测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511
本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
CBO优化
优化说明
CBO是指Cost based Optimizer,即基于计算成本的优化。
在Hive中,计算成本模型考虑到了:数据的行数、CPU、本地IO、HDFS IO、网络IO等方面。Hive会计算同一SQL语句的不同执行计划的计算成本,并选出成本最低的执行计划。目前CBO在hive的MR引擎下主要用于join的优化,例如多表join的join顺序。
相关参数为:
–是否启用cbo优化
set hive.cbo.enable=true;
优化案例
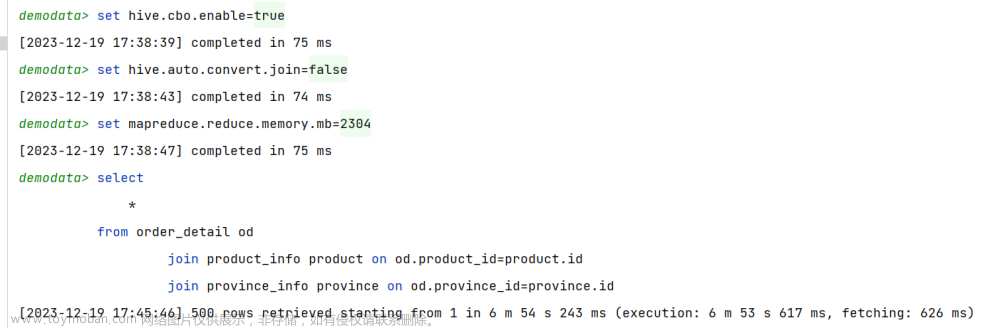
(1)示例SQL语句
select
*
from order_detail od
join product_info product on od.product_id=product.id
join province_info province on od.province_id=province.id;
(2)关闭CBO优化
–关闭cbo优化
set hive.cbo.enable=false;
–为了测试效果更加直观,关闭map join自动转换
set hive.auto.convert.join=false;
–增加reduce端容器内存
set mapreduce.reduce.memory.mb=2304;
