官方文档地址:https://dolphinscheduler.apache.org/zh-cn/docs/3.1.8
因为官方文档经常出现文档桑、图片加载缓慢、中文名对应关系较差,且存在部分链接异常的情况,所以我将其重新整理、排版以方便阅读。
同时做了部分优化,增加了一些注解,补充了中英文对应关系。
3.3 任务类型
DolphinScheduler任务插件有一些公共参数,我们将这些公共参数列在文档中供您查阅。每种任务都有如下的所有或者部分默认参数:
3.3.1 Appendix
3.3.2 Shell
3.3.2.1 综述
Shell 任务类型,用于创建 Shell 类型的任务并执行一系列的 Shell 脚本。worker 执行该任务的时候,会生成一个临时 shell 脚本,并使用与租户同名的 linux 用户执行这个脚本。
3.3.2.2 创建任务
【Step 1】点击项目管理-项目名称-工作流定义,点击 “创建工作流” 按钮,进入 DAG 编辑页面。
【Step 2】工具栏中拖动  到画板中,即可完成创建。
到画板中,即可完成创建。
3.3.2.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
除上述默认参数,此任务没有其他参数。
3.3.2.5 任务样例
3.3.2.5.1 简单打印一行文字
该样例模拟了常见的简单任务,这些任务只需要简单的一两行命令就能运行起来。我们以打印一行日志为例,该任务仅会在日志文件中打印一行 “This is a demo of shell task”
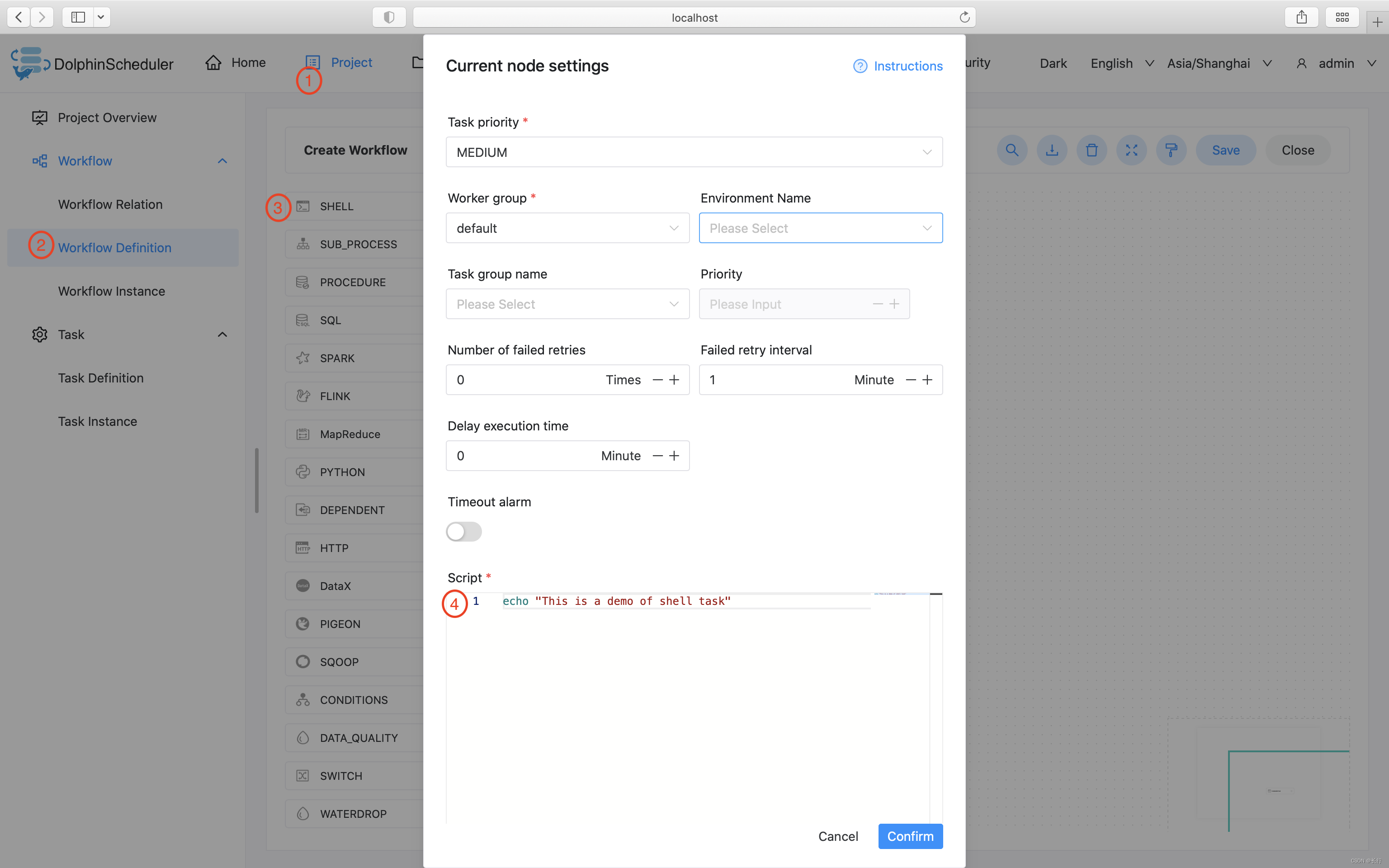
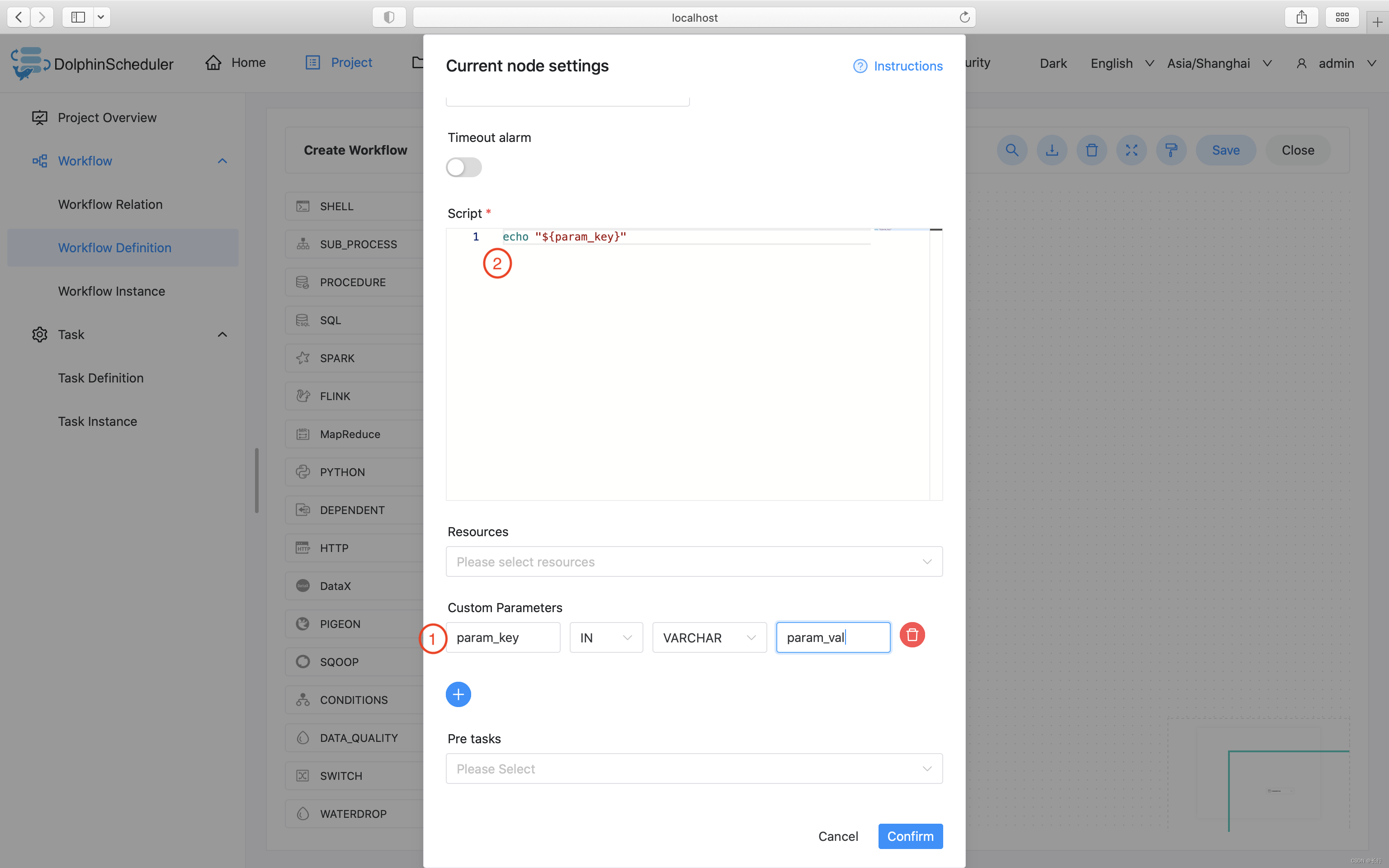
3.3.2.5.2 使用自定义参数
该样例模拟了自定义参数任务,为了更方便的复用已有的任务,或者面对动态的需求时,我们会使用变量保证脚本的复用性。本例中,我们先在自定义脚本中定义了参数 “param_key”,并将他的值设置为 “param_val”。接着在"脚本"中声明了 echo 命令,将参数 “param_key” 打印了出来。当我们保存并运行任务后,在日志中会看到将参数 “param_key” 对应的值 “param_val” 打印出来。
3.3.2.6 注意事项
Shell 任务类型通过解析任务日志是否包含 application_xxx_xxx 的内容来判断是否 Yarn 任务,如果是则会将相应的 application_id 的状态作为当前 Shell 节点的运行状态判断,此时如果操作停止工作流则会 Kill 相应的 application_id
如果 Shell 任务中需要使用到用户自定义的脚本,可通过资源中心来上传对应的文件然后在 Shell 任务中引用他们,可参考:3.7.3 文件管理。
3.3.3 SubProcess 子流程节点
3.3.3.1 综述
子流程节点,就是把外部的某个工作流定义当做一个节点去执行。
3.3.3.2 创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击 ”创建工作流” 按钮,进入 DAG 编辑页面:
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.3.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 子节点 | 是选择子流程的工作流定义,右上角进入该子节点可以跳转到所选子流程的工作流定义 |
3.3.3.4 任务样例
该样例模拟了常见的任务类型,这里我们使用子结点任务调用 Shell(详见 3.3.2 Shell) 打印出 ”hello world“。即将一个 shell 任务当作子结点来执行。
3.3.3.5 创建 shell 任务
创建一个 shell 任务,用于打印 “hello”。并为该工作流定义为 test_dag01。
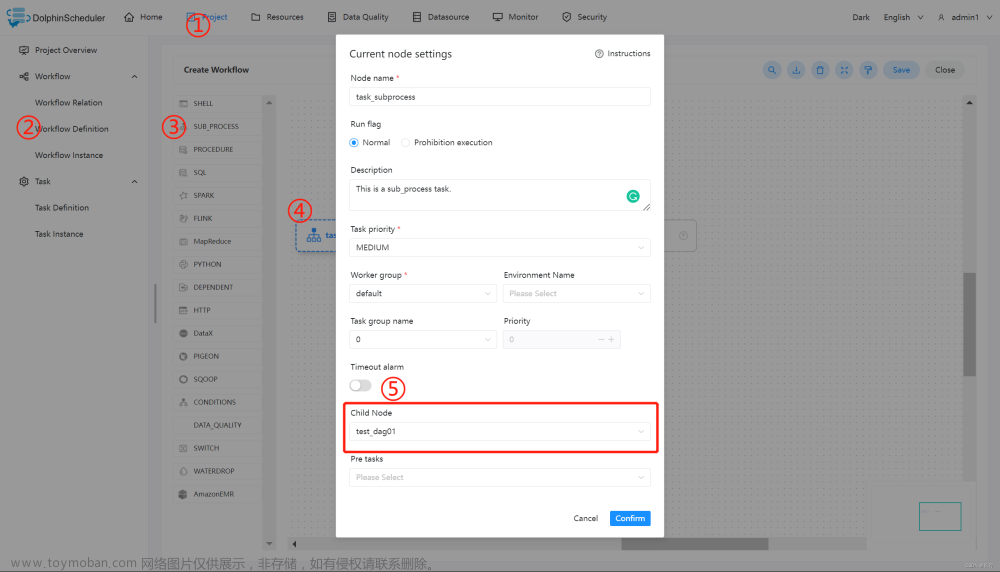
3.3.3.6 创建 sub_process 任务
在使用 sub_process 的过程中,需要创建所需的子结点任务,也就是我们第一步所创建的 shell 任务。然后如下图所示,在 ⑤ 的位置选择对应的子结点即可。
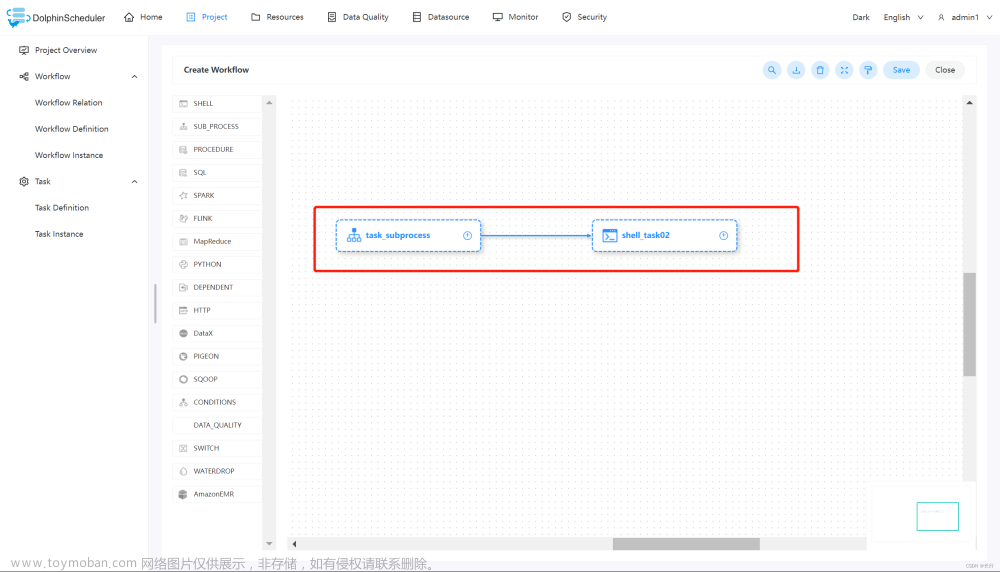
创建 sub_process 完成之后,再创建一个对应的 shell 任务,用于打印 “world”,并将二者连接起来。保存当前工作流,并上线运行,即可得到想要的结果。
3.3.3.7 注意事项
在使用 sub_process 调用子结点任务的时候,需要保证定义的子结点为上线状态,否则 sub_process 的工作流无法正常运行。
3.3.4 Dependent 节点
3.3.4.1 综述
Dependent 节点,就是依赖检查节点。比如 A 流程依赖昨天的 B 流程执行成功,依赖节点会去检查 B 流程在昨天是否有执行成功的实例。
3.3.4.2 创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.4.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
此任务除上述链接中的默认参数外无其他参数。
3.3.4.4 任务样例
Dependent 节点提供了逻辑判断功能,可以按照逻辑来检测所依赖节点的执行情况。
例如,A 流程为周报任务,B、C 流程为天任务,A 任务需要 B、C 任务在上周的每一天都执行成功,如图示:
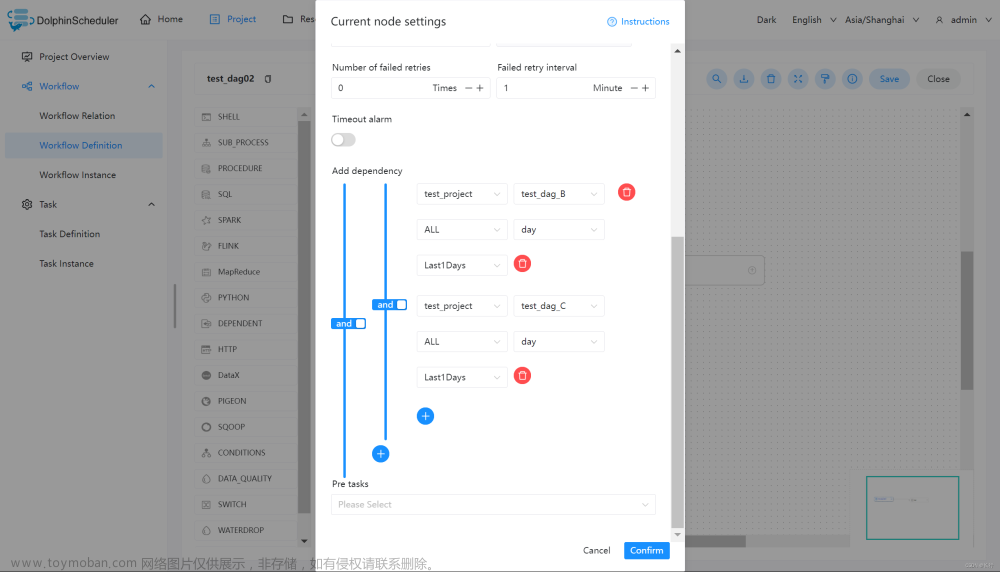
例如,A 流程为周报任务,B、C 流程为天任务,A 任务需要 B 或 C 任务在上周的每一天都执行成功,如图示:
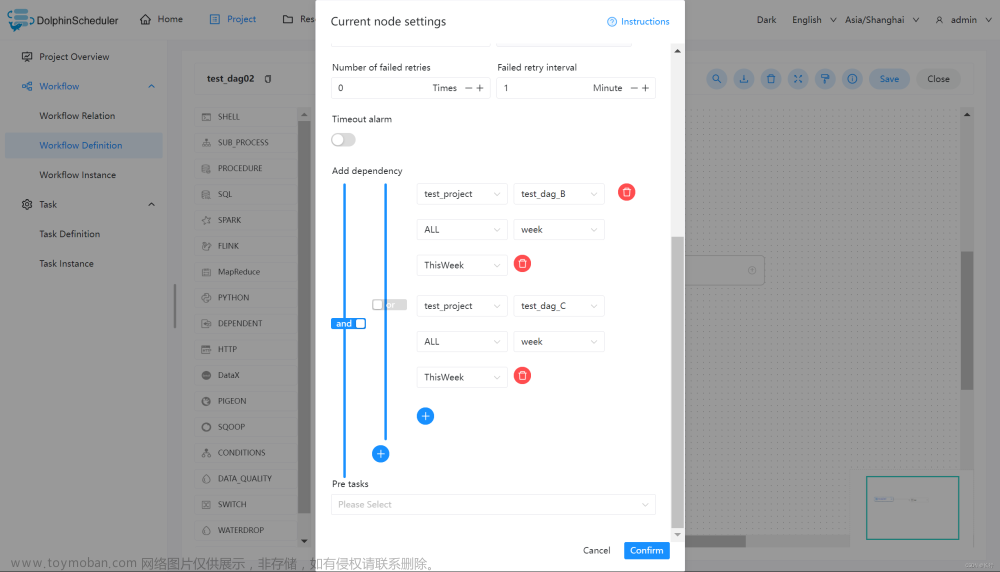
假如,周报 A 同时还需要自身在上周二执行成功:
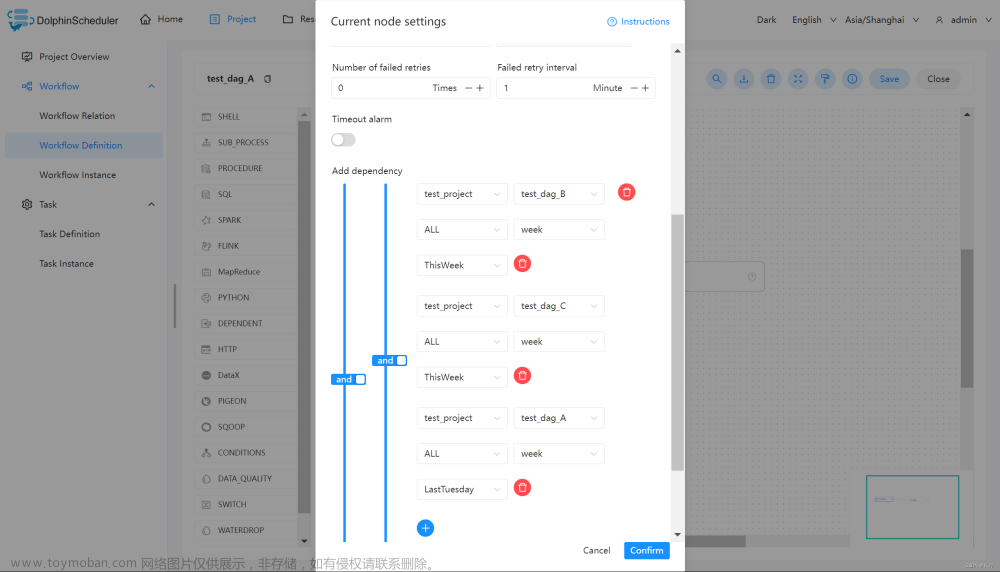
3.3.5 Stored Procedure 存储过程节点
根据选择的数据源,执行存储过程。拖动工具栏中的PROCEDURE任务节点到画板中,如下图所示:
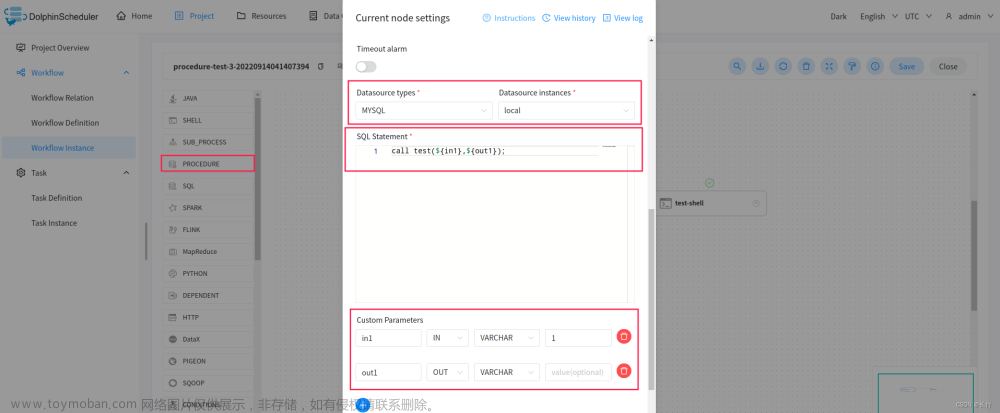
前提:在该数据库里面创建存储过程,如:
CREATE PROCEDURE dolphinscheduler.test(in in1 INT, out out1 INT)
begin
set out1=in1;
END
3.3.5.1 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 数据源 | 存储过程的数据源类型支持MySQL、POSTGRESQL、ORACLE,选择对应的数据源 |
| SQL Statement | 调用存储过程,如 call test(${in1},${out1});
|
| 自定义参数 | 存储过程的自定义参数类型支持IN、OUT两种,数据类型支持VARCHAR、INTEGER、LONG、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP、BOOLEAN九种数据类型 |
3.3.6 SQL
3.3.6.1 综述
SQL任务类型,用于连接数据库并执行相应SQL。
3.3.6.2 创建数据源
可参考 数据源配置 数据源中心。
3.3.6.3 创建任务
- 点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
- 工具栏中拖动
 到画板中,选择需要连接的数据源,即可完成创建。
到画板中,选择需要连接的数据源,即可完成创建。
3.3.6.4 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
- 数据源:选择对应的数据源
- sql 类型:支持查询和非查询两种。
- 查询:支持
DML select类型的命令,是有结果集返回的,可以指定邮件通知为表格、附件或表格附件三种模板; - 非查询:支持
DDL全部命令 和DML update、delete、insert三种类型的命令; - 默认采用
;\n作为 SQL 分隔符,拆分成多段SQL语句执行。Hive的JDBC不支持一次执行多段SQL语句,请不要使用;\n。 - sql参数:输入参数格式为key1=value1;key2=value2…
- sql语句:SQL语句
- UDF 函数:对于 HIVE 类型的数据源,可以引用资源中心中创建的UDF函数,其他类型的数据源暂不支持UDF函数。
- 自定义参数:SQL任务类型,而存储过程是自定义参数顺序,给方法设置值自定义参数类型和数据类型,同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换sql语句中${变量}。
- 前置sql:前置sql在sql语句之前执行。
- 后置sql:后置sql在sql语句之后执行。
3.3.6.5 任务样例
3.3.6.5.1 Hive表创建示例
在hive中创建临时表并写入数据。
该样例向hive中创建临时表 tmp_hello_world 并写入一行数据。选择SQL类型为非查询,在创建临时表之前需要确保该表不存在,所以我们使用自定义参数,在每次运行时获取当天时间作为表名后缀,这样这个任务就可以每天运行。创建的表名格式为:tmp_hello_world_{yyyyMMdd}。 注意:sql任务组件的hive应用是基于JDBC去调用,SQL statement 不支持多行执行,请注意不要在语句末尾使用’;'。如果要执行多行语句请使用 3.3.22 Hive CLI 任务。
