零.全文概述:
从平时上机和作业的题目中可以看出,涉及到链表的题目基本上都是附加代码模式。
所以要解决链表的问题,我们只用做到两点:
1.知道每道题目都要用到的基本操作函数怎么写
2.结合每道题的实际情况,去具体书写题目中要求的特殊函数
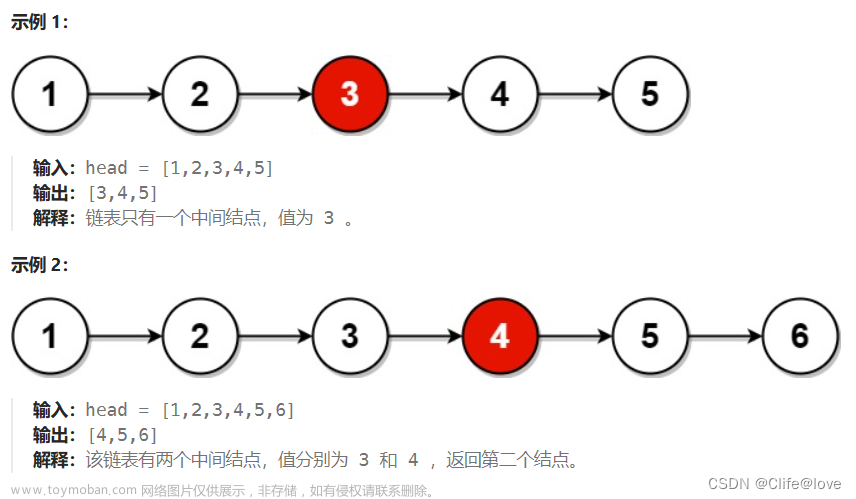
例题1:

例题2:


从例题1和例题2可以看出,提示中的单链表操作函数都是相同的,会在叁部分介绍。
而每道题还有他具体的逻辑和实现函数,会在肆部分介绍。
壹.前置知识
a. 链表综述
链表是一种物理存储单元上非连续、非顺序的存储结构。
数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
b. struct结构体的介绍
由前文我们可以知道,链表是许多节点被链条串在一起的一种数据结构。
那自然的,我们就要表示每个节点。由于此时每个节点都要即包含数据,又要包含一个(指向下个节点的)指针 。——所以此时我们采用struct结构体去表示每个节点。
表示如下:
struct Node
{
int data; //这是数据域
Node* next; //这是指针域(表示一个指针指向下一个节点)
};结构体struct的定义即是struct 变量名字,再用一个括号(括号内包含了所需的指针域和数据域),特别注意的是括号最后一定要加上表示结尾的分号!!!
对指针域的解释:此时指针是一个指向下一个节点的指针,所以指针的类型即是结构体的名字。故指针域的形式就是 结构体的名字+*(表示这是一个指针)+next(这是指针的名字,next指向下一个节点)。
另外要记得写struct的定义时是写在main函数外面的,即单独写

c. typedef的介绍
typedef是c语言的一个关键字,可以使用它来为已有的数据类型取一个新的名字(即别名)。当你为某种数据类型取别名后,这个"别名"与该数据类型本来的名字是等价的。
1.typedef的使用形式如下
typedef 数据类型 新的名字;#:要注意的是typedef的定义也是应该写在main函数外面的
2.typedef的优点:
typedef可以把某个比较复杂的东西起一个简单的别名,可以在程序的书写中更加方便,同时好的别名也可以提高程序的可读性
3.typedef在链表中的应用:
typedef Node* List;在链表中,我们习惯将struct中的指针域给typedef成List。(可以偷懒少打个指针符号)
所以在随后的书写中,看到List我们要明白他就是Node*的别名,表示的是指向链表的指针数据类型
d. 引用
引用也是取别名。可以类比typedef去理解;只是typedef是给数据类型起别名,而引用是给变量取别名
1.引用的定义与形式:
引用不是新定义一个变量,而是给已存在变量取了一个别名,(编译器不会为引用变量开辟内存空间,它与引用的变量共用同一块内存空间)
类型 & 引用变量名 = 要引用的那个东西
eg:int & p = a;因此,变量a和他的引用p就是完完全全等价的东西。你对p进行的所有操作都会完全等价地作用于a,对a进行的操作同理也会完全等价地作用于p。他们就是一个东西
2.引用在链表中应用
在链表的学习中,我们会用到许多函数去实现其中的功能,但是我们知道函数的传参是一种值传递,我们在函数中进行的修改出了函数就会消失。
因此我们利用引用就可以在函数中对链表进行操作了。
例子:
int AddNode(List &list, int data)
//由于此函数在list前加了&(引用),所以函数中对list的修改都会作用到传入的listA上
{
List new_node = new Node;
new_node->data = data;
new_node->next = NULL;
List temp = list;
while(temp->next) temp=temp->next;
temp->next = new_node;
return 0;
}
..........
