背景
最近在做一些工具的预研工作,会涉及到对工具的压力测试,分析工具的资源消耗等问题,其中CPU 资源消耗是关键指标之一。为了后续性能优化做准备,回顾了以前相关CPU优化知识,并做总结分享。希望能帮助到正在遇到相关问题的同事。
CPU 使用率
cpu 使用率,是我们做嵌入式开发者,经常会遇到的一个性能指标。但是每个人对他的理解可能有点不一样。在这里按照我个人的理解,和大家简单介绍一下。
何为CPU 使用率
使用率:通常是指在一定时间内实际使用的资源或服务与可使用的资源或服务之间的比率。
CPU 使用率: 就是指一定时间内,CPU实际被占用的比例。那么核心问题来了, CPU 被占用之后,主要用来做什么了呢?
只有知道了CPU被用来做什么了,我们才有目标,有针对性的去优化。
CPU 消耗在哪里?
我们知道CPU的核心功能就是执行指令和处理数据。
从linux 系统中,代码的分类,我们可以分为执行用户态代码,执行内核态代码,执行中断程序代码。
另外,linux 是多任务操作系统,它支持远大于CPU数量的任务同时运行。当然这些任务不是真的同时运行,而是系统在很小的时间段内,将CPU 不断分配给任务,导致同时运行的错觉。每个任务运行前,CPU 需要知道从哪里加载,以及从哪里运行。也就是说操作系统需要需要提前设置好任务的CPU寄存器和程序计数器(PC)。这也是CPU的上下文。同理,任务的上下文切换,根据不同的场景,上下文切换的资源消耗也是不一样的。
- 进程上下文切换:包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态的资源备份和恢复。
- 线程上下文切换(前后线程是同一个进程):需要对线程的私有数据进行保存,比如线程寄存器,线程栈等。
- 中断上下文切换:只包括中断服务程序的所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
还有一种特殊的场景,那就是进程占用CPU,但是却不做任何事。那就是不可中断状态。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
| 综上所述, CPU 资源主要消耗在以下场景。
|
CPU性能分析工具
砍柴不误磨刀功。分析CPU性能问题时,可以利用一些工具,大大提高我们的效率。本节介绍几个好用的命令,其中可能有大家平时用到过,但是对于其参数也许并没有深入了解。
top
top命令是我们在分析性能问题时,常用到的一个工具。执行top -d 1 ,-d 参数表示更新频率。默认3s。
yihua@ubuntu:~$ top -d 1
top - 23:36:05 up 22:14, 4 users, load average: 0.48, 0.10, 0.03
Tasks: 330 total, 1 running, 253 sleeping, 0 stopped, 0 zombie
%Cpu(s): 9.9 us, 66.5 sy, 0.0 ni, 23.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 4013240 total, 1004708 free, 1293040 used, 1715492 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 2398648 avail Mem
Unknown command - try 'h' for help
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10612 yihua 20 0 120024 7940 6636 S 305.0 0.2 0:21.79 sysbench
10623 yihua 20 0 44380 4132 3328 R 1.0 0.1 0:00.03 top
1 root 20 0 225544 9332 6636 S 0.0 0.2 0:03.29 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
7 root 20 0 0 0 0 S 0.0 0.0 0:00.09 ksoftirqd/0
8 root 20 0 0 0 0 I 0.0 0.0 0:00.61 rcu_sched
9 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_bh
10 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
11 root rt 0 0 0 0 S 0.0 0.0 0:00.09 watchdog/0其中第一行:top - 23:36:05 up 22:14, 4 users, load average: 0.48, 0.10, 0.03
23:36:05 up 22:14, 4 users 当前系统时间,系统运行时间,4个用户登录。
load average: 0.48, 0.10, 0.03 系统1分钟,5分钟,15分钟的负载。通过该参数,可以判断当前系统整体资源运行状态。
第二行:Tasks: 330 total, 1 running, 253 sleeping, 0 stopped, 0 zombie
当前系统中共有330个任务,1个正在运行;253个处于休眠;0个处于停止,但是资源未回收;0个僵尸进程。
第三行:%Cpu(s): 9.9 us, 66.5 sy, 0.0 ni, 23.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
表示当前CPU的资源消耗状态。参数详情可参考以下。
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。即执行用户态代码。
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。执行用户态代码。
system(通常缩写为 sys),代表内核态 CPU 时间。执行内核态代码。
idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。进程不可中断状态持续时间。
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。执行硬中断代码。
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。执行软中断代码。
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
可知当前CPU资源主要消耗在内核态。
| 通过top 命令,我们可以知道关于CPU资源的以下信息。
|
vmstat
vmstat 是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
# 每隔5秒输出1组数据
yihua@ubuntu:~$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 985808 246852 1477912 0 0 4 3 1 123 0 0 100 0 0特别关注的四列内容:
cs(context switch)是每秒上下文切换的次数。
in(interrupt)则是每秒中断的次数。
r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
b(Blocked)则是处于不可中断睡眠状态的进程数。
这个例子中的上下文切换次数 cs 是 123 次,而系统中断次数 in 则是 1 次,而就绪队列长度 r 为1 ,不可中断状态进程数 b 都是 0。
| 通过vmstat 命令,我们可以在指定时间段内,得到以下信息。
|
pidstat
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。常用以下场景。
1. 查看所有进程CPU资源消耗,确认是哪一个进程导致的CPU性能问题
# 间隔5秒后输出一组数据
yihua@ubuntu:~$ pidstat -u 5 1
Linux 4.15.0-213-generic (ubuntu) 10/24/2023 _x86_64_ (4 CPU)
12:15:29 AM UID PID %usr %system %guest %wait %CPU CPU Command
12:15:35 AM 0 585 0.20 0.00 0.00 0.00 0.20 0 vmtoolsd
12:15:35 AM 0 879 0.20 0.00 0.00 0.00 0.20 1 snapd
12:15:35 AM 0 5480 0.00 0.20 0.00 0.00 0.20 2 kworker/2:1
12:15:35 AM 1000 11892 42.83 100.00 0.00 0.00 100.00 1 sysbench
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 585 0.20 0.00 0.00 0.00 0.20 - vmtoolsd
Average: 0 879 0.20 0.00 0.00 0.00 0.20 - snapd
Average: 0 5480 0.00 0.20 0.00 0.00 0.20 - kworker/2:1
Average: 1000 11892 42.83 100.00 0.00 0.00 100.00 - sysbench以上信息可得知,主要是sysbench 这个进程占用了资源,且主要消耗在内核态。该指令可以配合top 使用,若已明确系统CPU资源受限,可通过该命令确认是哪一个进程以及主要消耗在哪里。
2. 查看上下文切换的消耗,确认是哪一个进程或线程导致的CPU 问题
yihua@ubuntu:~$ pidstat -wt 5 1
Linux 4.15.0-213-generic (ubuntu) 10/24/2023 _x86_64_ (4 CPU)
12:24:55 AM UID TGID TID cswch/s nvcswch/s Command
12:25:00 AM 0 7 - 0.78 0.00 ksoftirqd/0
12:25:00 AM 0 - 7 0.78 0.00 |__ksoftirqd/0
12:25:00 AM 0 8 - 6.64 0.00 rcu_sched
12:25:00 AM 0 - 8 6.64 0.00 |__rcu_sched
12:25:00 AM 0 11 - 0.20 0.00 watchdog/0
12:25:00 AM 0 - 11 0.20 0.00 |__watchdog/0
12:25:00 AM 0 14 - 0.20 0.00 watchdog/1
12:25:00 AM 0 - 14 0.20 0.00 |__watchdog/1
12:25:00 AM 0 20 - 0.20 0.00 watchdog/2
12:25:00 AM 0 - 20 0.20 0.00 |__watchdog/2
12:25:00 AM 0 22 - 0.20 0.00 ksoftirqd/2
12:25:00 AM 0 - 22 0.20 0.00 |__ksoftirqd/2
12:25:00 AM 0 26 - 0.20 0.00 watchdog/3
12:25:00 AM 0 - 26 0.20 0.00 |__watchdog/3
12:25:00 AM 0 28 - 1.17 0.00 ksoftirqd/3
12:25:00 AM 0 - 28 1.17 0.00 |__ksoftirqd/3
12:25:00 AM 0 287 - 0.20 0.00 kworker/2:1H
12:25:00 AM 0 - 287 0.20 0.00 |__kworker/2:1H
12:25:00 AM 0 306 - 0.20 0.00 kworker/3:1H
12:25:00 AM 0 - 306 0.20 0.00 |__kworker/3:1H
12:25:00 AM 0 585 - 12.11 0.00 vmtoolsd
