1 概述
和近数据计算不同,存内计算直接使用内存单元做计算,主要利用电阻和电流电压的物理关系表达运算过程。存内计算依赖于新型的非易失性存储器,如 ReRAM和 PCM 等。在所有存内计算操作中,最普遍的是利用基尔霍夫定律(Kirchoff’sLaw) 进行向量乘矩阵操作。原因在于:
(1)它能够高效地将计算和存储紧密结合;
(2)它的计算效率高(即,在一个读操作延迟内能完成一次向量乘矩阵);
(3)目前流行的数据密集型应用中,如机器学习应用和图计算应用,向量乘矩阵的计算占了总计算量的90%以上。
除了向量乘矩阵操作,存内计算还能利用电阻、电流及电压的物理关系实现查询,按比特与/或/非等操作。
2 基于向量乘矩阵的存内计算
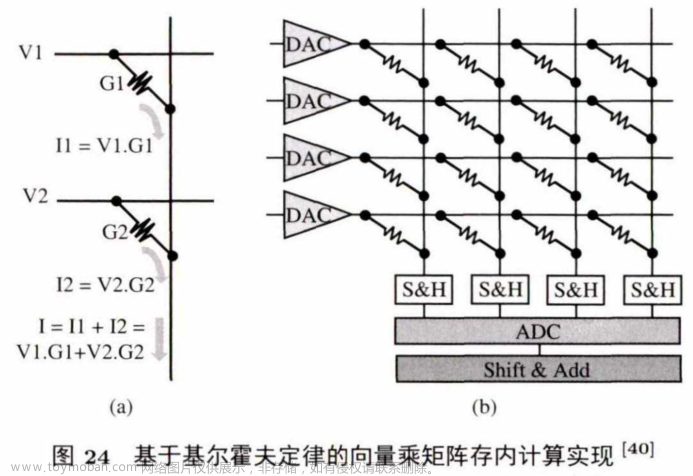
图24是存内计算支持向量乘矩阵的最基本单元,展示了存内计算使用基尔霍夫定律,在将近一个读操作延迟内完成一次向量乘矩阵操作的过程.左图中计算的是一个2x1 的 向 量 (V1,V2)乘以一个1x2的向量(G1,G2) ,其中(G1,G2)用ReRAM阻值表示,事先存在ReRAM中,(V1,V2)用电压表示,加到对应的字节线上.根据基尔霍夫定律,比特线上最后输出的电流值就代表了(V I,V2) x (G1,G2)T 的计算值.同理,扩展到右图的向量乘矩阵操作,ReRAM阵列中存储着要做计算的矩阵,将向量转化成电压加在字节线上,通过比特线得到的输出就是相应的结果向量.由于向量乘矩阵操作是神经网络和图计算中的主要操作,这种内存计算结构得到了高效利用。
基于向量乘矩阵的存内计算代表性工作有: Hewlett Packard Laboratories的DPE, University of Utah的ISAAC,University of Santa Barbara的PRIME,University of Pittsburgh的PipeLayer ,
Tsinghua University的TIME,Tsinghua University的LerGAN, IBM Research的PCM+CMOS存内计算,University of Rochester的SC, Duke University的GraphR。
下文将综述这些工作如何支持神经网络应用或图计算应用,以及其他包含向量乘矩阵的应用。
2.1 Hewlett Packard Laboratories的DPE
DPE是一个专门针对向量乘矩阵操作设计的存内计算加速器.它提供了一个转化算法,可将实际的全精度矩阵存储到精度有限的ReRAM存内计算阵列中,减少器件问题以及外围电路问题对计算结果的影响。图25是DPE的工作流程,分为3个部分:转换、写入、计算。
