1. PAI-TorchAcc 简介
PAI-TorchAcc(Torch Accelerator)是阿里云机器学习平台开发的Pytorch上的大模型训练加速框架。
PAI-TorchAcc借助社区PyTorch/XLA,通过 GraphCapture 技术将 Pytorch 动态图转换为静态计算图,基于计算图进行分布式优化、计算优化、显存优化等,为包括大语言模型在内的Pytorch上的模型提供高效训练支持。相比于社区Pytorch/XLA,PAI-TorchAcc具有更好的易用性、更高的性能和更丰富的功能。更详细的介绍可以见文章:AI加速引擎PAI-TorchAcc:整体介绍与性能概述。
2. 完全开源的 OLMo 模型
OLMo (Open Language Model) 是由艾伦人工智能研究所等机构发表的完全开源的大语言模型。OLMo 模型提供了完整的训练数据集、代码、checkpoint 等,几乎完全开源了一个大语言模型从零开始训练所需的代码和数据。不仅如此,OLMo 模型在多项核心指标上接近而且部分超过 LLAMA2 模型。
3. 如何使用 PAI-TorchAcc 加速 OLMo 模型训练?
通过 PAI-TorchAcc 加速模型训练一般需要三个步骤:
- 定义 torchacc.Config,并指定加速选项。
- 调用 torchacc.accelerate,并传入model和config,完成加速训练的准备。
- 通过 torchacc.AsyncLoader对 torch dataset_loader 进行封装,加速数据加载。
# 定义 model 和 dataloader
model = AutoModelForCausalLM.from_pretrained("allenai/OLMo-1B", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("allenai/OLMo-1B", use_fast=False, trust_remote_code=True)
train_loader = get_dataloader(tokenizer)
# 定义 TorchAcc Config
config = torchacc.Config()
config.compute.bf16 = True # 开启 bf16
config.compute.acc_scaled_dot_attn = True # 自动替换 Torch ScaledDot 为torchacc flash attn 版本
config.dist.fsdp.size = torchacc.dist.world_size() # 开启 FSDP,设置 FSDP 数目
config.dist.fsdp.wrap_layer_cls = {"OlmoSequentialBlock"} # 将OLMo模型的decoder layer进行FSDP封装
# 一行代码加速模型
model = torchacc.accelerate(model, config)
# 异步加速数据加载
train_loader = torchacc.AsyncLoader(train_loader, model.device)
# training loop
...阿里云 DSW Gallery 现在有更完整的 OLMo 模型加速示例:https://pai.console.aliyun.com/?regionId=cn-wulanchabu#/dsw-gallery/preview/deepLearning/torchacc/train_olmo
4. PAI-TorchAcc 的性能表现
以单机 8 卡 A100 为例,在 OLMo 1B 上,PAI-TorchAcc 相比 PyTorch FSDP 加速比为 1.64X;在 OLMo 7B 上,PAI-TorchAcc 相比 PyTorch FSDP 加速比为 1.52X。