..........
AddNode(listA,v);
e. new和delete
我们知道,在链表的操作中,是要不断开辟新的节点和删除节点中,这个操作可以借用c++中的new和delete
1.new
new操作符在C++中用于动态分配内存,并返回一个指向新分配内存的指针。
List new_node = new Node; 其中:
new后面跟着申请空间的类型,即告诉计算机我需要这么大的一块空间。此时我们是创建一个新的节点,所以new后面跟着的就是节点Node
因为new是返回一个指针,这个指针类型就是我们申请空间的类型。此时即是Node*。所以我们要用一个节点指针List去接收他。
2.delete
int DestroyList(List &list)
{
while(list->next)
{
List sb = list;
delete sb; //delete
list=list->next;
}
return 0;
}delete是用于释放空间的(与new对应)
操作为:delete+指针(指向要释放的那块空间)
f. 指向结构的指针
用->表示指针所指结构变量中的成员(打法是一个减号-加上一个大于号>)
例:
struct Node
{
int data; //数据域
Node* next; //指针域
};
.......
.......
int AddNode(List &list, int data)
{
List new_node = new Node;
new_node->data = data;
new_node->next = NULL;
List temp = list;
while(temp->next) temp=temp->next;
temp->next = new_node;
return 0;
}
形式即为:
new_node->data = data; //即new_node结构体中的数据域
new_node->next = NULL; //即new_node结构体中的指针域其中new_node是一个节点指针(指向struct数据类型)
我们知道new_node其中是包含数据域data和指针域next的;这是一个更方便地取其中数据域和指针域的方法
形式为:
变量名字->data:得到这个变量所包含的data数据域
变量名字->next:得到这个变量所包含的next指针域
补:
我们知道这里面new_node是一个指针,而常规的取指针中的值为: *指针名字
而结构体常规取其中某个数据的方法为: 结构体名字.data / 结构体名字.next
综上:
new_node->data (*new_node).data;
new_node->next (*new_node).next;这每一行的东西表示的是同一个意思
贰.重点
a. 头节点的重要性
要清楚,头节点是这个链表的唯一特征和标志
在定义链表变量时,我们是设出一个链表的头节点,在初始化的过程中,我们也都是对链表头节点进行操作的
无论是一个链表的创立初始化,还是将链表传入函数。 我们都是在对头节点进行操作
而且在链表的插入 查找 删除中,我们也是从头节点入手;抓住头节点,顺着头节点去往下遍历寻找
注意:
头节点是很特殊的一个节点,他是只有指针域而没有数据域的,即头节点并不包含数据,他只有指向下一个节点的指针
b. 链表的遍历
在对链表的各个操作中,对链表进行遍历是较为常见的,形式如下
while(list->next)
{
......... //其中省略号是具体要进行的操作
list=list->next; //往下进行遍历
}解释:
1.利用一个while循环去进行遍历,遍历结束的条件可以视情况而定,示例中就是list->next为NULL时停止循环(即当循环到链表尾端时)
2.list=list->next; 是往下不断地进行遍历(list不断指向下一个节点)
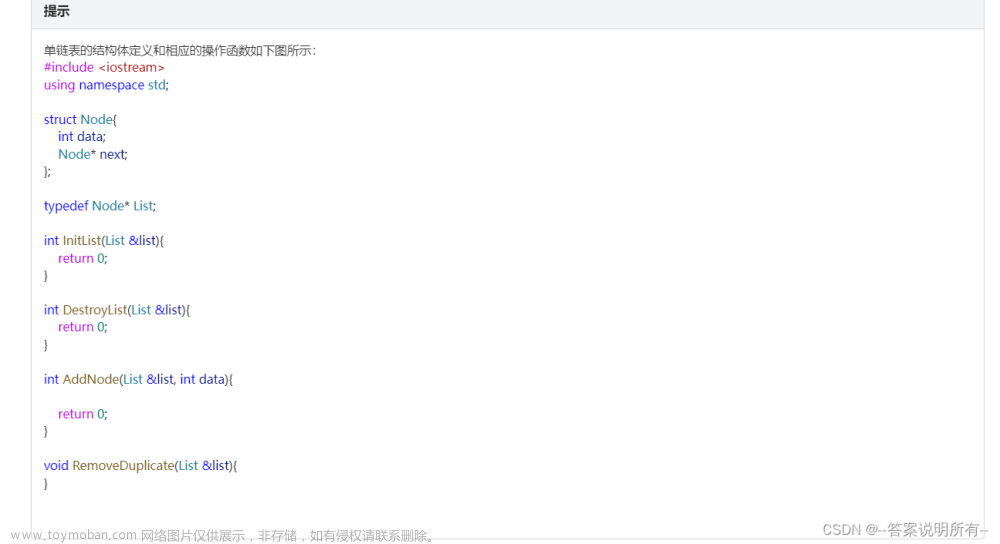