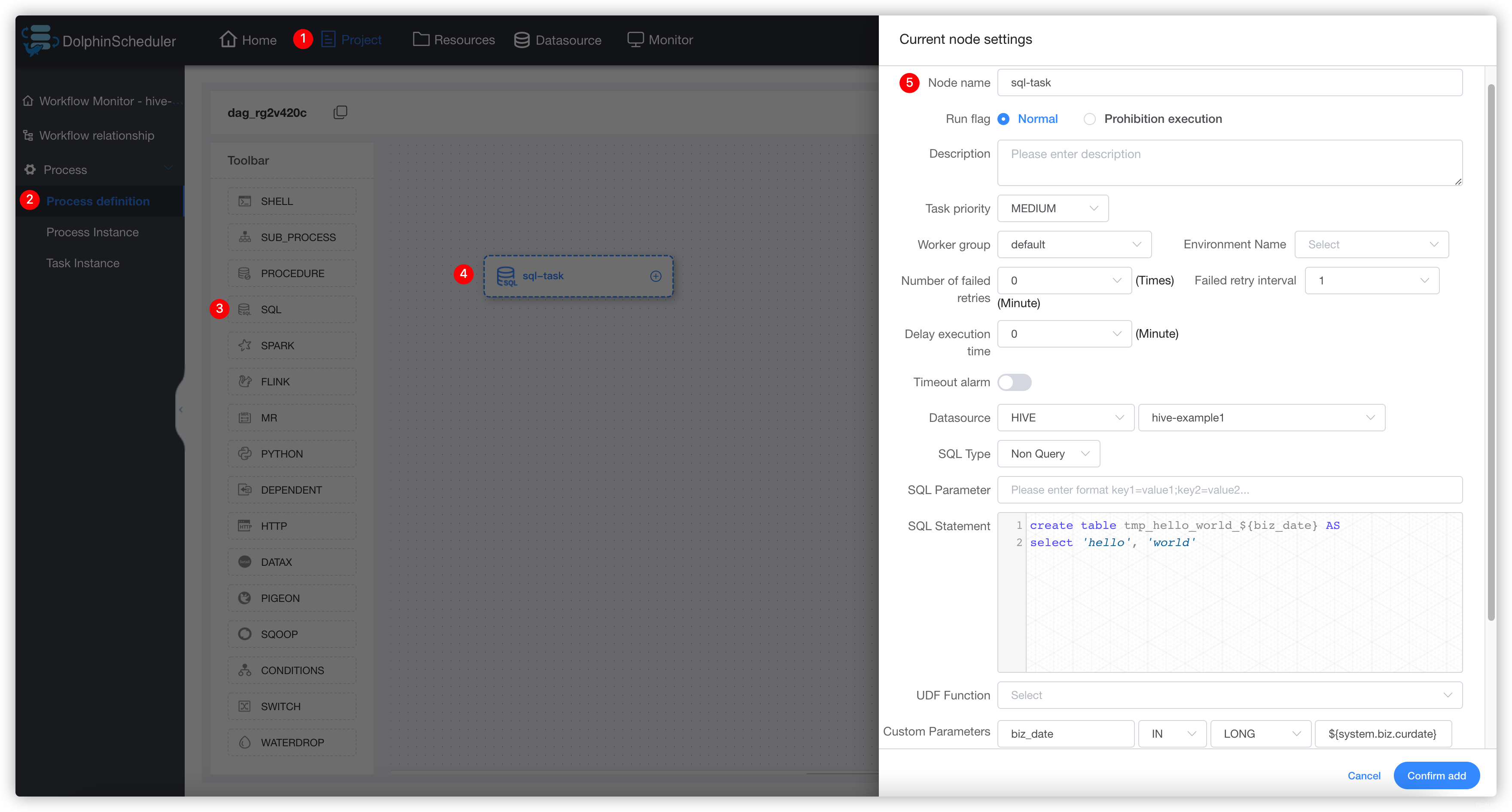
运行该任务成功之后在hive中查询结果:
登录集群使用hive命令或使用beeline、JDBC等方式连接apache hive进行查询,查询SQL为select * from tmp_hello_world_{yyyyMMdd},请将{yyyyMMdd}替换为运行当天的日期,查询截图如下:
3.3.6.5.2 使用前置sql和后置sql示例
在前置sql中执行建表操作,在sql语句中执行操作,在后置sql中执行清理操作。

3.3.6.6 注意事项
注意SQL类型的选择,如果是INSERT等操作需要选择非查询类型。
为了兼容长会话情况,UDF函数的创建是通过CREATE OR REPLACE语句
3.3.7 Spark
3.3.7.1 综述
Spark 任务类型用于执行 Spark 应用。对于 Spark 节点,worker 支持两个不同类型的 spark 命令提交任务:
(1) spark submit 方式提交任务。更多详情查看 spark-submit。
(2) spark sql 方式提交任务。更多详情查看 spark sql。
3.3.7.2 创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击”创建工作流”按钮,进入 DAG 编辑页面:
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.7.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
- 程序类型:支持 Java、Scala、Python 和 SQL 四种语言。
- Spark 版本:支持 Spark1 和 Spark2。
- 主函数的 Class:Spark 程序的入口 Main class 的全路径。
- 主程序包:执行 Spark 程序的 jar 包(通过资源中心上传)。
- SQL脚本:Spark sql 运行的 .sql 文件中的 SQL 语句。
- 部署方式:(1) spark submit 支持 yarn-clusetr、yarn-client 和 local 三种模式。 (2) spark sql 支持 yarn-client 和 local 两种模式。
- 任务名称(可选):Spark 程序的名称。
- Driver 核心数:用于设置 Driver 内核数,可根据实际生产环境设置对应的核心数。
- Driver 内存数:用于设置 Driver 内存数,可根据实际生产环境设置对应的内存数。
- Executor 数量:用于设置 Executor 的数量,可根据实际生产环境设置对应的内存数。
- Executor 内存数:用于设置 Executor 内存数,可根据实际生产环境设置对应的内存数。
- 主程序参数:设置 Spark 程序的输入参数,支持自定义参数变量的替换。
- 选项参数:支持
--jar、--files、--archives、--conf格式。 - 资源:如果其他参数中引用了资源文件,需要在资源中选择指定。
- 自定义参数:是 Spark 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容。
3.3.7.4 任务样例
3.3.7.4.1 spark submit
执行 WordCount 程序:本案例为大数据生态中常见的入门案例,常应用于 MapReduce、Flink、Spark 等计算框架。主要为统计输入的文本中,相同的单词的数量有多少。
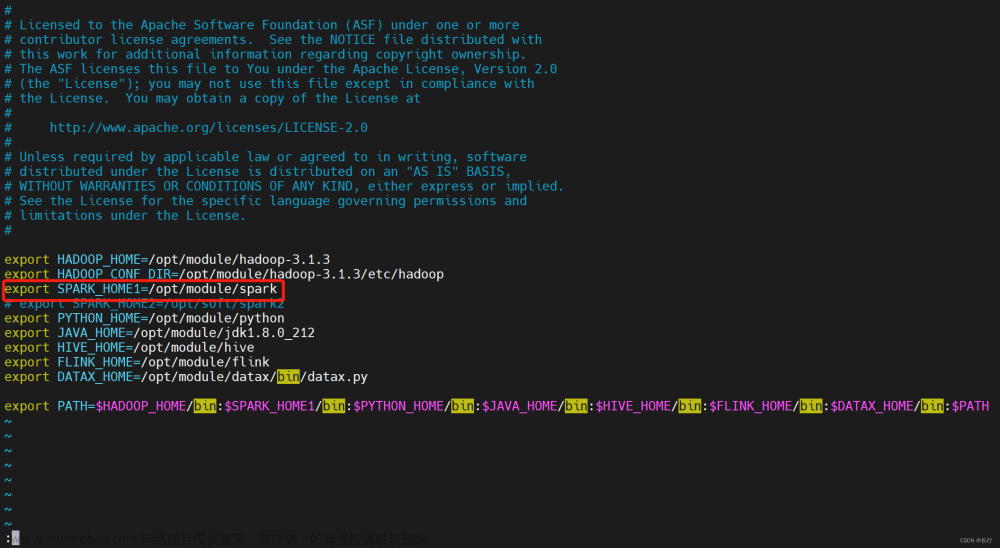
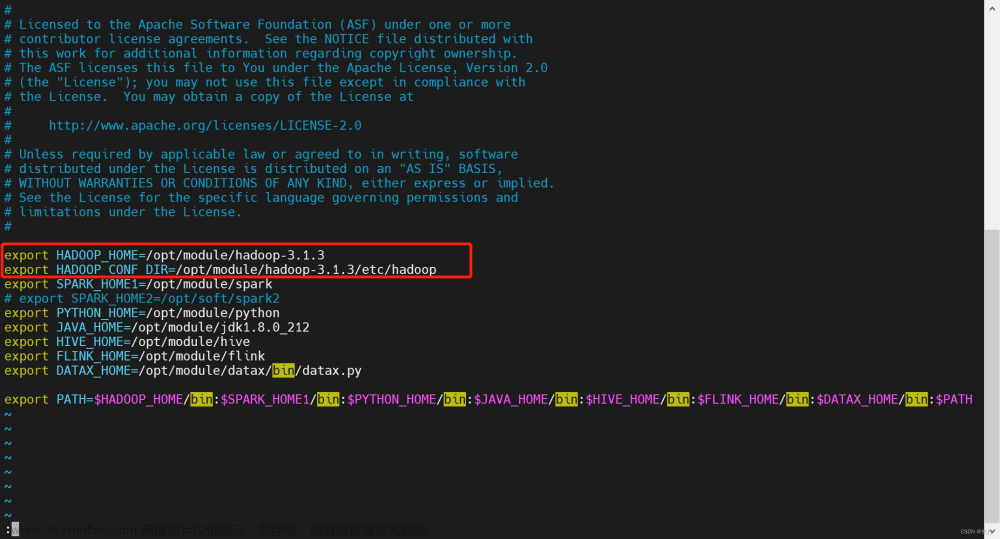
在 DolphinScheduler 中配置 Spark 环境:若生产环境中要是使用到 Spark 任务类型,则需要先配置好所需的环境。配置文件如下:bin/env/dolphinscheduler_env.sh。
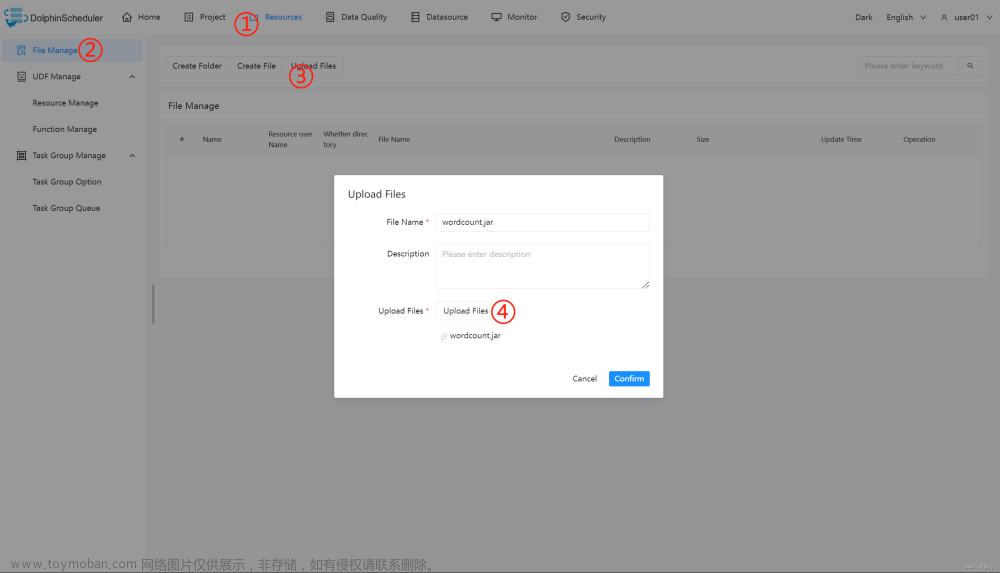
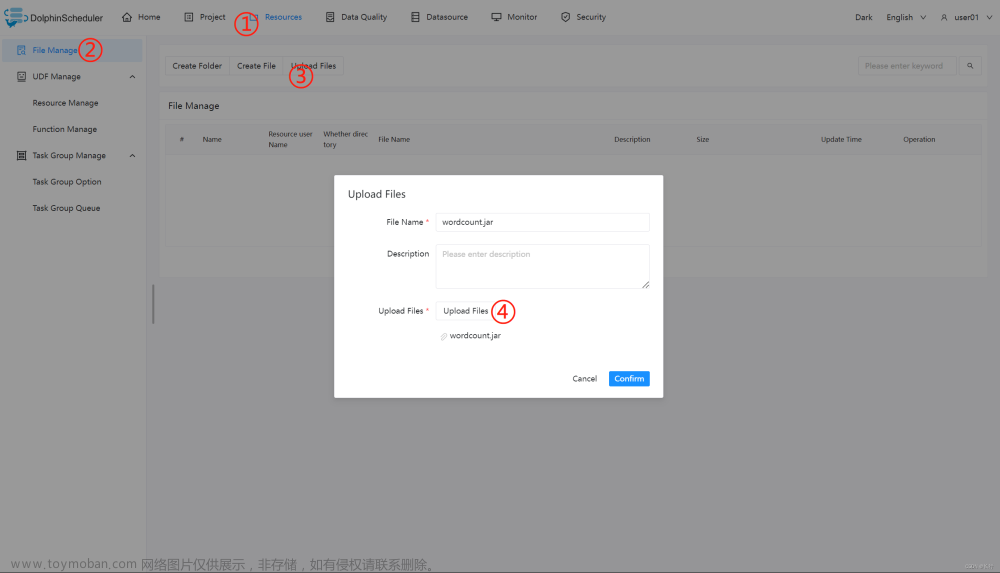
上传主程序包:在使用 Spark 任务节点时,需要利用资源中心上传执行程序的 jar 包,可参考 3.7.2 资源中心 - 配置详情。
当配置完成资源中心之后,直接使用拖拽的方式,即可上传所需目标文件。
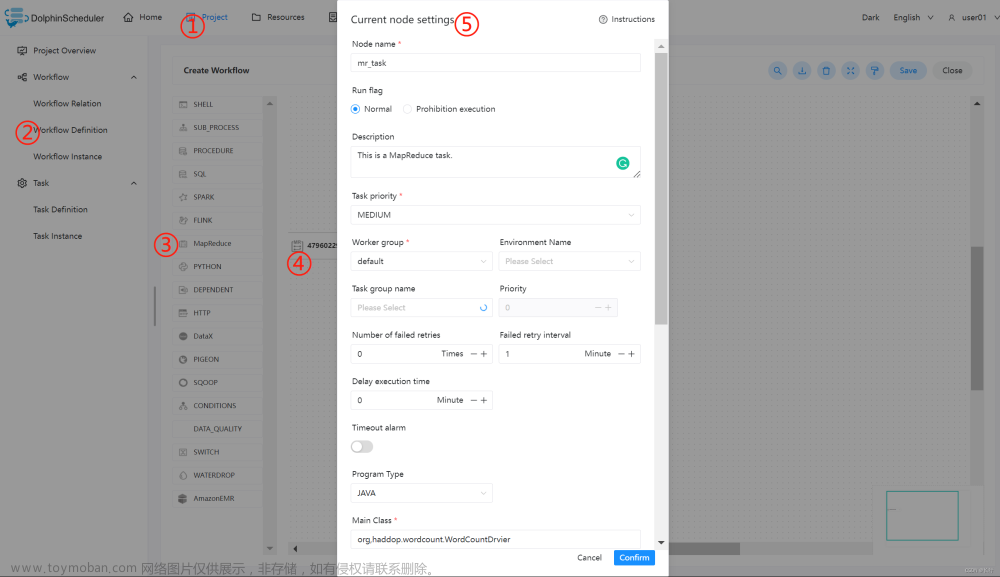
配置 Spark 节点:根据上述参数说明,配置所需的内容即可。

3.3.7.4.2 spark sql
执行 DDL 和 DML 语句:本案例为创建一个视图表 terms 并写入三行数据和一个格式为 parquet 的表 wc 并判断该表是否存在。程序类型为 SQL。将视图表 terms 的数据插入到格式为 parquet 的表 wc。
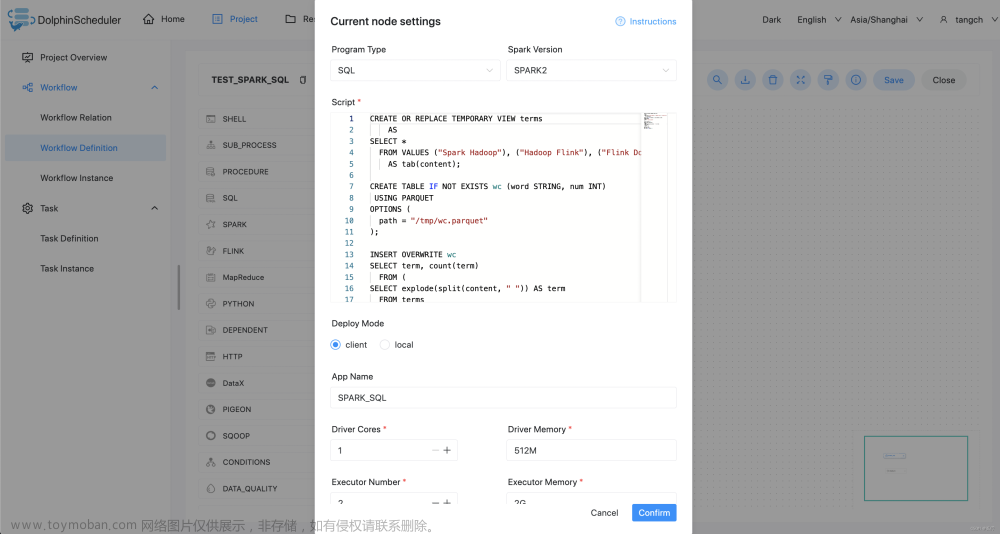
3.3.7.5 注意事项
注意:
JAVA 和 Scala 只用于标识,使用 Spark 任务时没有区别。如果应用程序是由 Python 开发的,那么可以忽略表单中的参数Main Class。参数SQL脚本仅适用于 SQL 类型,在 JAVA、Scala 和 Python 中可以忽略。
SQL 目前不支持 cluster 模式。
3.3.8 MapReduce(MR)节点
3.3.8.1 综述
MapReduce(MR) 任务类型,用于执行 MapReduce 程序。对于 MapReduce 节点,worker 会通过使用 Hadoop 命令 hadoop jar 的方式提交任务。更多详情查看 Hadoop Command Manual。
3.3.8.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入 DAG 编辑页面。
- 拖动工具栏中的
 任务节点到画板中,如下图所示:
任务节点到画板中,如下图所示:
3.3.8.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
JAVA / SCALA 程序:
| 任务参数 | 描述 |
|---|---|
| 程序类型 | 选择 JAVA/SCALA 语言 |
| 主函数的 Class | 是 MapReduce 程序的入口 Main Class 的全路径 |
| 主程序包 | 执行 MapReduce 程序的 jar 包 |
| 任务名称(选填) | MapReduce 任务名称 |
| 命令行参数 | 是设置 MapReduce 程序的输入参数,支持自定义参数变量的替换 |
| 其他参数 | 支持 –D、-files、-libjars、-archives 格式 |
| 自定义参数 | 是 MapReduce 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容 |
Python 程序:
| 任务参数 | 描述 |
|---|---|
| 程序类型 | 选择 Python 语言 |
| 主 jar 包 | 是运行 MapReduce 的 Python jar 包 |
| 其他参数 | 支持 –D、-mapper、-reducer、-input -output格式,这里可以设置用户自定义参数的输入,比如:-mapper “mapper.py 1” -file mapper.py -reducer reducer.py -file reducer.py –input /journey/words.txt -output /journey/out/mr/${currentTimeMillis},其中 -mapper 后的 mapper.py 1是两个参数,第一个参数是 mapper.py,第二个参数是 1 |
| 自定义参数 | 是 MapReduce 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容 |
3.3.8.4 任务样例
执行 WordCount 程序:该样例为 MapReduce 应用中常见的入门类型,主要为统计输入的文本中,相同单词的数量有多少。
在 DolphinScheduler 中配置 MapReduce 环境:若生产环境中要是使用到 MapReduce 任务类型,则需要先配置好所需的环境。配置文件如下:bin/env/dolphinscheduler_env.sh。
上传主程序包:在使用 MapReduce 任务节点时,需要利用资源中心上传执行程序的 jar 包。可参考资源中心。
当配置完成资源中心之后,直接使用拖拽的方式,即可上传所需目标文件。
配置 MapReduce 节点:根据上述参数说明,配置所需的内容即可。
3.3.9 Python 节点
3.3.9.1 综述
Python 任务类型,用于创建 Python 类型的任务并执行一系列的 Python 脚本。worker 执行该任务的时候,会生成一个临时python脚本, 并使用与租户同名的 linux 用户执行这个脚本。
3.3.9.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
- 工具栏中拖动
 到画板中,即可完成创建。
到画板中,即可完成创建。