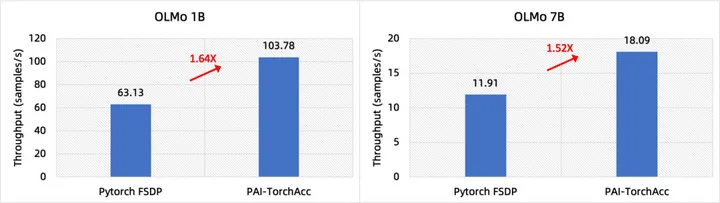
图 1: PAI-TorchAcc 相比 PyTorch FSDP 在 OLMo 模型上的性能提升
5. PAI-TorchAcc 为何这么快?
在 OLMo 模型的性能对比中,PAI-TorchAcc和 PyTorch 都采用相同的分布式策略 FSDP(ZeRO-3)。PAI-TorchAcc 通过计算优化、通信优化、显存优化等,在 OLMo 7B 上相比 PyTorch 达到了 1.52X 的加速比。下面我们以 OLMo 7B 为例分析 PAI-TorchAcc 的性能收益来源。
计算优化&通信优化
为了方便对比,我们将 PAI-TorchAcc和 PyTorch 的 micro batch size都设置为 2 进行对比。
从图 2 中可以看出,通过计算优化,PAI-TorchAcc 将访存密集型算子的时间优化为 PyTorch 对应算子时间的 45.56%,整体的加速比约为 1.25X。通过通信优化,PAI-TorchAcc 能够将计算和通信更好进行 overlap,将没有 overlap 的通信占整体时间的占比从 8.19%降低到 2.43%。
通过计算优化&通信优化,PAI-TorchAcc 相比PyTorch达到了 1.32X 的加速比。
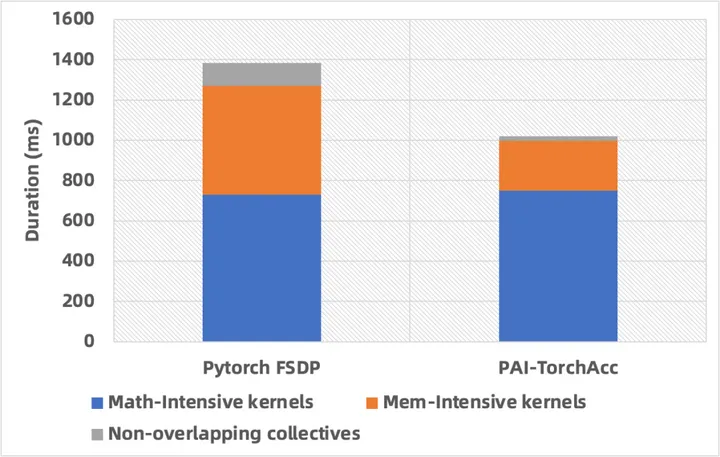
图 2: micro batch size=2 时,PAI-TorchAcc 相比 PyTorch FSDP 在 OLMo 7B 上的性能提升
显存优化
在 PAI-TorchAcc 中,由于 PyTorch 模型已经转换为静态计算图,所以可以使用比较多的显存优化方法。例如,通过对算子的执行顺序进行调整,可以得到更小的显存峰值;通过更优的显存分配算法,可以让显存碎片更少,减少显存使用;通过 patten match 等方式将 attention 替换为使用显存更少的 flash attention 等等。
通过显存优化,PAI-TorchAcc 的最大 micro batch size 能够达到 4,而 PyTorch 的最大 micro batch size 只能达到 2,这使得PAI-TorchAcc 能够获得更高的性能加速比,这一部分的性能收益主要来自于计算密集型算子。
如图 3 所示,PAI-TorchAcc micro batch size=4 相比 micro batch size=2 的吞吐加速比为 1.15X,这使得PAI-TorchAcc 相比 PyTorch 最终达到了 1.52X 的加速比。
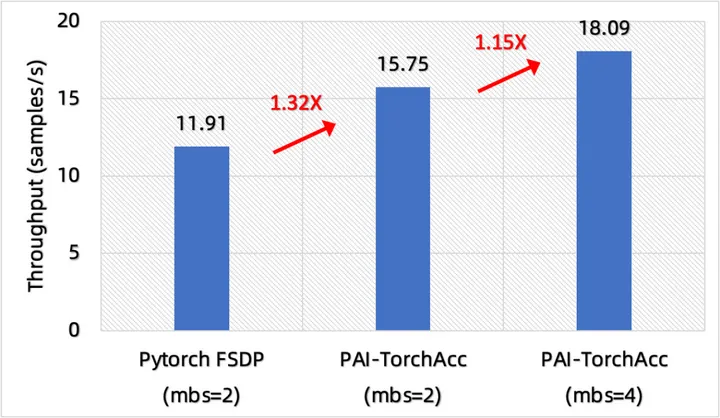
图 3: 在不同 micro batch size 下,PAI-TorchAcc 相比 PyTorch FSDP 在 OLMo 7B 上的性能提升
6. 总结
本文介绍了如何使用 PAI-TorchAcc 加速 OLMo 模型训练,分析了PAI-TorchAcc 的性能收益来源。实际上,PAI-TorchAcc可以通过并行化策略、显存优化、计算优化和调度优化等方法来加速更多的大语言模型训练,目前已接入常见的开源大模型,包括LLaMA、LLaMA-2、BaiChuan、ChatGLM、QWen等。除了大语言模型之外,PAI-TorchAcc也易于接入视觉类、语音类模型,并大幅度提升训练性能。欢迎在阿里云上使用该产品。
作者:黄奕桐、沈雯婷、艾宝乐、王昂、李永
原文链接文章来源:https://www.toymoban.com/news/detail-843527.html
本文为阿里云原创内容,未经允许不得转载。文章来源地址https://www.toymoban.com/news/detail-843527.html
到了这里,关于AI加速引擎 PAI-TorchAcc:OLMo训练加速最佳实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!