叁.链表的一些基本操作函数:
从上机和作业的题目中,可以看出题目基本上都有着相同的基本操作函数(以下四种)
a. 初始化函数init
void InitList(List &list)
{
list = new Node;
list->next = NULL;
return ;
}
int main()
{
.......
.......
List listA, listB; //设出头节点listA和listB
InitList(listA); // 初始化单链表A(即对A的头
InitList(listB); // 初始化单链表
........
........
}1. 定义变量链表listA和listB:
从对头节点的理解可以知道,头节点就是我们识别链表的唯一特征标识。因此这里面我们定义新变量listA和链表listB;其实就是在设出他们的头节点listA和listB
(按照北化的代码模式,这一步在主函数main中进行)
做完这一步之后,只有两个空的指针变量,随后通过initlist函数对其进行初始化
2. 利用initlist函数进行初始化
2.1函数传参的分析
void InitList(List &list)//通过引用,在initlist函数内去对头节点list初始化2.2分配空间
list = new Node;//利用关键字new,去给头节点指针list分配空间2.3使链表结构完备
此时已经有了一个头节点head,但是还要有尾部指向NULL。由于此时链表相当于是空的,所以直接让头节点list指向NULL即可
list->next=NULL; //让头节点指向空完成了初始化后,此时我们的链表如下图所示

b. 插入函数AddNode(特指从尾部插入)
int AddNode(List &list, int data)
{
List new_node = new Node;
new_node->data = data;
new_node->next = NULL;
List temp = list;
while(temp->next) temp=temp->next;
temp->next = new_node;
return 0;
}1.函数传参的分析
int AddNode(List &list, int data) //参量1:通过引用传入链表的头节点list,对其操作
//参量2:要在尾部插入的数据data 2.创建一个新的节点,分配空间并赋值
List new_node = new Node; //通过new去创建一个新的节点,分配空间
new_node->data = data; //给这个新的节点赋值数据域和指针域
new_node->next = NULL;赋值的分析:此时这个新节点应该是接在最后面的,因此他的指针域next就应该是指向NULL;而数据域显然就是我们传入的参数data
3.找到新节点插入的位置
由于是尾部插入,因此问题转化成了找到链表的最后一个位置。可以利用遍历进行
List temp = list;
while(temp->next) temp=temp->next;
temp->next = new_node;利用一个临时指针temp去指向链表的头指针,随后用while进行遍历知道temp此时即为链表的最后一个元素;再让temp的下一个next指向我们新创的节点即可
c. 打印链表函数PrintList
void PrintList(const List &list) //加了个const的作用是保证了在函数内部不改变传入的这个链表
//不过其实加不加都无所谓的
{
list temp = list;
while(temp->next)
{
temp = temp->next;
cout<<temp->data<<" ";
}
return 0;
}用一个临时指针temp去指向头节点,然后利用while在遍历的同时输出每个节点的值