3.3.9.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 脚本 | 用户开发的PYTHON程序 |
| 自定义参数 | 是PYTHON局部的用户自定义参数,会替换脚本中以${变量}的内容 |
3.3.9.4 任务样例
3.3.9.4.1 简单打印一行文字
该样例模拟了常见的简单任务,这些任务只需要简单的一两行命令就能运行起来。我们以打印一行日志为例,该任务仅会在日志文件中打印一行 “This is a demo of python task”
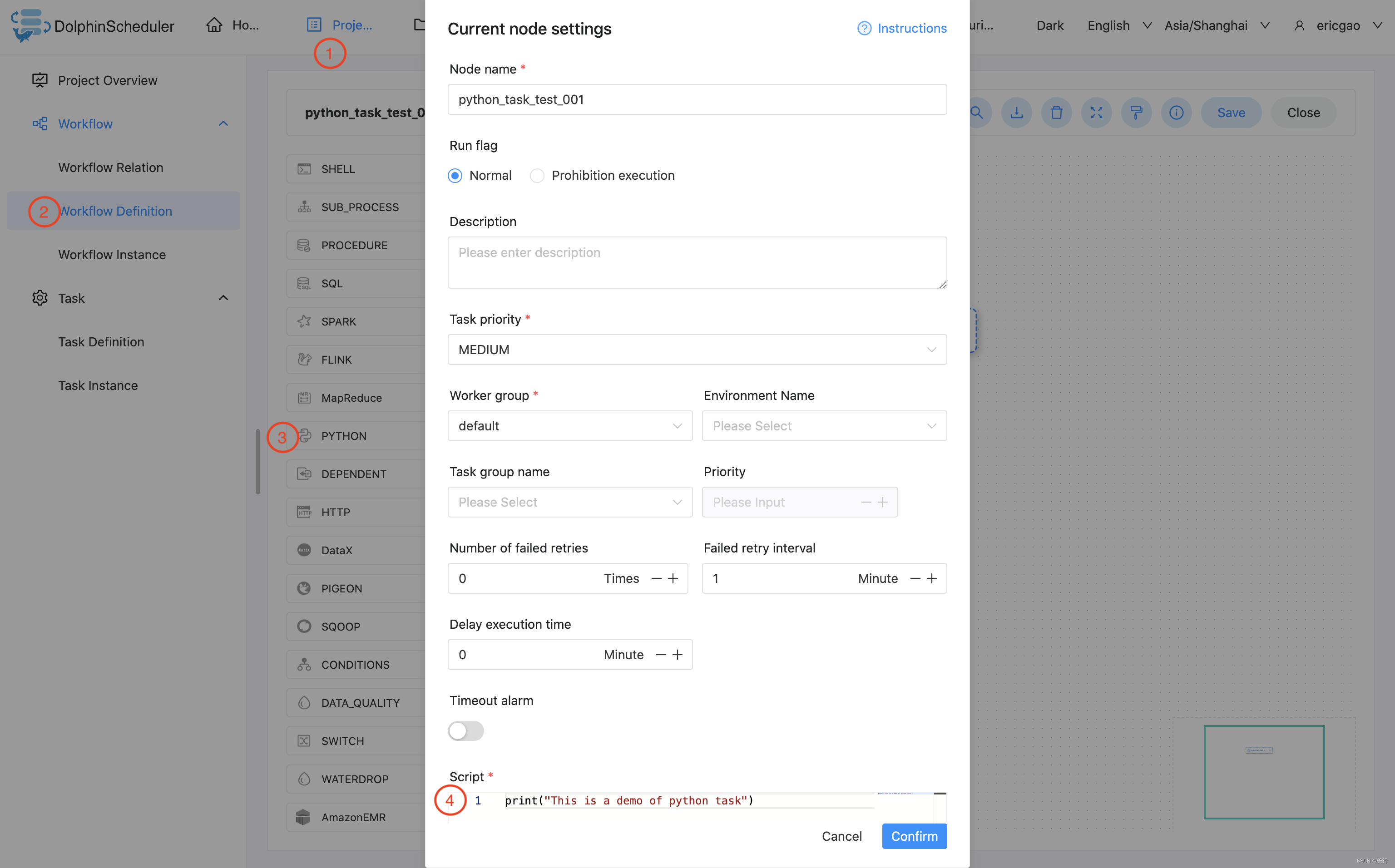
print("This is a demo of python task")
3.3.9.4.2 使用自定义参数
该样例模拟了自定义参数任务,为了更方便的复用已有的任务,或者面对动态的需求时,我们会使用变量保证脚本的复用性。本例中,我们先在自定义脚本 中定义了参数 “param_key”,并将他的值设置为 “param_val”。接着在"脚本"中使用了 print 函数,将参数 “param_key” 打印了出来。当我们保存 并运行任务后,在日志中会看到将参数 “param_key” 对应的值 “param_val” 打印出来。
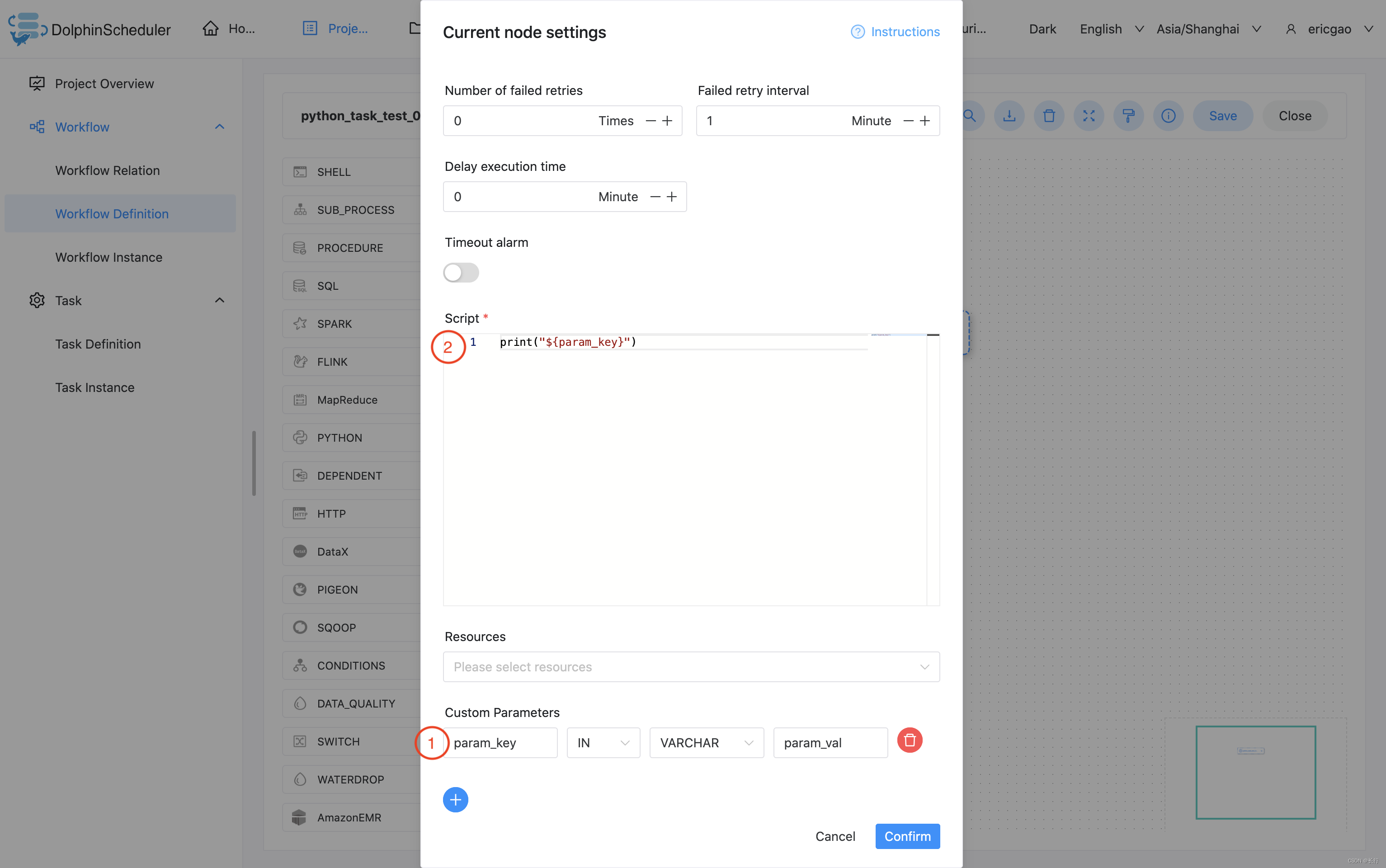
print("${param_key}")
3.3.10 Flink
3.3.10.1 综述
Flink 任务类型,用于执行 Flink 程序。对于 Flink 节点:
- 当程序类型为 Java、Scala 或 Python 时,worker 使用 Flink 命令提交任务
flink run。更多详情查看 flink cli 。 - 当程序类型为 SQL 时,worker 使用
sql-client.sh提交任务。更多详情查看 flink sql client 。
3.3.10.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.10.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 程序类型 | 支持 Java、Scala、 Python 和 SQL 四种语言 |
| 主函数的 Class | Flink 程序的入口 Main Class 的全路径 |
| 主程序包 | 执行 Flink 程序的 jar 包(通过资源中心上传) |
| 部署方式 | 支持 cluster、 local 和 application (Flink 1.11和之后的版本支持,参见 Run an application in Application Mode) 三种模式的部署 |
| 初始化脚本 | 用于初始化会话上下文的脚本文件 |
| 脚本 | 用户开发的应该执行的 SQL 脚本文件 |
| Flink 版本 | 根据所需环境选择对应的版本即可 |
| 任务名称(选填) | Flink 程序的名称 |
| jobManager 内存数 | 用于设置 jobManager 内存数,可根据实际生产环境设置对应的内存数 |
| Slot 数量 | 用于设置 Slot 的数量,可根据实际生产环境设置对应的数量 |
| taskManager 内存数 | 用于设置 taskManager 内存数,可根据实际生产环境设置对应的内存数 |
| taskManager 数量 | 用于设置 taskManager 的数量,可根据实际生产环境设置对应的数量 |
| 并行度 | 用于设置执行 Flink 任务的并行度 |
| 主程序参数 | 设置 Flink 程序的输入参数,支持自定义参数变量的替换 |
| 选项参数 | 支持 --jar、--files、--archives、--conf 格式 |
| 自定义参数 | 是 Flink 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容 |
3.3.10.4 任务样例
3.3.10.4.1 执行 WordCount 程序
本案例为大数据生态中常见的入门案例,常应用于 MapReduce、Flink、Spark 等计算框架。主要为统计输入的文本中,相同的单词的数量有多少。(Flink 的 Releases 附带了此示例作业)
在 DolphinScheduler 中配置 flink 环境:若生产环境中要是使用到 flink 任务类型,则需要先配置好所需的环境。配置文件如下:bin/env/dolphinscheduler_env.sh。
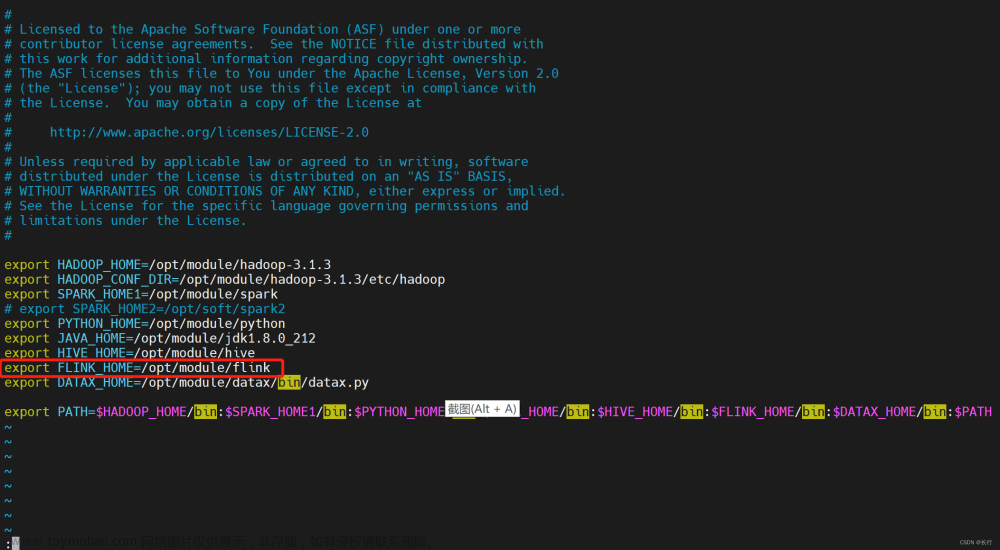
上传主程序包:在使用 Flink 任务节点时,需要利用资源中心上传执行程序的 jar 包,可参考 3.7.2 配置详情。
当配置完成资源中心之后,直接使用拖拽的方式,即可上传所需目标文件。

配置 Flink 节点:根据上述参数说明,配置所需的内容即可。
3.3.10.4.2 执行 FlinkSQL 程序
根据上述参数说明,配置所需的内容即可。

3.3.10.5 注意事项
- Java 和 Scala 只是用来标识,没有区别,如果是 Python 开发的 Flink 则没有主函数的 class,其余的都一样。
- 使用 SQL 执行 Flink SQL 任务,目前只支持 Flink 1.13及以上版本。
3.3.11 HTTP
3.3.11.1 综述
该节点用于执行 http 类型的任务,例如常见的 POST、GET 等请求类型,此外还支持 http 请求校验等功能。
3.3.11.2 创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击”创建工作流”按钮,进入 DAG 编辑页面:
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.11.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 请求地址 | http 请求 URL |
| 请求类型 | 支持 GET、POST、HEAD、PUT、DELETE |
| 请求参数 | 支持 Parameter、Body、Headers |
| 校验条件 | 支持默认响应码、自定义响应码、内容包含、内容不包含 |
| 校验内容 | 当校验条件选择自定义响应码、内容包含、内容不包含时,需填写校验内容 |
| 自定义参数 | 是 http 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容 |
3.3.11.4 任务样例
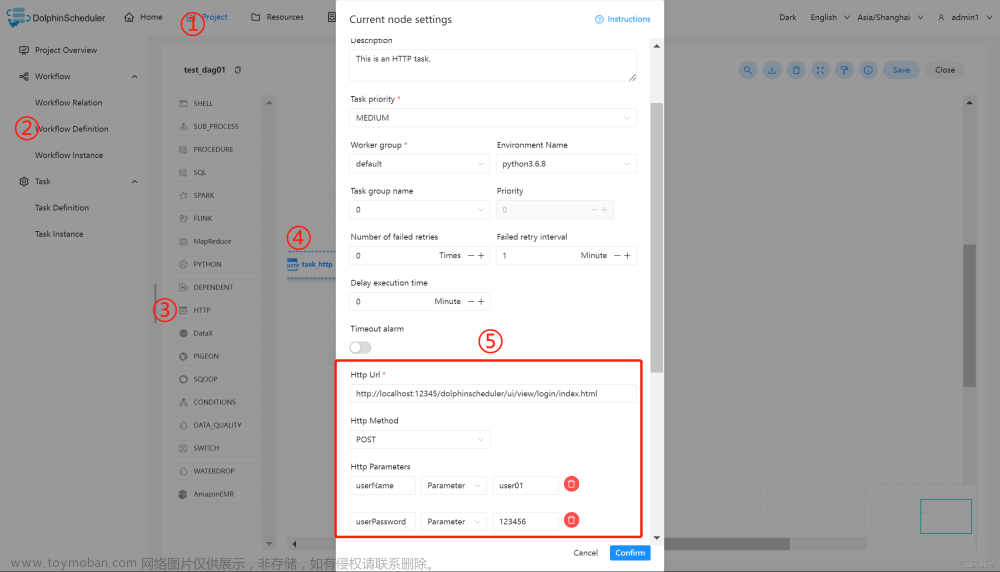
HTTP 定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE。这里我们使用 http 任务节点,演示使用 POST 向系统的登录页面发送请求,提交数据。
主要配置参数如下:
- URL:访问目标资源的地址,这里为系统的登录页面。
- HTTP Parameters
- userName:用户名;
- userPassword:用户登录密码。
3.3.12 DataX
3.3.12.1 综述
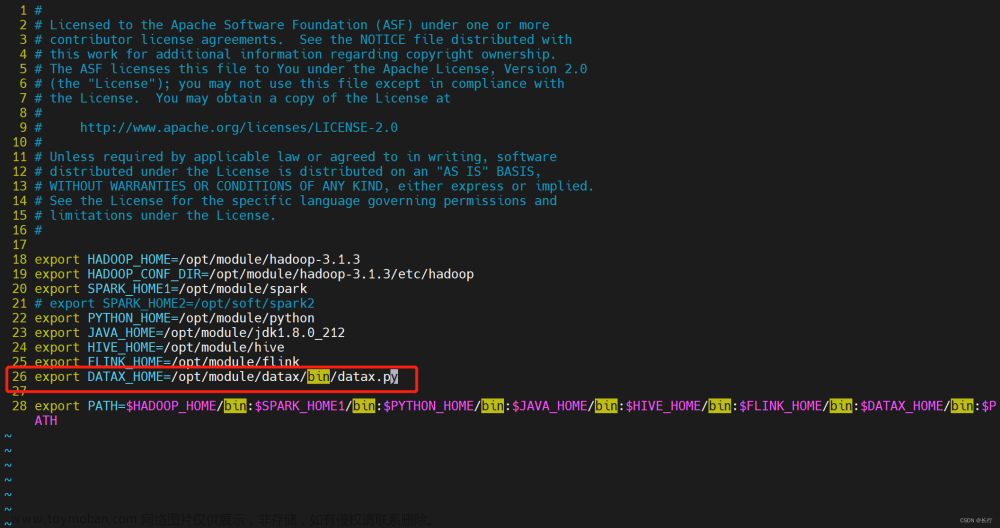
DataX 任务类型,用于执行 DataX 程序。对于 DataX 节点,worker 会通过执行 ${DATAX_HOME}/bin/datax.py 来解析传入的 json 文件。
3.3.12.2 创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.12.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| json | DataX 同步的 json 配置文件 |
| 资源 | 在使用自定义json中如果集群开启了kerberos认证后,datax读取或者写入hdfs、hbase等插件时需要使用相关的keytab,xml文件等,则可使用改选项。资源中心-文件管理上传或创建的文件 |
| 自定义参数 | sql 任务类型,而存储过程是自定义参数顺序的给方法设置值自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换 sql 语句中 ${变量} |
| 数据源 | 选择抽取数据的数据源 |
| sql 语句 | 目标库抽取数据的 sql 语句,节点执行时自动解析 sql 查询列名,映射为目标表同步列名,源表和目标表列名不一致时,可以通过列别名(as)转换 |
| 目标库 | 选择数据同步的目标库 |
| 目标库前置 | 前置 sql 在 sql 语句之前执行(目标库执行) |
| 目标库后置 | 后置 sql 在 sql 语句之后执行(目标库执行) |
| 限流(字节数) | 限制查询的字节数 |
| 限流(记录数) | 限制查询的记录数 |
3.3.12.4 任务样例
该样例演示为从 Hive 数据导入到 MySQL 中。
在 DolphinScheduler 中配置 DataX 环境:若生产环境中要是使用到 DataX 任务类型,则需要先配置好所需的环境。配置文件如下:/dolphinscheduler/conf/env/dolphinscheduler_env.sh。
当环境配置完成之后,需要重启 DolphinScheduler。
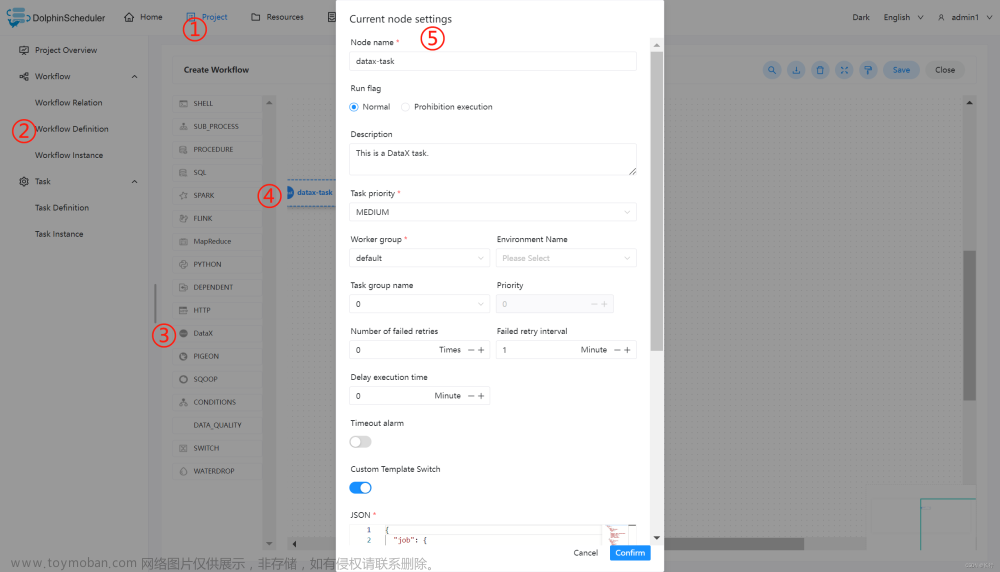