12:25:00 AM 0 - 585 12.11 0.00 |__vmtoolsd
12:25:00 AM 0 - 586 0.98 0.00 |__HangDetector
12:25:00 AM 0 - 877 0.39 0.00 |__gmain
12:25:00 AM 0 - 891 0.39 0.00 |__gmain
12:25:00 AM 0 900 - 0.20 0.00 irqbalance
12:25:00 AM 0 - 900 0.20 0.00 |__irqbalance
12:25:00 AM 0 902 - 0.20 0.00 wpa_supplicant
12:25:00 AM 0 - 902 0.20 0.00 |__wpa_supplicant
12:25:00 AM 0 - 1037 1.17 0.00 |__containerd
12:25:00 AM 0 - 1096 0.78 0.00 |__containerd
12:25:00 AM 0 - 3497 0.78 0.20 |__containerd
12:25:00 AM 121 1258 - 0.20 0.00 gnome-shell
12:25:00 AM 121 - 1258 0.20 0.00 |__gnome-shell
12:25:00 AM 121 1773 - 0.98 0.00 gsd-color
12:25:00 AM 121 - 1773 0.98 0.00 |__gsd-color
12:25:00 AM 1000 1957 - 0.20 0.00 Xorg
12:25:00 AM 1000 - 1957 0.20 0.00 |__Xorg
12:25:00 AM 1000 2104 - 0.78 0.59 gnome-shell
12:25:00 AM 1000 - 2104 0.78 0.59 |__gnome-shell
12:25:00 AM 1000 - 2110 1.37 0.00 |__llvmpipe-0
12:25:00 AM 1000 - 2111 1.56 0.00 |__llvmpipe-1
12:25:00 AM 1000 - 2112 1.76 0.00 |__llvmpipe-2
12:25:00 AM 1000 - 2113 1.37 0.00 |__llvmpipe-3
12:25:00 AM 1000 2268 - 0.98 0.00 gsd-color
12:25:00 AM 1000 - 2268 0.98 0.00 |__gsd-color
12:25:00 AM 1000 2335 - 10.16 0.00 vmtoolsd
12:25:00 AM 1000 - 2335 10.16 0.00 |__vmtoolsd
12:25:00 AM 1000 - 2729 0.20 0.00 |__gmain
12:25:00 AM 1000 - 2727 0.20 0.00 |__gmain
12:25:00 AM 0 5480 - 1.37 0.00 kworker/2:1
12:25:00 AM 0 - 5480 1.37 0.00 |__kworker/2:1
12:25:00 AM 0 9193 - 0.98 0.00 kworker/1:0
12:25:00 AM 0 - 9193 0.98 0.00 |__kworker/1:0
12:25:00 AM 0 9224 - 1.17 0.00 kworker/3:0
12:25:00 AM 0 - 9224 1.17 0.00 |__kworker/3:0
12:25:00 AM 0 10778 - 7.62 0.00 kworker/u256:0
12:25:00 AM 0 - 10778 7.62 0.00 |__kworker/u256:0
12:25:00 AM 0 11010 - 0.98 0.00 kworker/0:4
12:25:00 AM 0 - 11010 0.98 0.00 |__kworker/0:4
12:25:00 AM 0 11946 - 1.95 0.00 kworker/u256:3
12:25:00 AM 0 - 11946 1.95 0.00 |__kworker/u256:3
12:25:00 AM 1000 - 11952 21298.44 184419.14 |__sysbench
12:25:00 AM 1000 - 11953 19585.35 192591.21 |__sysbench
12:25:00 AM 1000 - 11954 20186.52 173420.90 |__sysbench
12:25:00 AM 1000 - 11955 20158.59 193855.27 |__sysbench
12:25:00 AM 1000 - 11956 19719.34 178251.37 |__sysbench
12:25:00 AM 1000 - 11957 20934.38 162003.52 |__sysbench
12:25:00 AM 1000 - 11958 22238.48 162588.67 |__sysbench
12:25:00 AM 1000 - 11959 19943.55 181168.75 |__sysbench
12:25:00 AM 1000 - 11960 20675.00 177943.16 |__sysbench
12:25:00 AM 1000 - 11961 20960.35 183560.94 |__sysbench
12:25:00 AM 1000 11962 - 0.20 229.10 pidstat
12:25:00 AM 1000 - 11962 0.20 229.49 |__pidstat
Average: UID TGID TID cswch/s nvcswch/s Command
Average: 0 7 - 0.78 0.00 ksoftirqd/0
Average: 0 - 7 0.78 0.00 |__ksoftirqd/0
Average: 0 8 - 6.64 0.00 rcu_sched
Average: 0 - 8 6.64 0.00 |__rcu_sched