注意 一开始的头节点是没有数据域的,所以不用输出头节点的数值
d. 删除链表并释放空间DestroyList
int DestroyList(List &list)
{
while(list->next)
{
List sb = list;
delete sb;
list=list->next;
}
return 0;
}从头节点开始,每经过一个节点就去用delete删除并释放它的内存;同时不断循环直到到达了尾部
肆.具体题目的介绍
a. 题目一 :两个有序链表序列的合并(附加代码模式)
链接:两个有序链表序列的合并(附加代码模式)
题目:

代码实现:
#include <iostream>
#include <cstdio>
using namespace std;
struct Node
{
int data;
Node* next;
};
typedef Node* List;
void InitList(List &list)
{
list = new Node;
list->next = NULL;
return ;
}
void DestroyList(List &list)
{
List temp = list ;
while(temp->next)
{
List sb = temp;
delete sb;
temp = temp->next;
}
return ;
}
void AddNode(List &list,int data)
{
List temp = list ;
List add_node = new Node;
add_node->data = data ;
add_node->next = NULL ;
while(temp->next)
{
temp=temp->next;
}
temp->next = add_node;
return ;
}
List MergeList(List &listA,List &listB) //因为此时要返回一个头节点指针(代表答案链表),所以返回类型是List
{
//首先去创建一个新的答案链表(头节点),并将其初始化
List listC;
InitList(listC);
//用两个链表指针分别指向两个链表的头部和尾部
List i = listA;
List j = listB;
while( i->next && j->next ) //跳出循环的前提是两个链表中有一个已经循环完了
{
//去比较大小
if(i->next->data<=j->next->data)
{
AddNode(listC,i->next->data); //要注意头节点只是一个有地址和next的东西 是没有数据的 所以这里读入数据的时候 应该是i->next->data(要有一个next)
i=i->next;
}
else
{
AddNode(listC,j->next->data);
j=j->next;
}
}
//此时跳出了循环,说明A和B链表中有一个已经循环完了。所以此时如果另外一个链表还有东西的话,直接全部加到答案链表C的后面即可
while(i->next)
{
AddNode(listC,i->next->data);
i=i->next;
}
while(j->next){
AddNode(listC,j->next->data);
j=j->next;
}
return listC;
}
void PrintList(const List &list)
{
List temp=list;
while(temp->next)
{
temp=temp->next;
cout << temp->data << " ";
}
cout << endl;
}
int main(){
int m,n;
cin >> m >> n;
List listA, listB;
InitList(listA); // 初始化单链表
InitList(listB); // 初始化单链表