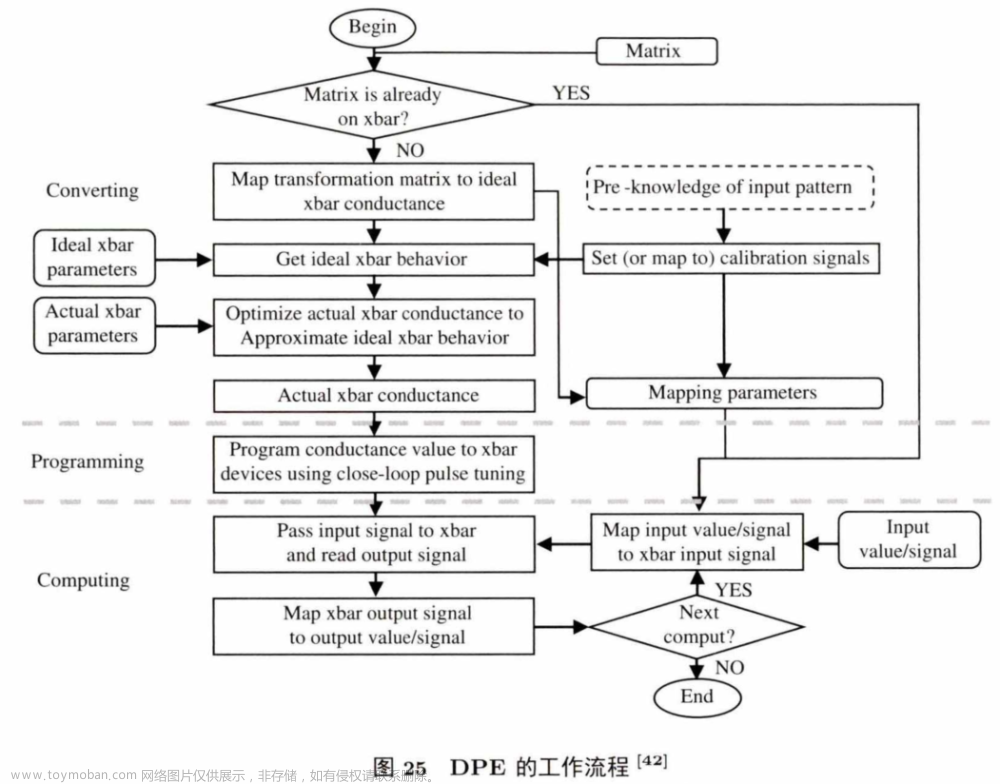
首先将矩阵映射到合适的 ReRAM阵列中.这个过程利用了对输入的预先了解以及ReRAM阵列参数共同优化来决定最后写入ReRAM阵列的数据.而后通过写入阶段,再进入计算阶段.计算阶段将预先准备好的输入数据转成信号,再传入ReRAM阵列中并读取输出数据.如果还有其他计算操作,则将临时输出传送到下一个ReRAM阵列中;如果没有,则结束计算.D P E 测试结果显示,只用4bit 的 DAC/ADC (电信号转模拟信号单元/模拟信号转电信号单元)就能保证计算结果没有精度损失,相比于数字的ASIC向量乘矩阵加速器,能取得 1000到 10000倍的性能提升。
2.2 University of Utah的ISAAC
ISAAC 是一个针对神经网络推理设计的存内计算架构,图26是其整体架构。

一个芯片上包含多个存内计算阵列(tile), 它们通过C-m esh的片上网络连接,可以互相通信.存内计算阵列里有用于池化层计算的最大池化单元(Max Pool, MP), 用于激活层计算的Sigmoid单元,用于数据缓存的eDRAM buffer, 用于中间数据移位加操作的S + A 单元、用于存放临时输出的输出数据寄存器,以及支持原地向量乘矩阵操作的基础单元(in-situmultiply accumulate, IMA)。每个IMA中包含4个基于ReRAM阵列的向量乘矩阵单元、电模互转单元(DAC, ADC) 、 输入寄存器、移位加操作单元,以及输出寄存器. R eR A M 阵列的个数和其他电路单元的设计考虑了向量乘矩阵的计算延迟以及片上网络的带宽,充分利用了片上资源.该结构在做推理时,采用了 pipeline的方式将硬件时分复用,以加快整个推理的过程.然而,推理过程中会有很多由归一化操作产生的气泡,当推理任务松散时,ISAA C的 pipeline效果并不理想.相比于针对神经网络的加速器DaDianNao, ISA A C有 14.8倍的性能提升和5.5 倍的能耗节约。
2.3 University of Santa Barbara的PRIME
PRIME也是一个针对神经网络推理设计的存内计算架构,图27是其系统结构。
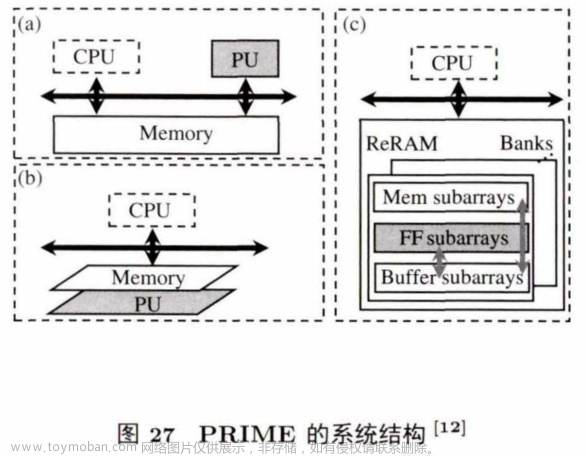