配置 DataX 任务节点:由于默认的的数据源中并不包含从 Hive 中读取数据,所以需要自定义 json,可参考:HDFS Writer。其中需要注意的是 HDFS 路径上存在分区目录,在实际情况导入数据时,分区建议进行传参,即使用自定义参数。
在编写好所需的 json 之后,可按照下图步骤进行配置节点内容。
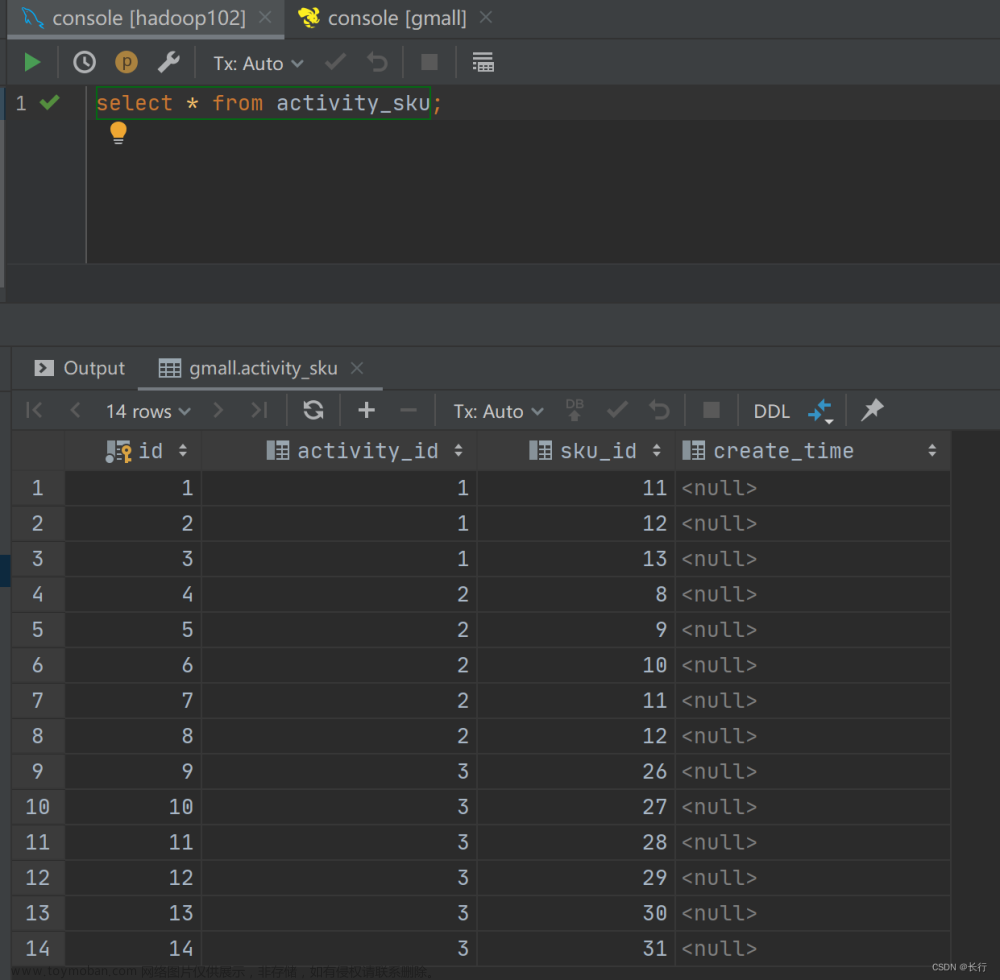
查看运行结果
3.3.12.5 注意事项
若默认提供的数据源不满足需求,可在自定义模板选项中,根据实际使用环境来配置 DataX 的 writer 和 reader,可参考:https://github.com/alibaba/DataX
3.3.13 Sqoop
3.3.14 Pigeon
Pigeon任务类型是通过调用远程websocket服务,实现远程任务的触发,状态、日志的获取,是 DolphinScheduler 通用远程 websocket 服务调用任务
3.3.14.1 创建任务
拖动工具栏中的  任务节点到画板中即能完成任务创建
任务节点到画板中即能完成任务创建
3.3.14.2 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 目标任务名 | 输入Pigeon任务的目标任务名称 |
3.3.15 Conditions
Conditions 是一个条件节点,根据上游任务运行状态,判断应该运行哪个下游任务。截止目前 Conditions 支持多个上游任务,但只支持两个下游任务。当上游任务数超过一个时,可以通过 且 以及 或 操作符实现复杂上游依赖
3.3.15.1 创建任务
- 点击项目管理-项目名称-工作流定义,点击 “创建工作流” 按钮,进入 DAG 编辑页面;
- 拖动工具栏中的

任务节点到画板中。
3.3.15.2 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 下游任务选择 | 根据前置任务的状态来跳转到对应的分支:成功分支 - 当上游运行成功时,运行成功选择的分支;失败分支 - 当上游运行失败时,运行失败选择的分支 |
| 上游条件选择 | 可以为 Conditions 任务选择一个或多个上游任务:增加上游依赖 - 通过选择第一个参数选择对应的任务名称,通过第二个参数选择触发的 Conditions 任务的状态;上游任务关系选择 - 当有多个上游任务时,可以通过且以及或操作符实现任务的复杂关系。 |
3.3.5.13 相关任务
3.3.16 switch:Condition节点主要依据上游节点的执行状态(成功、失败)执行对应分支。3.3.16 switch 节点主要依据全局变量的值和用户所编写的表达式判断结果执行对应分支。
3.3.5.14 任务样例
该样例通过使用 3.3.16 switch 任务来演示 Condition 任务的操作流程。
创建工作流。进入工作流定义页面,然后分别创建如下任务节点:
- Node_A:Shell 任务,打印输出 ”hello world“,其主要作用是 Condition 的上游分支,根据其执行是否成功来触发对应的分支节点。
- Condition:Conditions 任务,根据上游任务的执行状态,来执行对应的分支。
- Node_Success:Shell 任务,打印输出 “success”,Node_A 执行成功的分支。
- Node_False:Shell 任务,打印输出 ”false“,Node_A 执行失败的分支。
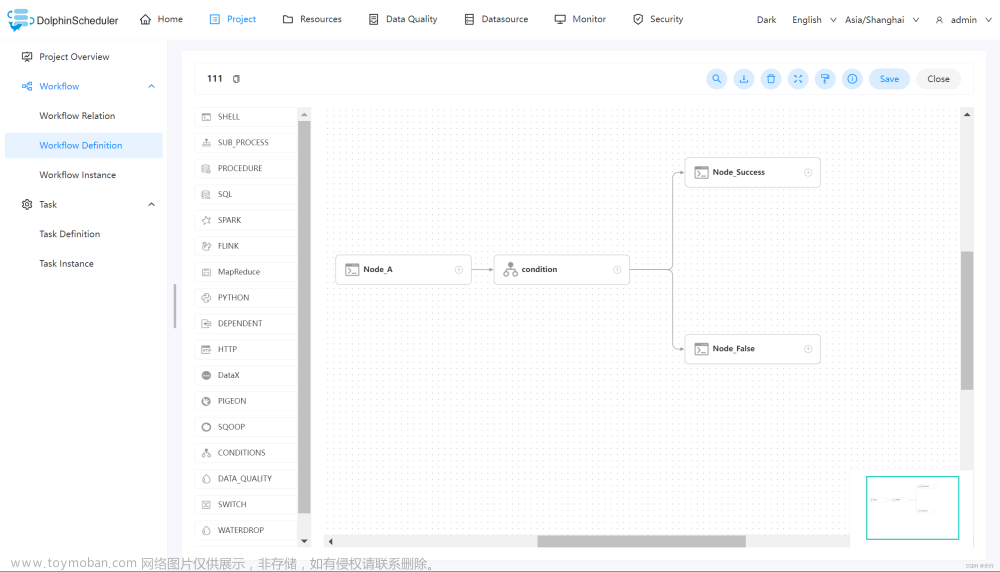
查看执行结果。当完成创建工作流之后,可以上线运行该工作流。在工作流实例页面可以查看到各个任务的执行状态。如下图所示:
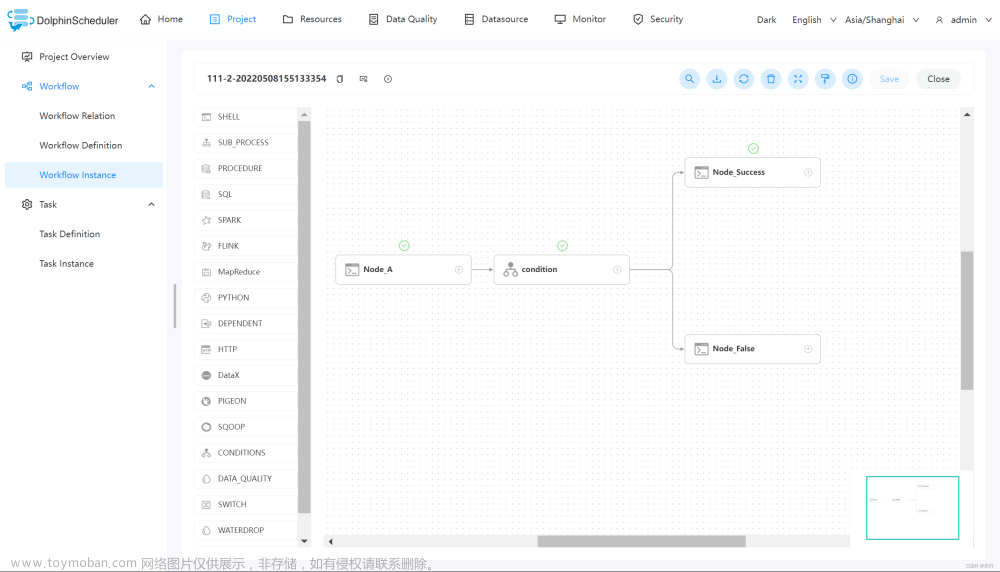
上图中,任务状态标记为绿色对号的,即为成功执行的任务节点。
3.3.5.15 注意事项
- Conditions 任务支持多个上游任务,但只支持两个下游任务。
- Conditions 任务以及包含该任务的工作流不支持复制操作。
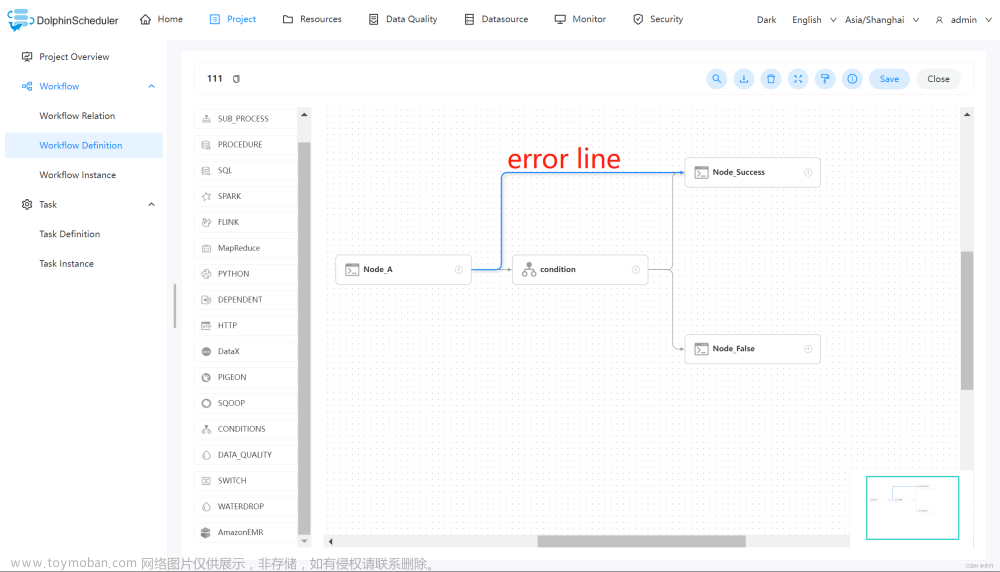
- Conditions 的前置任务不能连接其分支节点,会造成逻辑混乱,不符合 DAG 调度。如下图所示的情况是错误的。

3.3.16 Switch
Switch 是一个条件判断节点,依据全局变量的值和用户所编写的表达式判断结果执行对应分支。 注意使用 javax.script.ScriptEngine.eval 执行表达式。
3.3.16.1 创建任务
点击项目管理 -> 项目名称 -> 工作流定义,点击"创建工作流"按钮,进入 DAG 编辑页面。 拖动工具栏中的  任务节点到画板中即能完成任务创建。 注意 switch 任务创建后,要先配置上下游,才能配置任务分支的参数。
任务节点到画板中即能完成任务创建。 注意 switch 任务创建后,要先配置上下游,才能配置任务分支的参数。
3.3.16.2 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 条件 | 可以为 switch 任务配置多个条件,当条件满足时,就会执行指定的分支,可以配置多个不同的条件来满足不同的业务,使用字符串判断时需要使用"" |
| 分支流转 | 默认的流转内容,当条件中的内容为全部不符合要求时,则运行分支流转中指定的分支 |
3.3.16.3 任务样例
这里使用一个 switch 任务以及三个 shell 任务来演示。
创建工作流。新建 switch 任务,以及下游的三个 shell 任务。shell 任务没有要求。 switch 任务需要和下游任务连线配置关系后,才可以进行下游任务的选择。
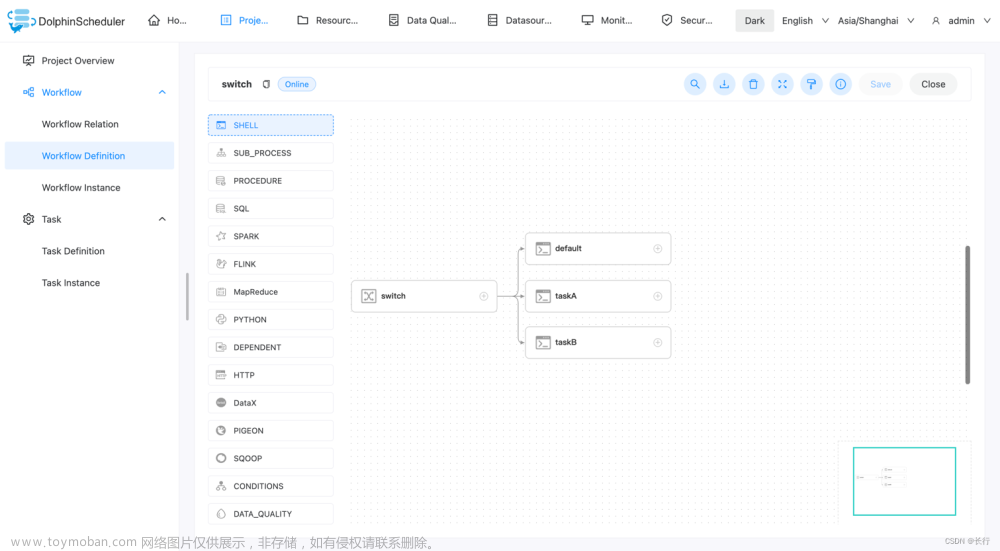
设置条件。配置条件和默认分支,满足条件会走指定分支,都不满足则走默认分支。 图中如果变量的值为 “A” 则执行分支 taskA,如果变量的值为 “B” 则执行分支 taskB ,都不满足则执行 default。
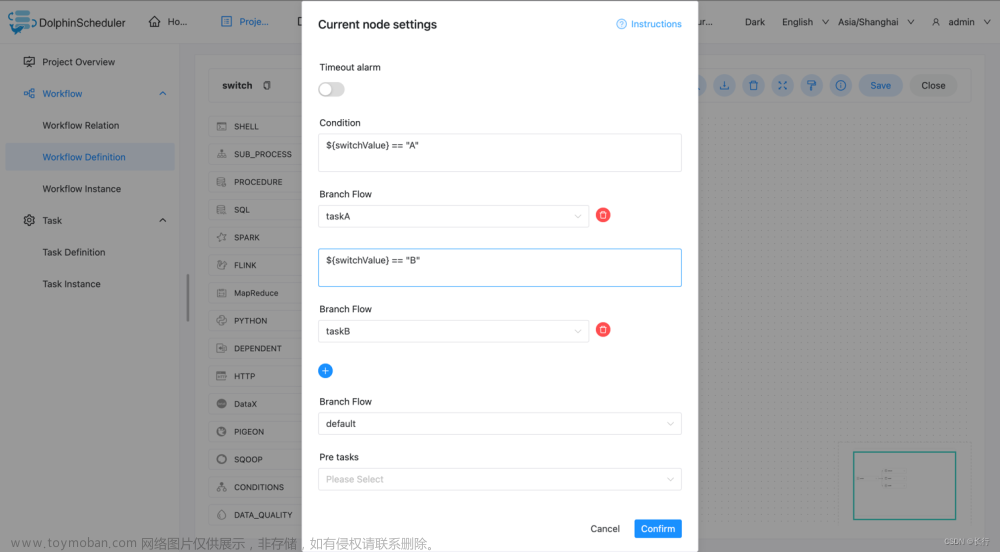
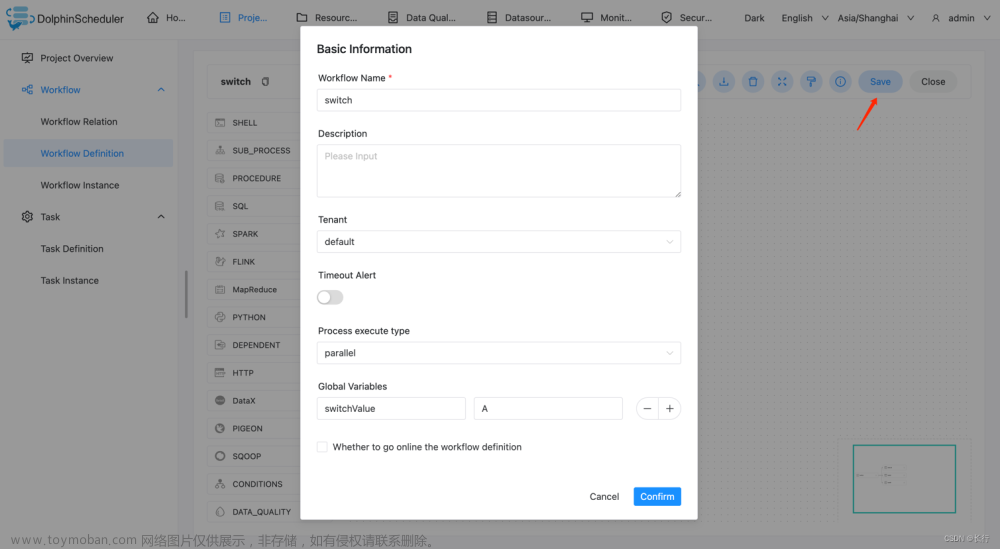
条件使用了全局变量,请参考全局变量。 这里配置全局变量的值为 A。
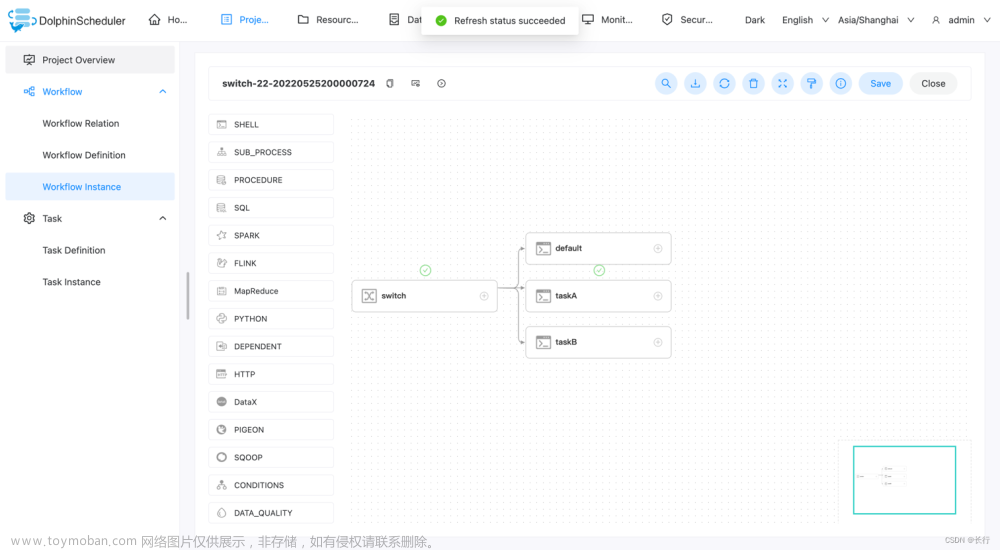
如果执行正确,那么 taskA 会被正确执行。
执行。并且查看是否符合预期。可以看到符合预期,执行了指定的下游任务 taskA。
3.3.17 SeaTunnel
3.3.17.1 综述
SeaTunnel 任务类型,用于创建并执行 SeaTunnel 类型任务。worker 执行该任务的时候,会通过 start-seatunnel-spark.sh 、 start-seatunnel-flink.sh 和 seatunnel.sh 命令解析 config 文件。 点击 这里 获取更多关于 Apache SeaTunnel 的信息。
3.3.17.2 创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.17.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
- 启动脚本:选择你想要运行任务的启动脚本,包括
seatunnel.sh,start-seatunnel-flink-13-connector-v2.sh,start-seatunnel-flink-15-connector-v2.sh,start-seatunnel-flink-connector-v2.sh,start-seatunnel-flink.sh,start-seatunnel-spark-2-connector-v2.sh,start-seatunnel-spark-3-connector-v2.sh,start-seatunnel-spark-connector-v2.sh,start-seatunnel-spark.sh - FLINK
- 运行模型:支持
run和run-application两种模式 - 选项参数:用于添加 Flink 引擎本身参数,例如
-m yarn-cluster -ynm seatunnel - SPARK
- 部署方式:指定部署模式,
clusterclient - Master:指定
Master模型,yarnlocalsparkmesos,其中spark和mesos需要指定Master服务地址,例如:127.0.0.1:7077 - SEATUNNEL_ENGINE
- 部署方式:指定部署模式,
clusterlocal,点击 这里 获取更多关于Apache SeaTunnel command使用的信息 - 自定义配置:支持自定义配置或从资源中心选择配置文件,点击 这里 获取更多关于
Apache SeaTunnel config文件介绍 - 脚本:在任务节点那自定义配置信息,包括四部分:
envsourcetransformsink
3.3.17.4 任务样例
该样例演示为使用 Flink 引擎从 Fake 源读取数据打印到控制台。
在 DolphinScheduler 中配置 SeaTunnel 环境。若生产环境中要是使用到 SeaTunnel 任务类型,则需要先配置好所需的环境,配置文件如下:/dolphinscheduler/conf/env/dolphinscheduler_env.sh。