for(int i=0;i<m;i++){
int v;cin >> v;
AddNode(listA,v); // 在单链表的末尾增加节点
}
for(int i=0;i<n;i++){
int v; cin >> v;
AddNode(listB, v);
}
List listC = MergeList(listA,listB); //合并两个单链表
PrintList(listC); // 输出单链表
DestroyList(listA); // 销毁单链表
DestroyList(listB); // 销毁单链表
DestroyList(listC); // 销毁单链表
return 0;
} 只需要将叁中学习到的基本操作函数补充完整,同时书写一个函数对链表A,B进行比较后将其插入到链表C即可
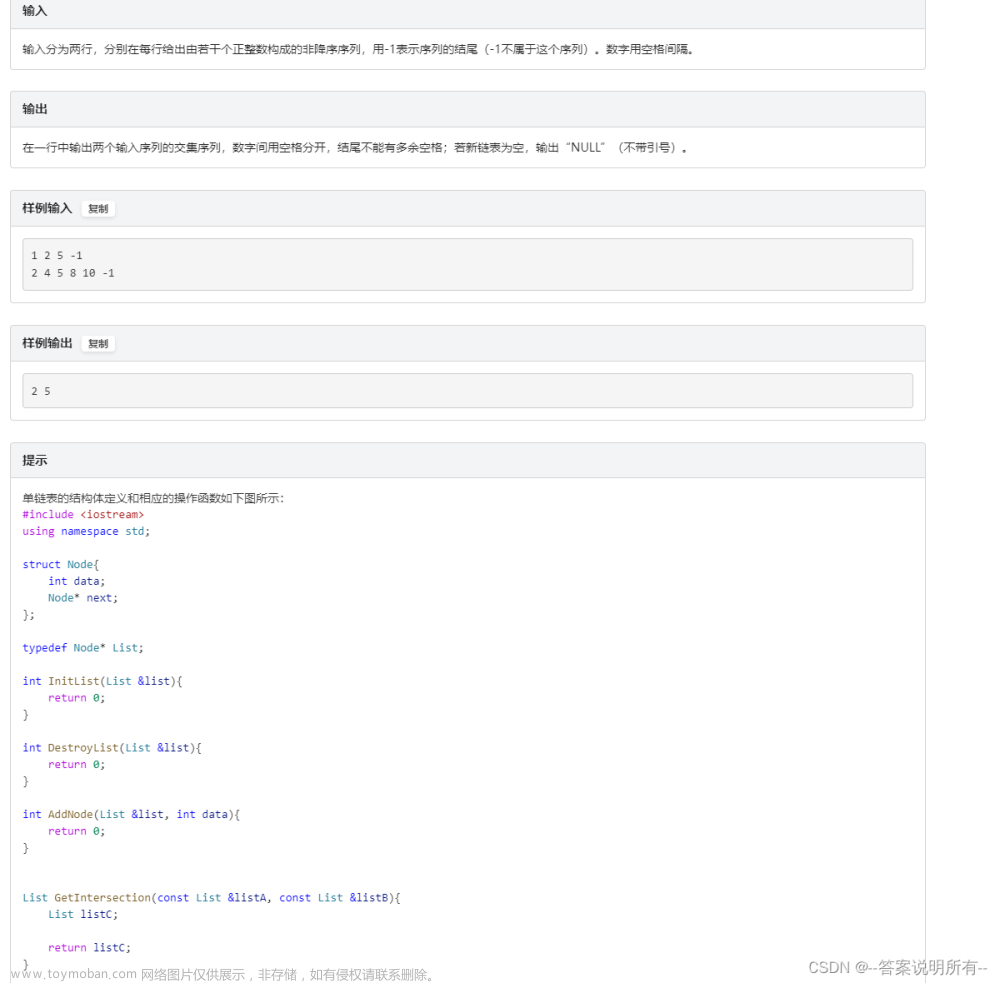
b. 题目二:两个有序链表序列的交集(附加代码模式)
链接:
题目:

代码与思路:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e5+10;
int a[N];
struct Node
{
int data; //数据域
Node* next; //指针域
};
typedef Node* List;
int InitList(List &list)
{
list = new Node; //利用new给头节点分配空间
list->next=NULL; //让头节点指向空
return 0;
}
int DestroyList(List &list)
{
while(list->next)
{
List sb = list;
delete sb;
list=list->next;
}
return 0;
}
void AddNode(List &list,int data)
{
List temp = list ;
List add_node = new Node;
add_node->data = data ;
add_node->next = NULL ;
if(data==-1) return ; //这就是这道题的特殊之处 当输入为-1时要return停止输入
while(temp->next)
{
temp=temp->next;
}
temp->next = add_node;
return ;
}
List GetIntersection(const List &listA, const List &listB) //因为此时要返回一个头节点指针(代表答案链表),所以返回类型是List
{
//先将数组a初始化
memset(a,0,sizeof(a));
//去创建一个新的答案链表(头节点),并将其初始化
List listC;
InitList(listC);
//去对链表A进行一遍遍历,同时把其中每一个值都标记到数组a中
List i = listA;
int t;
while(i->next)
{
t=i->next->data;
a[t]=1;
}
//去对链表B进行一遍遍历,把其中每个值去看看在数组a中是否标记为存在,若存在则存入链表C中
List j = listB;
while(j->next)
{
t=j->next->data;
if(a[t]==1)
{
AddNode(listC,t);
}
}
return listC;
}
void PrintList(const List &list)
{
list temp = list;
while(temp->next)
{
temp = temp->next;
cout<<temp->data<<" ";
}
return 0;
}
int main(){
List listA, listB;
InitList(listA); // 初始化单链表