在一般的加速器结构中,计算加速单元作为C P U 的协处理器放在C P U 旁边,通过总线与主存相连(如 图 27(a)所示) . 在基于3D堆叠的近数据计算架构中,加速单元靠近主存堆叠,并通过总线与CPU相连(如图 27(b) 所示)。在 P R IM E 中,直接使用ReRAM 单元做计算。其中,一个ReRAM bank分为3部分:用作存储的Mem subarrays、用作计算的FFsubarrays, 以及用作缓存的Buffer subarray。计算阵列和缓存阵列进行数据交互,缓存阵列和存储阵列进行数据交互.与ISAAC不同的是, PRIME不用片上 eDRAM 作为缓存,也不使用输入输出寄存器,而是直接使用ReRAM 阵列作为缓存和存储。与基于CPU 的神经网络处理器相比,PRIME能够取得2360倍的性能提升和895 倍的能耗节约。
2.4 University of Pittsburgh的PipeLayer
PipeLayer间是一个针对神经网络训练设计的存内计算系统架构,图28展示了其训练一个三层神经网络的数据流情况。
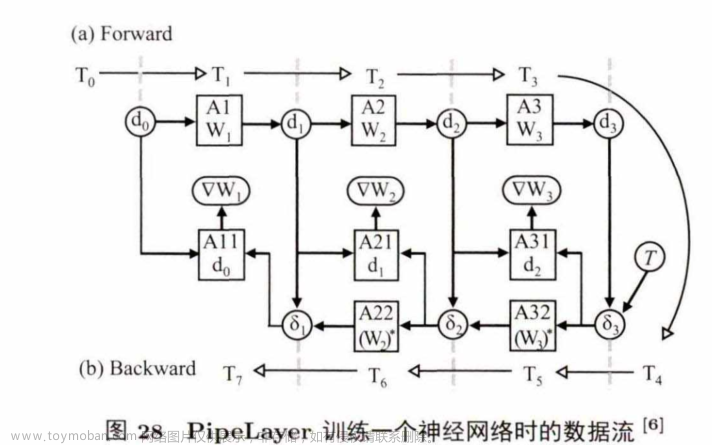
其中,圆形圈出的数据存在普通ReRAM中,方块中的数据存在基于ReRAM的存内计算阵列中. PipeLayer通过合理地复制多份权重数据(图 中 的 A l,A2, A3, A ll,A21,A31, A22, A32)实现少气泡的pipeline结构,同时使得反向传播阶段的误差传递和权值计算并行,从而提高使用存内计算训练神经网络的计算效率。
实验显示,与GPU 系统训练神经网络相比,PipeLayer有 42 倍的性能提升和7 倍的能耗节约。
2.5 Tsinghua University的TIME
TIME也是一个针对神经网络训练的存内计算系统架构,与 PipeLayer不同的是,为了减少训练时权重矩阵更新带来的高延迟和高能耗的问题,它采取权重矩阵复用的方法,而不是将权重矩阵复
制多份来保证训练过程的高度并行。同时,TIME还支持增强学习的训练。图2 9 是增强学习网络的推理和训练过程。
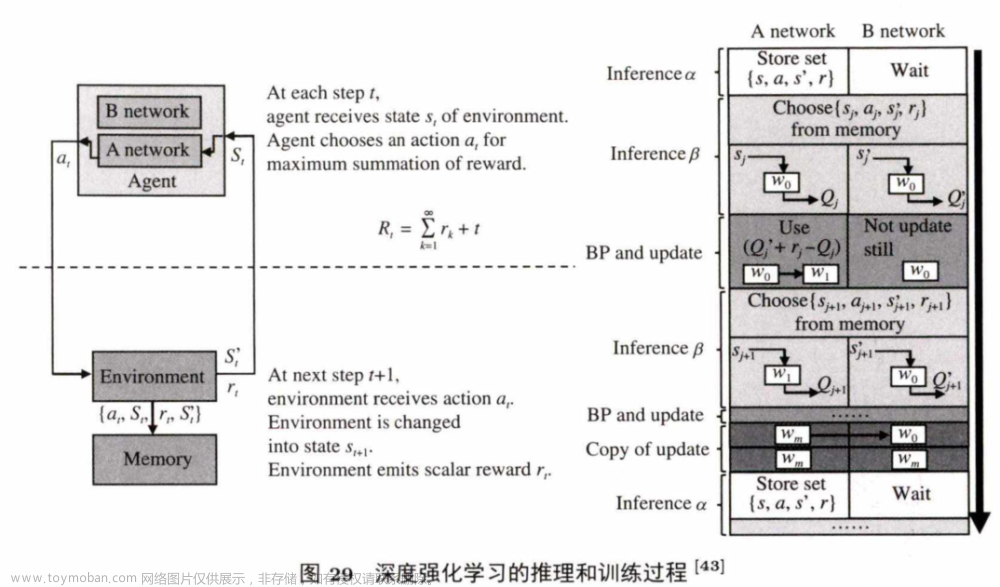
它拥有两个网络,训练过程会产生一个将A网络的权值拷贝到B网络,而后更新B网络的操作(A网络的替换B网络的TIME通过重用ReRAM阵列网络的方式,提出了一个特殊的数据映射操作来消除拷贝操作带来的写操作开销。
实验结果显示,与 ASIC加速器相比,针对有监督的神经网络,TIME能取得 5.3倍的能耗节约;针对强化学习网络,TIME能取得126倍的能耗节约。
2.6 Tsinghua University的LerGAN
