目录
一、配置Hadoop环境
1.查看Hadoop解压位置
2.配置环境变量
3.编辑环境变量
4.重启环境变量
5.查看Hadoop版本,查看成功就表示Hadoop安装成功了
二、修改配置文件
1.检查三台虚拟机:
2.切换到配置文件目录
3.修改 hadoop-env.sh 文件
4.修改 core-site.xml 文件
5.修改 mapred-site.xml 文件
6.修改 hdfs-site.xml 文件
7.修改 yarn-site.xml 文件
8.修改 workers 文件
三、给hadoop2、hadoop3分发文件
1.到存放hadoop的文件夹下
2.1.给hadoop2和hadoop3拷贝文件和环境变量
2.2.给hadoop2和hadoop3创建软连接
2.3.检查hadoop2和hadoop3是否拷贝成功
2.4.如果没有拷贝成功就将hadoop2和hadoop3的hadoop文件夹删除,然后在拷贝一次
四、修改脚本文件
1.切换到hadoop的sbin目录下
2.修改 start-dfs.sh 脚本文件
3.修改 stop-dfs.sh 脚本文件
4.修改 start-yarn.sh 脚本文件
5.修改 stop-yarn.sh 脚本文件
五、启动hadoop集群
1.格式化HDFS
2.启动hadoop
3.启动yarn
4.查看进程
5.关闭防火墙
6.访问Hadoop的web网站
7.停止hadoop
8.停止yarn
9.启动hadoop和yarn遇到的问题
六、编辑启动和停止脚本文件
1.进入脚本文件目录
2.编写集群控制文件
3.给 hadoop.sh 授权
4.启动集群,查看进程
5.停止集群,查看进程
七、编辑同步执行命令脚本
1.编辑
2.给 xcall.sh 授权
3.执行脚本
4.脚本的另一种写法
一、配置Hadoop环境
1.查看Hadoop解压位置
pwd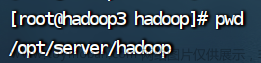
2.配置环境变量
vim /etc/profile
3.编辑环境变量
“/opt/server/hadoop”填自己Hadoop的存放位置。
export HADOOP_HOME=/opt/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin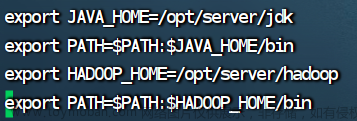
4.重启环境变量
source /etc/profile
5.查看Hadoop版本,查看成功就表示Hadoop安装成功了
hadoop version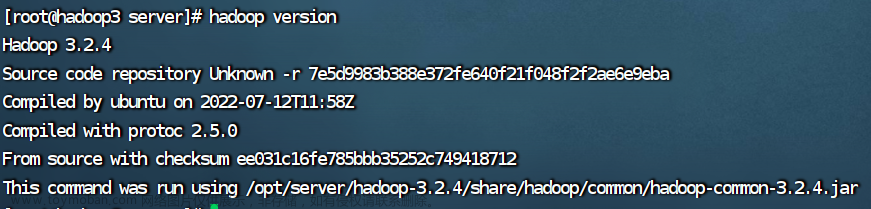