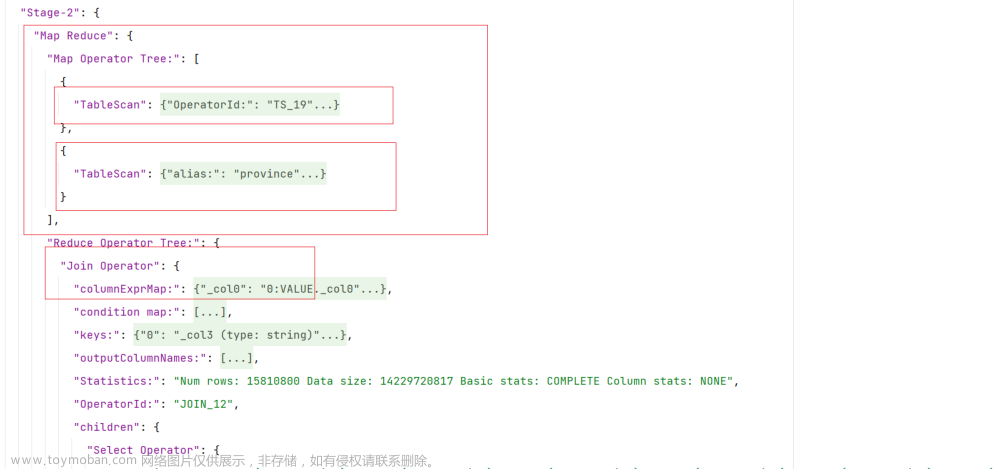
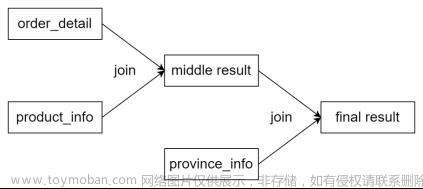
根据执行计划,可以看出,三张表的join顺序如下:
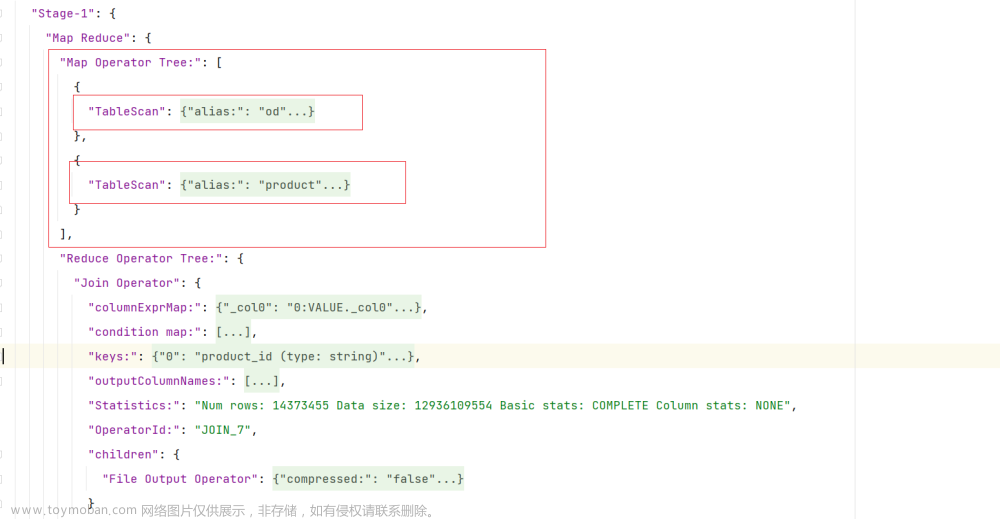

(3)开启CBO优化
–开启cbo优化
set hive.cbo.enable=true;
–为了测试效果更加直观,关闭map join自动转换
set hive.auto.convert.join=false;
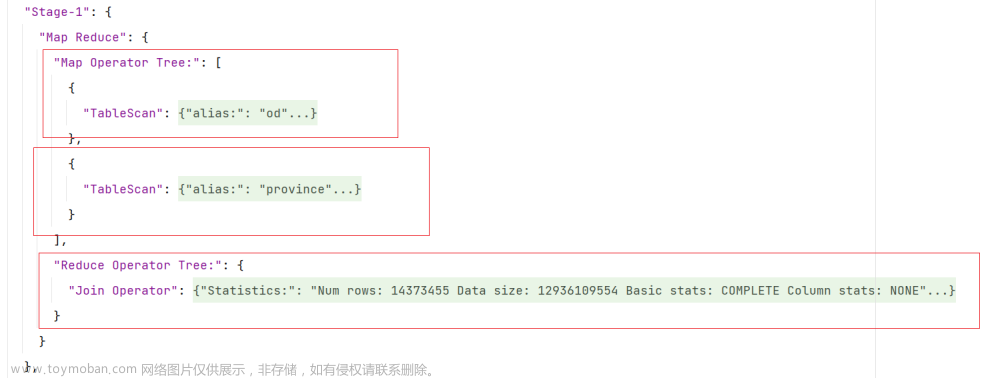
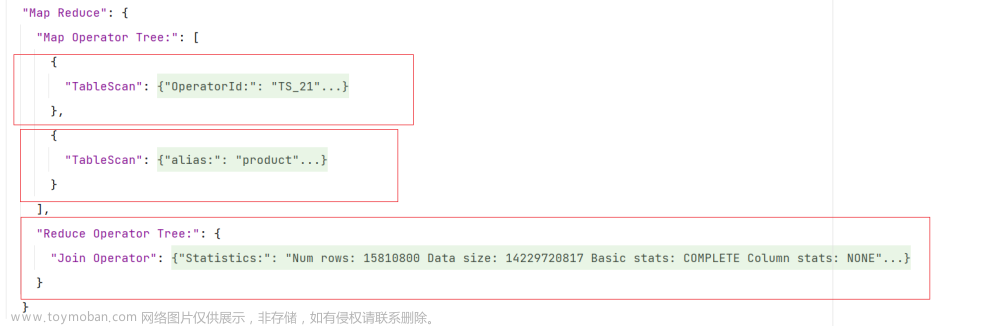
根据执行计划,可以看出,三张表的join顺序如下:
(4)总结
根据上述案例可以看出,CBO优化对于执行计划中join顺序是有影响的,其之所以会将province_info的join顺序提前,是因为province info的数据量较小,将其提前,会有更大的概率使得中间结果的数据量变小,从而使整个计算任务的数据量减小,也就是使计算成本变小。
谓词下推
优化说明
谓词下推(predicate pushdown)是指,尽量将过滤操作前移,以减少后续计算步骤的数据量。
相关参数为:
–是否启动谓词下推(predicate pushdown)优化
set hive.optimize.ppd = true;
需要注意的是:
CBO优化也会完成一部分的谓词下推优化工作,因为在执行计划中,谓词越靠前,整个计划的计算成本就会越低。
优化案例