Average: 0 11 - 0.20 0.00 watchdog/0
Average: 0 - 11 0.20 0.00 |__watchdog/0
Average: 0 14 - 0.20 0.00 watchdog/1
Average: 0 - 14 0.20 0.00 |__watchdog/1
Average: 0 20 - 0.20 0.00 watchdog/2
Average: 0 - 20 0.20 0.00 |__watchdog/2
Average: 0 22 - 0.20 0.00 ksoftirqd/2
Average: 0 - 22 0.20 0.00 |__ksoftirqd/2
Average: 0 26 - 0.20 0.00 watchdog/3
Average: 0 - 26 0.20 0.00 |__watchdog/3
Average: 0 28 - 1.17 0.00 ksoftirqd/3
Average: 0 - 28 1.17 0.00 |__ksoftirqd/3
Average: 0 287 - 0.20 0.00 kworker/2:1H
Average: 0 - 287 0.20 0.00 |__kworker/2:1H
Average: 0 306 - 0.20 0.00 kworker/3:1H
Average: 0 - 306 0.20 0.00 |__kworker/3:1H
Average: 0 585 - 12.11 0.00 vmtoolsd
Average: 0 - 585 12.11 0.00 |__vmtoolsd
Average: 0 - 586 0.98 0.00 |__HangDetector
Average: 0 - 877 0.39 0.00 |__gmain
Average: 0 - 891 0.39 0.00 |__gmain
Average: 0 900 - 0.20 0.00 irqbalance
Average: 0 - 900 0.20 0.00 |__irqbalance
Average: 0 902 - 0.20 0.00 wpa_supplicant
Average: 0 - 902 0.20 0.00 |__wpa_supplicant
Average: 0 - 1037 1.17 0.00 |__containerd
Average: 0 - 1096 0.78 0.00 |__containerd
Average: 0 - 3497 0.78 0.20 |__containerd
Average: 121 1258 - 0.20 0.00 gnome-shell
Average: 121 - 1258 0.20 0.00 |__gnome-shell
Average: 121 1773 - 0.98 0.00 gsd-color
Average: 121 - 1773 0.98 0.00 |__gsd-color
Average: 1000 1957 - 0.20 0.00 Xorg
Average: 1000 - 1957 0.20 0.00 |__Xorg
Average: 1000 2104 - 0.78 0.59 gnome-shell
Average: 1000 - 2104 0.78 0.59 |__gnome-shell
Average: 1000 - 2110 1.37 0.00 |__llvmpipe-0
Average: 1000 - 2111 1.56 0.00 |__llvmpipe-1
Average: 1000 - 2112 1.76 0.00 |__llvmpipe-2
Average: 1000 - 2113 1.37 0.00 |__llvmpipe-3
Average: 1000 2268 - 0.98 0.00 gsd-color
Average: 1000 - 2268 0.98 0.00 |__gsd-color
Average: 1000 2335 - 10.16 0.00 vmtoolsd
Average: 1000 - 2335 10.16 0.00 |__vmtoolsd
Average: 1000 - 2729 0.20 0.00 |__gmain
Average: 1000 - 2727 0.20 0.00 |__gmain
Average: 0 5480 - 1.37 0.00 kworker/2:1
Average: 0 - 5480 1.37 0.00 |__kworker/2:1
Average: 0 9193 - 0.98 0.00 kworker/1:0
Average: 0 - 9193 0.98 0.00 |__kworker/1:0
Average: 0 9224 - 1.17 0.00 kworker/3:0
Average: 0 - 9224 1.17 0.00 |__kworker/3:0
Average: 0 10778 - 7.62 0.00 kworker/u256:0
Average: 0 - 10778 7.62 0.00 |__kworker/u256:0
Average: 0 11010 - 0.98 0.00 kworker/0:4
Average: 0 - 11010 0.98 0.00 |__kworker/0:4
Average: 0 11946 - 1.95 0.00 kworker/u256:3
Average: 0 - 11946 1.95 0.00 |__kworker/u256:3
Average: 1000 - 11952 21298.44 184419.14 |__sysbench
Average: 1000 - 11953 19585.35 192591.21 |__sysbench
Average: 1000 - 11954 20186.52 173420.90 |__sysbench
Average: 1000 - 11955 20158.59 193855.27 |__sysbench
Average: 1000 - 11956 19719.34 178251.37 |__sysbench