配置 SeaTunnel 任务节点。根据上述参数说明,配置所需的内容即可。
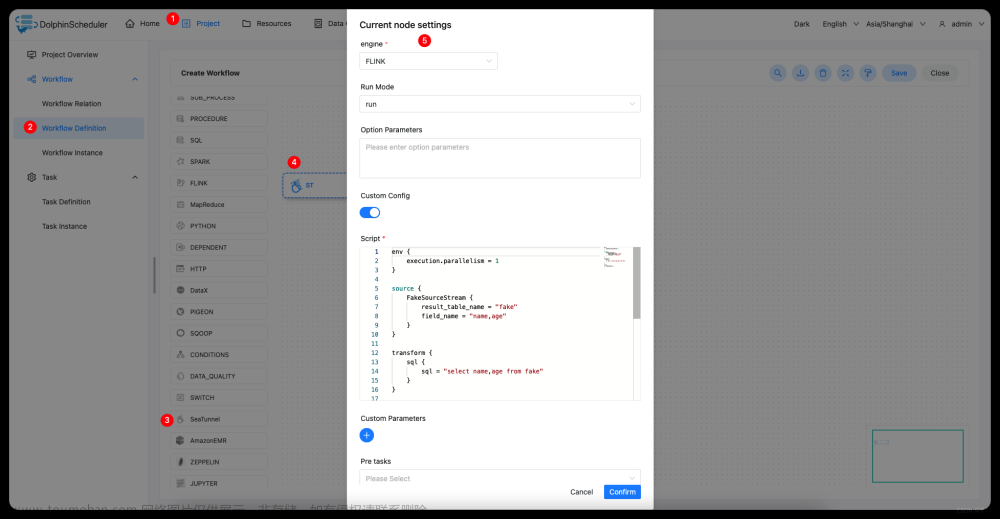
Config 样例:
env {
execution.parallelism = 1
}
source {
FakeSource {
result_table_name = "fake"
field_name = "name,age"
}
}
transform {
sql {
sql = "select name,age from fake"
}
}
sink {
ConsoleSink {}
}
3.3.18 Amazon EMR
3.3.18.1 综述
Amazon EMR 任务类型,用于在AWS上操作EMR集群并执行计算任务。 后台使用 aws-java-sdk 将JSON参数转换为任务对象,提交到AWS,目前支持两种程序类型:
-
RUN_JOB_FLOW使用 API_RunJobFlow 提交 RunJobFlowRequest 对象 -
ADD_JOB_FLOW_STEPS使用 API_AddJobFlowSteps 提交 AddJobFlowStepsRequest 对象
3.3.18.2 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 程序类型 | 选择程序类型,如果是RUN_JOB_FLOW,则需要填写jobFlowDefineJson,如果是ADD_JOB_FLOW_STEPS,则需要填写stepsDefineJson
|
| jobFlowDefineJson | RunJobFlowRequest 对象对应的JSON,详细JSON定义参见 API_RunJobFlow_Examples |
| stepsDefineJson | AddJobFlowStepsRequest 对象对应的JSON,详细JSON定义参见 API_AddJobFlowSteps_Examples |
3.3.18.3 任务样例
3.3.18.3.1 创建EMR集群并运行Steps
该样例展示了如何创建RUN_JOB_FLOW类型EMR任务节点,以执行SparkPi为例,该任务会创建一个EMR集群,并且执行SparkPi示例程序。
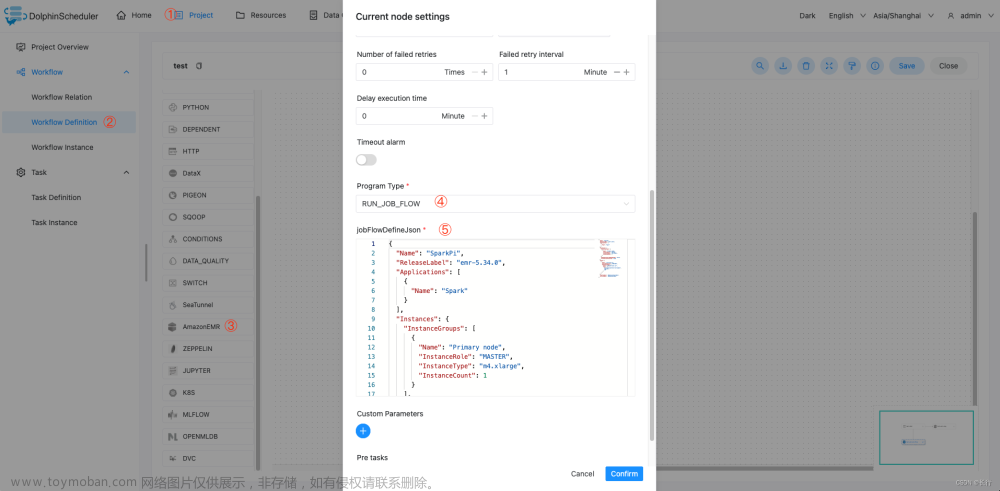
jobFlowDefineJson 参数样例:
{
"Name": "SparkPi",
"ReleaseLabel": "emr-5.34.0",
"Applications": [
{
"Name": "Spark"
}
],
"Instances": {
"InstanceGroups": [
{
"Name": "Primary node",
"InstanceRole": "MASTER",
"InstanceType": "m4.xlarge",
"InstanceCount": 1
}
],
"KeepJobFlowAliveWhenNoSteps": false,
"TerminationProtected": false
},
"Steps": [
{
"Name": "calculate_pi",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"/usr/lib/spark/bin/run-example",
"SparkPi",
"15"
]
}
}
],
"JobFlowRole": "EMR_EC2_DefaultRole",
"ServiceRole": "EMR_DefaultRole"
}
3.3.18.3.2 向运行中的EMR集群添加Step
该样例展示了如何创建ADD_JOB_FLOW_STEPS类型EMR任务节点,以执行SparkPi为例,该任务会向运行中的EMR集群添加一个SparkPi示例程序。
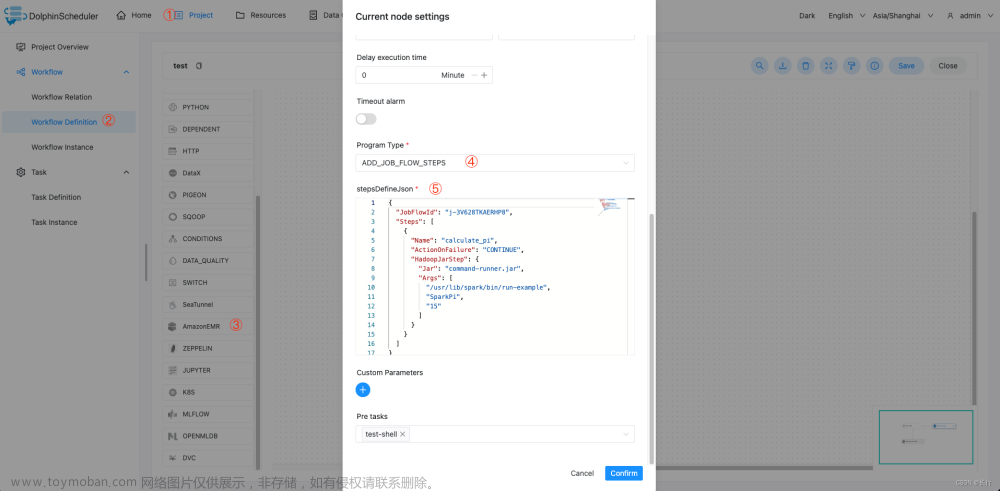
stepsDefineJson 参数样例
{
"JobFlowId": "j-3V628TKAERHP8",
"Steps": [
{
"Name": "calculate_pi",
"ActionOnFailure": "CONTINUE",
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"/usr/lib/spark/bin/run-example",
"SparkPi",
"15"
]
}
}
]
}
3.3.18.4 注意事项
- EMR 任务类型的故障转移尚未实现。目前,DolphinScheduler 仅支持对 yarn task type 进行故障转移。其他任务类型,如 EMR 任务、k8s 任务尚未准备好。
-
stepsDefineJson一个任务定义仅支持关联单个step,这样可以更好的保证任务状态的可靠性。
3.3.19 Apache Zeppelin
3.3.19.1 综述
Zeppelin任务类型,用于创建并执行Zeppelin类型任务。worker 执行该任务的时候,会通过Zeppelin Cient API触发Zeppelin Notebook Paragraph。 点击这里 获取更多关于Apache Zeppelin Notebook的信息。
3.3.19.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
- 工具栏中拖动
 到画板中,即可完成创建。
到画板中,即可完成创建。
3.3.19.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| Zeppelin Note ID | Zeppelin Note对应的唯一ID |
| Zeppelin Paragraph ID | Zeppelin Paragraph对应的唯一ID。如果你想一次性调度整个note,这一栏不填即可 |
| Zeppelin Rest Endpoint | 您的Zeppelin服务的REST Endpoint |
| Zeppelin Production Note Directory | 生产模式下存放克隆note的目录 |
| Zeppelin Parameters | 用于传入Zeppelin Dynamic Form的参数 |
3.3.19.4 生产(克隆)模式
- 填上
Zeppelin Production Note Directory参数以启动生产模式。 - 在
生产模式下,目标note会被克隆到您所填的Zeppelin Production Note Directory目录下。Zeppelin任务插件将会执行克隆出来的note并在执行成功后自动清除它。 因为在此模式下,如果您不小心修改了正在被Dolphin Scheduler调度的note,也不会影响到生产任务的执行, 从而提高了稳定性。 - 如果您选择不填
Zeppelin Production Note Directory这个参数,Zeppelin任务插件将会执行您的原始note。 'Zeppelin Production Note Directory’参数在格式上应该以斜杠开头和结尾,例如/production_note_directory/。
3.3.19.5 任务样例
3.3.19.5.1 Zeppelin Paragraph 任务样例
这个示例展示了如何创建Zeppelin Paragraph任务节点:
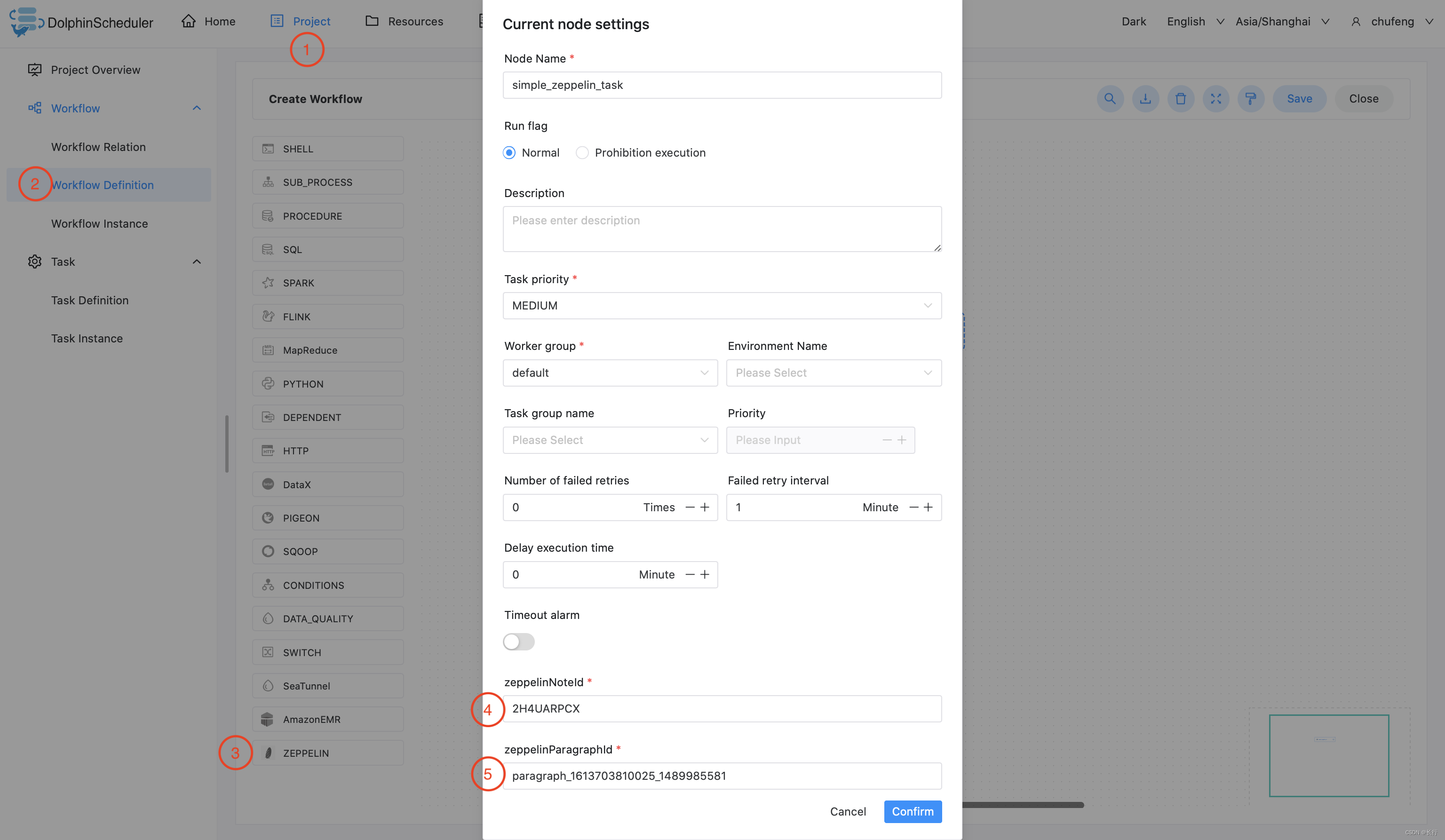

3.3.20 Jupyter
3.3.20.1 综述
Jupyter任务类型,用于创建并执行Jupyter类型任务。worker 执行该任务的时候,会通过papermill执行jupyter note。 点击这里 获取更多关于papermill的信息。
3.3.20.2 Conda虚拟环境配置
- 在
common.properties配置conda.path,将其指向您的conda.sh。这里的conda应该是您用来管理您的papermill和jupyter所在python环境的相同conda。 点击 这里 获取更多关于conda的信息. -
conda.path默认设置为/opt/anaconda3/etc/profile.d/conda.sh。 如果您不清楚您的conda环境在哪里,只需要在命令行执行conda info | grep -i 'base environment'即可获得。
注意:
Jupyter任务插件使用source命令激活conda环境, 如果您的租户没有source命令使用权限,Jupyter任务插件将无法使用。
3.3.20.3 Python依赖管理
3.3.20.3.1 使用预装好的Conda环境
- 手动或使用
shell任务在您的目标机器上创建conda环境。 - 在您的
jupyter任务中,将condaEnvName设置为您在上一步创建的conda环境名。
3.3.20.3.2 使用打包的Conda环境
- 使用 Conda-Pack 将您的conda环境打包成
tarball. - 将您打包好的conda环境上传到
资源中心. - 在您的
jupyter任务资源设置中,添加您在上一步中上传的conda环境包,如jupyter_env.tar.gz.
提示:请您按照 Conda-Pack 官方指导打包conda环境, 正确打包出的conda环境包解压后文件目录结构应和下图完全一致:
.