二、修改配置文件
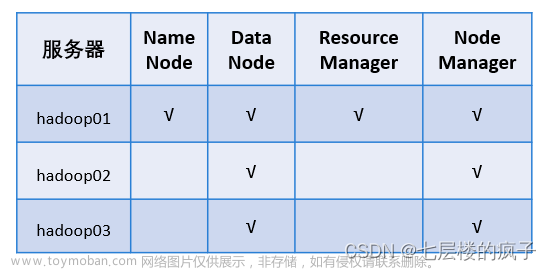
1.检查三台虚拟机:
是否都安装了jdk和hadoop并且配置了环境变量,确保虚拟机之间都能互相ping通以及两两之间能够ssh免密登陆,都完成了网卡、主机名、hosts文件等配置。
| ip地址 | 主机名 | 节点 |
|---|---|---|
| 192.168.147.200 |
hadoop | 主节点 |
| 192.168.147.201 |
hadoop2 | 子节点 |
| 192.168.147.203 |
hadoop3 | 子节点 |
2.切换到配置文件目录
cd /opt/server/hadoop/etc/hadoop
3.修改 hadoop-env.sh 文件
路径改成自己的jdk安装路径(vim命令用不了就用vi)
vim hadoop-env.sh
export JAVA_HOME=/opt/server/jdk

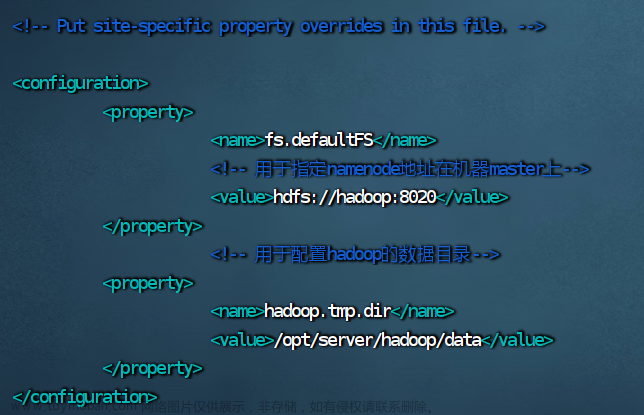
4.修改 core-site.xml 文件
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 用于指定namenode地址在机器master上-->
<value>hdfs://hadoop:8020</value>
</property>
<!-- 用于配置hadoop的数据目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/server/hadoop/data</value>
</property>
</configuration>

5.修改 mapred-site.xml 文件
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce运行时框架,这里指定在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

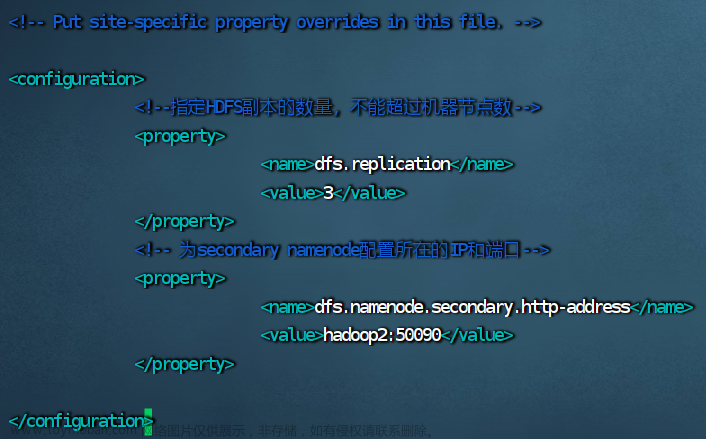
6.修改 hdfs-site.xml 文件
vim hdfs-site.xml
<configuration>
<!--指定HDFS副本的数量,不能超过机器节点数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 为secondary namenode配置所在的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:50090</value>