Average: 1000 - 11957 20934.38 162003.52 |__sysbench
Average: 1000 - 11958 22238.48 162588.67 |__sysbench
Average: 1000 - 11959 19943.55 181168.75 |__sysbench
Average: 1000 - 11960 20675.00 177943.16 |__sysbench
Average: 1000 - 11961 20960.35 183560.94 |__sysbench
Average: 1000 11962 - 0.20 229.10 pidstat
Average: 1000 - 11962 0.20 229.49 |__pidstat
由上可知,该命令可以配合vmstat 使用, 因为vmstat 仅能描述系统整体的上下文切换信息。而pidstat可以精确到具体的线程或进程。
| 通过pidstat 命令,我们确认以下信息。
|
dstat
dstat 是一个新的性能工具,它吸收了 vmstat、iostat、ifstat 等几种工具的优点,可以同时观察系统的 CPU、磁盘 I/O、网络以及内存使用情况。
yihua@ubuntu:~$ dstat 1 10
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
0 1 99 0 0| 15k 12k| 0 0 | 0 0 |1186 24k
0 0 100 0 0| 0 0 | 120B 178B| 0 0 | 80 111
0 0 0 100 0| 30M 0 | 120B 178B| 0 0 | 53 85
0 0 100 0 0| 0 0 | 60B 118B| 0 0 | 47 81
0 0 100 0 0| 0 0 | 60B 118B| 0 0 | 37 63
0 0 100 0 0| 0 0 | 60B 118B| 0 0 | 52 89
1 0 99 0 0| 0 0 | 120B 178B| 0 0 | 79 198
0 0 100 0 0| 0 0 | 210B 236B| 0 0 | 48 72
0 0 100 0 0| 0 0 | 60B 118B| 0 0 | 49 86
0 0 100 0 0| 0 0 | 60B 118B| 0 0 | 55 87由上可知,当I/O wait 为100%时,分析 磁盘 ,网卡,换页,中断等数据,可以得知当前是在读取磁盘的数据变慢了。造成了阻塞。
| 通过dstat 命令,可以确认I/O的性能瓶颈具体产生在哪个硬件设备 |
perf
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。可以帮助我们进一步定位具体的代码或函数。
常用的方式有两种。
- perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
SQL
Samples: 1K of event 'cpu-clock', Event count (approx.): 120772854
Overhead Shared Object Symbol
31.51% perf [.] d_demangle_callback
9.68% [kernel] [k] _raw_spin_unlock_irqrestore
6.76% perf [.] __symbols__insert
6.15% [kernel] [k] mpt_put_msg_frame
5.77% [kernel] [k] __softirqentry_text_start
5.68% libelf-0.170.so [.] gelf_getsym
3.82% perf [.] rb_next
1.26% perf [.] rb_insert_color
1.07% libc-2.27.so [.] _int_malloc
1.04% libc-2.27.so [.] calloc
0.90% [kernel] [k] clear_page_orig
0.87% [kernel] [k] e1000_xmit_frame
0.87% [kernel] [k] exit_to_usermode_loop
0.79% [kernel] [k] radix_tree_next_chunk
0.69% libmozjs-52.so.0.0.0 [.] JS::UnmarkGrayGCThingRecursively
0.68% libc-2.27.so [.] __libc_malloc
0.63% libmozjs-52.so.0.0.0 [.] js::UnsafeTraceManuallyBarrieredEdge<JSObject*>
0.63% perf [.] dso__load_sym
0.62% perf [.] __demangle_java_sym
0.62% perf [.] java_demangle_sym
0.49% [kernel] [k] filemap_map_pages
0.48% [kernel] [k] get_page_from_freelist
0.48% libc-2.27.so [.] __strrchr_avx2
0.46% libelf-0.170.so [.] elf_fill
0.42% [kernel] [k] finish_task_switch
0.41% [kernel] [k] __do_page_fault
0.41% libelf-0.170.so [.] gelf_update_verdaux
0.39% libslang.so.2.3.1 [.] SLerrno_strerror
0.35% libmozjs-52.so.0.0.0 [.] js::gc::EdgeNeedsSweep<jsid>
0.35% [kernel] [k] arch_local_irq_enable
0.32% [kernel] [k] queue_work_on
