码中我们得到,对于大页场景,order = 9,costly_order
- 如果允许direct reclaim,直接尝试compaction,避免内存direct/kswapd内存回收;
- 不会触发OOM
如果需要触发kswap,
wakeup_kswapd()
---
/* Hopeless node, leave it to direct reclaim if possible */
if (pgdat->kswapd_failures >= MAX_RECLAIM_RETRIES ||
(pgdat_balanced(pgdat, order, highest_zoneidx) &&
!pgdat_watermark_boosted(pgdat, highest_zoneidx))) {
/*
* There may be plenty of free memory available, but it's too
* fragmented for high-order allocations. Wake up kcompactd
* and rely on compaction_suitable() to determine if it's
* needed. If it fails, it will defer subsequent attempts to
* ratelimit its work.
*/
if (!(gfp_flags & __GFP_DIRECT_RECLAIM))
wakeup_kcompactd(pgdat, order, highest_zoneidx);
return;
}
---
如果该node的watermark是OK的,就会唤醒kcompactd,进行后台compaction;
那么后台的kcompactd什么时间停止呢?这取决于它的发起方式,参考代码:
__compact_finished()
---
/* Compaction run completes if the migrate and free scanner meet */
if (compact_scanners_met(cc)) {
[Condition 0]
}
if (cc->proactive_compaction) {
[Condition 1]
}
/* Direct compactor: Is a suitable page free? */
ret = COMPACT_NO_SUITABLE_PAGE;
for (order = cc->order; order < MAX_ORDER; order++) {
...
/* Job done if page is free of the right migratetype */
if (!free_area_empty(area, migratetype))
return COMPACT_SUCCESS;
[ Condition 2 ]
}
---
- condition 0,搜索完整个设定的范围,/proc/sys/vm/compact_memory
- condition 1,碎片化指数,/proc/sys/vm/compaction_proactiveness
- condition 2,至少有一个符合条件的高order page
3.6 khugepaged
defrag的defer策略,如果在内存申请路径没有申请到huge page,会唤醒kcompactd,并暂时fallback到普通page;在系统kcompactd获得huge page之后,由khugepaged将原任务的普通page替换为huge page,其流程大致如下:
首先需要将任务的vma发送给khugepaged,参考代码,
do_huge_pmd_anonymous_page()
-> khugepaged_enter()
-> alloc_hugepage_vma()
hugepage_madvise()
-> MADV_HUGEPAGE
khugepaged_enter_vma_merge()
-> khugepaged_enter()
vma_merge()
-> khugepaged_enter_vma_merge()
-> khugepaged_enter()khugepaged申请huge page的路径如下:文章来源:https://www.toymoban.com/news/detail-739893.html
khugepaged_do_scan()
-> khugepaged_scan_mm_slot()
-> khugepaged_scan_pmd()
-> collapse_huge_page()
-> alloc_hugepage_khugepaged_gfpmask() | __GFP_THISNODE
-> khugepaged_alloc_page()
static inline gfp_t alloc_hugepage_khugepaged_gfpmask(void)
{
return khugepaged_defrag() ? GFP_TRANSHUGE : GFP_TRANSHUGE_LIGHT;
}/sys/kernel/mm/transparent_hugepage/khugepaged/defrag用来控制khugepaged申请方式。文章来源地址https://www.toymoban.com/news/detail-739893.html
到了这里,关于hugetlb核心组件的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[1Panel]开源,现代化,新一代的 Linux 服务器运维管理面板](https://imgs.yssmx.com/Uploads/2024/02/722869-1.png)