LerGAN是一个针对训练对抗生成网络(GAN) 设计的存内计算系统架构。与传统CNN/DNN不同,对抗生成网络有两个网络,并且使用跨步卷积代替原来的池化层.上述存内计算系统架构直接用于对抗生成网络加速难度很大,很多零相关的操作占据了大量的存内计算空间,并且复杂的数据流使得存内计算的片上互联成为瓶颈。基于此,LerGAN首先提出了去除零相关的操作,通过重构卷积核以及相应的数据映射,能够去除因跨步卷积和外圈补零带来的零相关操作。另外,基于GAN训练时的数据流结构, LerGAN还提出了一种三层堆叠的存内计算阵列结构,分别映射前向传播层、误差传播层,以及权值计算层,使 得 G A N 训练的数据传输路径变短,且路由变少。为了融合这两项技术,LerGAN使用内存控制器控制数据的映射以及相应的片上互联重配,以使得数据传输尽可能少且各部分计算速度尽可能一致。
实验显示,和针对CNN的存内计算系统相比,LerGAN能取得7.46倍的性能提升和7.68倍的能耗节约。
2.7 IBM Research的PCM+CMOS存内计算
IBM的研究人员提出了一种用PCM+ CMOS的存储单元来做存内计算的方法,能在同一个阵列中实现全连接神经网络的前向传播、反向传播和权值计算。图30是PCM+ CM OS的存内计算结构。
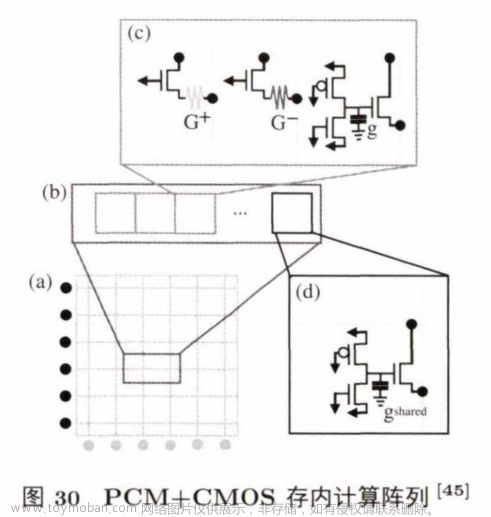
图 30(a) 部分是一个存内计算阵列,包含了多个行。图30(b) 是其中一个行的结构,包含多个存储单元(图 30(c))和一个共享电容单元.该结构的特殊之处在于图30(c) 中的存储单元,该单元由两个 PCM cell (G+ 和 G- ) 和一个电容器(g) 组成.其中,PCM单元用来存储权值的高位,正值存在G+中,负值存绝对值在G- 中;电容器单元用来存储权值的低位.在训练时,权值的高位改变少,所以使用寿命短且非易失的PC M 单元来存;相反,频繁变化的低位就用电容器单元来存。
图31展示了使用该结构训练一个全连接神经网络的过程。
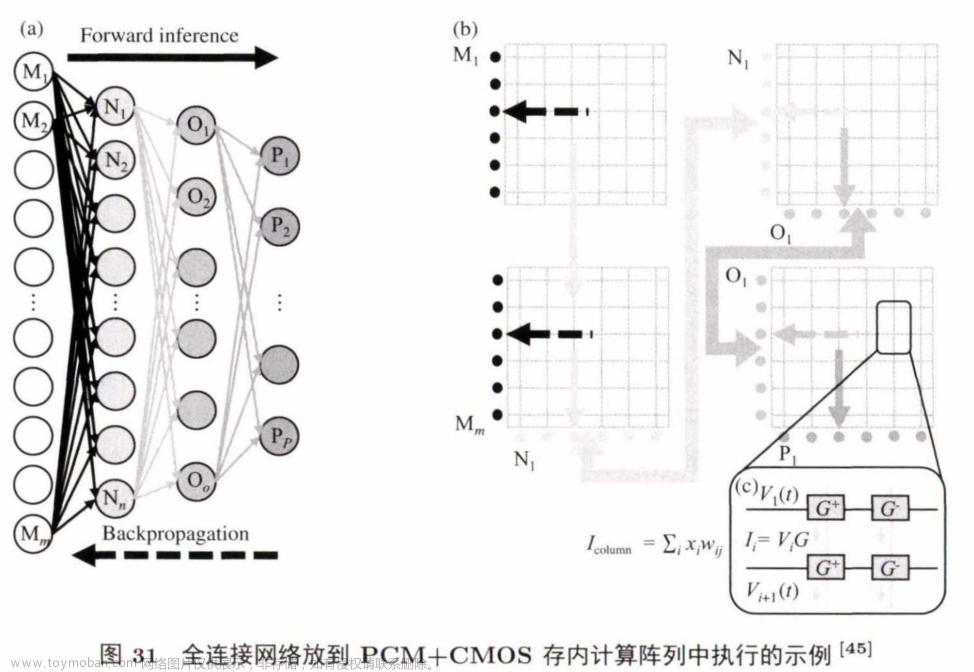
M层作为输入首先进入存内计算的阵列中(图 31(b) 左侧两个阵列),输出进入下一层权值所存放的阵列中,依此类推(所有实线箭头表示前向的数据流)。前向传播完成后,在原地进行反向传播(图中虚线部分标出),不需要转置权值矩阵。该结构能支持原地的前向反向传播,但不适用于卷积神经网络的训练,而现在大多数流行的神经网络都有卷积层的计算,这是此工作的一个局限。实验结果显示,相比较于GPU,该结构对全连接的网络能有两个数量级的性能提升,仅伴随不到1%的精度损失。
2.8 University of Rochester的SC