├── bin
├── conda-meta
├── etc
├── include
├── lib
├── share
└── ssl
注意:请严格按照上述conda pack指示操作,并且不要随意修改bin/activate。 Jupyter任务插件使用source命令激活您打包的conda环境。 若您对使用source命令有安全性上的担忧,请使用其他方法管理您的python依赖。
3.3.20.3.3 由依赖需求文本文件临时构建
- 在
资源中心创建或上传.txt格式的python依赖需求文本文件。 - 将
jupyter任务中的condaEnvName参数设置成您的python依赖需求文本文件,如requirements.txt。 - 在您
jupyter任务的资源中选取您的python依赖需求文本文件,如requirements.txt。
如下是一个依赖需求文本文件的样例,通过该文件,jupyter任务插件会自动构建您的python依赖,并执行您的python代码, 执行完成后会自动释放临时构建的环境。
fastjsonschema==2.15.3
fonttools==4.33.3
geojson==2.5.0
identify==2.4.11
idna==3.3
importlib-metadata==4.11.3
importlib-resources==5.7.1
ipykernel==5.5.6
ipython==8.2.0
ipython-genutils==0.2.0
jedi==0.18.1
Jinja2==3.1.1
json5==0.9.6
jsonschema==4.4.0
jupyter-client==7.3.0
jupyter-core==4.10.0
jupyter-server==1.17.0
jupyterlab==3.3.4
jupyterlab-pygments==0.2.2
jupyterlab-server==2.13.0
kiwisolver==1.4.2
MarkupSafe==2.1.1
matplotlib==3.5.2
matplotlib-inline==0.1.3
mistune==0.8.4
nbclassic==0.3.7
nbclient==0.6.0
nbconvert==6.5.0
nbformat==5.3.0
nest-asyncio==1.5.5
notebook==6.4.11
notebook-shim==0.1.0
numpy==1.22.3
packaging==21.3
pandas==1.4.2
pandocfilters==1.5.0
papermill==2.3.4
3.3.20.4 创建任务
- 点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
- 工具栏中拖动
 到画板中,即可完成创建。
到画板中,即可完成创建。
3.3.20.5 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| Conda Env Name | Conda环境或打包的Conda环境包名称 |
| Input Note Path | 输入的jupyter note模板路径 |
| Output Note Path | 输出的jupyter note路径 |
| Jupyter Parameters | 用于对接jupyter note参数化的JSON格式参数 |
| Kernel | Jupyter notebook 内核 |
| Engine | 用于执行Jupyter note的引擎名称 |
| Jupyter Execution Timeout | 对于每个jupyter notebook cell设定的超时时间 |
| Jupyter Start Timeout | 对于jupyter notebook kernel设定的启动超时时间 |
| Others | 传入papermill命令的其他参数 |
3.3.20.6 任务样例
3.3.20.6.1 简单的Jupyter任务样例
这个示例展示了如何创建Jupyter任务节点:
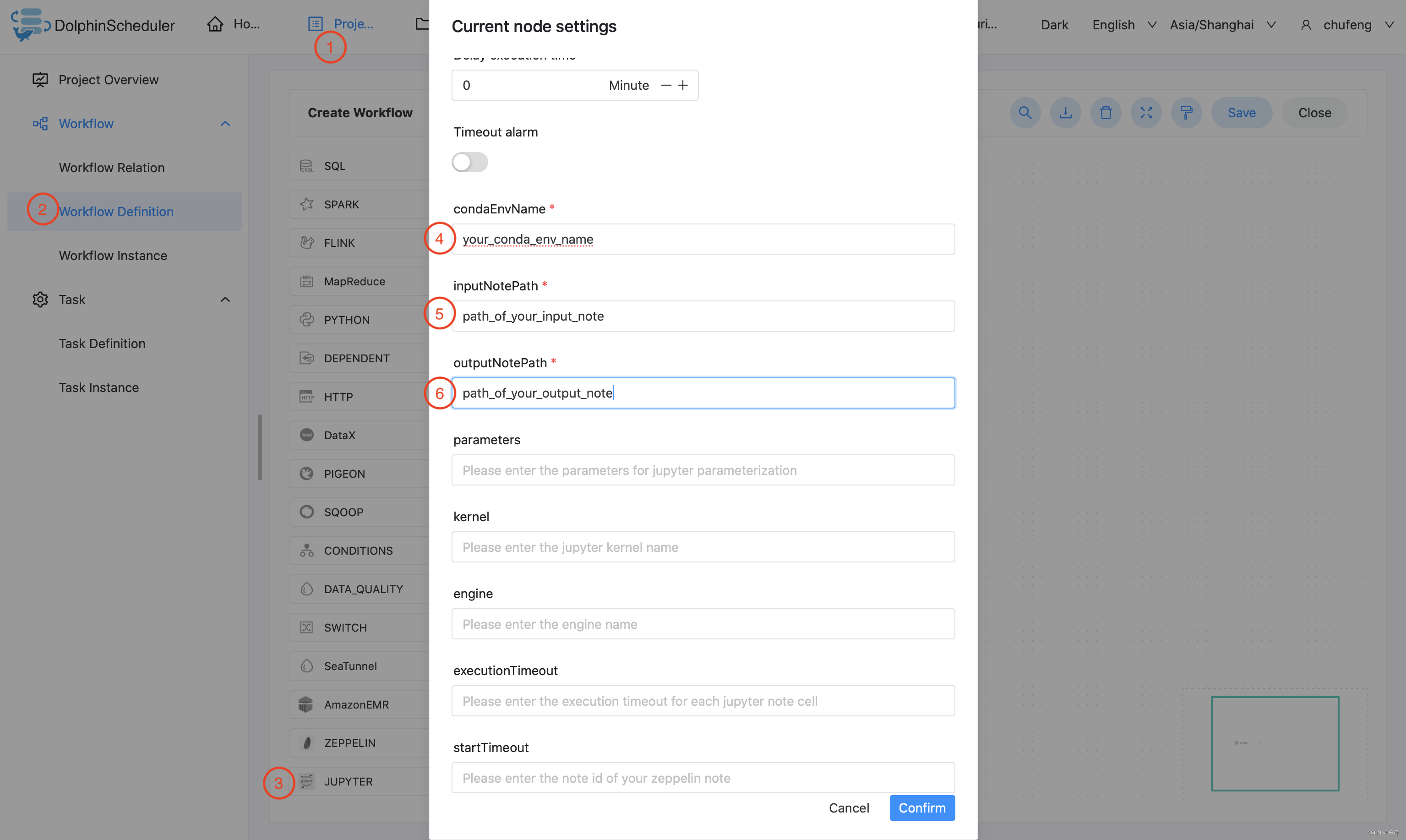
3.3.21 Hive CLI
3.3.21.1 综述
使用Hive Cli任务插件创建Hive Cli类型的任务执行SQL脚本语句或者SQL任务文件。 执行任务的worker会通过hive -e命令执行hive SQL脚本语句或者通过hive -f命令执行资源中心中的hive SQL文件。
3.3.21.2 Hive CLI任务 VS 连接Hive数据源的SQL任务
在DolphinScheduler中,我们有Hive CLI任务插件和使用Hive数据源的SQL插件提供用户在不同场景下使用,您可以根据需要进行选择。
-
Hive CLI任务插件直接连接HDFS和Hive Metastore来执行hive类型的任务,所以需要能够访问到对应的服务。 执行任务的worker节点需要有相应的Hivejar包以及Hive和HDFS的配置文件。 但是在生产调度中,Hive CLI任务插件能够提供更可靠的稳定性。 -
使用Hive数据源的SQL插件不需要您在worker节点上有相应的Hivejar包以及Hive和HDFS的配置文件,而且支持Kerberos认证。 但是在生产调度中,若调度压力很大,使用这种方式可能会遇到HiveServer2服务过载失败等问题。
3.3.21.3 创建任务
- 点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
- 工具栏中拖动
 到画板中,即可完成创建。
到画板中,即可完成创建。
3.3.21.4 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| Hive Cli 任务类型 | Hive Cli任务执行方式,可以选择FROM_SCRIPT或者FROM_FILE。 |
| Hive SQL 脚本 | 手动填入您的Hive SQL脚本语句。 |
| Hive Cli 选项 | Hive Cli的其他选项,如--verbose来查看任务结果。 |
| 资源 | 如果您选择FROM_FILE作为Hive Cli任务类型,您需要在资源中选择Hive SQL文件。 |
3.3.21.5 任务样例
Hive CLI任务样例:下面的样例演示了如何使用Hive CLI任务节点执行Hive SQL脚本语句:
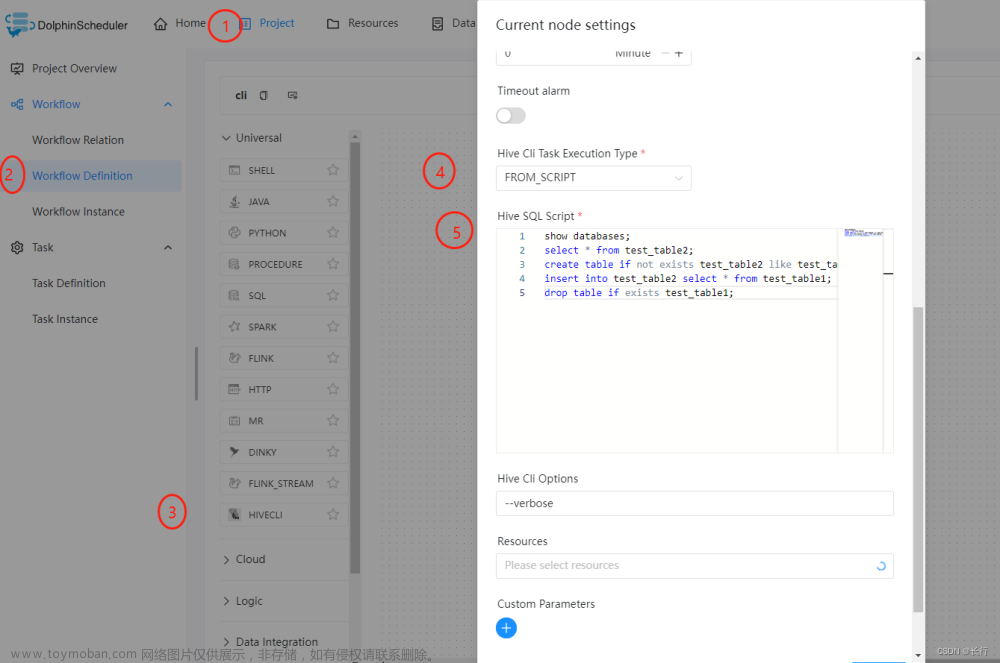
下面的样例演示了如何使用Hive CLI任务节点从资源中心的Hive SQL
3.3.22 Kubernetes
3.3.22.1 综述
kubernetes任务类型,用于在kubernetes上执行一个短时和批处理的任务。worker最终会通过使用kubernetes client提交任务。
3.3.22.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
- 工具栏中拖动
 到画板中,选择需要连接的数据源,即可完成创建。
到画板中,选择需要连接的数据源,即可完成创建。
3.3.22.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 命名空间 | 选择kubernetes集群上存在的命名空间 |
| 最小CPU | 任务在kubernetes上运行所需的最小CPU |
| 最小内存 | 任务在kubernetes上运行所需的最小内存 |
| 镜像 | 镜像地址 |
| 自定义参数 | kubernetes任务局部的用户自定义参数,自定义参数最终会通过环境变量形式存在于容器中,提供给kubernetes任务使用 |
3.3.22.4 任务样例
在 DolphinScheduler 中配置 kubernetes 集群环境:若生产环境中要是使用到 kubernetes 任务类型,则需要预先配置好所需的kubernetes集群环境
配置 kubernetes 任务节点:根据上述参数说明,配置所需的内容即可。
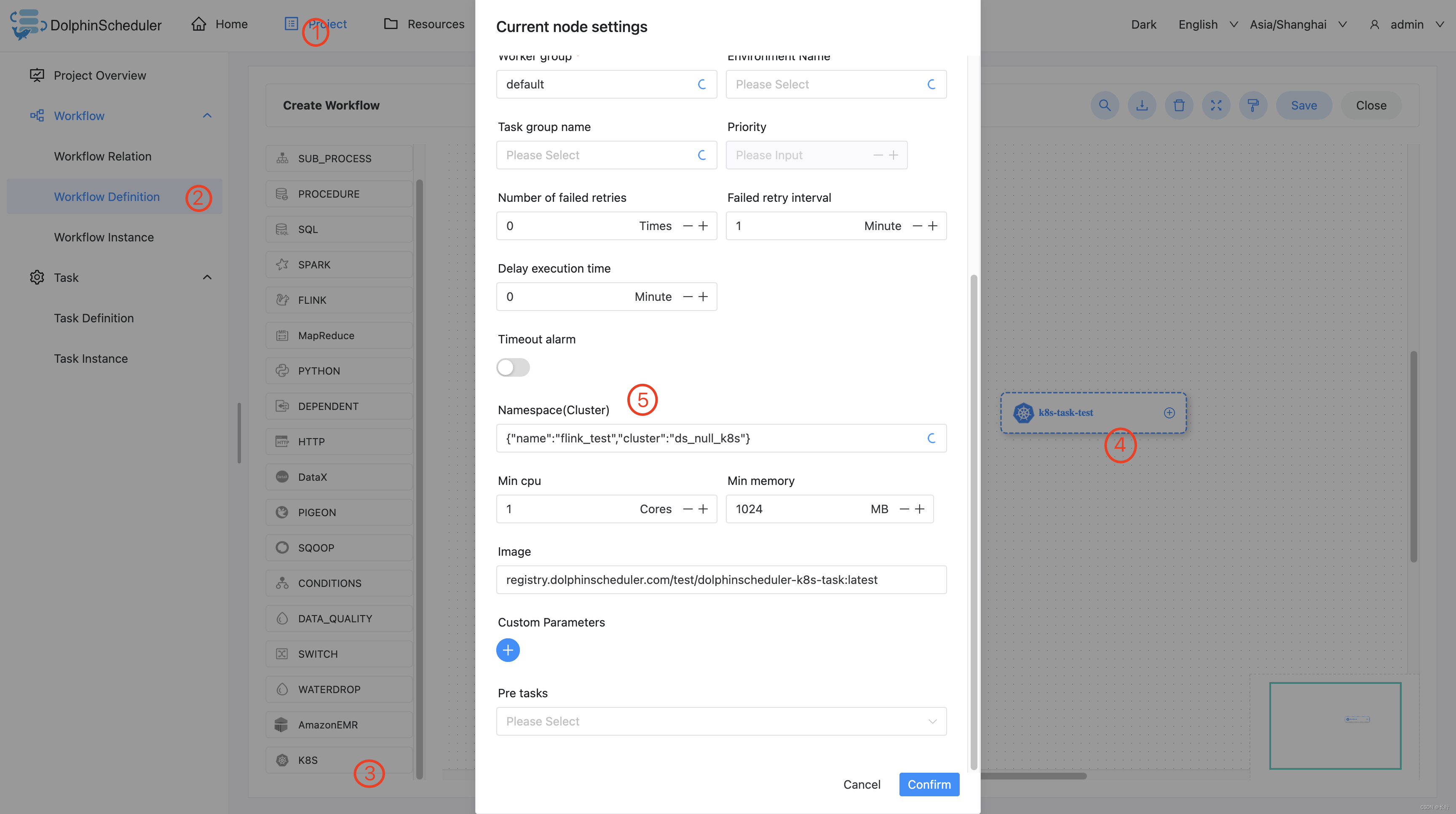
3.3.22.5 注意事项
任务名字限制在小写字母、数字和-这三种字符之中。
3.3.23 MLflow
3.3.23.1 综述
MLflow 是一个MLops领域一个优秀的开源项目, 用于管理机器学习的生命周期,包括实验、可再现性、部署和中心模型注册。
MLflow 组件用于执行 MLflow 任务,目前包含Mlflow Projects,和MLflow Models。(Model Registry将在不就的将来支持)。
- MLflow Projects: 将代码打包,并可以运行到任务的平台上。
- MLflow Models: 在不同的服务环境中部署机器学习模型。
- Model Registry: 在一个中央存储库中存储、注释、发现和管理模型 (你也可以在你的MLflow project 里面自行注册模型)。
目前 Mlflow 组件支持的和即将支持的内容如下中:
- MLflow Projects
- BasicAlgorithm: 基础算法,包含LogisticRegression, svm, lightgbm, xgboost
- AutoML: AutoML工具,包含autosklean, flaml
- Custom projects: 支持运行自己的MLflow Projects项目
- MLflow Models
- MLFLOW: 直接使用
mlflow models serve部署模型。 - Docker: 打包 DOCKER 镜像后部署模型。
- MLFLOW: 直接使用
3.3.23.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的

任务节点到画板中。
3.3.23.3 任务样例
默认参数说明请参考 3.3.30 默认任务参数。
以下是一些MLflow 组件的常用参数
| 任务参数 | 描述 |
|---|---|
| MLflow Tracking Server URI | MLflow Tracking Server 的连接,默认 http://localhost:5000 |
| 实验名称 | 任务运行时所在的实验,若实验不存在,则创建。若实验名称为空,则设置为Default,与 MLflow 一样 |
3.3.23.3.1 MLflow Projects
BasicAlgorithm:
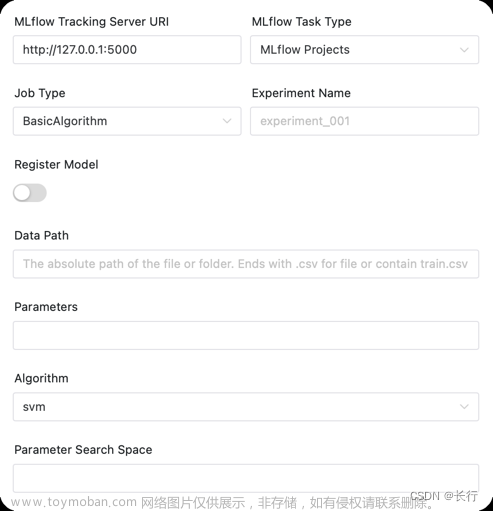
| 任务参数 | 描述 |
|---|---|
| 注册模型 | 是否注册模型,若选择注册,则会展开以下参数 |
| 注册的模型名称 | 注册的模型名称,会在原来的基础上加上一个模型版本,并注册为Production |
| 数据路径 | 文件/文件夹的绝对路径,若文件需以.csv结尾(自动切分训练集与测试集),文件夹需包含train.csv和test.csv(建议方式,用户应自行构建测试集用于模型评估)。详细的参数列表如下: LogisticRegression SVM lightgbm xgboost |
| 算法 | 选择的算法,目前基于 scikit-learn 形式支持 lr,svm,lightgbm,xgboost
|
| 参数搜索空间 | 运行对应算法的参数搜索空间,可为空。如针对lightgbm 的 max_depth=[5, 10];n_estimators=[100, 200] 则会进行对应搜索。约定传入后会以;切分各个参数,等号前的名字作为参数名,等号后的名字将以python eval执行得到对应的参数值 |