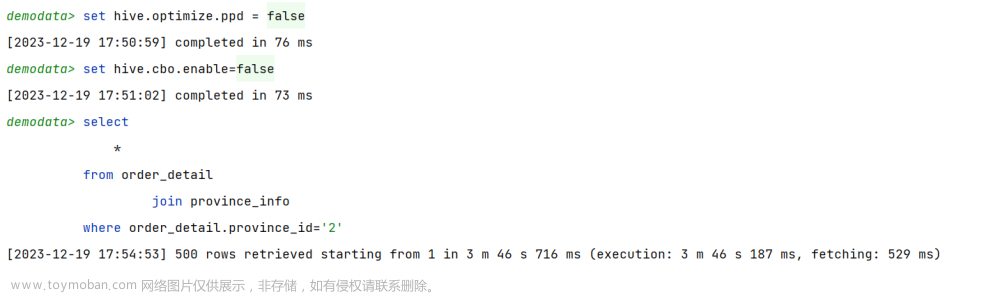
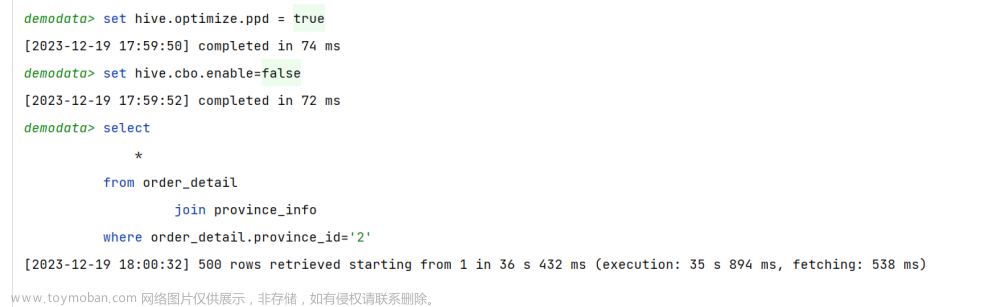
(1)示例SQL语句
select
*
from order_detail
join province_info
where order_detail.province_id='2';
(2)关闭谓词下推优化
–是否启动谓词下推(predicate pushdown)优化
set hive.optimize.ppd = false;
–为了测试效果更加直观,关闭cbo优化
set hive.cbo.enable=false;
通过执行计划可以看到,过滤操作位于执行计划中的join操作之后。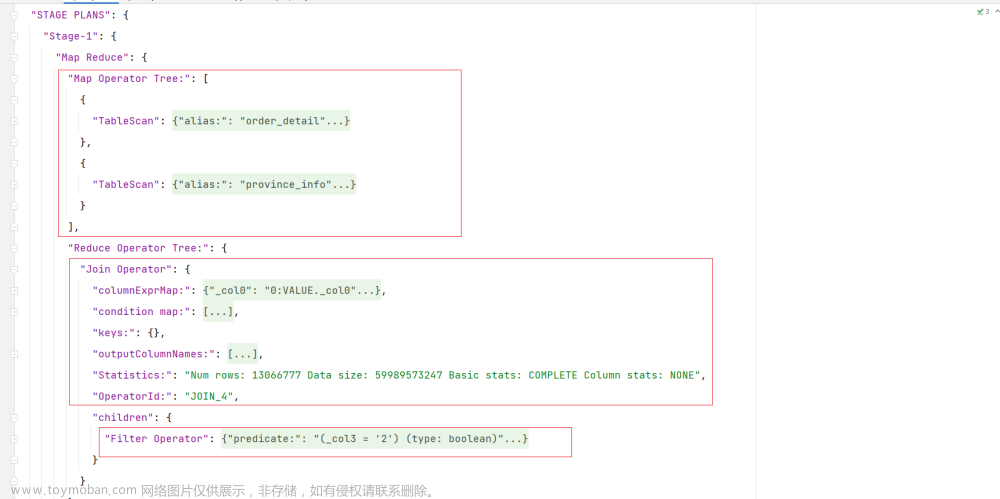
(3)开启谓词下推优化
–是否启动谓词下推(predicate pushdown)优化
set hive.optimize.ppd = true;
–为了测试效果更加直观,关闭cbo优化
set hive.cbo.enable=false;
通过执行计划可以看出,过滤操作位于执行计划中的join操作之前。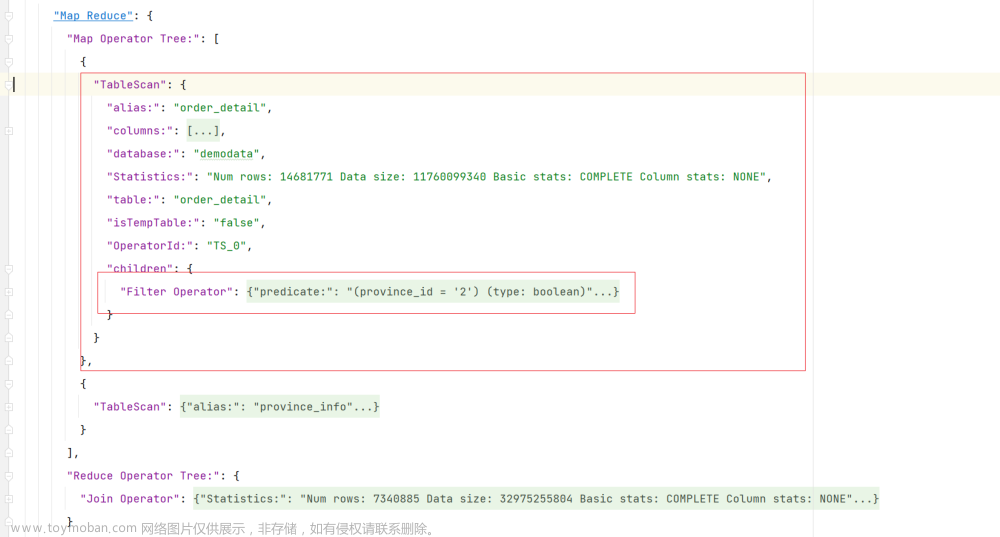
矢量化查询
Hive的矢量化查询优化,依赖于CPU的矢量化计算,CPU的矢量化计算的基本原理如下图: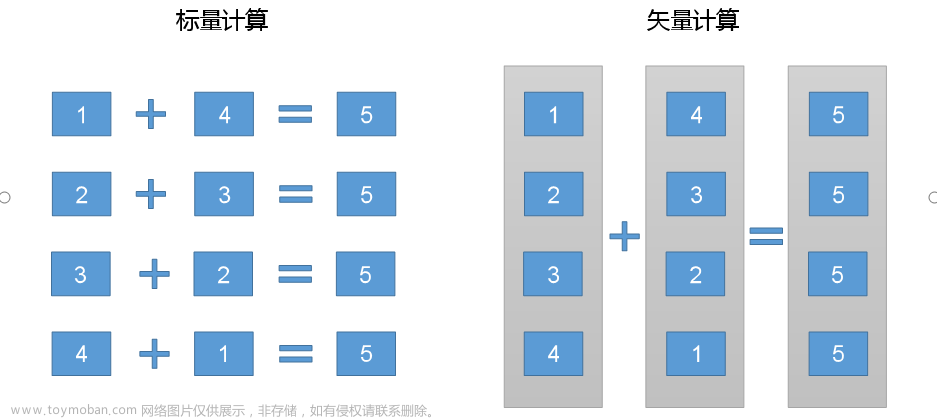
Hive的矢量化查询,可以极大的提高一些典型查询场景(例如scans, filters, aggregates, and joins)下的CPU使用效率。