SC是一个针对科学计算提出的存内计算系统架构.线性代数在科学计算和工程中普遍存在,用专门的硬件加速线性代数计算,有助于提高相关应用的运行速度,减少能耗。向量乘矩阵就是线性代数中的一个重要算子。前述存内计算用于加速向量乘矩阵的系统结构有很大的局限性:只支持定点
的低精度计算,而科学计算需要全精度的浮点运算支持。SC通过探索指数分布的局部性,提供基于定点计算的浮点计算支持,提出了支持快速低功耗的全精度浮点数向量乘矩阵的存内计算硬件架构。
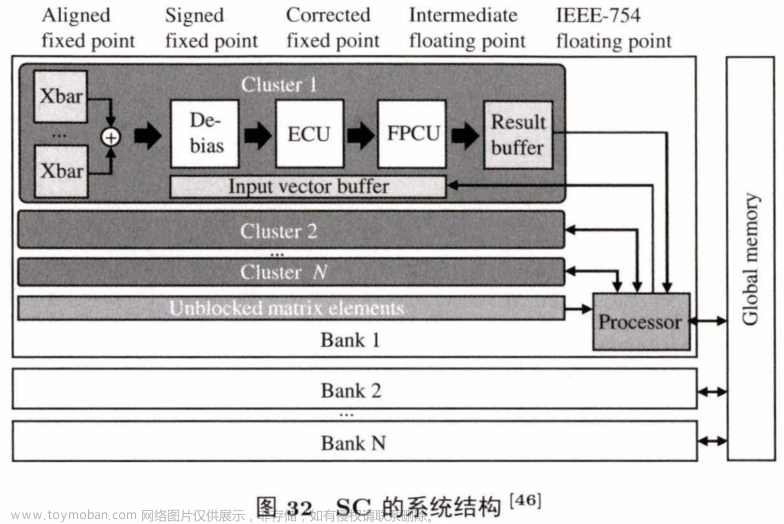
图32是SC的硬件系统结构,由多个ReRAM阵列组成.每个阵列包含多个集群和一个通用处理器,可处理ReRAM阵列不支持的计算.每个集群中有大小不同的计算阵列来支持高效的稀疏矩阵计算。SC结合了现有的G PU 系统来处理数据,可广泛应用,相比于纯GPU,能够取得10.3倍的性能提升和10.9倍的能耗节约。
2.9 Duke University的GraphR
GraphR是一个针对图计算提出的存内计算系统架构. GraphR把一个图分成多个子图,探索子图之间的并行性,以提高性能,并减少因矩阵稀疏性带来的资源浪费。
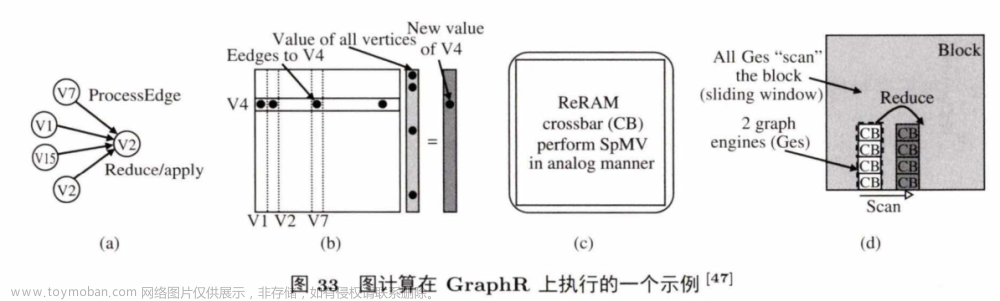
图33 展示了一个子图在eRAM阵列中做计算的实例。该例中,有一个通过4个点和V4 点连接的程序,这4个点的值用于更新V4的 值 (图 33(a)). GraphR 先把这个计算转化成图33(b) 所示的向量乘矩阵操作,其中矩 阵 是V4 的邻接矩阵,向量是其他点的值,最终计算得到V4 的更新值.最简单的方法就是把此图直接转化为矩阵,映 射 到 ReRAM 阵列中做计算,但是会造成很大的资源浪费。因此,GraphR 用小ReRAM 阵列,例如 4x4 或 8x8 (之前的工作中通常用64x 64 或 128x 128),来组成图处理引擎(graph-processing engine,GE),处理和扫描每一个子图。
实验表明,相比于CPU,GraphR能取得16倍的性能提升和34倍的能耗节约;相比于GPU,有1.69到 2.19倍的性能提升和4.11到 8.91倍的能耗节约;相比于近数据计算,有1.16到 .12倍的性能提升和3.67到10.96倍的能耗节约。
3 基于逻辑操作的存内计算
基于逻辑操作的存内计算代表工作有: University of California, Santa Barbara的Pinatubo,Delft University of Technology 的 Scouting Logic和 XOR/XNOR存内计算系统, University of California,San Diego的MPIM和MAPIM,具体如下.