</property>
</configuration>
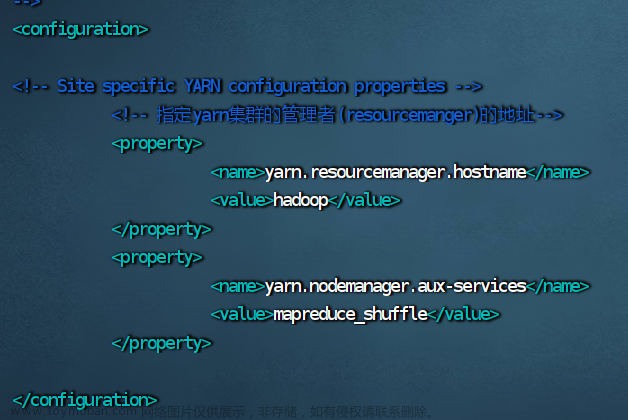
7.修改 yarn-site.xml 文件
vim yarn-site.xml
<configuration>
<!-- 指定yarn集群的管理者(resourcemanger)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

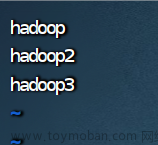
8.修改 workers 文件
vim workers
hadoop
hadoop2
hadoop3
三、给hadoop2、hadoop3分发文件
1.到存放hadoop的文件夹下
cd /opt/server/
2.1.给hadoop2和hadoop3拷贝文件和环境变量
scp -r hadoop-3.2.4/ root@hadoop2:/opt/server/hadoop-3.2.4/
scp /etc/profile root@hadoop2:/etc/profile

2.2.给hadoop2和hadoop3创建软连接
ln -s hadoop-3.2.4/ hadoop
2.3.检查hadoop2和hadoop3是否拷贝成功
hadoop的配置文件拷贝给了hadoop2和hadoop3,在hadoop2打开workers。
vim workers
hadoop2的workers没被修改,说明没拷贝成功。
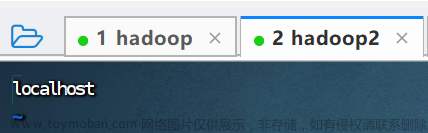
2.4.如果没有拷贝成功就将hadoop2和hadoop3的hadoop文件夹删除,然后在拷贝一次
rm -rf hadoop-3.2.4 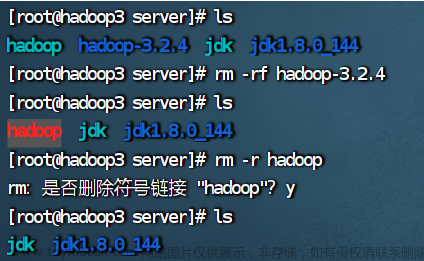
重复2.1的操作
四、修改脚本文件
1.切换到hadoop的sbin目录下
脚本文件都在sbin文件下。
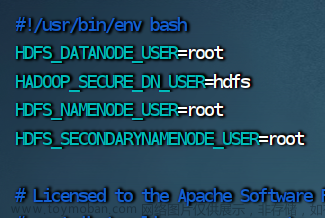
cd /opt/server/hadoop/sbin2.修改 start-dfs.sh 脚本文件
vim start-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
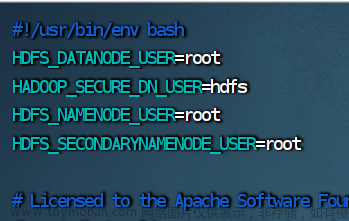
3.修改 stop-dfs.sh 脚本文件