AutoML:
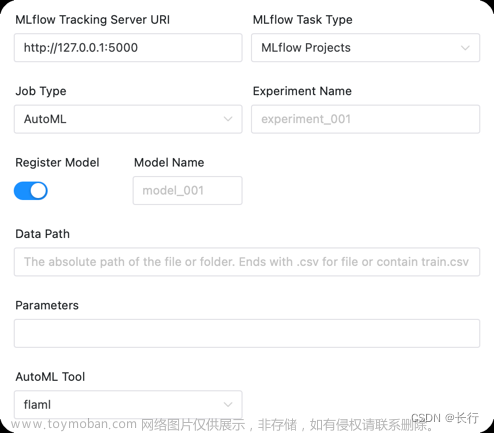
| 任务参数 | 描述 |
|---|---|
| 注册模型 | 是否注册模型,若选择注册,则会展开以下参数 |
| 注册的模型名称 | 注册的模型名称,会在原来的基础上加上一个模型版本,并注册为Production |
| 数据路径 | 文件/文件夹的绝对路径,若文件需以.csv结尾(自动切分训练集与测试集),文件夹需包含train.csv和test.csv(建议方式,用户应自行构建测试集用于模型评估) |
| 参数 | 初始化AutoML训练器时的参数,可为空,如针对 flaml 设置time_budget=30;estimator_list=['lgbm']。约定传入后会以; 切分各个参数,等号前的名字作为参数名,等号后的名字将以python eval执行得到对应的参数值。详细的参数列表如下: flaml,autosklearn
|
| AutoML工具 | 使用的AutoML工具,目前支持 autosklearn,flaml |
Custom projects:
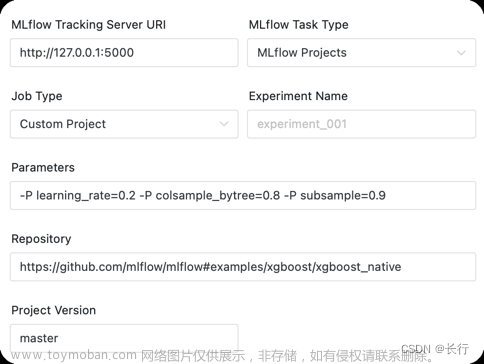
| 任务参数 | 描述 |
|---|---|
| 参数 |
mlflow run中的 --param-list 如 -P learning_rate=0.2 -P colsample_bytree=0.8 -P subsample=0.9
|
| 运行仓库 | MLflow Project的仓库地址,可以为github地址,或者worker上的目录,如MLflow project位于子目录,可以添加 # 隔开,如 https://github.com/mlflow/mlflow#examples/xgboost/xgboost_native
|
| 项目版本 | 对应项目中git版本管理中的版本,默认 master |
现在你可以使用这个功能来运行github上所有的MLflow Projects (如 MLflow examples )了。你也可以创建自己的机器学习库,用来复用你的研究成果,以后你就可以使用DolphinScheduler来一键操作使用你的算法库。
3.3.23.3.2 MLflow Models
| 任务参数 | 描述 |
|---|---|
| 部署模型的URI | MLflow 服务里面模型对应的URI,支持 models:/<model_name>/suffix 格式 和 runs:/ 格式 |
| 监听端口 | 部署服务时的端口 |
MLFLOW:

Docker:

3.3.23.4 环境准备
3.3.23.4.1 conda 环境配置
请提前安装anaconda 或者安装miniconda
方法A:
配置文件:/dolphinscheduler/conf/env/dolphinscheduler_env.sh。
在文件最后添加内容
# 配置你的conda环境路径
export PATH=/opt/anaconda3/bin:$PATH
方法B:
你需要进入admin账户配置一个conda环境变量。
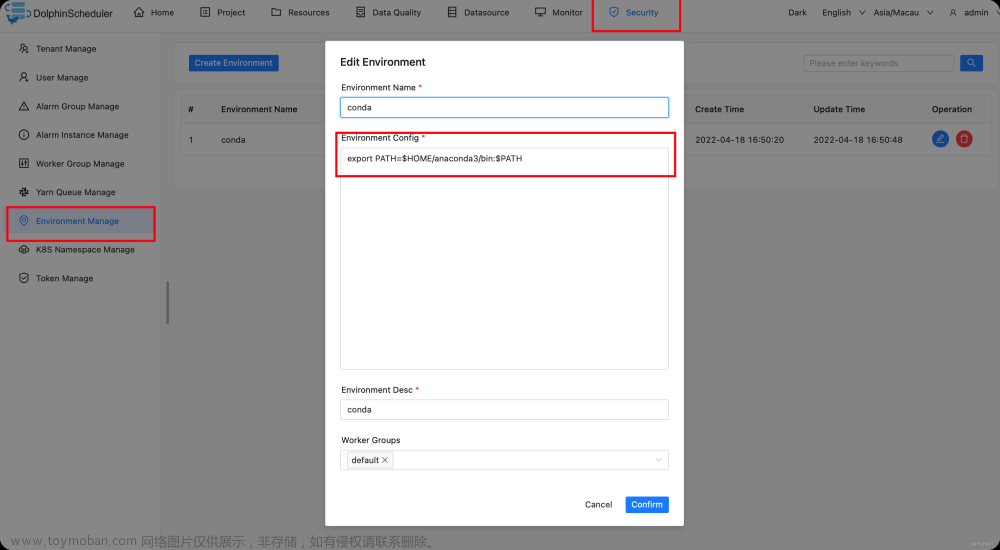
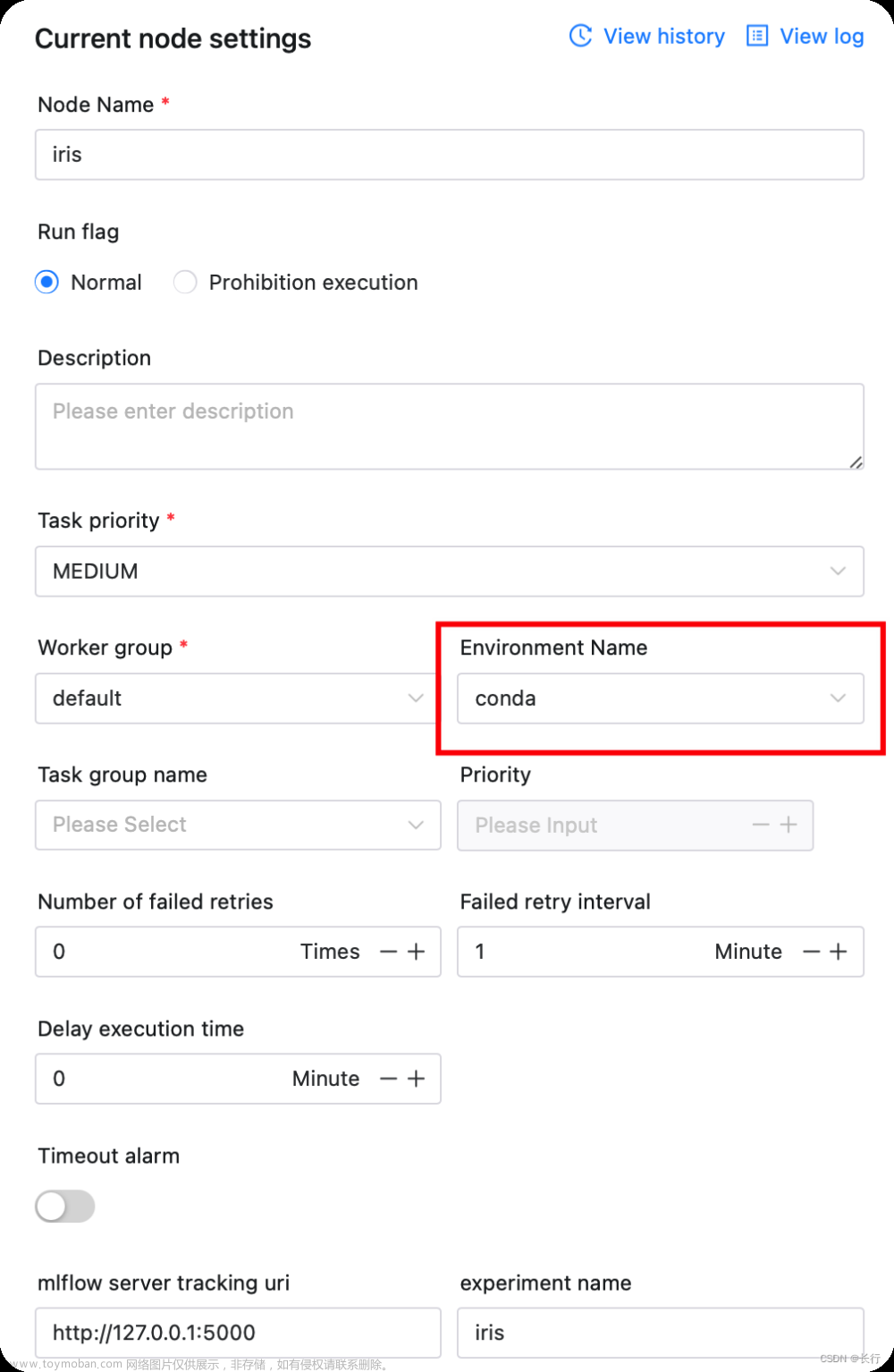
后续注意配置任务时,环境选择上面创建的conda环境,否则程序会找不到conda环境。
3.3.23.4.2 MLflow service 启动
确保你已经安装MLflow,可以使用pip install mlflow进行安装。
在你想保存实验和模型的地方建立一个文件夹,然后启动 mlflow service。
mkdir mlflow
cd mlflow
mlflow server -h 0.0.0.0 -p 5000 --serve-artifacts --backend-store-uri sqlite:///mlflow.db
运行后会启动一个MLflow服务。
可以通过访问 MLflow service (http://localhost:5000) 页面查看实验与模型。
3.3.23.4.3 内置算法仓库配置
如果遇到github无法访问的情况,可以修改commom.properties配置文件的以下字段,将github地址替换能访问的地址。
# mlflow task plugin preset repository
ml.mlflow.preset_repository=https://github.com/apache/dolphinscheduler-mlflow
# mlflow task plugin preset repository version
ml.mlflow.preset_repository_version="main"
3.3.24 Openmldb
3.3.24.1 综述
OpenMLDB 是一个优秀的开源机器学习数据库,提供生产级数据及特征开发全栈解决方案。
OpenMLDB任务组件可以连接OpenMLDB集群执行任务。
3.3.24.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.24.3 任务样例
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| zookeeper地址 | OpenMLDB集群连接地址中的zookeeper地址, e.g. 127.0.0.1:2181 |
| zookeeper路径 | OpenMLDB集群连接地址中的zookeeper路径, e.g. /openmldb |
| 执行模式 | 初始执行模式(离线/在线),你可以在sql语句中随时切换 |
| SQL语句 | SQL语句 |
下面有几个例子:
3.3.24.3.1 导入数据
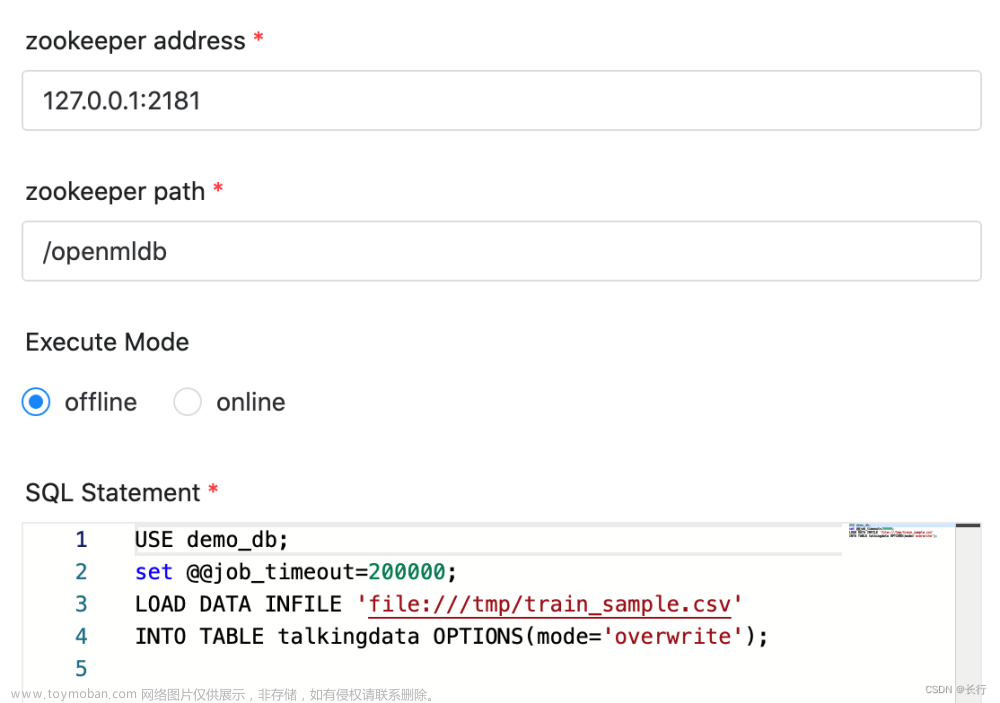
我们使用LOAD DATA语句导入数据到OpenMLDB集群。因为选择的是离线执行模式,所以将会导入数据到离线存储中。
3.3.24.3.2 特征抽取
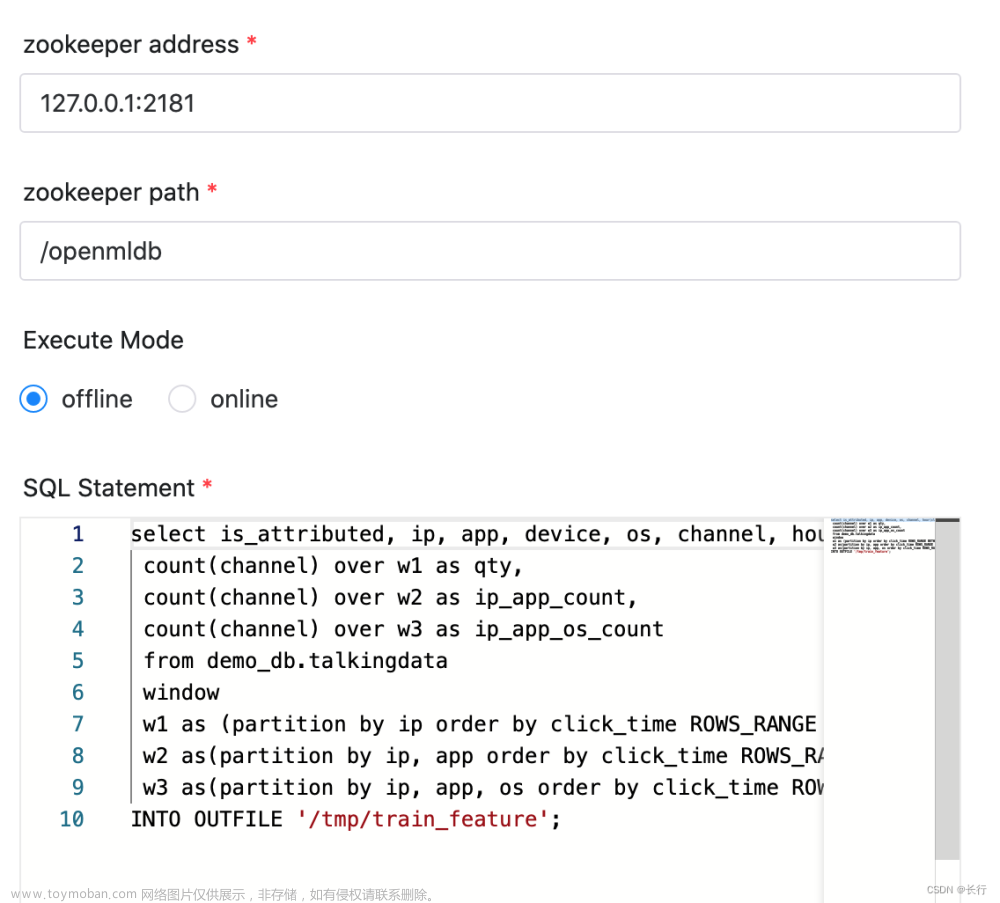
我们使用SELECT INTO进行特征抽取。因为选择的是离线执行模式,所以会使用离线引擎做特征计算。
3.3.24.4 环境准备
3.3.24.4.1 OpenMLDB 启动
执行任务之前,你需要启动OpenMLDB集群。如果是在生产环境,请参考 deploy OpenMLDB.
你可以参考 在docker中运行OpenMLDB集群 快速启动。
3.3.24.4.2 Python 环境
OpenMLDB任务组件将使用OpenMLDB Python SDK来连接OpenMLDB。所以你需要Python环境。
我们默认使用python3,你可以通过配置PYTHON_HOME来设置自己的Python环境。
请确保已通过pip install openmldb,在worker server的主机中安装了OpenMLDB Python SDK。
3.3.25 DVC
3.3.25.1 综述
DVC(Data Version Control) 是一个MLops领域一个优秀的开机器学习版本管理系统。
DVC 组件用于在DS上使用DVC的数据版本管理功能,帮助用户简易地进行数据的版本管理。组件提供如下三个功能:
- Init DVC: 将git仓库初始化为DVC仓库,并绑定存储数据的地址用于存储实际的数据。
- Upload: 将特定数据添加或者更新到仓库中,并记录版本号。
- Download: 从仓库中下载特定版本的数据。
3.3.25.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.25.3 任务样例
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| DVC任务类型 | 可以选择 Upload、Download、Init DVC |
| DVC仓库 | 任务执行时关联的仓库地址 |
3.3.25.3.1 Init DVC
将git仓库初始化为DVC仓库, 并绑定数据储存的地方。
项目初始化后,仍然为git仓库,不过添加了DVC的特性。
实际上数据并不保存在git仓库,而是存储在另外的地方,DVC会跟踪数据的版本和地址,并处理好这个关系。
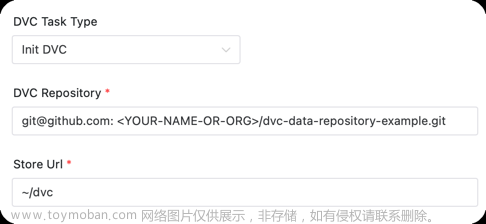
任务参数:
- 数据存储地址 :实际的数据保存的地址,支持的类型可见 DVC supported storage types 。
如上述例子表示: 将仓库 git@github.com:<YOUR-NAME-OR-ORG>/dvc-data-repository-example.git 初始化为DVC项目,并绑定远程储存地址为 ~/dvc
3.3.25.3.2 Upload
用于上传和更新数据,并记录版本号。

任务参数:
- DVC仓库中的数据路径 :上传的数据保存到仓库的地址。
- Worker中数据路径 :需要上传的数据的地址。
- 数据版本 :上传数据后,为该版本数据打上的版本号,会保存到 git tag 里面。
- 数据版本信息 :本次上传需要备注的信息。
如上述例子表示: 将数据 /home/data/iris 上传到仓库 git@github.com:<YOUR-NAME-OR-ORG>/dvc-data-repository-example.git 的根目录下,数据的文件/文件夹名字为iris。 然后执行 git tag "iris_1.0" -m "init iris data"。 记录版本号 iris_1.0和 版本信息 ‘inir iris data’
3.3.25.3.3 Download
用于下载特定版本的数据。
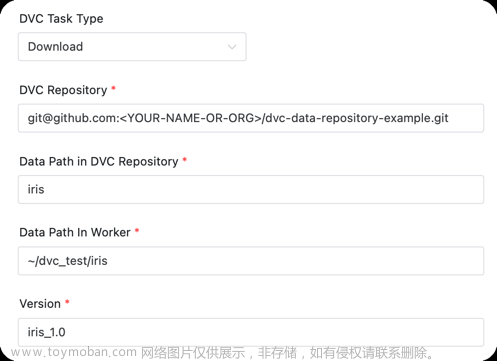
任务参数:
- DVC仓库中的数据路径 :需要下载数据在仓库中的路径。
- Worker中数据路径 :数据下载到本地后的保存地址。
- 数据版本 :需要下载的数据的版本。
如上述例子表示: 将仓库 git@github.com:xxxx/dvc-data-repository-example.git 版本为 iris_1.0 的 iris 的数据下载到 ~/dvc_test/iris
3.3.25.4 环境准备
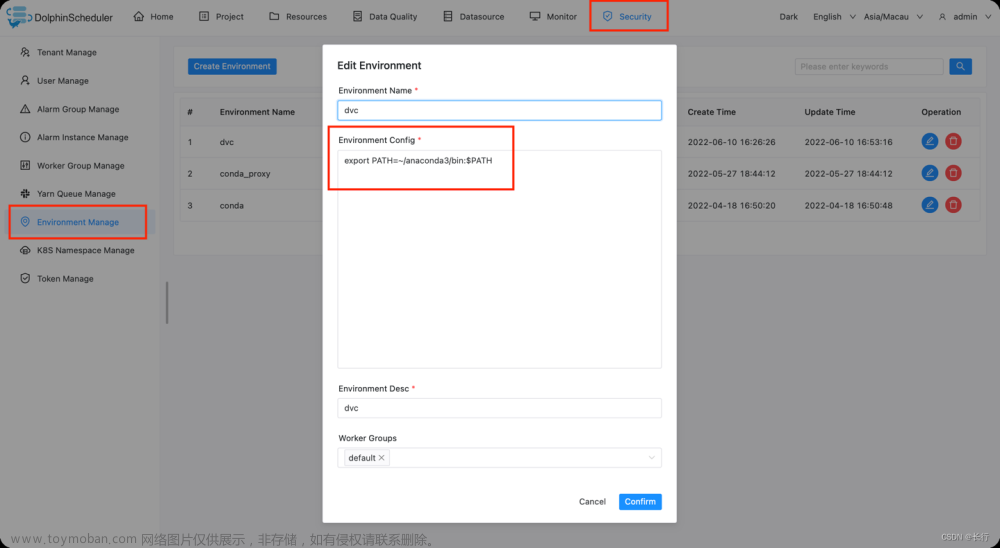
3.3.25.4.1 dvc 安装
确保你已经安装DVC可以使用pip install dvc进行安装。
获取dvc地址, 并配置环境变量
下面以 conda 上的 python pip 安装为例子,配置 conda 的环境变量,使得组件能正确找到dvc命令
which dvc
# >> ~/anaconda3/bin/dvc
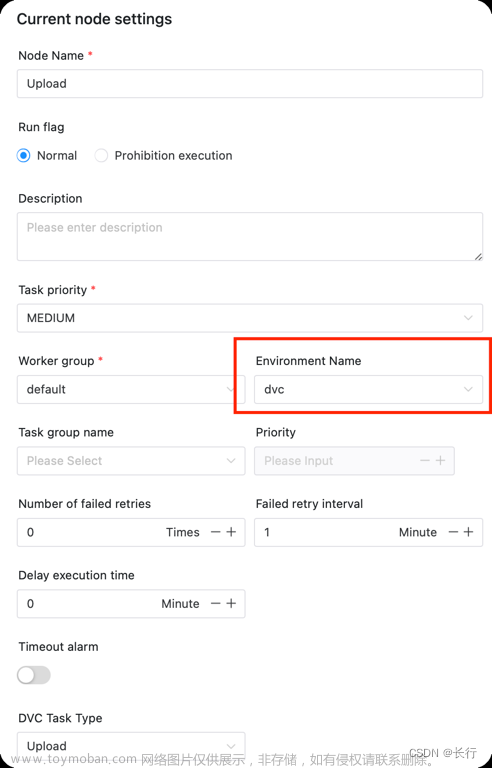
你需要进入admin账户配置一个conda环境变量(请提前安装anaconda 或者安装miniconda )。
后续注意配置任务时,环境选择上面创建的conda环境,否则程序会找不到conda环境。
3.3.26 Dinky
3.3.26.1 综述
Dinky任务类型,用于创建并执行Dinky类型任务以支撑一站式的开发、调试、运维 FlinkSQL、Flink Jar、SQL。worker 执行该任务的时候,会通过Dinky API触发Dinky 的作业。 点击这里 获取更多关于Dinky的信息。