相关参数如下:
set hive.vectorized.execution.enabled=true;
若执行计划中,出现“Execution mode: vectorized”字样,即表明使用了矢量化计算。
官网参考连接:
https://cwiki.apache.org/confluence/display/Hive/Vectorized+Query+Execution#VectorizedQueryExecution-Limitations
优化案例
(1)示例SQL语句
select province_id,sum(product_num) from order_detail group by province_id;
(2) 关闭矢量化查询
set hive.vectorized.execution.enabled=false;
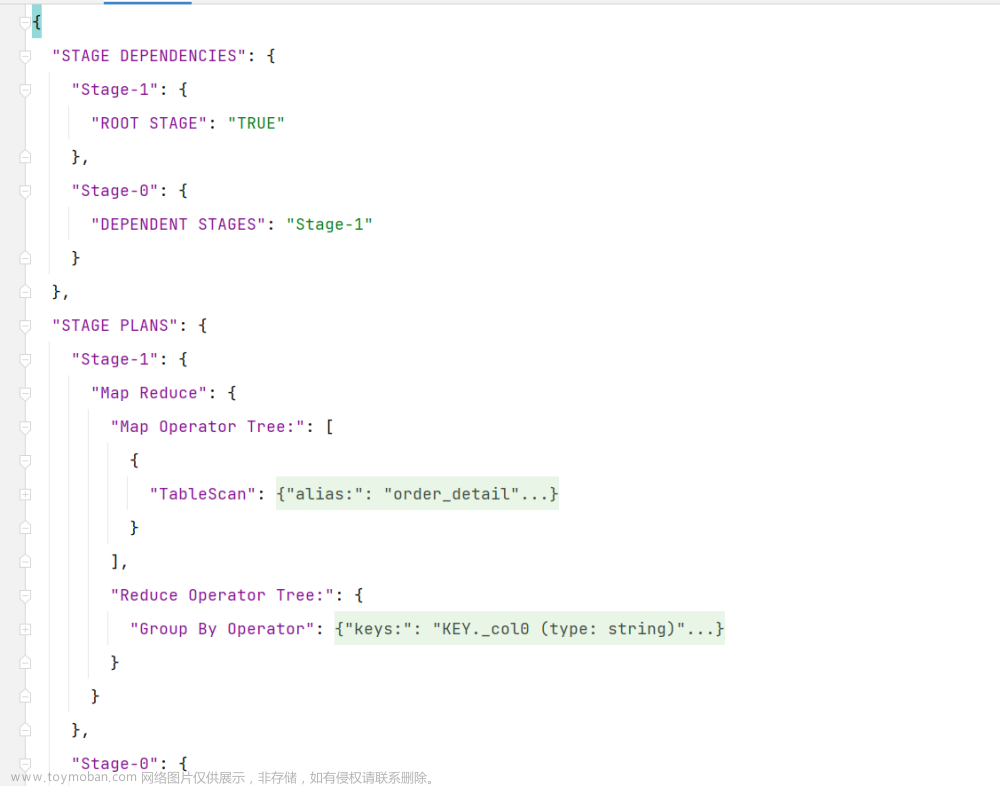

(2) 打开矢量化查询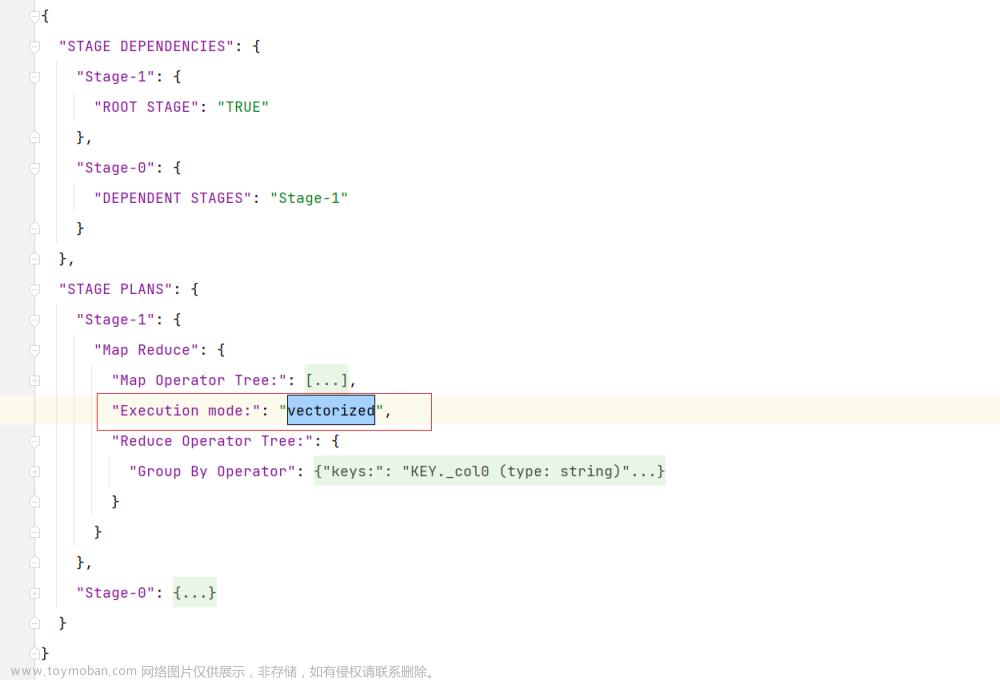

Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:select * from emp;在这种情况下,Hive可以简单地读取emp对应的存储目录下的文件,然后输出查询结果到控制台。
相关参数如下:
–是否在特定场景转换为fetch 任务
–设置为none表示不转换
set hive.fetch.task.conversion=none;
–设置为minimal表示支持select *,分区字段过滤,Limit等