vim stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
4.修改start-yarn.sh 脚本文件
vim start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
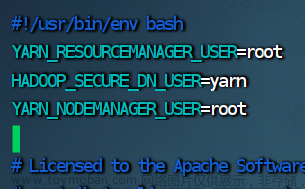
4.修改 start-yarn.sh 脚本文件
vim start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
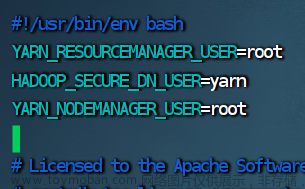
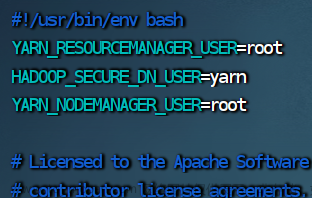
5.修改 stop-yarn.sh 脚本文件
vim stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
五、启动hadoop集群
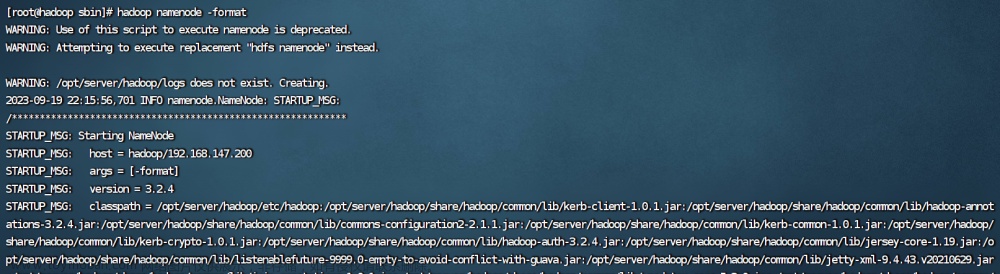
1.格式化HDFS
hadoop namenode -format
2.启动hadoop
启动hadoop和yarn一定要在sbin目录下。
./start-dfs.sh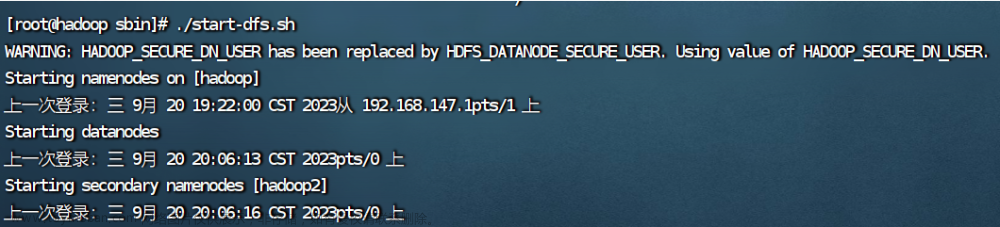
3.启动yarn
./start-yarn.sh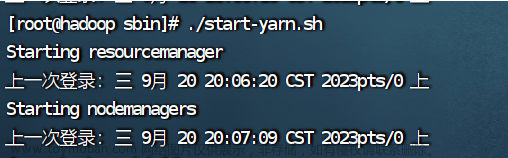
4.查看进程
jps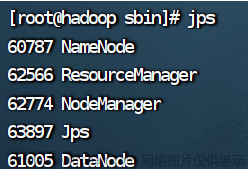
5.关闭防火墙
#关闭
systemctl stop firewalld.service
#查看
systemctl status firewalld.service
#防火墙失效设置
systemctl disable firewalld.service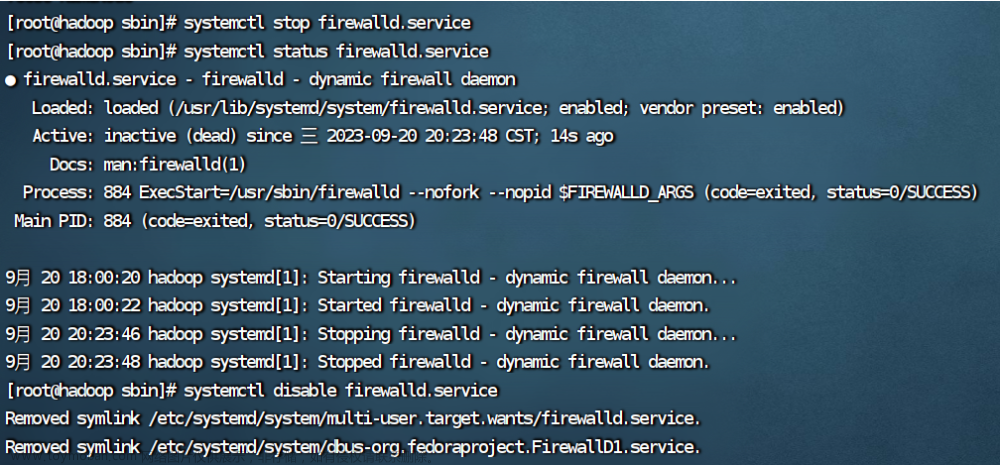
6.访问Hadoop的web网站
ip+端口
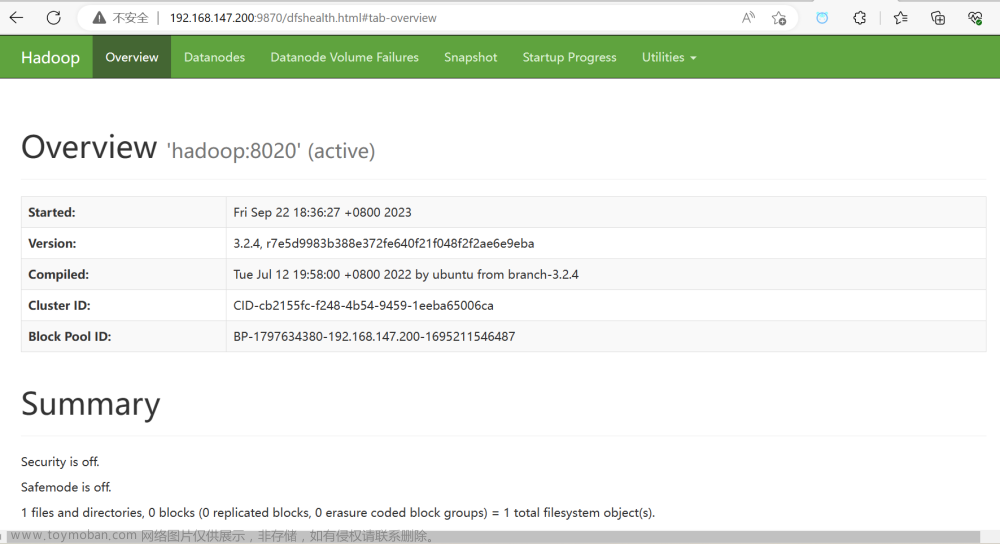
7.停止hadoop
./stop-dfs.sh
8.停止yarn
./stop-yarn.sh第一次停止yarn可能会出现以下情况:
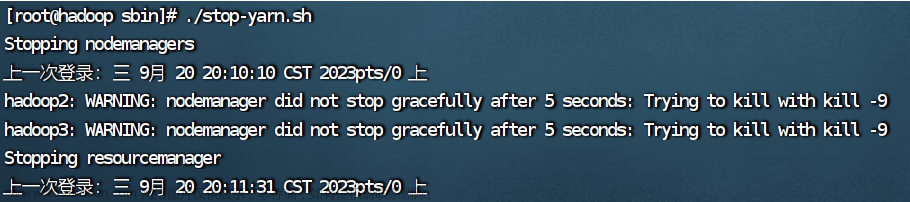
再输入一次命令就好了
9.启动hadoop和yarn遇到的问题
ERROR: JAVA_HOME is not set and could not be found.