0.32% [kernel] [k] kallsyms_expand_symbol.constprop.1
0.28% libc-2.27.so [.] __strlen_avx2
0.27% perf [.] dso__find_symbol
0.25% libc-2.27.so [.] __memcpy_avx_unaligned_erms
0.25% [kernel] [k] kmem_cache_alloc
0.23% libelf-0.170.so [.] gelf_getrela
0.21% perf [.] cplus_demangle
0.21% [kernel] [k] handle_mm_fault
0.21% containerd [.] fmt.(*pp).doPrintf
0.21% libelf-0.170.so [.] gelf_getphdr
0.21% libpthread-2.27.so [.] pthread_mutex_init
0.21% perf [.] arch__sym_update
0.21% perf [.] elf_read_build_id
0.21% perf [.] symbols__fixup_duplicate.part.2
0.21% perf [.] symbols__fixup_end
0.20% perf [.] dso__loaded
0.20% [kernel] [k] find_inode_fast
0.20% libmozjs-52.so.0.0.0 [.] std::__adjust_heap<unsigned int*, long, unsigned int, __gnu_cxx::__ops::_Iter_less_iter>
0.19% libc-2.27.so [.] cfree@GLIBC_2.2.5
0.16% perf [.] map__find_symbol
0.16% libmozjs-52.so.0.0.0 [.] js::SetWindowProxy
0.16% [kernel] [k] _raw_spin_lock
0.15% [kernel] [k] update_iter
0.15% libvmtools.so.0.0.0 [.] Backdoor_InOut由上可知,perf 中的 d_demangle_callback 函数被调用频率较高,我们则可以从该接口入手,进行优化。
2. perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
SQL
yihua@ubuntu:~$ sudo perf record
^C[ perf record: Woken up 53 times to write data ]
[ perf record: Captured and wrote 14.481 MB perf.data (289019 samples) ]
yihua@ubuntu:~$ ls
c++ ekuiper-demo emqtt-bench emqx mi-ota nanoMQ perf.data presureTest sysstat test toolchain tranning vdi vsomeip
yihua@ubuntu:~$ perf report
failed to open perf.data: Permission denied
yihua@ubuntu:~$ sudo perf report
Samples: 289K of event 'cpu-clock', Event count (approx.): 72254750000
Overhead Command Shared Object Symbol
36.13% sysbench [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
26.80% swapper [kernel.kallsyms] [k] native_safe_halt
11.08% sysbench [kernel.kallsyms] [k] __schedule
5.69% sysbench [kernel.kallsyms] [k] finish_task_switch
5.34% sysbench [kernel.kallsyms] [k] do_syscall_64
3.30% sysbench [kernel.kallsyms] [k] sys_sched_yield
3.10% sysbench libpthread-2.27.so [.] pthread_mutex_unlock
2.96% sysbench libc-2.27.so [.] sched_yield
1.71% sysbench libpthread-2.27.so [.] __pthread_mutex_lock
0.62% sysbench [kernel.kallsyms] [k] exit_to_usermode_loop
0.58% sysbench sysbench [.] crc32
0.43% sysbench [kernel.kallsyms] [k] schedule
0.24% swapper [kernel.kallsyms] [k] finish_task_switch
0.23% swapper [kernel.kallsyms] [k] tick_nohz_idle_enter
0.20% sysbench libpthread-2.27.so [.] __lll_lock_wait
0.14% swapper [kernel.kallsyms] [k] __softirqentry_text_start
0.12% swapper [kernel.kallsyms] [k] tick_nohz_idle_exit
0.09% Xorg [kernel.kallsyms] [k] exit_to_usermode_loop
0.08% sysbench sysbench [.] pthread_yield@plt
0.07% sysbench [kernel.kallsyms] [k] futex_wake
