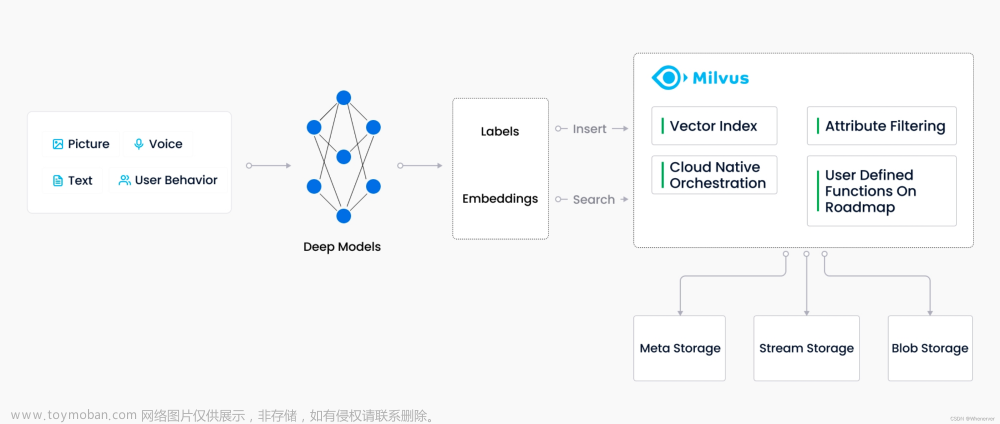
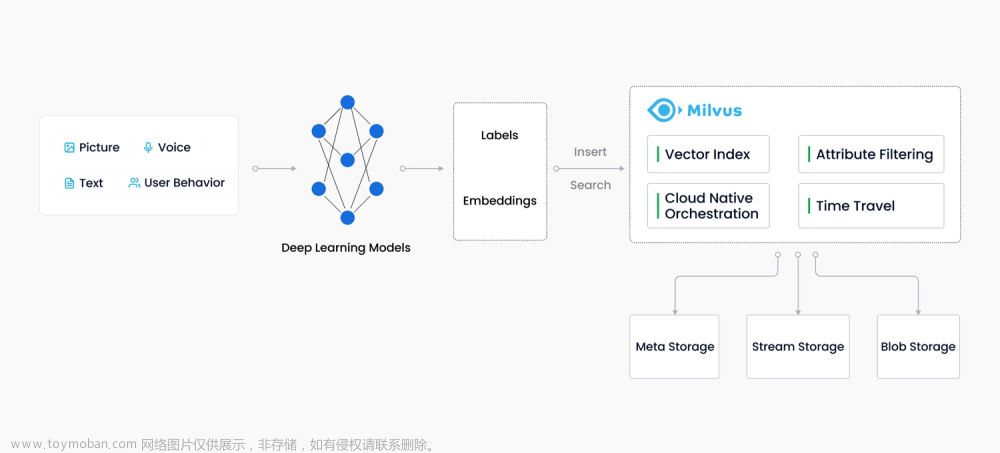
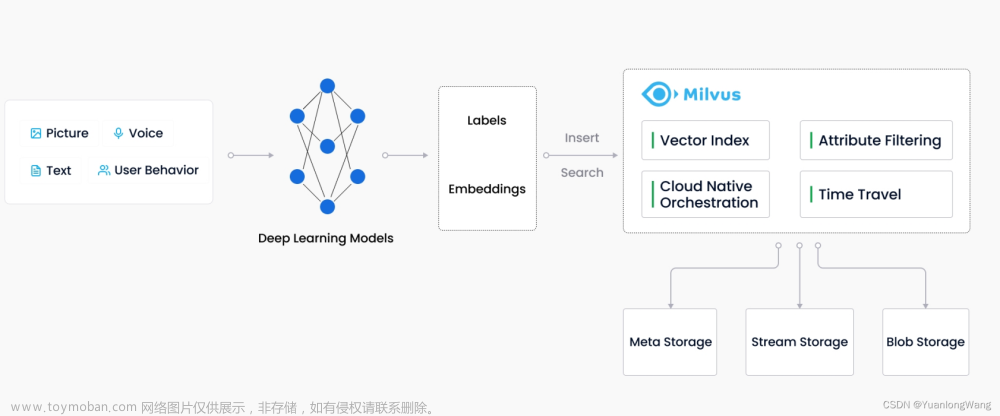
本文主要基于milvus官方的材料外加自己的一些理解整理而来,欢迎交流
设计理念
云原生:存&算分离; 读写分离; 增量存量分离; 微服务架构,极致弹性;
日志即数据:通过message queue解耦生产者、消费着,降低系统复杂度; 提升index、data、query模块弹性;
流批一体:表和日志二象性;流式数据分段固化持久化,提供快速恢复能力;通过TSO保证顺序;
#个人解读:
1.设计理念非常贴近技术前沿,利用开源组件来承载流、批数据高可靠/可用存储,实现计算、存储、索引构建解耦&极致弹性,这种技术方案非常优雅。
2.通过pub-sub机制改变了传统数据主节点-备节点-只读节点依靠binlog进行数据复制的玩法,只有datanode一种消费者角色(可以认为kafka,pular本身就是master;另外queryNode、indexNode是为了减少各功能间耦合性从dataNode中剥离出,逻辑上还是dataNode的一部分)
3. 事实上,不少开源厂商比如图数据库TigerGraph也是这种玩法,我给其起个名字:把简单留给自己,把困难留给巨人。勇敢点,踩着巨人,你也会成为巨人。
4. 其实日志即数据、流批一体都是Flink设计精髓, 也就是Kappa架构