set hive.fetch.task.conversion=minimal;
–设置为more表示支持select 任意字段,过滤,和limit等
set hive.fetch.task.conversion=more;
优化案例
(1)示例SQL语句
select * from order_detail;
(2) --设置为none表示不转换
set hive.fetch.task.conversion=none;


(3)–设置为more表示支持select 任意字段,包括函数,过滤,和limit等
set hive.fetch.task.conversion=more;

本地模式
优化说明
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
相关参数如下:
–开启自动转换为本地模式
set hive.exec.mode.local.auto=true;
–设置local MapReduce的最大输入数据量,当输入数据量小于这个值时采用local MapReduce的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
–设置local MapReduce的最大输入文件个数,当输入文件个数小于这个值时采用local MapReduce的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
优化案例
(1)示例SQL语句
select
count(*)
from product_info
group by category_id;
(2)关闭本地模式
set hive.exec.mode.local.auto=false;


(3)开启本地模式
set hive.exec.mode.local.auto=true;

开启本地模式后如果执行SQL报错,可参考文章:
并行执行
Hive会将一个SQL语句转化成一个或者多个Stage,每个Stage对应一个MR Job。默认情况下,Hive同时只会执行一个Stage。但是某SQL语句可能会包含多个Stage,但这多个Stage可能并非完全互相依赖,也就是说有些Stage是可以并行执行的。此处提到的并行执行就是指这些Stage的并行执行。相关参数如下:
–启用并行执行优化
set hive.exec.parallel=true;
–同一个sql允许最大并行度,默认为8
set hive.exec.parallel.thread.number=8;
优化案例
(1)示例SQL语句
select
count(*)
from product_info
group by category_id;
(2)关闭并行执行优化
set hive.exec.parallel=false;


(3)启用并行执行优化
set hive.exec.parallel=true;


严格模式
Hive可以通过设置某些参数防止危险操作:
(1)分区表不使用分区过滤
将hive.strict.checks.no.partition.filter设置为true时,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
hive.strict.checks.no.partition.filter=true