0.06% sysbench [kernel.kallsyms] [k] futex_wait
0.06% sysbench libpthread-2.27.so [.] pthread_yield
0.06% sysbench [kernel.kallsyms] [k] sys_futex
0.06% sysbench libpthread-2.27.so [.] sched_yield@plt
0.05% sysbench [kernel.kallsyms] [k] futex_wait_queue_me
0.05% sysbench libpthread-2.27.so [.] __lll_unlock_wake
0.04% sysbench [kernel.kallsyms] [k] _raw_spin_lock
0.04% sysbench [kernel.kallsyms] [k] mark_wake_futex
0.04% swapper [kernel.kallsyms] [k] do_idle
0.04% sysbench [kernel.kallsyms] [k] do_futex
0.03% sysbench libm-2.27.so [.] __ieee754_log_fma
0.03% sysbench sysbench [.] pthread_mutex_unlock@plt
0.03% sysbench sysbench [.] sb_histogram_update
0.03% sysbench [kernel.kallsyms] [k] futex_wait_setup
0.03% sysbench sysbench [.] sb_event_stop
0.03% sysbench [kernel.kallsyms] [k] get_futex_key_refs.isra.11
0.02% Xorg libpixman-1.so.0.34.0 [.] _pixman_internal_only_get_implementation
0.02% sysbench [kernel.kallsyms] [k] __unqueue_futex
0.02% sysbench [kernel.kallsyms] [k] get_futex_value_locked
0.02% nautilus-deskto [kernel.kallsyms] [k] exit_to_usermode_loop
0.02% sysbench [kernel.kallsyms] [k] hash_futex
0.02% sysbench [kernel.kallsyms] [k] get_futex_key
0.02% swapper [kernel.kallsyms] [k] __schedule
0.02% sysbench [kernel.kallsyms] [k] __softirqentry_text_start
0.02% swapper [kernel.kallsyms] [k] rcu_idle_exit
0.02% sysbench [kernel.kallsyms] [k] native_queued_spin_lock_slowpath
0.02% sysbench [kernel.kallsyms] [k] wake_q_add
0.01% sysbench libc-2.27.so [.] clock_gettime
0.01% sysbench [kernel.kallsyms] [k] plist_add
0.01% swapper [kernel.kallsyms] [k] arch_cpu_idle
0.01% sysbench [vdso] [.] __vdso_clock_gettime
0.01% sysbench [kernel.kallsyms] [k] wake_up_q
0.01% swapper [kernel.kallsyms] [k] __cpuidle_text_start
0.01% swapper [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.01% swapper [kernel.kallsyms] [k] schedule_idle由上可知sysbench 进程中的 内核态 的 _raw_spin_unlock_irqrestore 接口调用最频繁。
| 通过perf命令,可以快速定位到热点代码,帮助我们确定优化范围。 |
CPU性能分析定位套路
我们已经知道了哪些场景会使用到CPU。执行用户态代码,执行内核态代码,执行中断程序代码,任务的上下文切换,进程处于不可中断状态。定位相关场景的工具。top,vmstat,pidstat,dstat,perf。
根据以上知识点,当我们遇到CPU 性能瓶颈时,有一个快速定位问题的套路。思路如下图:
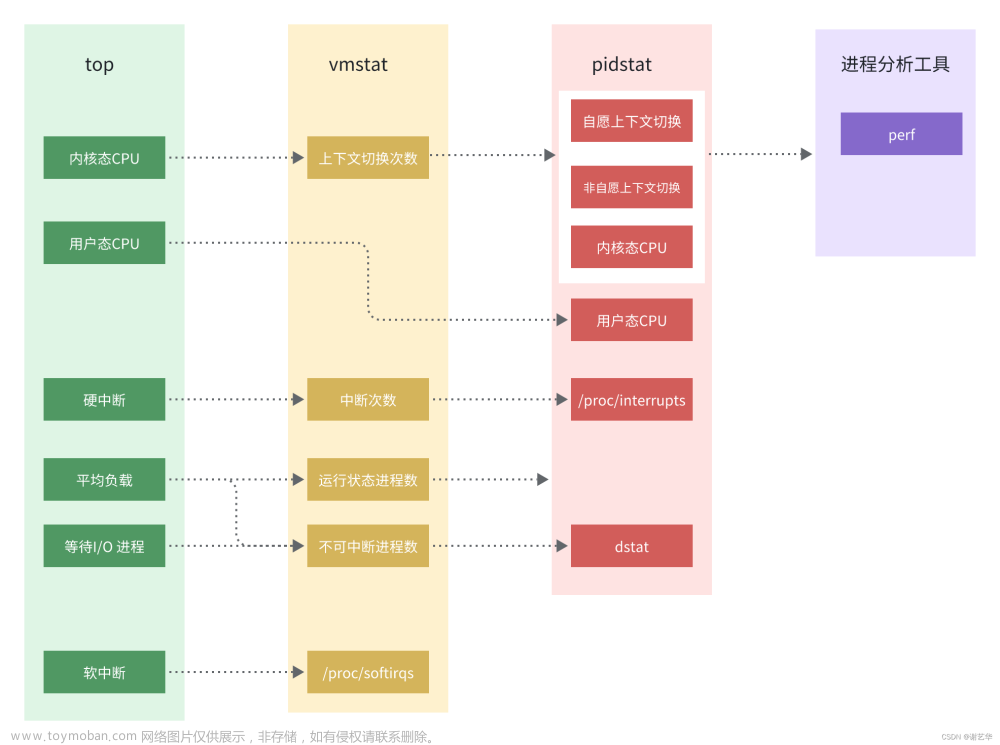
通过top命令,分析获取系统整体的CPU资源消耗。判断集中消耗在哪里,即关注以下信息。
- 内核态(sy)。系统内核态占用比较高。有两种情况:上下文切换频繁,导致资源的消耗;进程内核代码执行频繁,比如驱动代码,系统调用等。
- 通过vmstat 1 3 查看当前系统上下文切换次数是否异常。若异常则说明,大量的CPU资源消耗在上下文切换。
- 通过pidstat -uwt 1 10 查看当前所有进程占用的CPU 资源以及上下文切换频率。确定异常进程。
- 最终通过perf record+perf report定位热点代码块。
- 用户态(us+ni)。若用户态占用比较高,说明程序中存在大量的计算。
- 通过pidstat -u 1 10 查看所有进程占用的CPU资源,确定异常进程。
- 最终通过perf record+perf report定位热点代码块。
- 通过pidstat -u 1 10 查看所有进程占用的CPU资源,确定异常进程。
- 硬中断(hi)。硬中断若占用比较高,存在两种可能:中断处理函数耗时较多;中断源触发频繁。
