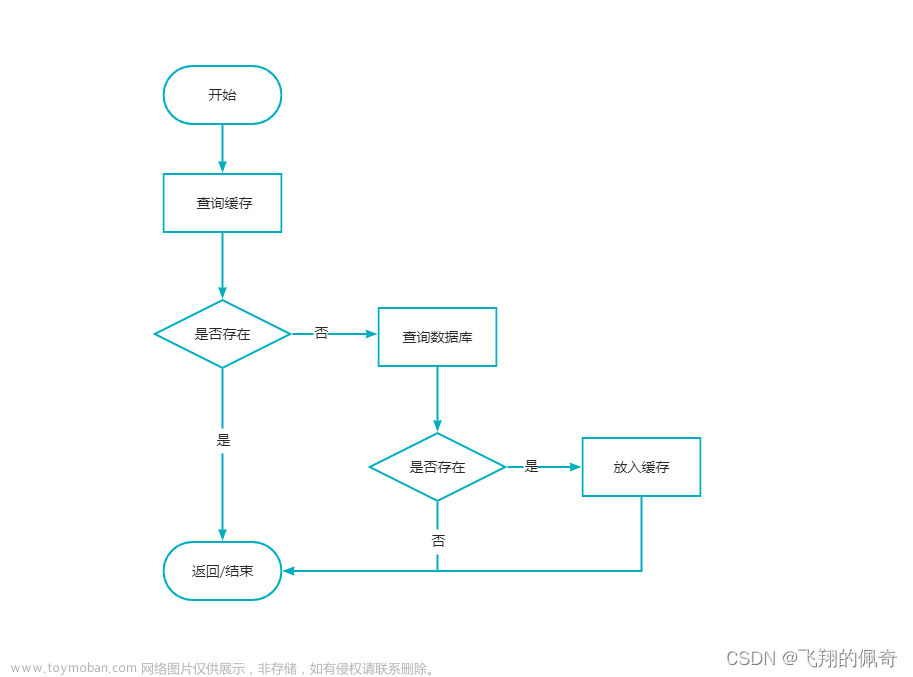
1、简介
MySQL 和 Redis 如何保证数据一致性,目前大多讨论的是先更新Redis后更新MySQL,还是先更新MySQL 后更新Redis,这两种方式在实际的应用场景中都不能确保数据的完全一致性,在某些情况下会出现问题,本文介绍使用 Canal 工具,通过将自己伪装成MySQL的从节点,读取binlog 日志实现。
Canal是用 Java开发的基于数据库增量日志解析,提供增量数据订阅 &消费的中间件。
目前 。 Canal主要支持了 MySQL的 Binlog解析,解析完成后才利用 Canal Client来处理获得
的相关数据。与此类似的组件还有 flink CDC 等。
2、canal 实现 MySQL 和 Redis 数据一致原理
Canal 通过伪装成MySQL 的从节点,获取binlog 得到MySQL 修改内容,从而更新 Redis 缓存,保证MySQL 和 Redis 数据一致性。
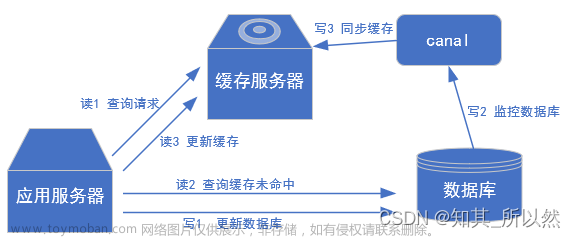
3、canal 下载安装配置
注:实现主从复制,要保证 Master 节点的 binlog 功能要开启。
修改主节点 MySQL 的配置文件(MySQL8.0默认开启,且binlog_format默认为row):
# vim /etc/my.cnf
[mysqld]
server-id=1
log-bin=test # 自定义二进制日志文件名
binlog_format=row
3.1、canal 下载
下载地址:Releases · alibaba/canal · GitHub,本文以 canal.deployer-1.1.7.tar.gz 为例搭建环境。
3.2、安装
Canal 安装很简单,只要解压到指定的文件夹下就行。
# 解压(需要提前创建好canal文件夹)
tar -zxvf canal.deployer-1.1.7.tar.gz -C /opt/canal3.3、配置文件
3.3.1、 Canal 的配置文件
######### common argument #############
# tcp bind ip
canal.ip =
# 默认端口为11111
canal.port = 11111
canal.metrics.pull.port = 11112
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
# 默认为 tcp,支持以上几种mq的数据传输
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
canal.instance.parser.parallelBufferSize = 256
######### destinations(canal 获取数据发送的目标地址) #############
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
######### Kafka #############
kafka.bootstrap.servers = 127.0.0.1:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = ../conf/kerberos/krb5.conf
kafka.kerberos.jaas.file = ../conf/kerberos/jaas.conf
# sasl demo
# kafka.sasl.jaas.config = org.apache.kafka.common.security.scram.ScramLoginModule required \\n username=\"alice\" \\npassword="alice-secret\";
# kafka.sasl.mechanism = SCRAM-SHA-512
# kafka.security.protocol = SASL_PLAINTEXT
######### RocketMQ #############
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
######### RabbitMQ #############
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
说明:这个文件是 canal的基本通用配置, canal端口号默认就是 11111 修改 canal的输出 model,默认 tcp。
3.3.2、实例的配置文件
多实例配置,如果创建多个实例 通过前面 Canal 架构,我们可以知道,一个 Canal 服务中可以有多个 instance conf/下的每一个 example即是一个实例,每个实例下面都有独立的配置文件。默认只有一个实例 example,如果需要多个实例处理不同的 MySQL数据的话,直接拷贝出多个 example ,并对其重新命名,命名和配置文件中指定的名称一致,然后修改canal.properties中的 canal.destinations = 实例 1,实例 2,实例 3。
到每个实例下面修改 instance.properties 文件。
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=12 # 集群中唯一就行
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=127.0.0.1:3306 # 主节点的ip和端口
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=root # Master 数据库用户名
canal.instance.dbPassword=123456 # Master 数据库密码
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.enableDynamicQueuePartition=false
#canal.mq.partitionsNum=3
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#