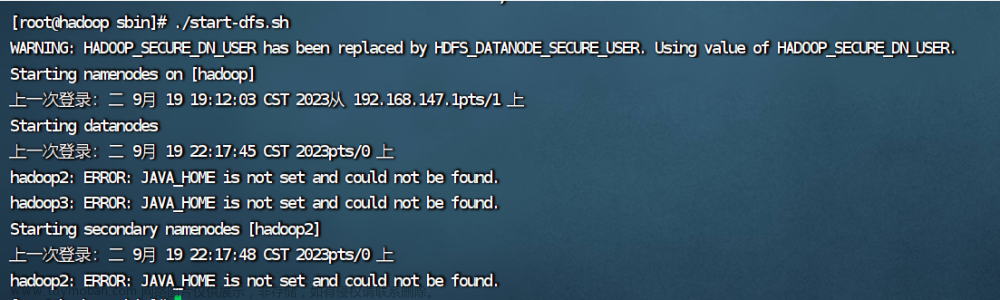
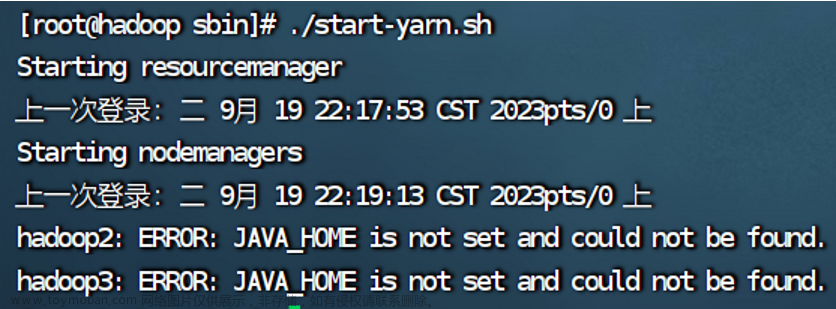
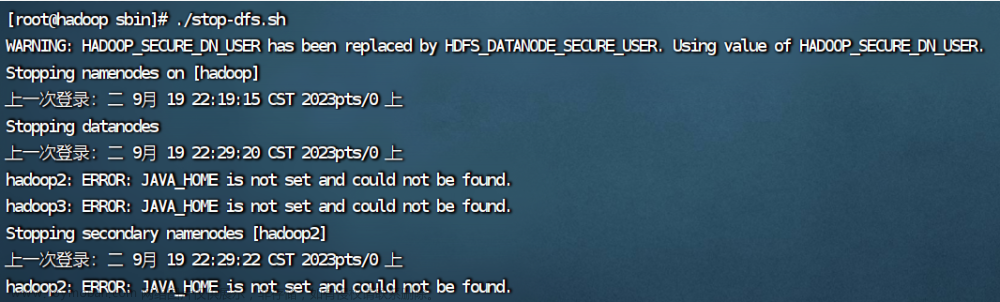
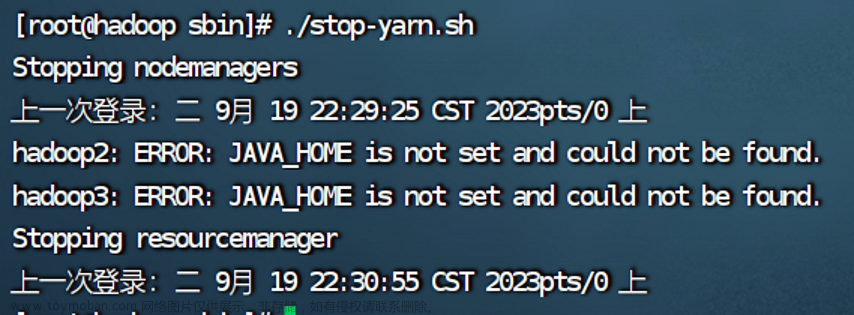
出错的原因是2.3的hadoop配置文件没有成功拷贝给hadoop2和hadoop3,解决办法在2.4。
六、编辑启动和停止脚本文件
1.进入脚本文件目录
cd /opt/script/如果没有script目录就新建一个。
mkdir script
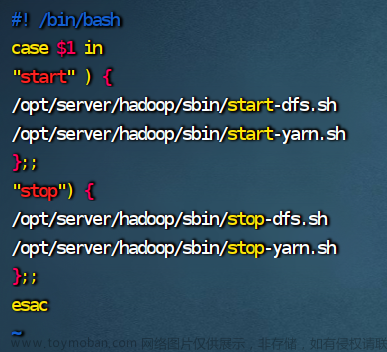
2.编写集群控制文件
vim hadoop.sh
#! /bin/bash
case $1 in
"start" ) {
/opt/server/hadoop/sbin/start-dfs.sh
/opt/server/hadoop/sbin/start-yarn.sh
};;
"stop") {
/opt/server/hadoop/sbin/stop-dfs.sh
/opt/server/hadoop/sbin/stop-yarn.sh
};;
esac

3.给 hadoop.sh 授权
chmod 777 hadoop.sh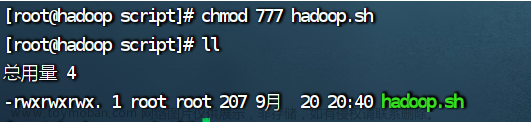
4.启动集群,查看进程