- 通过vmstat 1 3 查看当前系统中断次数是否异常。若异常则说明又由于真实的硬件中断触发导致的。
- 若中断次数处于正常范围,则说明中断处理接口可能出现了问题。
- 通过cat /proc/interrupts 定位的中断源,确认频率是否正常或分析对应驱动。
- 平均负载比较高。若负载比较高,直观的现象就是,有些进程可能运行卡顿,比如ssh 客户端。平均负载计算两类进程:运行状态进程,不可中断状态进程。
- 通过vmstat 1 3 查看当前运行状态和不可中断状态进程数。若运行状态进程数较多,则说明当前的确有很多进程需要运行,且是因为CPU 资源性能不足。
- 针对这种情况,我们可以直接通过pidstat -u 1 5定位相关进程。
- 若当前不可中断状态进程数较多,说明当前出现了I/O 瓶颈。可通过dstat 1 10确认磁盘读写,网络收发,内存换页等I/O瓶颈。
- 通过vmstat 1 3 查看当前运行状态和不可中断状态进程数。若运行状态进程数较多,则说明当前的确有很多进程需要运行,且是因为CPU 资源性能不足。
- 等待I/O比较高(wa)。与上述类似,可通过dstat 1 10确认磁盘读写,网络收发,内存换页等I/O瓶颈。
- 软中断(si)。可通过cat /proc/softirqs 查看是哪一类软中断触发频繁。
以上的套路是我个人的理解,当然还有一些其他场景没有包含,但是应该可以适用我们实际工作中90%的场景了。
常见的优化措施
当我们定位到CPU 性能瓶颈之后,下一步操作就是如何优化。在这里根据分享一下我的经验,有好的场景或好的措施,也欢迎补充。
应用程序优化
若定位到性能瓶颈在用户态代码后,我们可以尝试从以下几方面入手。
- 编码的角度。排除所有不必要的工作,只保留核心逻辑。比如减少循环的层次、减少递归、减少动态内存分配等等
- 编译器优化。很多编译器都会提供编译优化选项,适当开启它们,在编译阶段可以获得帮助。比如,gcc 提供了优化选项-O2,开启之后会自动对程序进行优化。
- 算法优化。使用复杂度更低的算法,可以显著提供运算速度。比如在大数据量的情况下,使用O(nlogn)的排序算法,替换O(n^2)的冒泡算法等。
- 异步处理。使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,轮询事件改为事件通知,可以避免轮询导致的CPU消耗。
- 多线程替换多进程。这里主要就是节约线程上下文和进程上下文切换的损耗了。
- 善用缓存,即空间换时间。经常访问的数据或计算过程中的步骤,可以放在内存中缓存起来,加快内存命中率,提高执行速度。
内核态程序优化
若定位到性能瓶颈在内核态之后,正常情况下,作为应用开发工程师,我们是无法去优化内核代码的,当然内核代码一般也很少有优化空间。但并不代表我们就无计可施。可以尝试从以下几方面入手。
- CPU绑定。把进程绑定到一个或者多个CPU上,可以提高CPU的缓存命中率,减少CPU调度带来的上下文切换问题。
- 优先级调整:使用nice调整进程的优先级,或修改进程的调度策略。比如,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用优先被处理。
- 降低系统调用频率:内核态一般都是通过系统调用从用户态进入到内核态。而系统调用也存在上下文的切换损耗,我们可以降低系统调用的频率,从而减少损耗。比如用readv/writev替换read/write。
当然以上的措施,在应用程序优化中,也可以使用。
硬中断
若定位到性能瓶颈在硬中断后,大概率就是环境出现了问题,很少是驱动异常。我们可以通过查看cat /proc/interrupts确定是哪类中断异常,再进一步去排查。
I/O阻塞
若定位到性能瓶颈在I/O后,大概率就是硬件设备I/O性能不足导致的。我们一般可以从以下方面入手:
- 善用缓存。我们知道内存的访问速度远远大于对磁盘的访问速度,我们可以使用缓冲区,减少实际的磁盘或网络I/O。比如,读写磁盘操作中,我们尽量不使用O_DIRECT参数,它表示绕过系统缓存,直接对磁盘进行读写。
- 优化磁盘I/O。提升硬件性能,比如使用SSD;优化文件系统,比如使用ext4或XF5。提高成本。
- 引入提高I/O性能技术。比如引入iota和dma技术。技术难度大。
软中断
若定位到性能瓶颈在软中断后,大概率也是环境问题,很少是驱动异常。具体的原因可以通过查看cat /proc/softirqs确定是哪一类软中断异常,再进一步去排查,处理。
| $ watch -d cat /proc/softirqs |
比如,经过分析,发现上图中NET_RX,也就是网络数据包接收软中断的变化速率最快。而其他几种类型的软中断,是保证 Linux 调度、时钟和临界区保护这些正常工作所必需的,所以它们有一定的变化倒是正常的。那么就可以确认是网卡接收数据出现了异常。
再深入分析,可能就可以结合tcpdump命令,进行抓包,查看是哪一个数据包一直发送。从而定位到问题原因。比如SYN FLOOD问题 就会导致上述问题。
处理方式:从交换机或硬件防火墙中封掉来源IP,这样SYN FLOOD网络帧就不会收到了。
总结
当出现CPU性能问题时,我们第一时间往往是手足无措,不知从何下手。本身深深体验过这种感受,确实不好受。因此希望本文能够帮助到正在经历这种痛苦的朋友。有好的案例或者场景也可以分享,讨论。共勉~
若我的内容对您有所帮助,还请关注我的公众号。不定期分享干活,剖析案例,也可以一起讨论分享。
我的宗旨:
踩完您工作中的所有坑并分享给您,让你的工作无bug,人生尽是坦途
 文章来源:https://www.toymoban.com/news/detail-744659.html
文章来源:https://www.toymoban.com/news/detail-744659.html
 文章来源地址https://www.toymoban.com/news/detail-744659.html
文章来源地址https://www.toymoban.com/news/detail-744659.html
到了这里,关于CPU性能优化——“瑞士军刀“的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!