InitList(listB); // 初始化单链表
int v;
while(cin >> v && v != -1){
AddNode(listA,v); // 在单链表的末尾增加节点
}
while(cin >> v && v != -1){
AddNode(listB,v); // 在单链表的末尾增加节点
}
List listC = GetIntersection(listA,listB); //合并两个单链表
PrintList(listC); // 输出单链表
DestroyList(listA); // 销毁单链表
DestroyList(listB); // 销毁单链表
DestroyList(listC); // 销毁单链表
return 0;
}
解释:
本题有两个特殊之处:
1.本题的输入有告知是在输入为-1的时候停止输入了,所以在AddNode函数中要加入一个if判断去判断是否有-1的输入
2.求交集的函数中:
运用了一个数组a去标记元素是否有出现过,如果元素x出现过,那么a【x】就会被标记为1。而若x未出现过,则a【x】标记为0
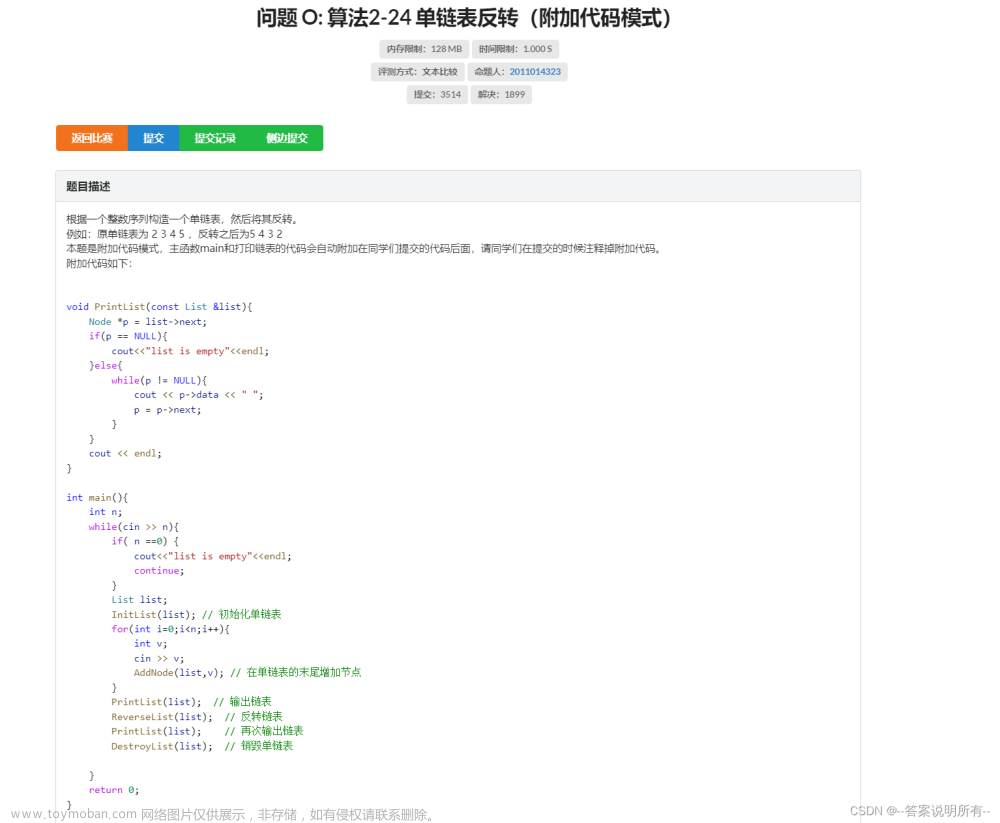
c. 题目三:单链表反转(附加代码模式)
链接:
题目:
代码实现:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
struct Node
{
int data; //数据域
Node* next; //指针域
};
typedef Node* List;
int InitList(List &list)
{
list = new Node; //利用new给头节点分配空间
list->next=NULL; //让头节点指向空
return 0;
}
int DestroyList(List &list)
{
while(list->next)
{
List sb = list;
delete sb;
list=list->next;
}
return 0;
}
void AddNode(List &list,int data)
{
List temp = list ;
List add_node = new Node;
add_node->data = data ;
add_node->next = NULL ;
while(temp->next)
{
temp=temp->next;
}
temp->next = add_node;
return ;
}
void ReverseList(List &list)
{
List p, q;
p = list->next;
list->next = NULL;
while (p)
{
q = p;
p = p->next;
q->next = list->next;
list->next = q;
}
return ;
}
void PrintList(const List &list){
Node *p = list->next;
if(p == NULL){
cout<<"list is empty"<<endl;
}else{
while(p != NULL){
cout << p->data << " ";
p = p->next;
}
}
cout << endl;
}
int main(){
int n;
while(cin >> n)
{
if( n ==0)
{
cout<<"list is empty"<<endl;
continue;
}
List list;
InitList(list); // 初始化单链表
for(int i=0;i<n;i++){
int v;
cin >> v;
AddNode(list,v); // 在单链表的末尾增加节点
}
PrintList(list); // 输出链表
ReverseList(list); // 反转链表
