课程:清华大学-数据挖掘:理论与算法(国家级精品课)_哔哩哔哩_bilibili
一、Learning Resources



二、Data
- 数据是最底层的一种表现形式。
- 数据具有连续性。
- 从存储上来讲,数据分为逻辑上的和物理层的。
- 大数据:数据量大、产生速度快、数据种类多、
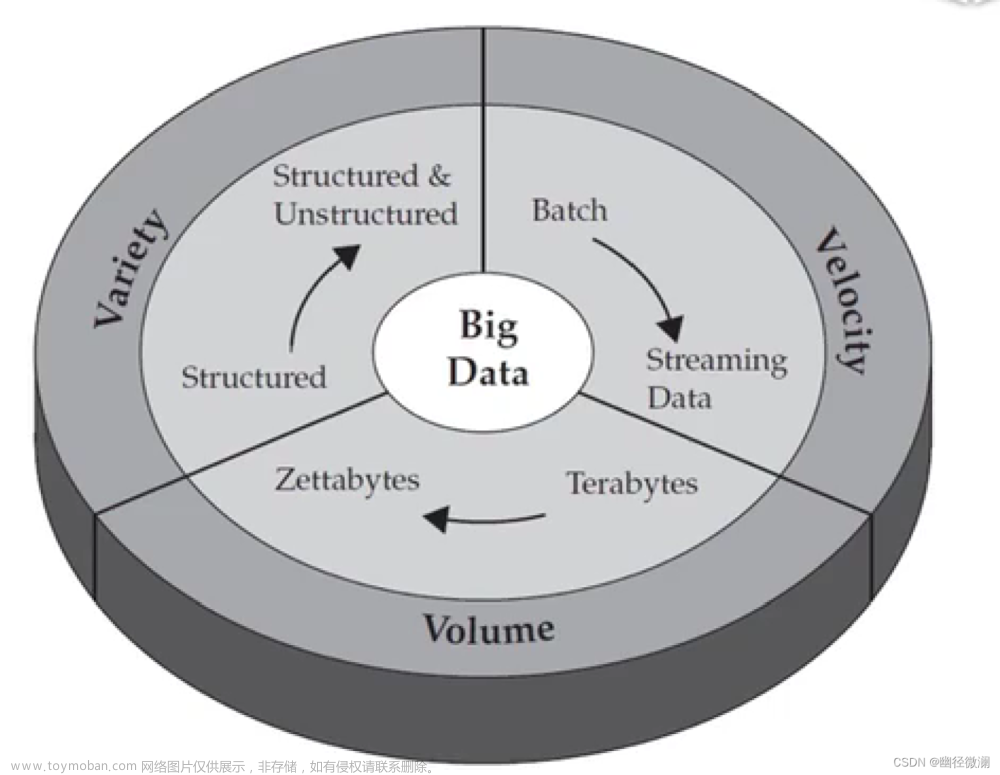

三、The Process of Data Mining

四、clustering聚类
聚类:把一堆数据分为一组一组的(没有标签)
层次性聚类:
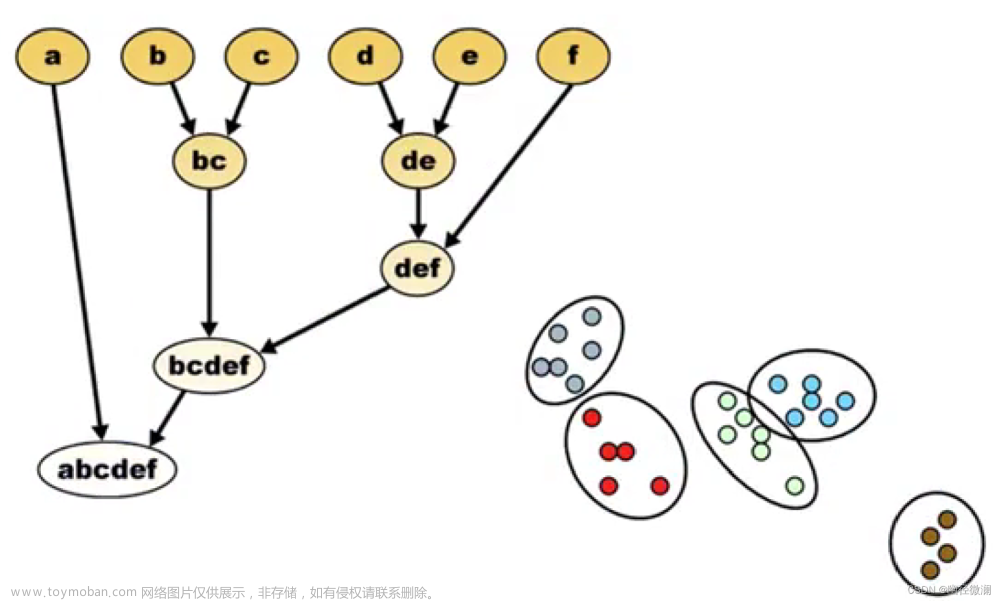
一个一个单独的elements/items,两两去聚。
五、 云计算
把服务器当作一种资源,随着访问需求变化,从云计算的服务商地方租,使利用率变高。

- Pay As You Go
- Software as a Service
- Platform as a Service
- Infrastructure as a Service
六、并行运算
把问题进行切分,分配到不同的处理器上。
七、
- 解决数据挖掘:想清楚数据之间到底有没有规律
- 看问题要全面,要从多个角度、多个维度思考,不能以偏概全。
- 注意:存在内在分组
- 不能忘记时间维度。
- 幸存者偏差问题:
 文章来源:https://www.toymoban.com/news/detail-820056.html
文章来源:https://www.toymoban.com/news/detail-820056.html
样本可能存在偏差。文章来源地址https://www.toymoban.com/news/detail-820056.html
到了这里,关于数据挖掘笔记1的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!