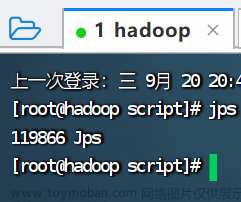
./hadoop.sh start
jps查看hadoop进程
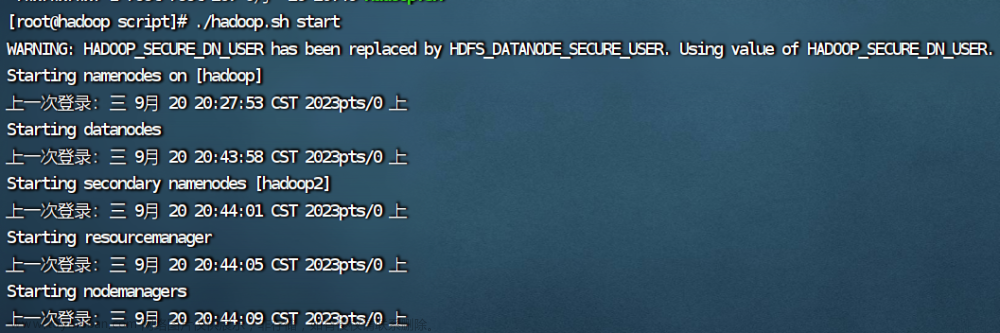

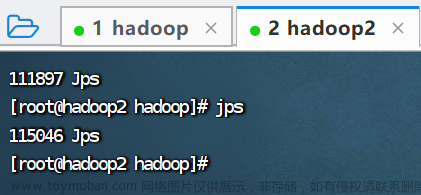
查看hadoop2进程

5.停止集群,查看进程
./hadoop.sh stop
jps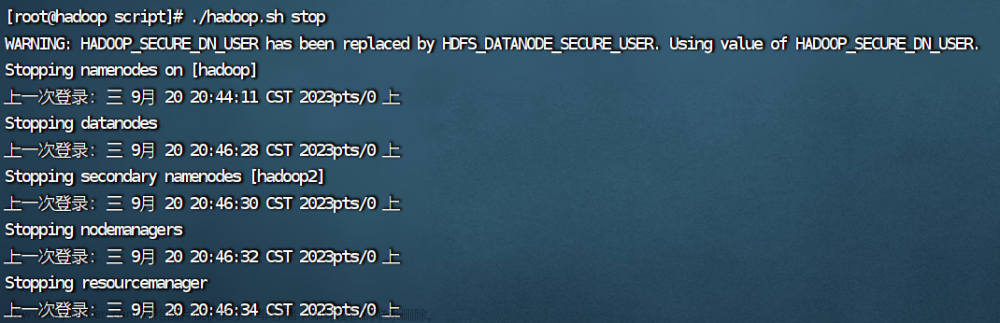
七、编辑同步执行命令脚本
1.编辑
vim xcall.sh
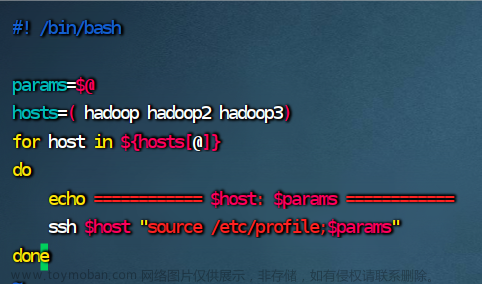
#! /bin/bash
params=$@
hosts=( hadoop hadoop2 hadoop3)
for host in ${hosts[@]}
do
echo ============ $host: $params ============
ssh $host "source /etc/profile;$params"
done
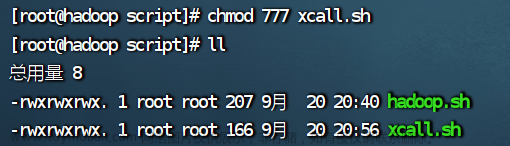
2.给 xcall.sh 授权
chmod 777 xcall.sh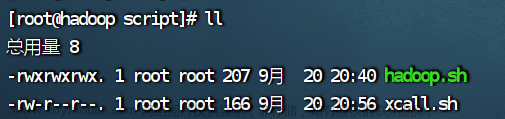
3.执行脚本
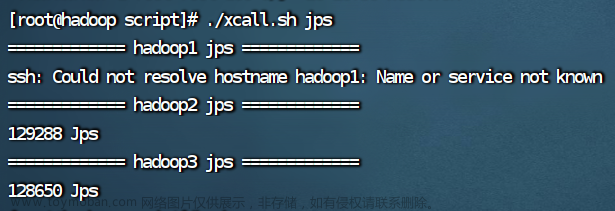