PrintList(list); // 再次输出链表
DestroyList(list); // 销毁单链表
}
return 0;
}
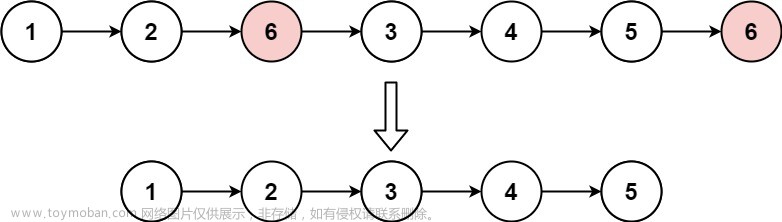
这里面唯一的不同就是反转链表的函数。
此中借助了两个辅助指针,以原链表中有三个数据节点为例子作图:



本质是有利用两个辅助指针p和q去分别表示两个节点:
进行while循环后,每次改变两个节点间的方向,让原先绿色的向右箭头去变成红色向左箭头方向;
同时在这个过程中,不断更新list指针,让它始终指向新链表的首元素。然后通过迭代让q变成p,p=p->next变成新的p,从而把这节点一直不断地往后循环直至p为0。
d. 题目四: 有序单链表删除重复元素
链接:有序单链表删除重复元素
题目:

代码实现:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 1e5+10;
int a[N];
struct Node
{
int data; //数据域
Node* next; //指针域
};
typedef Node* List;
int InitList(List &list)
{
list = new Node; //利用new给头节点分配空间
list->next=NULL; //让头节点指向空
return 0;
}
int DestroyList(List &list)
{
while(list->next)
{
List sb = list;
delete sb;
list=list->next;
}
return 0;
}
void AddNode(List &list,int data)
{
List temp = list ;
List add_node = new Node;
add_node->data = data ;
add_node->next = NULL ;
while(temp->next)
{
temp=temp->next;
}
temp->next = add_node;
return ;
}
void RemoveDuplicate(List &list)
{
//由于有多次操作,所以先去把数组a初始化以下(即全部为0)
memset(a,0,sizeof(a));
List t = list;
while(t->next)
{
int x = t->next->data;
if(a[x]==1) //此时说明这个元素重复了,那么就要进行删除操作
{
t->next = t->next->next; //删除操作
}
else a[x]=1; //元素未出现则标记一下他出现过
t = t->next; //把指针往后移动一位
}
return ;
}
void PrintList(const List &list){
Node *p = list->next;
if(p == NULL){
cout<<"list is empty"<<endl;
}else{
while(p != NULL){
cout << p->data << " ";
p = p->next;
}
}
cout << endl;
}
int main(){
int n;
while(cin >> n)
{
if( n ==0) {
cout<<"list is empty"<<endl;
continue;
}
List list;
InitList(list); // 初始化单链表
for(int i=0;i<n;i++){
int v;
cin >> v;
AddNode(list,v); // 在单链表的末尾增加节点
}
PrintList(list); // 输出链表
RemoveDuplicate(list); // 删除重复元素
PrintList(list); // 再次输出链表
DestroyList(list); // 销毁单链表