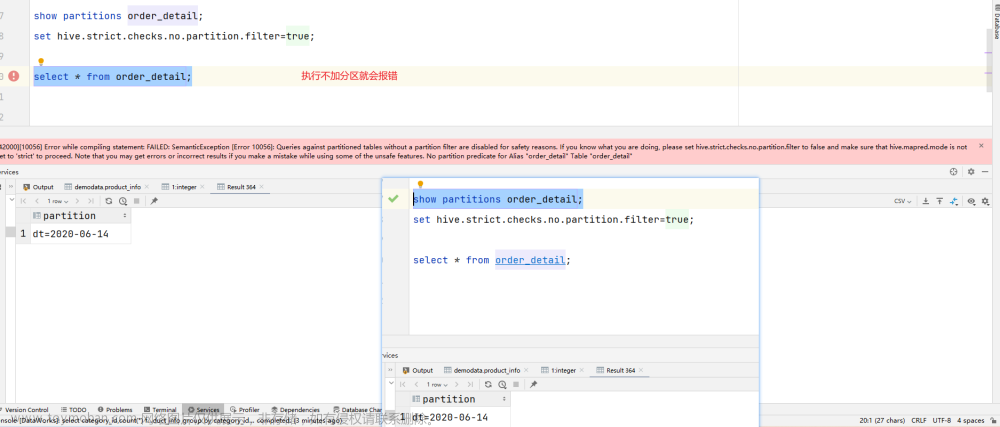
报错翻译:
(2)使用order by没有limit过滤
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reduce中进行处理,强制要求用户增加这个limit语句可以防止Reduce额外执行很长一段时间(开启了limit可以在数据进入到Reduce之前就减少一部分数据)。
hive.strict.checks.orderby.no.limit=true
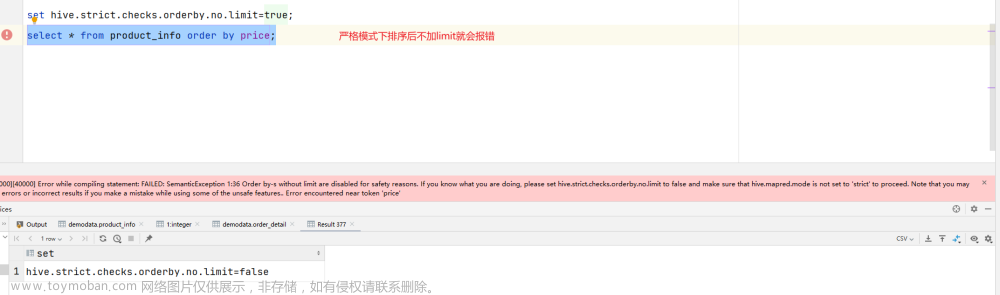
报错翻译:
(3)笛卡尔积
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。文章来源:https://www.toymoban.com/news/detail-830014.html
hive.strict.checks.cartesian.product=true
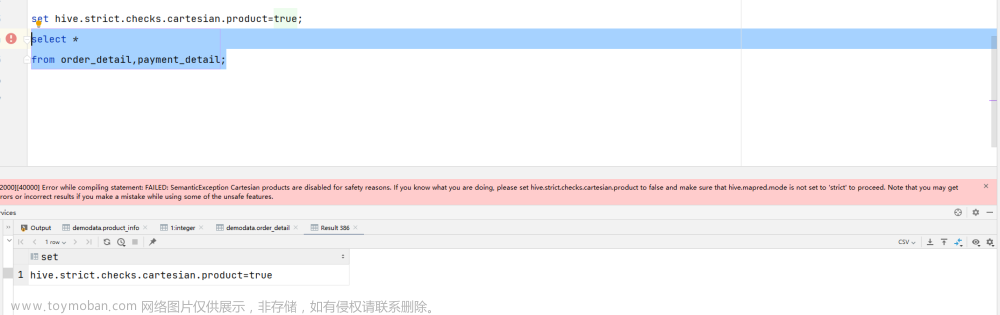
报错翻译: 文章来源地址https://www.toymoban.com/news/detail-830014.html
文章来源地址https://www.toymoban.com/news/detail-830014.html
到了这里,关于hive企业级调优策略之CBO,谓词下推等优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!