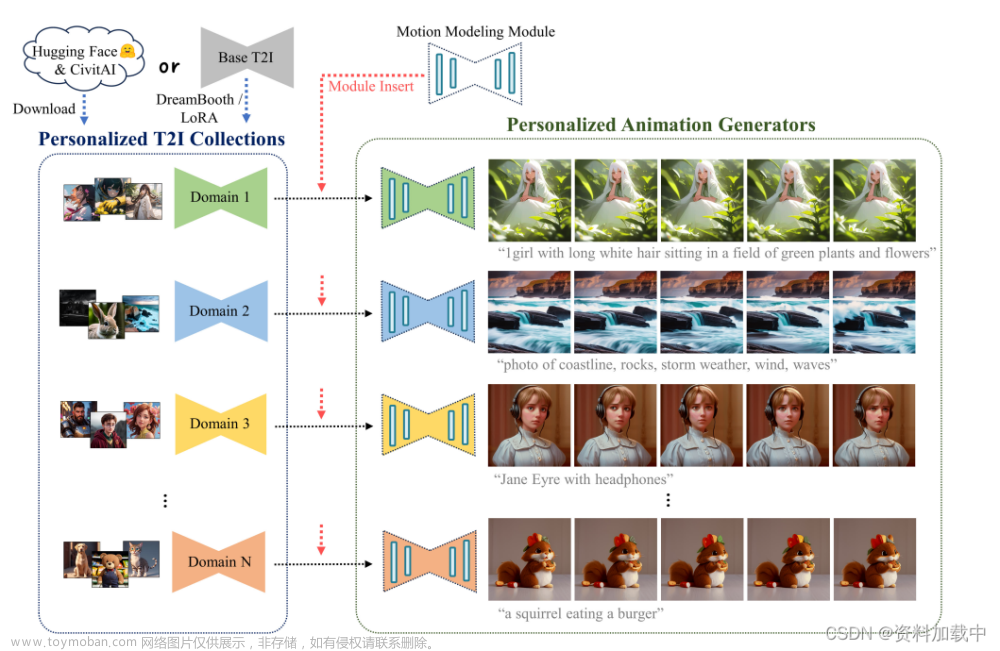
一、背景
需要训练自己的LORA模型
二、分析
1、有sd-webui有训练插件功能
2、有单独的LORA训练开源web界面
两个开源训练界面
1、秋叶写的SD-Trainer
https://github.com/Akegarasu/lora-scripts/ 没成功,主要也是cudnn和nvidia-smi中的CUDA版本不一致退出
2、Kohya's GUI
GitHub - bmaltais/kohya_ss 成功了
遇到问题1,cudnn和nvidia-smi中的CUDA版本不一致
解决方法:unset LD_LIBRARY_PATH解决了我的问题
问题2:报错量化错误
优化器Optimizer 选 :AdamW
三、步骤
1、下载代码
git clone https://github.com/bmaltais/kohya_ss.git2、有Python 3.10.8环境
cd kohya_ss
chmod +x ./setup.sh
./setup.sh
./gui.sh --listen=0.0.0.0 --headless不要自己去安装python包,巨坑。
3、准备数据
下载该数据
https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions/tree/main
#安装处理该数据的包
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fastparquet
# pip install pyarrow
from fastparquet import ParquetFile
datadir = r'./'
filename = datadir + r'下载的数据.parquet'
pf = ParquetFile(filename)
dF = pf.to_pandas()
from PIL import Image
import io
import base64
# 将byte数据转换为PIL图像对象
def save_png(name,image_bytes):
image = Image.open(io.BytesIO(image_bytes))
# 保存图像到文件
filename = 'lora_data/'+str(name)+'.jpg'
print(filename)
# 调整尺寸
new_image = image.resize((512, 512))
new_image.save(filename)
def save_txt(name,text):
# text = "这是要保存的文本内容"
filename = 'lora_data/'+str(name)+'.txt'
with open(filename, 'w') as file:
file.write(text)
保存数据的
for index, row in dF.iterrows():
# print(index,row['text'],row['image.bytes']) # 输出列名
save_txt(index,row['text'])
save_png(index,row['image.bytes'])
if index==20:
break4、创建数据目录
在kohya_ss项目下,创建一个train目录,具体内容如下:
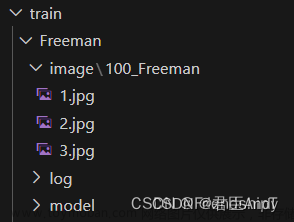
image : 图片放在这里。
log:训练记录
model:模型保存路径
image目录还有一个子目录,比如本文这里是100_pokemon,100表示100个steps,会直接影响训练的步数和效果,pokemon表示图片人物名称。
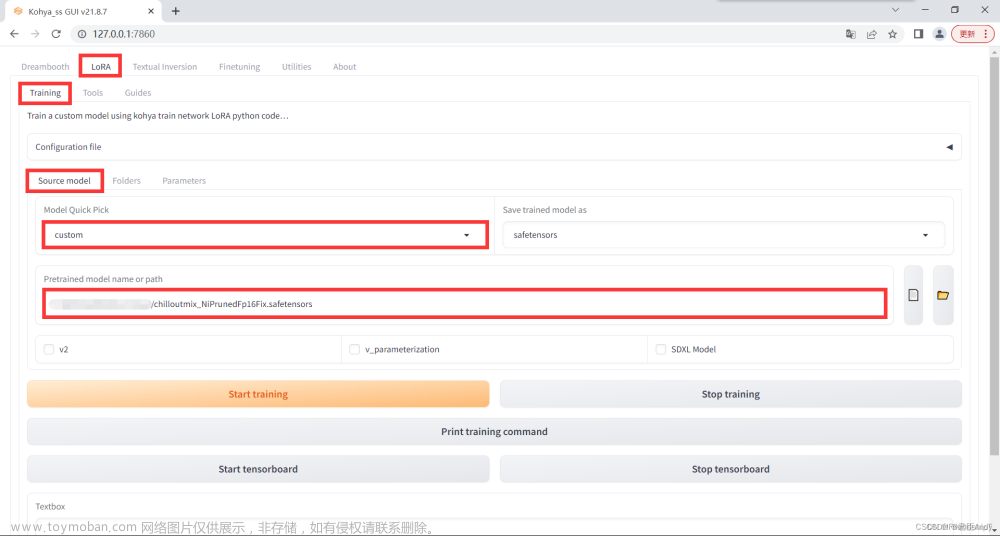
5、训练
训练数据目录填 /home/.../image 不要写到/home/.../image/100_pokemon
基础模型写全/media/...../openjourney-v4.ckpt
 文章来源:https://www.toymoban.com/news/detail-758107.html
文章来源:https://www.toymoban.com/news/detail-758107.html
一定可以训练成功的,有数据有模型有步骤,不清楚可以联系我文章来源地址https://www.toymoban.com/news/detail-758107.html
到了这里,关于训练自己的个性化Stable diffusion模型,LORA的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!