产品探讨
- 自身定位:Milvus 主要是做向量域的近似查询的数据库
- Milvus 首先不是一个关系型数据库,不会支持特别复杂的 JOIN 之类的查询,也不会支持 ACID 的事务
- Milvus 不是一个搜索引擎,跟传统的 Elasticsearch、Solr 之间也有很大区别。Milvus 针对的是 embedding 向量数据,而不是传统的文本格式的数据。对于文本来说,Milvus 做的是基于语义的检索,而不是基于关键词的检索
- 业务层面:非独立解决方案,需要用户组合使用
别的系统比如tsdb、mongdb、es、graph、rdis等等都可以独立提供服务。从milus目前提供的所有场景看,其只提供向量检索这种抽象进, 抽象出的能力:入口一般为query vector,出口为相似向量id,需要借助其他技术来提供整体解决方案,比如:
- 文本检索:上游:BERT; 下游:mysql
- 问答系统:上游:BERT; 下游:mysql
- 推荐系统(电影特征抽取):上游:PaddlePaddle; 下游:redis或者mysql
- 图片检索:上游:ResNet-50; 下游:mysql
- 视频推荐:上游:OpenCV抽取视频关键帧,ResNet-50图片特征向量抽取;下游:Mysql,OSS
- 音频检索:上游:PANNs (Large-Scale Pretrained Audio Neural Networks):下游:Object Storage
- 分子结构:上游:RDKit; 下游:mysql
- DNA序列发现:上游:CountVectorizer;下游: 下游:mysql
个人解读:前后端场景多、技术差异性大,要做好需要很大工程能力,可能还是推出使用案例,引导用户自行构建整体系统这条路比较容易。
- 产品能力:用户需要了解很多细节,有门槛
- 用户来指定partition:并按照partition精细化管理其entity
- 人工干预操作:比如flush、load_collection, load_partition等
- Entity不支持去重:用过RDBMS的用户会很麻烦,需要先抽取特征,检索并根据精确度来判断是否重复
- 类型系统有限:string类型正在开发中
- 不支持transaction,但支持四种一致性
- 强一致性:GuaranteeTs 设为系统最新时间戳,QueryNodes 需要等待 ServiceTime 推进到 当前最新时间戳才能执行该 Search 请求;
- 最终一致性:GuaranteeTs 设为一个特别小的值(比如说设为 1),跳过一致性检查,立刻在当 前已有数据上执行 Search 查询;
- 有界一致性:GuaranteeTs 是一个比系统最新时间稍旧的时间,在可容忍范围内可以立刻执行查询;
- 客户端一致性:客户端使用上一次写入的时间戳作为 GuaranteeTs,那么每个客户端至少能看到 自己插入的全部数据

- 性能&成本问题
- milvus查询需要sealed seg和growing seg都加载到QueryNode的内存中才能计算,大数据量下成本高
- 随机向量检索场景下如果采用内存换入换出的思路会有性能问题
- 虽然开源,没有自己的生态,容易被云厂商集成
这点由2所决定的,并且其主打的多模态查询、云原生、Log as data、流批一体这些概念在云原生数据库基本也都是标配,据我所知,阿里云数据库这边是个产品都会集成向量检索的能力,卷起来比谁都狠。
整体架构
包括LB、Access Layer、Coordinator Service、Message Storage、WorkerNode四类,如下图:

Access layer:请求接入
Proxy
- serverless,高弹性
- 所有请求入口
- 并发处理:查询请求通过pub-sub分到多个queryNode中,proxy对最终结果进行荟聚

Coordinator service:
接收任务并分发给对应worker node,主要工作包括:集群拓扑管理、负载均衡、TSO时间生成器、数据管理等(应该不具备动态扩容能力,靠k8s快速拉起?)
RootCoord:集群controller
- DDL/DCL处理:比如collection/partition/index等创建以及删除;
- TSO时钟服务: 时钟timer tick;提供ts服务
- collect生命期状态管理:
- collection channel分配:分配vchannel到pchannel映射
- segment alloc:接收DataCoord分配的segId并持久化
- segment index build:接收DataNode flush seg结束请求,并trigger IndexCoord去build index
QueryCoord:查询服务的controller
- 处理请求:LoadCollection, LoadPartition, ReleaseCollection, ReleasePartition
- QueryNode集群管理
- Collection数据负载均衡:每个queryNode分配若干个Dmchannel,让查询最大程度并行化
DataCoord:数据服务的controller
- 管理信息:datanode信息、channel列表以及消费各datanode消费位点、<collection, partiton, segment>等信息
- DataNode集群管理和负载均衡,目前两种策略:
- 按pchannel一致性哈希,每个dataNode可能管理对应多个pchannel,导致不均衡
- 保证每个collection的pchannel分布在不同的dataNode上
- 触发flush、compact等后端数据操作
IndexCoord:索引构建服务的controller
- 管理信息:indexnode信息、indexMetable(index-related task)
- 处理四类请求:
- watchNodeLoop: 监控indexNode离线、在线状态
- watchMetaLoop: 监控Meta变化(indexNode触发并写入etcd,indexcoord更新本地)
- assignTaskLoop : 从metaTable取任务并发起索引构建任务
- recycleUnusedIndexFiles:异步删除无用索引文件

Worker nodes:具体任务执行者
负责具体执行来自coord的任务; 每类节点只负责部分segment的处理;所有节点无状态,可以按需平滑扩容文章来源:https://www.toymoban.com/news/detail-771322.html
QueryNode:对其所管理的segment进行流批一体化查询
- 从MessageQueue消费增量日志并写入到growing segments中进行增量查询
- 从object storage load加载seal seg进行存量数据查询
DataNode:对其所管理的segment进行持久化
- 消费增量数据写入growing segments并通过log snapshot持久化
- growing segments flush,条件:
- entity条数超过配置
- 用户调用flush
- 超过一定时间
- 重启后恢复flowgraph(对应一个collection的一个segment):
- 通过WatchDmChannels从datacoord中获取vchannel state位点信息
- 如何保证消费不丢不重? datanode在每次flush时都通过RPC SaveBinlogPaths 告诉datacoord,并datacoord将其更新到etcd中
IndexNode: 对其所管理的segment进行全量索引构建
- 接收index coord的请求从存储层提取Segment提取数据并构建索引,写入index File中;
Storage:高可用高可靠数据承载着
[etcd] metadata storage 元数据信息持久化
- collection schema: 存储在minio中和data、index共同存储
- node status:indexnode、datanode、querynode
- message consumption checkpoints:消费位点
[pulsar]log broker: log as data理念,流数据持久化,写节点只读节点化
- 读、写事务解耦,追加binlog方式
- 增量数据持久化,高可靠
- 查询请求异步化处理
- 查询结果异步返回
- 事件通知机制
[s3]object storage: 用户数据持久化
- 存储logs(来自datanode)、index(来自inodenode)、Delta File
- 利用本地ssd缓存来自aws s3、azure blob的结果(规划中)
周边工具
MilvusDM (Milvus Data Migration): 数据迁移
Attu:服务可视化
Milvus CLI:交互式命令行
MilvusMonitor:服务监控
Milvus sizing tool:容量评估文章来源地址https://www.toymoban.com/news/detail-771322.html
到了这里,关于向量数据库~milvus的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!