}
return 0;
}
1. 用数组去进行标记:
类比题目2,此时也是要判断数是否有出现在链表里过,所以我们也可以开一个数组(用memset初始化全为0)去标记。
如果a【x】为0,说明没有出现过,则标记a【x】为1,表示已经出现过x这个数了
如果a【x】为1,说明已经出现过,则进行删除操作
2.链表的删除操作:
t->next = t->next->next; //删除操作 不考虑释放内存的问题,则直接让next指针从指向下一个变成指向下下个即可

图例删除掉了节点3
f. 题目五:求链表的倒数第m个元素(附加代码模式)
链接:求链表的倒数第m个元素(附加代码模式)
题目:

代码实现:文章来源:https://www.toymoban.com/news/detail-780572.html
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
struct Node
{
int data; //数据域
Node* next; //指针域
};
typedef Node* List;
int InitList(List &list)
{
list = new Node; //利用new给头节点分配空间
list->next=NULL; //让头节点指向空
return 0;
}
int DestroyList(List &list)
{
while(list->next)
{
List sb = list;
delete sb;
list=list->next;
}
return 0;
}
int AddNode(List &list,int data)
{
List temp = list ;
List add_node = new Node;
add_node->data = data ;
add_node->next = NULL ;
while(temp->next)
{
temp=temp->next;
}
temp->next = add_node;
return 0;
}
// 查找倒数第m个节点
Node* FindMthNode(const List& list, int m)
{
// 去求整个链表的长度
List t = list;
int l = 0;
while(t->next)
{
t = t->next;
l++;
}
// 转为正数第几个
int x = l-m+1;
//去遍历找到那个指针
t = list;
while(x--)
{
t = t->next;
}
return t;
}
int main()
{
// freopen("/config/workspace/answer/in.txt","r",stdin);
int n;
cin >> n;
List list;
InitList(list);
for(int i=0;i<n;i++){
int v;
cin >> v;
int r = AddNode(list,v);
if(r != 0) cout<<"add node failed"<<endl;
}
// PrintList(list);
int m;
cin >> m;
Node* result = FindMthNode(list,m);
if(result == NULL){
cout << "failed to find the node" <<endl;
}else{
cout << result->data << endl;
}
DestroyList(list);
return 0;
}
比较直接的方法,求长度后再转为正数第几个。文章来源地址https://www.toymoban.com/news/detail-780572.html
到了这里,关于链表知识与部分题目的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!