3.3.26.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击"创建工作流"按钮,进入DAG编辑页面。
- 工具栏中拖动
 到画板中,即可完成创建。
到画板中,即可完成创建。
3.3.26.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
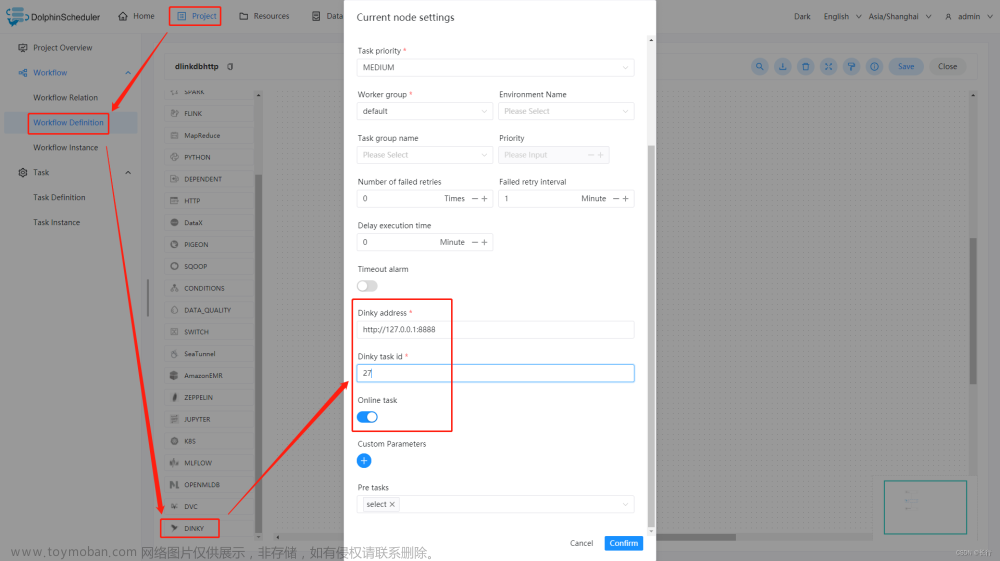
| Dinky 地址 | Dinky 服务的 url。 |
| Dinky 任务 ID | Dinky 作业对应的唯一ID。 |
| 上线作业 | 指定当前 Dinky 作业是否上线,如果是,则该被提交的作业只能处于已发布且当前无对应的 Flink Job 实例在运行才可提交成功。 |
3.3.26.4 任务样例
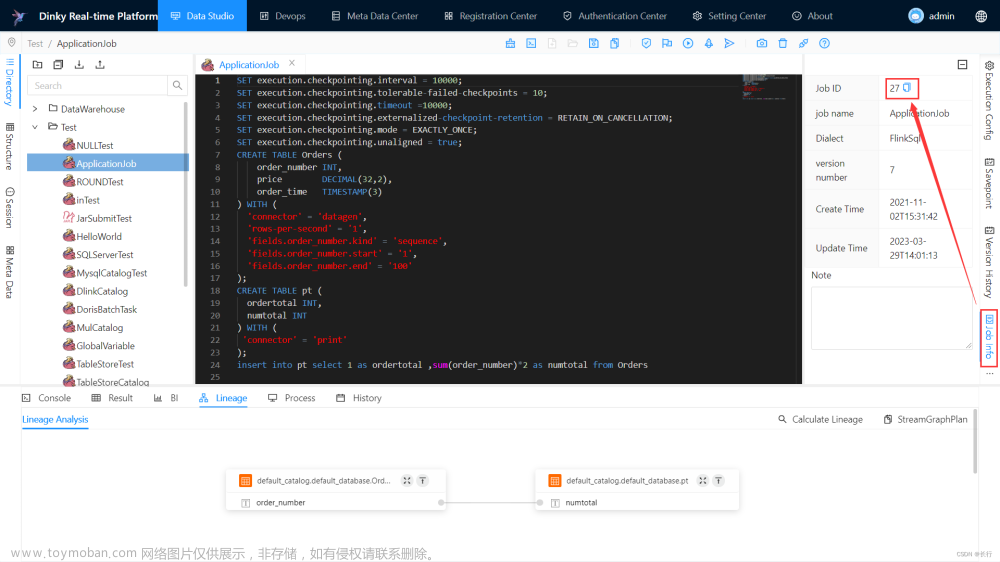
Dinky Task Example
这个示例展示了如何创建 Dinky 任务节点:
3.3.27 SageMaker
3.3.27.1 综述
Amazon SageMaker 是一个云机器学习平台。 提供了完整的基础设施,工具和工作流来帮助用户可以创建、训练和发布机器学习模型。
Amazon SageMaker Model Building Pipelines 是一个可以直接使用SageMaker各种集成的机器学习管道构建工具,用户可以使用使用 Amazon SageMaker Pipeline 来构建端到端的机器学习系统。
对于使用大数据与人工智能的用户,SageMaker 任务组件帮助用户可以串联起大数据工作流与SagaMaker的使用场景。
DolphinScheduler SageMaker 组件的功能:
- 启动 SageMaker Pipeline Execution,并持续获取状态,直至Pipeline执行完成。
3.3.27.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
3.3.27.3 任务样例
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
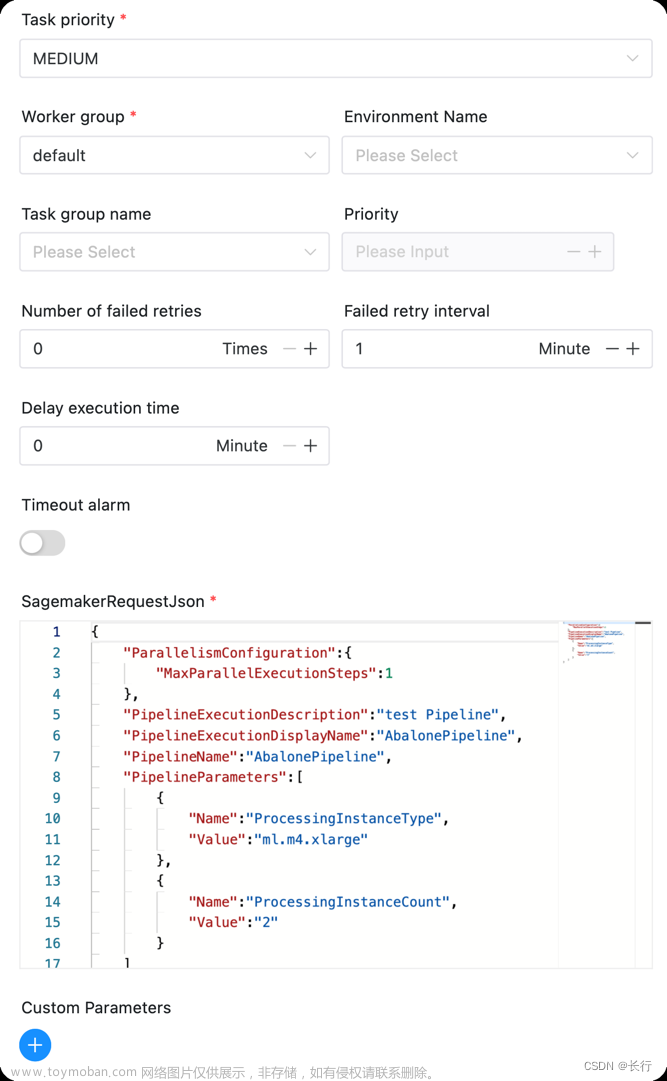
| SagemakerRequestJson | 启动SageMakerPipeline的需要的请求参数,可见 AWS API |
组件图示如下:
3.3.27.4 环境配置
需要进行AWS的一些配置,修改common.properties中的xxxxx为你的配置信息
# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.access.key.id=<YOUR AWS ACCESS KEY>
# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.secret.access.key=<YOUR AWS SECRET KEY>
# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.region=<AWS REGION>
3.3.28 ChunJun
3.3.28.1 综述
ChunJun 任务类型,用于执行 ChunJun 程序。对于 ChunJun 节点,worker 会通过执行 ${CHUNJUN_HOME}/bin/start-chunjun 来解析传入的 json 文件。
3.3.28.2 创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的 任务节点到画板中。
3.3.28.3 任务参数
默认参数说明请参考 3.3.30 默认任务参数。
| 任务参数 | 描述 |
|---|---|
| 自定义模板 | 自定义 ChunJun 节点的 json 配置文件内容,当前支持此种方式。 |
| json | ChunJun 同步的 json 配置文件。 |
| 自定义参数 | 用户自定义参数,会替换脚本中以 ${变量} 的内容。 |
| 部署方式 | 执行ChunJun任务的方式,比如local,standalone等。 |
| 选项参数 | 支持 -confProp "{\"flink.checkpoint.interval\":60000}" 格式。 |
3.3.28.4 任务样例
该样例演示为从 Hive 数据导入到 MySQL 中。
在 DolphinScheduler 中配置 ChunJun 环境。若生产环境中要是使用到 ChunJun 任务类型,则需要先配置好所需的环境。配置文件如下:/dolphinscheduler/conf/env/dolphinscheduler_env.sh。
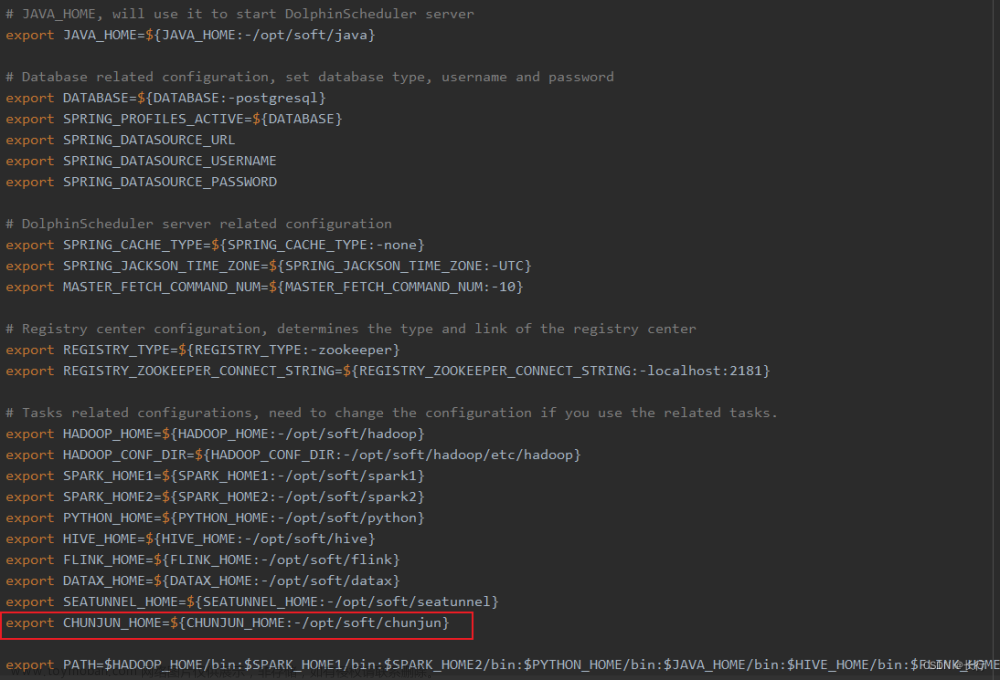
当环境配置完成之后,需要重启 DolphinScheduler。
配置 ChunJun 任务节点。从 Hive 中读取数据,所以需要自定义 json,可参考:Hive Json Template
3.3.29 Pytorch 节点(试验版)
3.3.29.1 综述
Pytorch 是一个的主流Python机器学习库。
为了用户能够在DolphinScheduler中更方便的运行Pytorch项目,实现了Pytorch任务组件。主要提供便捷的python环境管理以及支持运行python项目。
与Python任务组件不同,该组件允许用户快速使用已有python环境或者创建新的python环境(使用virtualenv或者conda);支持运行Python项目(本地项目或者Git项目)而非只是python脚本。
3.3.29.2 创建任务
- 点击项目管理-项目名称-工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
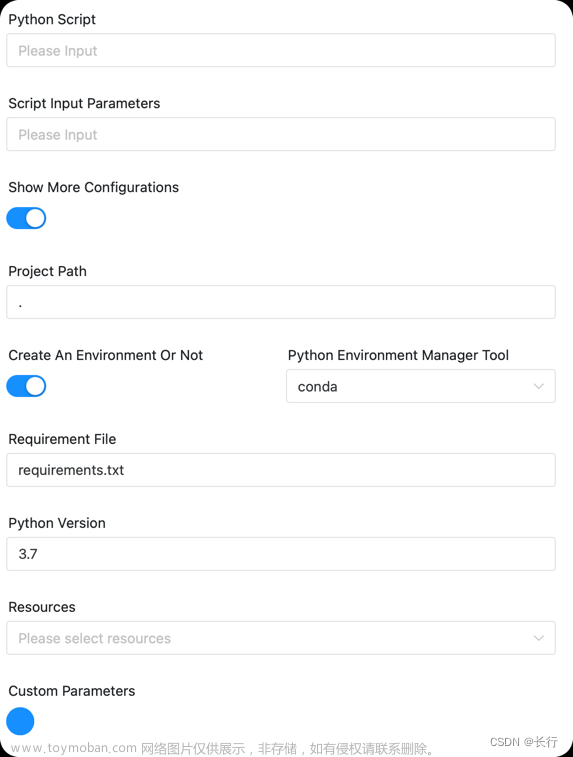
3.3.29.3 任务样例
组件图示如下:
Pytorch参数:
默认参数说明请参考 3.3.30 默认任务参数。
运行参数:
| 任务参数 | 描述 |
|---|---|
| python脚本 | 需要运行的python脚本文件入口 |
| 脚本启动参数 | 运行时的输入参数 |
以上为两个最小化配置运行的参数,另外提供其他的一些配置参数如下可选,当选择展开更多配置时,可以配置更多参数。
| 任务参数 | 描述 |
|---|---|
| python项目地址 | 设置PYTHONPATH环境变量,设置后运行python脚本时可以加载该地址下的python包/项目代码。支持本地路径或者Git url。若为本地路径,作为PYTHONPATH环境变量,如果为Git URL (以`git@ |
python环境参数:
| 任务参数 | 描述 |
|---|---|
| 是否创建新环境 | 是否创建新的python环境来运行该任务 |
| python命令路径 | 如/usr/bin/python,默认为DS环境配置中的${PYTHON_HOME}
|
| python环境管理工具 | 可以选择virtualenv或者conda,若选择virtualenv,则会用virtualenv创建一个新环境,使用命令 virtualenv -p ${PYTHON_HOME} venv 创建;若选择conda, 则会使用conda 创建一个新环境,并需要指定创建的python版本 |
| 依赖文件 | 默认为 requirements.txt |
配置了python项目地址参数,那么python脚本和依赖文件参数允许输入相对路径
Demo:
如现在需要运行 https://github.com/pytorch/examples 项目下的mnist的子项目。
可以设置
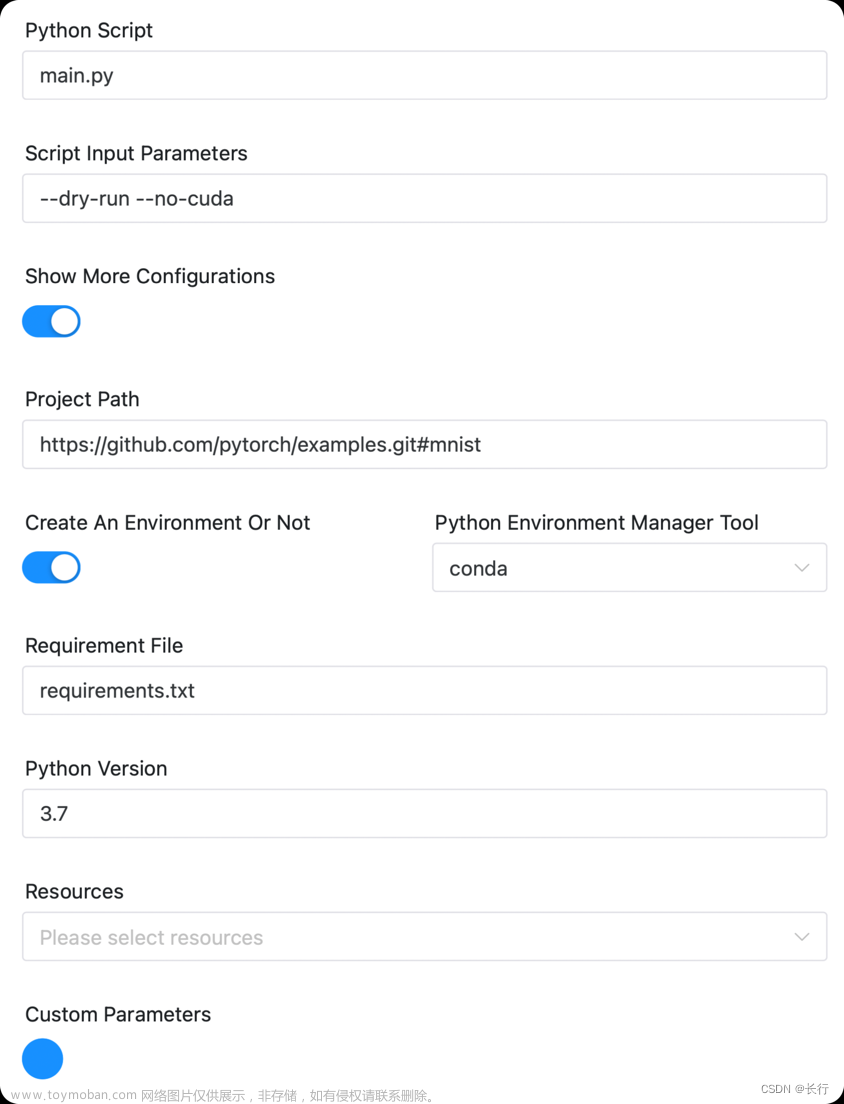
另外如果代码存放在资源中心,则可以使用资源参数下载代码,并将相关参数写成对应资源的路径即可。
3.3.29.4 环境配置
环境配置主要取决于运行时python环境的选择,需要在安全中心-环境管理中配置对应需要的环境变量即可。
指定python路径:
适用于worker上已经有运行该项目的python环境,那么可以直接在组件中配置pyhton命令路径为对应的python环境即可,如果不知道该环境地址,可以使用which python获取。
使用Conda创建新环境:
适用于新建环境运行该项目,需要在安全中心-环境管理中创建环境, 参考如下添加修改为实际环境即可。
# conda命令对应的目录加入PATH中
export PATH=$HOME/anaconda3/bin:$PATH
使用virtualenv创建新环境:
适用于新建环境运行该项目,需要在安全中心-环境管理中创建环境, 参考如下添加修改为实际环境即可。
# virtualenv命令对应的目录加入PATH中
export PATH=/home/lucky/anaconda3/bin:$PATH
export PYTHON_HOME=/usr/local/bin/python3.7
3.3.29.5 其他
本组件也可以运行xgboost, lightgbm, sklearn, tensorflow, keras 等项目。本组件可作为python组件运行机器学习任务的升级组件。文章来源:https://www.toymoban.com/news/detail-761301.html
如果有需要,后续建议可以统一涵盖为PythonML组件,来运行机器学习项目。文章来源地址https://www.toymoban.com/news/detail-761301.html
3.3.30 默认任务参数
| 任务参数 | 描述 |
|---|---|
| 任务名称 | 任务的名称,同一个工作流定义中的节点名称不能重复。 |
| 运行标志 | 标识这个节点是否需要调度执行,如果不需要执行,可以打开禁止执行开关。 |
| 描述 | 当前节点的功能描述。 |
| 任务优先级 | worker线程数不足时,根据优先级从高到低依次执行任务,优先级一样时根据先到先得原则执行。 |
| Worker分组 | 设置分组后,任务会被分配给worker组的机器机执行。若选择Default,则会随机选择一个worker执行。 |
| 任务组名称 | 任务资源组,未配置则不生效。 |
| 组内优先级 | 一个任务组内此任务的优先级。 |
| 环境名称 | 配置任务执行的环境。 |
| 失败重试次数 | 任务失败重新提交的次数,可以在下拉菜单中选择或者手动填充。 |
| 失败重试间隔 | 任务失败重新提交任务的时间间隔,可以在下拉菜单中选择或者手动填充。 |
| CPU 配额 | 为执行的任务分配指定的CPU时间配额,单位为百分比,默认-1代表不限制,例如1个核心的CPU满载是100%,16个核心的是1600%。 task.resource.limit.state |
| 最大内存 | 为执行的任务分配指定的内存大小,超过会触发OOM被Kill同时不会进行自动重试,单位MB,默认-1代表不限制。该功能由 task.resource.limit.state 控制。 |
| 超时告警 | 设置超时告警、超时失败。当任务超过"超时时长"后,会发送告警邮件并且任务执行失败。该功能由 task.resource.limit.state 控制。 |
| 资源 | 任务执行时所需资源文件 |
| 前置任务 | 设置当前任务的前置(上游)任务。 |
| 延时执行时间 | 任务延迟执行的时间,以分为单位 |
到了这里,关于大数据|海豚调度官方文档注解(3)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!