# multi stream for polardbx
canal.instance.multi.stream.on=false
#################################################
3.4、canal 启动
运行 bin/start.sh
注:如果jdk版本过高,本文用的是 jdk17 版本,canal 目前基于 jdk 11,因此会出现如下错误:

产生原因:
1)、-XX:+AggressiveOpts,这个参数在11的版本已经被废弃了,并在之后的版本会删除;
2)、-XX:+UseBiasedLocking,这个参数在15的版本被废弃了,这个偏向锁已经被废弃了。
解决方法:
修改启动文件(vim bin/start.sh),将下图中标注的两个参数删除,先 bin/stop.sh,然后再 bin/start.sh 即可:

4、canal 在tcp 模式下的测试
4.1、引入依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.6</version>
</dependency>4.2、编写客户端代码
import com.alibaba.fastjson2.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalClient {
public static void main(String[] args) throws InvalidProtocolBufferException {
//1.获取canal 连接对象
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.30.89", 11111), "example", "", "");
while (true) {
//2.获取连接
canalConnector.connect();
// 指定要监控的数据库
canalConnector.subscribe("test.*");
// 获取 Message
Message message = canalConnector.get(100);
List<CanalEntry.Entry> entries = message.getEntries();
if (entries.size() <= 0) {
System.out.println(" 没有数据,休息一会");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
for (CanalEntry.Entry entry : entries) {
// 获取表名
String tableName = entry.getHeader().getTableName();
CanalEntry.EntryType entryType = entry.getEntryType();
// 判断 entryType 是否为 ROWDATA
if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
// 序列化数据
ByteString storeValue = entry.getStoreValue();
//反序列化
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//获取事件类型
CanalEntry.EventType eventType = rowChange.getEventType();
// 获取具体的数据
List<CanalEntry.RowData> rowDatasList =
rowChange.getRowDatasList();
// 遍历并打印数据
for (CanalEntry.RowData rowData : rowDatasList) {
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
JSONObject beforeData = new JSONObject();
for (CanalEntry.Column column : beforeColumnsList) {
beforeData.put(column.getName(), column.getValue());
}
JSONObject afterData = new JSONObject();
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
afterData.put(column.getName(), column.getValue());
}
System.out.println("TableName:" + tableName + ",EventType:" + eventType + ",After:" + beforeData + ",After:" + afterData);
}
}
}
}
}
}
}4.3、测试结果
插入一条数据:
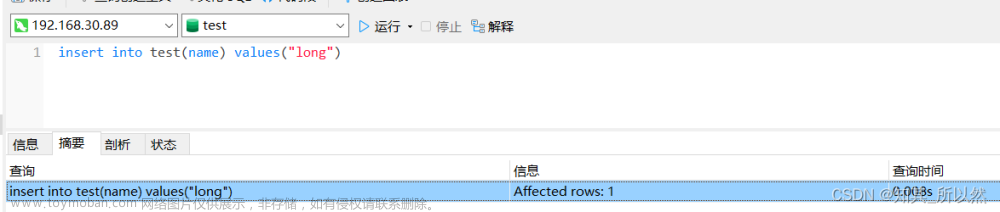
监听结果:
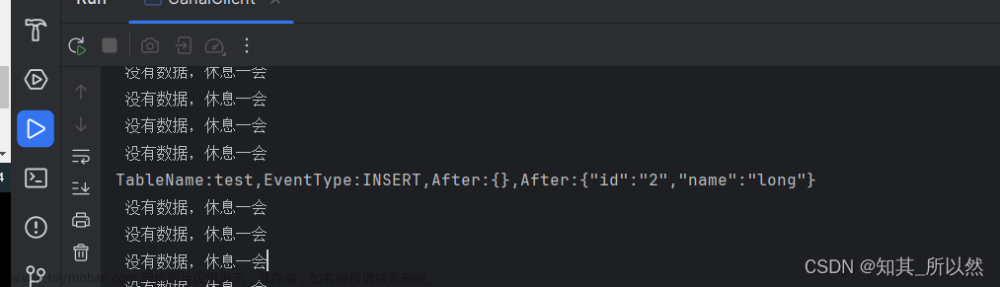
5、总结
本文介绍一种解决数据一致性的方案,通过MySQL 的主从复制实现,数据库和缓存一致性。canal 可以实现将结果发送到 mq操作,还支持高可用集群部署,这部分内容将在公众号中分享,关注下面公众号,学到更多知识。
本人是一个从小白自学计算机技术,对运维、后端、各种中间件技术、大数据等有一定的学习心得,想获取自学总结资料(pdf版本)或者希望共同学习,关注微信公众号:it自学社团。后台回复相应技术名称/技术点即可获得。(本人学习宗旨:学会了就要免费分享)文章来源:https://www.toymoban.com/news/detail-786707.html
 文章来源地址https://www.toymoban.com/news/detail-786707.html
文章来源地址https://www.toymoban.com/news/detail-786707.html
到了这里,关于MySQL 和 Redis 如何保证数据一致性,通过MySQL的binlog实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!