3.1 University of California, Santa Barbara的Pinatubo
Pinatubo是一个针对大量比特位操作的存内计算系统架构。图34 对比了传统冯.诺依曼系统结构 和Pinatubo的系统结构在执行批量比特位操作的过程。
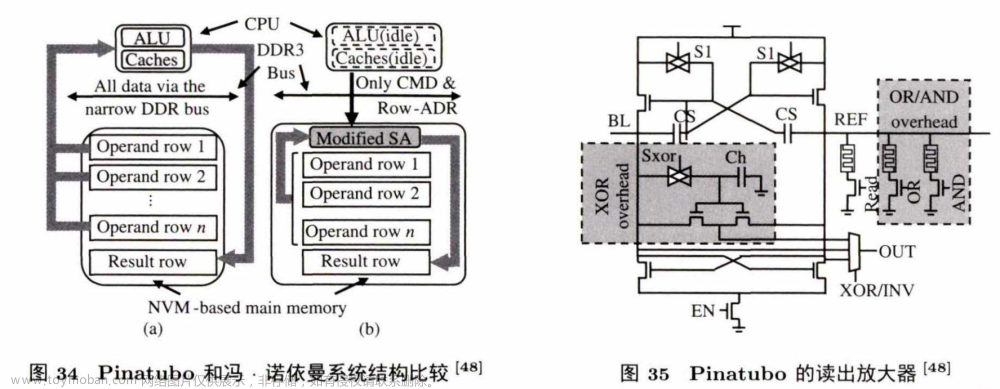
图34(a) 中,CPU 先通过有限的总线资源把内存数据读取到cache中,再 用 C P U 中 的 ALU单元对数据做计算,得到结果后将数据通过总线存入到内存中 .图 34(b) 展示 的 是Pinatubo的存内计算操作,C P U 只发送指令和行地址给内存,内存直接通过读操作将两个参与计算的行读取到修改了的读放大器中,读放大器可以直接计算出两行操作数的与、或,以及异或的值,然后存放到新的行中.在这个计算操作中,只有命令和行地址从总线上传输,避免了传统结构中的大量操作数的传输。
图35展示了修改后的能支持数据读取、与、或,以及异或计算的读放大器。NVM 中数据读取的本质是让给定的电流值经过要读取的电阻后,和读放大器中的己知的阻值作比较来确定是0还是1。基于此原理,Pinatubo同时读取两行或者多行操作数,在读放大器端加上异或、或 、与的参照电路,通过简单的读操作完成比特位逻辑运算.每个参照电路都有一个开关,当指定操作类型后,相应的参照电路将接入放大器中,获得最终的结果。实验结果显示,对于大量的比特位逻辑运算,Pinatubo能取得 500倍的性能提升和28000倍的能耗节约;在普通应用中,能取得1.12倍的性能提升和1.11倍的能耗节约。
2.2 Delft University of Technology 的 Scouting Logic
Scouting Logic 指出存内计算受限于NVM 有限的寿命;所有的计算更新都在N V M 中,缺乏传统计算机中寿命很长的片上缓存来辅助减少对N V M 的写操作.因此, Scouting Logic提出只通过读操作执行这些逻辑单元,而 不 改 动 NVM 存储的数据值.其核心思想与Pinatubo —致,主要是改动了读出放大器的设计,从而占用面积更小,性能更高. M PIM ^ l 为同时支持逻辑运算和搜索操作运算 (在 3.2.3小节中介绍)的存内计算架构,其中的逻辑运算操作原理与Pinatubo相同。实验显示,相比于GPU,MPIM能取得19倍的性能提升和5.5倍的能耗节约。
2.3 Delft University of Technology 的XOR/XNOR存内计算系统
Lebdeh等提出了一个针对XOR和 XNOR操作设计的存内计算系统,该系统基于两个输入的混合ReRAM阵 列 和 XNO R门设计,不需要额 外 的ReRAM 阵列和计算,能够取得54%的时间节约和56%的能耗节约。
2.4 University of California,San Diego的MPIM和MAPIM
MAPIM指出之前针对批量位逻辑运算的存内计算架构没有考虑并行,使得存内计算未取得潜在的高性能.因此,MAHM提出基于阵列并行的高性能存内计算系统架构,能够支持多个比特线的请求,并且共享支持位逻辑运算的读放大器,使得占面积大的读放大器利用率高,从而提升整体系统结构的性能.与之前的存内计算系统相比,MAPIM 能够取得16倍的性能提升和1.8倍的能耗节约。
4 基于搜索操作的存内计算
基于搜索操作的存内计算代表工作有: University of California, San Diego的 NVALT和
NVQuery, University of California, Irvine的MAP, Tsinghua University的SQL-PIM,具
体如下。
4.1 University of California, San Diego的NVALT
NVALT是一个基于存内计算设计的近似查找表,专门用于加速GPU.G P U 的应用展现出了非常高的数据相似性和局部性,如 FFT (fast fourier transform) 和图像处理,由重复的包含很多乘加操作的块构成。NVALT通过探寻这些应用的数据局部性,对这些基础应用建立高效的近似功能单元,来加速GPU的计算。
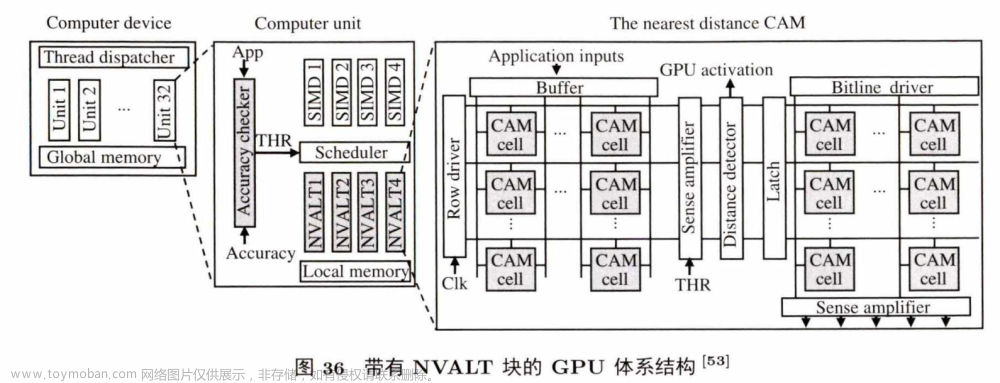
图36是集成有NVALT的 GPU架构。NVALT块放置在每一个单指令多数据流 (single instruction multiple data,SIMD) 处理通道的旁边.当应用在GPU 上执行时,首先经过精度核查,精度允许的条件下,调度器会把指令放到NVALT块上执行. NVALT块使用线下预处理的方式,识别并存储每个程序常用的数据输入模式和对应的数据输出模式.运行时,NVATL搜索存 储 在CAM里的输入数据,然后返回和输入模式最相似的条目所对应的输出结果.系统可根据用户的不同精度需求调度近似的NVALT核和精确的GPU核。
实验显示,在精度损失控制在10% 之内的情况下, NVALT平均能取得4.5倍的能耗节约和5.7倍的性能提升.