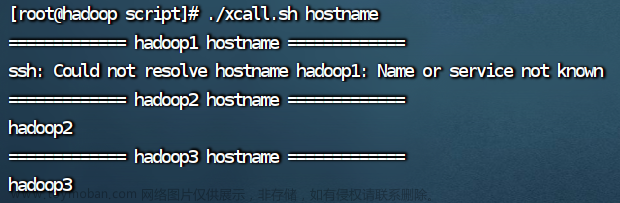
查看进程和主机名
./xcall.sh jps
./xcall.sh hostname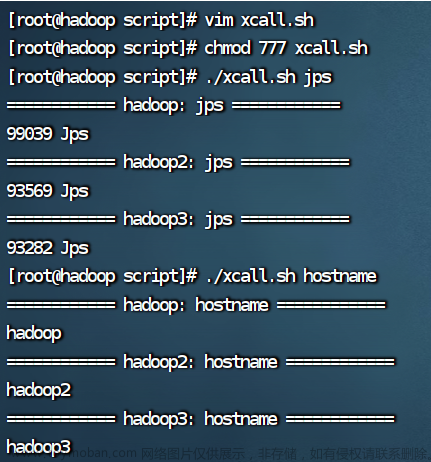
4.脚本的另一种写法
如果主机名是 hadoop1、hadoop2、hadoop3 可以用以下写法:
#! /bin/bash
params=$@
for (( i=1 ; i<=3 ; i=$i+1)) ; do
echo ============= hadoop$i $params =============
ssh hadoop$i "source /etc/profile;$params"
done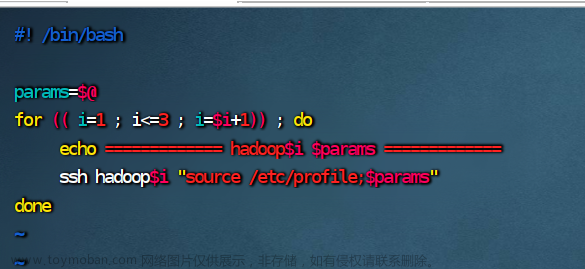 文章来源:https://www.toymoban.com/news/detail-773097.html
文章来源:https://www.toymoban.com/news/detail-773097.html
但是 hadoop、hadoop2、hadoop3用这种写法会出现以下结果:文章来源地址https://www.toymoban.com/news/detail-773097.html
到了这里,关于Linux修改hadoop配置文件及启动hadoop集群详细步骤的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!