4.2 NVQuery,University of California, Irvine的MAP
MAP是一个基于存内计算的近似计算协处理器。
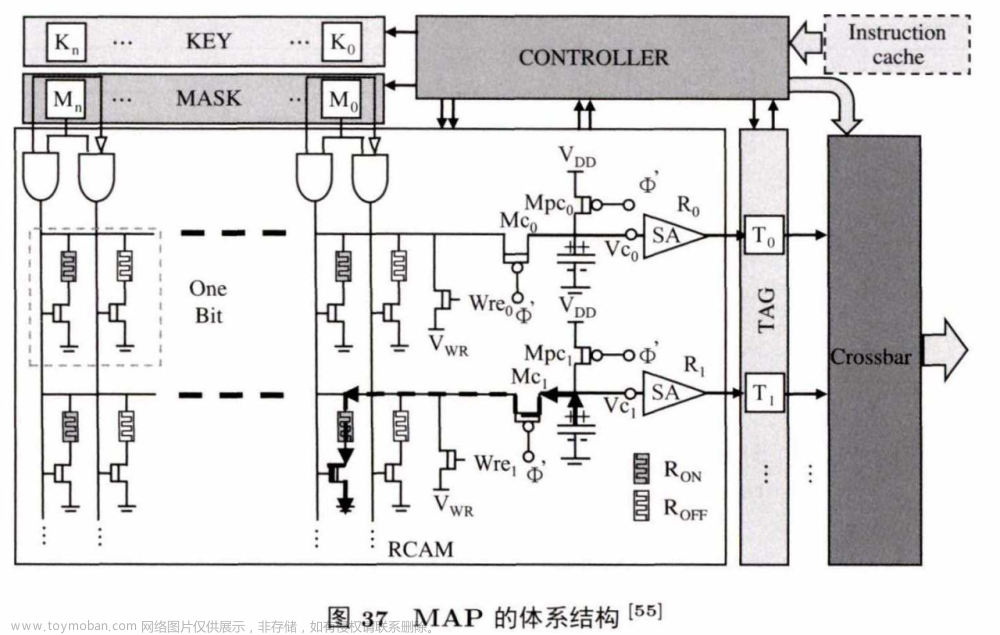
图37是MAP的系统结构,配备有基于忆阻器的内容寻址存储(resistive content addressable memory,RCAM)、控制器、指令缓存器和一些专用寄存 器 (例如键值寄存器、掩码寄存器、标志寄存器).指令所需要的数据全部存储在RCAM中. RCAM用两个忆阻器cell来存储一比特位的正负部分.系统运行时,指令寄存器先把指令发送到控制器,控制器生成相应的掩码和键放到寄存器中.键寄存器用来存放被写或者被比较的键值,而掩码寄存器用来显示哪些比特位在被写或被比较时激活.当执行比较操作时,比较电路找出和给出的键以及掩码相吻合的行,然后做标记并存储到内存中。由于高度并行,查找一个512行的表只需大约2 ns。实验显示,和传统的冯.诺依曼架构相比,MAP能取得80倍的能耗节约和20倍的性能提升。
4.3 Tsinghua University的SQL-PIM
Sun等提出了一个针对关系型数据库的存内计算系统结构(简 称 SQL-PIM)。在数据库应用里,该结构的存储部分既支持从表中直接读行的操作,又可以支持直接读取列的操作,减少了传统计算机中片上缓存不命中带来的时间和能耗的开销. SQL-PIM实现了限制查询语句,规划查询语句和聚合查询语句.限制查询语句是找出表中符合给出规定的一系列数据,这些规定可以是数值逻辑或者是非逻辑的条件语句,通 常 用 W HERE语法来操作;规划查询语句是找出表里含有特定参数的条目或者特定的列,通 常 用 SELECT语法进行操作;聚合查询语句是对一些给定条件的条目做加操作,通常用类似 SUM 语法来求一系列值的和。
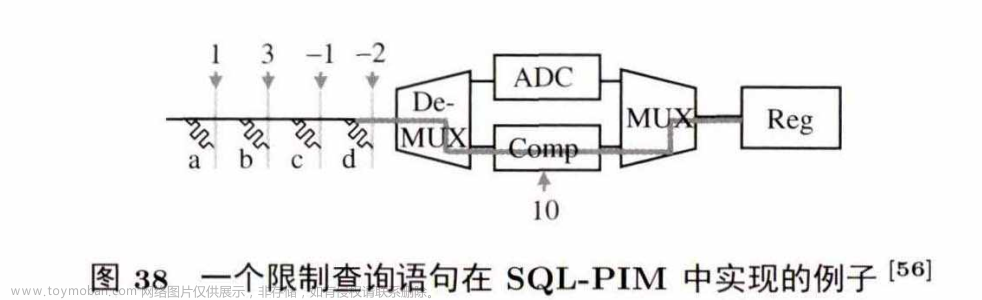
图38展示了一个SQL-PIM 实现的限制查询语句的实例: select * from Table where (a + 3x6)-(c+2xd) > 10。其中,{a ,b,c,d} 是表中四列数,存储在ReRAM阵列中{a ,b,c,d} 前面的系数{1,3,-1, 4}以电流方式加到比特线上。最后,结果电流通过包含存有10的比较电路,输出 0/1。结果为1 的,就是符合限制查询语句的条目。
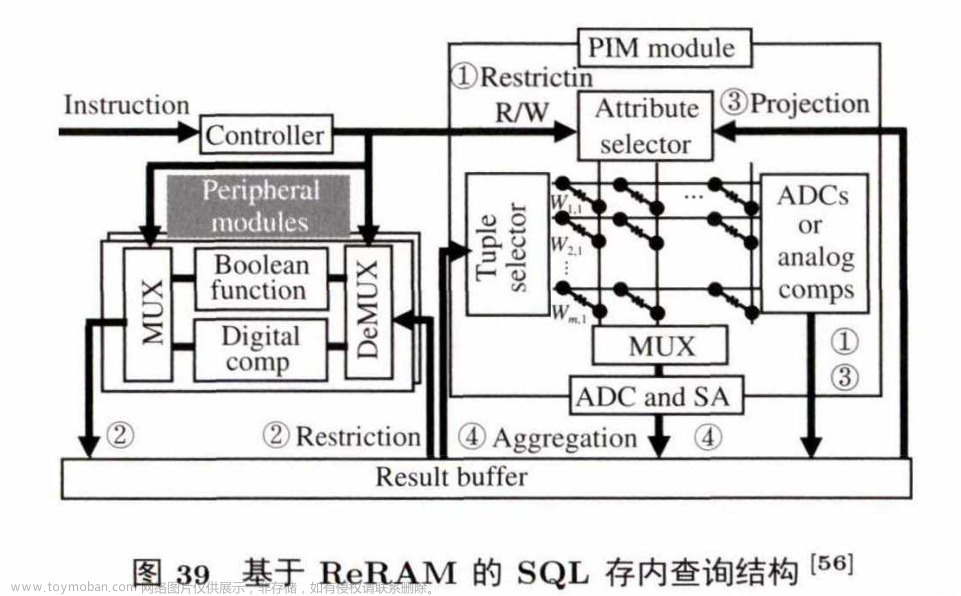
图39是 SQL-PIM 的结构,分为用于存放表格条目的P IM 部分和用于支持比较等操作的外围电路部分。指令通过控制器后,将相应的参数发送到这两个模块上,然后两个模块通过共享的缓存进行中间结果的传输.最后,结果写回到ReRAM中.除此之外,SQL-PIM 还能在不改变结构化存储的前提下支持增、删 、改、查操作.针对大的数据库表,SQL-PIM提出了一个特殊关联分割的方法,将大表存储在多个存内计算阵列中,同时减少每个计算阵列之间的相互通信.实验显示,与传统的内存数据库相比,SQL-PIM能 节 约 4〜 6 个数量级的能耗。
NVQuery也是利用RCAM支持多种查询语句的存内计算加速器,其系统结构和MAP相像。NVQuery能够支持聚合、预测、按位操作,以及精确的最近距离查找.为了支持最近距离查找,
NVQuery提出了比特线驱动的策略,将权重加到相应的比特位上.实验显示,与传统的冯•诺依曼系
统结构相比,NVQuery带 来 49.3倍的性能提升和32.9倍的能耗节约。
文章来源:https://www.toymoban.com/news/detail-835666.html
5 总结
存内计算支持的算子较少,设计灵活度不如近数据计算的逻辑层,但是存内计算用于支持特定算
子 (目前主要是向量乘矩阵算子)的性能很高且能耗低.存内计算的核心思路是利用新型存储的物理结构和特性来支持应用程序中频繁出现的算子.同时,存内计算相关研究还关注:存内计算模块互联和数据流的设计;数据映射策略:外围电路的优化和复用;与现有存储系统的融合。
文章来源地址https://www.toymoban.com/news/detail-835666.html
到了这里,关于存内计算的主流技术方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!